在之前的文章中,相信你已经学会了如何将加载好的文档按照一定规则分割成文档片段,以及对文档片段进行了文本嵌入生成对应的向量数据。
下一步就是要将这些向量数据存储到向量数据库,本文将会详细的讲解什么是向量数据库(Vector database) ,以及常用向量数据库Weaviate的安装及使用方法。
文中所有示例代码:github.com/wzycoding/l...
一、什么是向量数据库
向量数据库(Vector database) 是一种能够存储多维向量数据的新型数据库,向量数据库实现了一种或者多种近似相邻算法,来支持用户使用查询文本或图像进行相似性检索,来检索到最匹配的向量数据。
这些存储的向量都是高维的,比如我们在上一篇文章中使用的text-embedding-3-small模型,生成的向量的维度是1536,向量的维度一般可以从几百到几万不等,这些向量的维度表示了原始的数据在不同方面的特征,向量的维度取决于它要表示的数据复杂程度,除了文本片段,图像、音频等都可以被向量化存储到向量数据库。
下面通过一个例子进行分析:
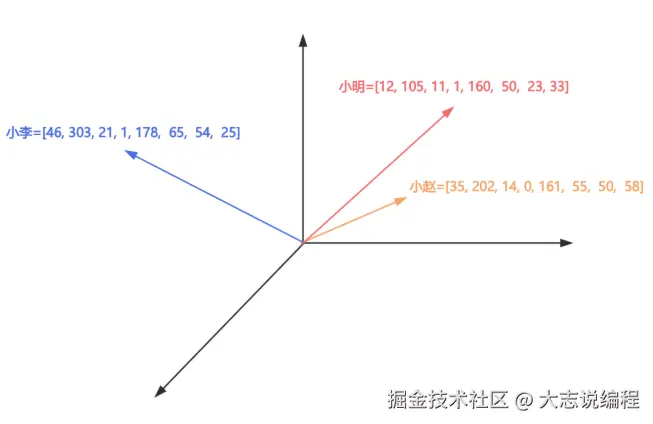
文本1:小明是一个光明小学五年级学生,年龄11岁,性别男,身高160cm,体重50kg,他喜欢唱歌和写作。
文本2:小赵是一个第二初级中学初二学生,年龄14岁,性别女,身高161cm,体重55kg,她喜欢游泳和羽毛球。
文本3:小李是一个光明大学大三学生,年龄21岁,性别男,身高178cm,体重65kg,他喜欢跑步和弹吉他。
假设要将上面的三个文本片段转换为向量,文本嵌入模型就会对原始文本的多方面的特征进行提取,比如以姓名、学校、年龄、性别、身高、体重、爱好维度进行向量转换。
通过一定规则根据这几个维度映射模拟的向量值如下,并将这些向量数据和元数据一起存储到向量数据库中。
第一个文本转换为向量:12, 105, 11, 1, 160, 50, 23, 33,元数据segment_id=1
第二个文本转换为向量:35, 202, 14, 0, 161, 55, 50, 58,元数据segment_id=2
第三个文本转换为向量:46, 303, 21, 1, 178, 65, 54, 25,元数据segment_id=3
以下是模拟三个向量映射到向量空间:
当进行数据检索时,假设提供的查询的文本是:
我需要一个身高在180cm左右,喜欢弹吉他的大学生的学生信息
通过文本嵌入模型将查询文本也转换向量:80, 300, 99, 10, 180, 60, 24, 25,通过这一组向量到数据中进行相似性检索,向量数据库会计算向量之间的距离,找到和查询文本向量距离最近的一个或者几个向量值,返回检索到的向量数据,通过向量的元数据中的segment_id,就可以找到原始的文本片段信息。
以上就是向量数据库的一次基础检索流程,向量数据库和传统的关系型数据库相比,可以进行语义上的相似性匹配,而不像关系型数据库只能根据关键词进行模糊搜索。
二、Weaviate向量数据库安装
本文要介绍的数据是当前非常流行的Weaviate数据库,Weaviate数据库是一个基于GO语言开发的开源的向量数据库。

Weaviate官方文档:docs.weaviate.io/weaviate
Weaviate支持以下四种部署方式:
Docker部署:Docker部署适用于开发和测试环境
Weaviate Cloud:Weaviate官方提供的Serverless方案,支持高可用、零停机时间,适用于生产环境
K8S部署:使用K8S部署Weaviate,可以用于开发或者生产环境。
嵌入式部署:嵌入式 Weaviate可以从应用程序中运行 Weaviate 实例,不需要从独立的服务器安装,嵌入式Weaviate目前仍处于实验阶段,并且不支持Windows系统。
下面对如何在Docker中安装Weaviate进行介绍:
运行 Weaviate命令如下
bash
docker run -d --name weaviate -p 8080:8080 -p 50051:50051 cr.weaviate.io/semitechnologies/weaviate:1.32.2这样Weaviate实例就创建成功了
bash
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
66cec8f2cc75 cr.weaviate.io/semitechnologies/weaviate:1.32.2 "/bin/weaviate --hos..." 13 seconds ago Up 12 seconds 0.0.0.0:8080->8080/tcp, 0.0.0.0:50051->50051/tcp weaviateDocker其他常用命令:
bash
# 查看所有docker镜像
docker images
# 查看所有docker实例
docker ps -a
# 查看所有运行中的Docker实例
docker ps
# 删除docker实例
docker rm weaviate
