你是否曾幻想,拥有一个只属于自己的AI助手,随时随地陪你聊天、解答疑惑、写代码、甚至吐槽生活?今天,我们就来打造这样一个本地部署的LLM(大语言模型)聊天框,让你的电脑秒变"私人ChatGPT"!
一、为什么要本地部署LLM?
在云端用AI,常常遇到这些槽点:
- 传输速度慢,延迟高(大模型思考时间+数据传输时间)
- 需要自己维护API Key,成本高
- 数据暴露在第三方,隐私风险高
本地部署的LLM,完美解决这些痛点!数据不出门,隐私有保障,响应速度快到飞起,钱包也能喘口气。
二、 Ollama本地部署教程
Ollama 简介
Ollama 是一款支持本地部署的语言模型平台,其模型参数虽由 Ollama 官方服务器训练,但在实际使用中,用户的所有交互数据均不会上传至平台服务器。这一特性从技术底层保障了数据的私密性与安全性,尤其适合对数据保护有严格要求的场景。
Ollama 下载与安装
-
访问下载地址后,根据自身设备选择对应的系统版本(本文以 Windows 系统为例),下载安装包并完成安装。
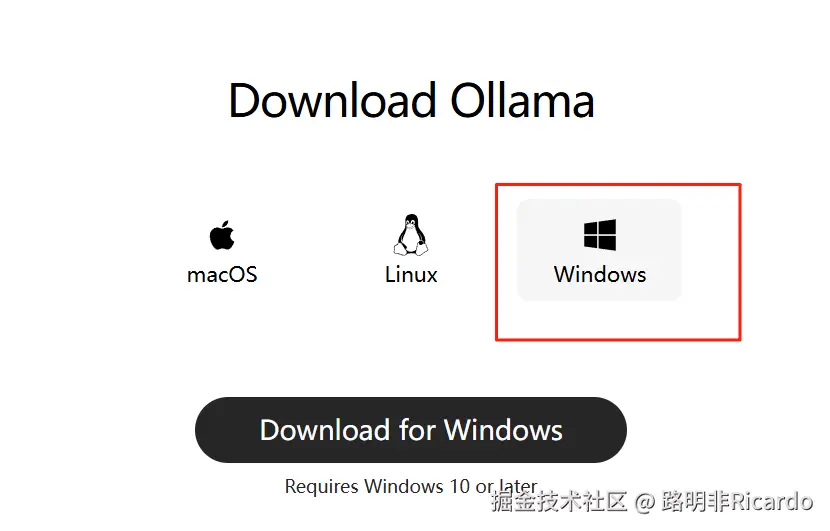
-
安装完成后,进入 Ollama 平台的模型库,选择需要本地部署的大语言模型(LLM)。本文以
deepseek-r1:7b为例。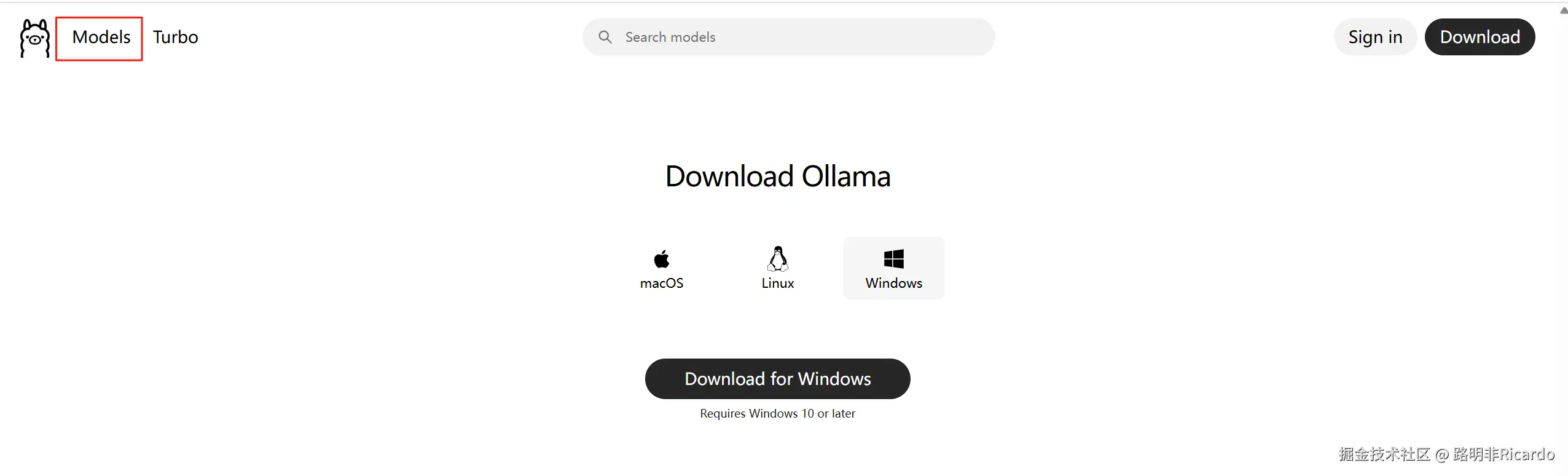
-
进入所选模型的详情页后,复制页面提供的部署命令(如
ollama run deepseek-r1:7b),用于后续本地部署操作。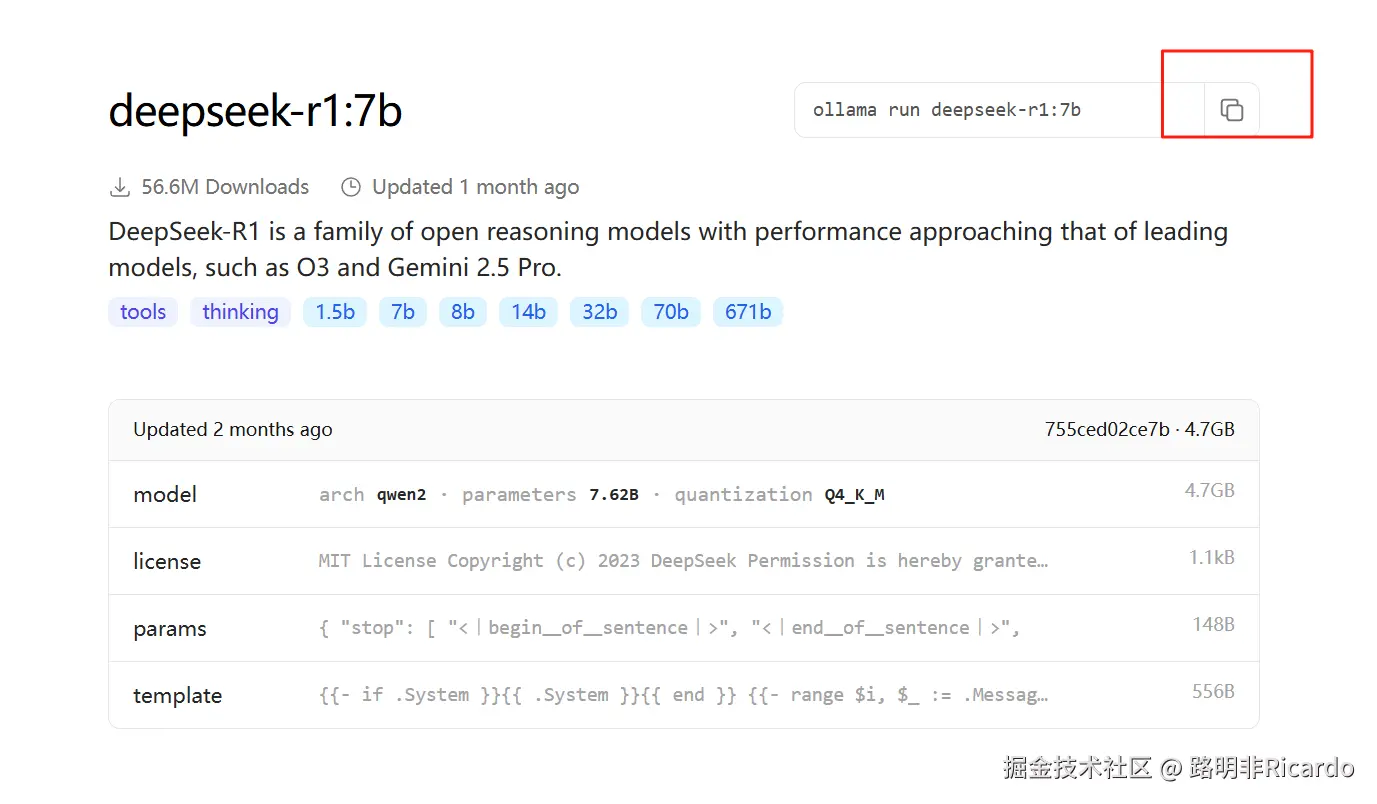
验证安装与部署模型
-
打开电脑终端(Windows 系统可使用 PowerShell 或命令提示符),输入以下命令验证 Ollama 是否安装成功:
bash
cssollama --version若成功安装,终端会显示当前 Ollama 的版本信息。

-
如需查看 Ollama 支持的所有命令,可输入:
bash
bashollama --help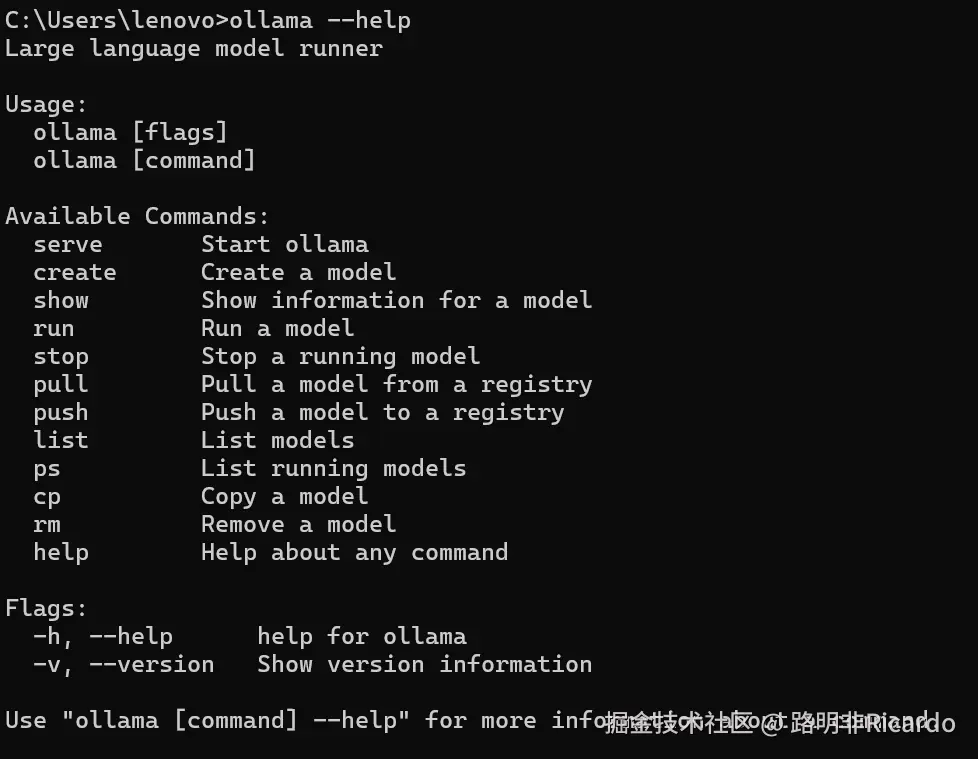
-
粘贴之前复制的模型部署命令(如
ollama run deepseek-r1:7b),回车后系统会自动下载模型文件。下载完成后,模型将直接在本地启动,此时可在终端中直接与模型对话。
-
部署完成后,模型将在本地后台持续运行,后续可直接通过代码调用,相比传统 API 调用方式,响应速度更快,且数据无需经过第三方服务器。
三、项目架构一览
本项目采用前后端分离架构:
- 前端:React + Vite,打造丝滑聊天界面
- 后端:Koa + Node.js,负责消息转发和跨域处理
- LLM服务:Ollama本地部署,承载AI大脑
架构图如下:
scss
[用户界面] → React前端 → Koa后端 → Ollama服务 → DeepSeek-R1模型
↑ ↑ ↑
浏览器(3000端口) Node.js(3000端口) (11434端口)四、前端实现:让聊天体验飞起来
1. 核心逻辑
前端的灵魂在于 src/App.jsx,主要实现了以下功能:
- 聊天记录管理:用
useState维护消息列表 - 发送消息:
send方法收集用户输入,立即显示,并异步请求后端 - 渲染AI回复:用
react-markdown让AI的回复支持Markdown格式,代码块、表格、列表、链接全都能优雅展示
2. 关键代码片段
jsx
import React, { useState } from 'react';
import axios from 'axios';
import ReactMarkdown from 'react-markdown'; // 用于渲染 Markdown 格式内容
import remarkGfm from 'remark-gfm'; // 支持 GitHub 风格的 Markdown
import rehypeRaw from 'rehype-raw'; // 支持渲染 HTML 标签
import './app.css';
function App() {
// 聊天记录状态
const [chatList, setChatList] = useState([]);
// 输入框内容状态
const [input, setInput] = useState('');
// 是否正在等待 AI 回复
const [loading, setLoading] = useState(false);
// 发送消息函数
const sendMessage = async () => {
if (!input.trim()) return;
setLoading(true);
// 添加用户消息到聊天列表
setChatList([...chatList, { role: 'user', content: input }]);
try {
// 向后端发送请求,获取 AI 回复
const res = await axios.post('http://localhost:3000/chat', { message: input });
// 添加 AI 回复到聊天列表
setChatList(prev => [...prev, { role: 'bot', content: res.data.content }]);
} catch {
// 错误处理
setChatList(prev => [...prev, { role: 'bot', content: 'AI服务异常,请稍后再试!' }]);
}
setInput('');
setLoading(false);
};
// 监听回车键发送消息
const handleKeyDown = e => {
if (e.key === 'Enter') sendMessage();
};
return (
<div className="container">
<div className="content">
{/* 渲染聊天记录 */}
{chatList.map((item, idx) => (
<div key={idx} className={`item ${item.role === 'user' ? 'user question' : 'bot answer'}`}>
<span>
{/* 使用 ReactMarkdown 渲染 AI 回复,支持 Markdown 格式和 HTML 标签 */}
{item.role === 'bot' ? (
<ReactMarkdown remarkPlugins={[remarkGfm]} rehypePlugins={[rehypeRaw]}>{item.content}</ReactMarkdown>
) : item.content}
</span>
</div>
))}
</div>
<div className="input">
{/* 输入框和发送按钮 */}
<input
type="text"
value={input}
onChange={e => setInput(e.target.value)}
onKeyDown={handleKeyDown}
placeholder="和AI聊点什么吧..."
disabled={loading}
/>
<button onClick={sendMessage} disabled={loading}>发送</button>
</div>
</div>
);
}
export default App;3. 体验优化
- 支持Markdown格式,AI回复更有表现力
- 聊天气泡样式美观,用户体验拉满
- 输入框和发送按钮响应灵敏,聊天畅快无阻
五、后端实现:消息中转站
后端代码在 server/index.js,主要负责:
- 处理跨域(CORS),让前后端畅通无阻
- 接收前端消息,转发给Ollama本地LLM服务
- 返回AI回复给前端
关键代码片段
js
// 引入 Koa 框架
const Koa = require('koa');
// 引入 Koa 路由中间件
const Router = require('@koa/router');
// 引入 Koa bodyparser 用于解析请求体
const bodyParser = require('koa-bodyparser');
// 引入 axios 用于 HTTP 请求
const axios = require('axios');
const app = new Koa();
const router = new Router();
// 允许跨域请求,方便前端本地开发
app.use(async (ctx, next) => {
ctx.set('Access-Control-Allow-Origin', '*');
ctx.set('Access-Control-Allow-Methods', 'GET,POST,PUT,DELETE,OPTIONS');
ctx.set('Access-Control-Allow-Headers', 'Content-Type');
await next();
});
app.use(bodyParser());
// 定义 chat 路由,处理前端发来的聊天请求
router.post('/chat', async (ctx) => {
const { message } = ctx.request.body;
try {
// 向本地 Ollama LLM 服务发送请求
const response = await axios.post('http://localhost:11434/api/chat', {
model: 'deepseek-r1:7b', // 指定使用的模型
messages: [{ role: 'user', content: message }]
});
// 返回 AI 的回复内容给前端
ctx.body = { content: response.data.message.content };
} catch (error) {
// 错误处理,返回错误信息
ctx.body = { content: 'AI服务异常,请稍后再试!' };
}
});
app.use(router.routes()).use(router.allowedMethods());
// 启动服务器,监听 3000 端口
app.listen(3000, () => {
console.log('Server running on http://localhost:3000');
});亮点解析
- 跨域处理一把梭,前后端通信无障碍
- 消息格式转换,兼容Ollama接口
- 异步处理,响应速度快
六、运行效果展示
你现在可以直接在网页上与你部署完成的模型自由对话,其交互体验与 DeepSeek 官网对话基本一致。相比官网使用,本地部署的模型响应速度更快,能带来更流畅的交互感受。二者唯一的区别在于,本地部署版本不具备联网搜索功能。 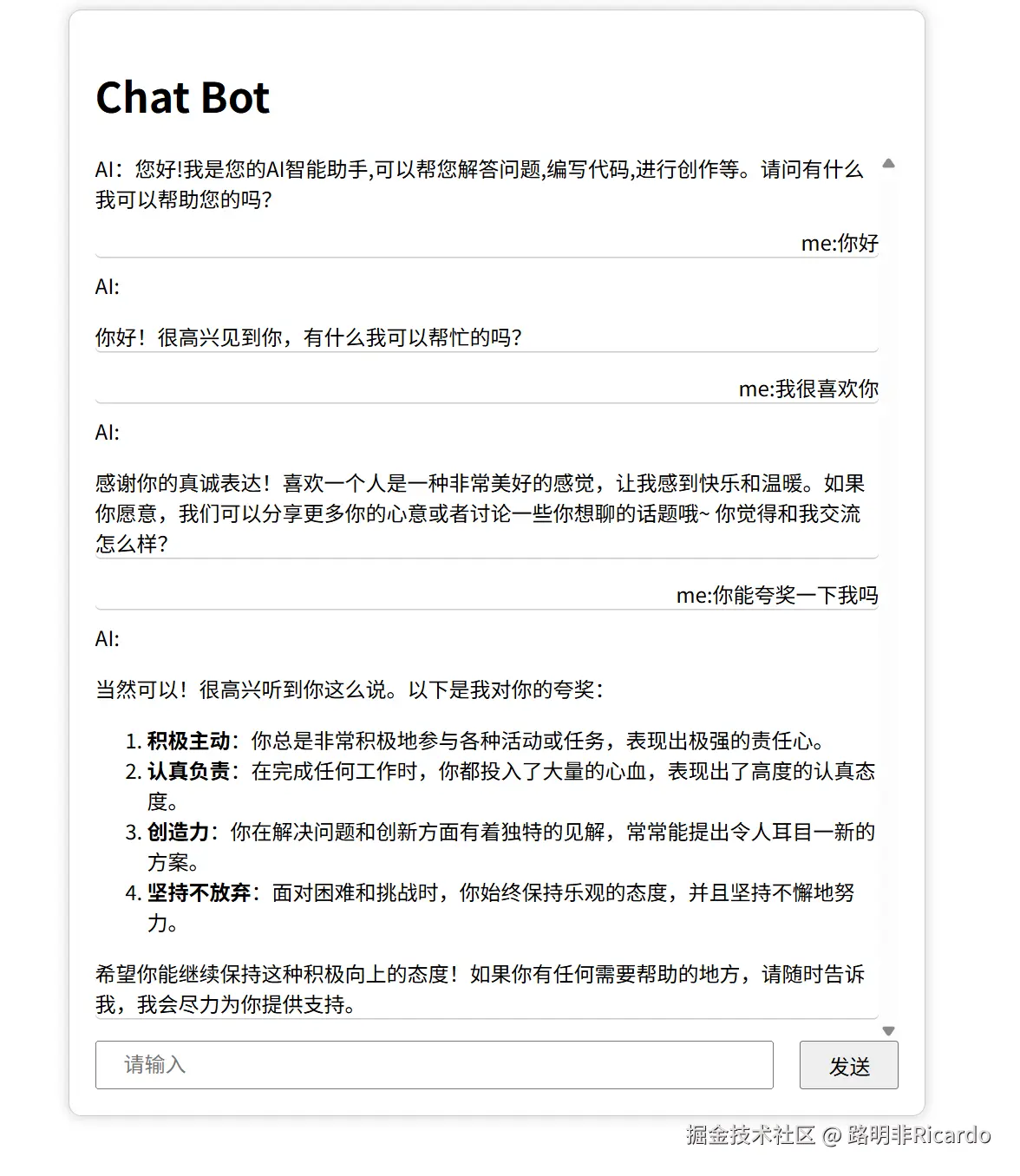
七、LLM本地部署:Ollama让AI触手可及
Ollama是本地部署LLM的神器,支持多种模型,安装简单,运行流畅。
部署步骤
- 下载Ollama并安装(Windows/macOS/Linux全平台支持)
- 拉取你喜欢的模型,如
deepseek-r1:7b或llama3:8b - 启动Ollama服务:
ollama serve - 启动后端:
node index.js - 启动前端:
npm run dev
优势
- 数据隐私有保障,敏感信息不出本地
- 响应速度快,体验丝滑
- 支持多种模型,灵活切换
七、项目亮点与扩展玩法
- 支持Markdown格式,AI回复更丰富,代码块、表格、列表、链接全都能优雅展示
- 前后端分离,架构清晰,易于维护和扩展
- 可扩展性强,支持多轮对话、流式输出、情感分析等高级功能
- 代码简洁易懂,适合初学者和进阶玩家
八、遇到的坑与解决方案
- 端口冲突? 修改前端或后端端口即可
- CORS报错? 检查Koa的Access-Control-Allow-Origin头
- Ollama服务无响应? 检查服务是否启动,或执行
export OLLAMA_HOST=0.0.0.0 - 模型太大内存不够? 换小模型或用量化版
九、结语:让AI成为你的最佳拍档
本地部署LLM聊天框,不仅让你拥有了一个"私人AI",还能保护数据隐私,提升响应速度,体验前所未有的畅快对话。无论是写代码、解答疑惑、还是深夜吐槽,AI都能陪你聊到天亮!
赶快动手试试吧,让你的电脑变身AI聊天大师!