# 启动weaviate实例
docker start weaviate
# 停止weaviate实例
docker stop weaviate三、Weaviate向量数据库使用方法
Weaviate官方并没有提供可视化界面来查看和操作Weaviate数据库,下面我们通过Weaviate提供的Python 客户端来操作Weaviate数据库。
首先,在项目中安装Weaviate客户端依赖
bash
pip install -U weaviate-client执行命令,生成依赖版本快照
bash
pip freeze > requirements.txt在介绍Weaviate客户端使用之前,首先需要了解Weaviate的几个基础知识。
- 在Weaviate中,可以创建多个集合,用来保存数据
- 在Weaviate中,保存数据的载体是对象,在对象中可以包含向量信息(Vector) 和属性信息(properties) ,这里的属性信息就是我们之前所说的元数据信息。
- 所有的对象都属于一个集合且仅属于一个集合
3.1 连接Weaviate
连接本地Weaviate数据库代码示例如下,指定host地址、端口号和grpc端口号。
python
import weaviate
client = weaviate.connect_to_local(
host="localhost",
port=8080,
grpc_port=50051,
)
print(client.is_ready())执行结果:
python
True3.2 创建集合
在Weaviate中,可以通过create方法创建集合:
python
client.collections.create("Database")3.3 创建对象
在集合Database中创建一个带向量和属性的对象,并且insert方法会返回一个uuid,这个uuid就是这个对象的唯一标识。
python
database = client.collections.get("Database")
uuid = database.data.insert(
properties={
"segment_id": "1000",
"document_id": "1",
},
# 复制生成1536维向量
vector=[0.12345] * 1536
)
print(uuid)执行结果:
python
a60f4b19-9c97-4eb0-ba02-8c7b0a6cfcb1也可以单独指定uuid,不让Weaviate自动生成,通过指定uuid属性,设置uuid
python
uuid = database.data.insert(
properties={
"segment_id": "1000",
"document_id": "1",
},
# 复制生成1536维向量
vector=[0.12345] * 1536,
uuid=uuid.uuid4()
)3.4 批量导入对象
除了单个创建对象,还可以批量导入对象,预先生成5条数据和5个向量,使用批量导入将对象导入到集合中,并自己指定uuid,当出现失败数量超过10个时,则终止对象导入。
python
# 生成5条数据
data_rows = [{"title": f"标题{i + 1}"} for i in range(5)]
# 生成5个对应的向量数据
vectors = [[0.1] * 1536 for i in range(5)]
# 集合对象
collection = client.collections.get("Database")
# 批处理大小为200
with collection.batch.fixed_size(batch_size=200) as batch:
for i, data_row in enumerate(data_rows):
# 批量导入对象
batch.add_object(
properties=data_row,
vector=vectors[i],
# 指定uuid
uuid=uuid.uuid4()
)
# 超过10个则终止导入
if batch.number_errors > 10:
print("批量导入对象出现错误次数过多,终止执行")
break
# 打印处理失败对象
failed_objects = collection.batch.failed_objects
if failed_objects:
print(f"导入失败数量: {len(failed_objects)}")
print(f"第一个导入失败对象: {failed_objects[0]}")3.5 根据uuid查询对象
Weaviate支持通过uuid 检索对象。如果uuid不存在,将会返回 404 错误,这里还指定了include_vector属性为True表示除了返回对象元数据信息之外,同时返回向量信息,在打印向量时,读取vector的default属性是因为,在Weaviate对象可以保存多个向量信息,默认的向量名就是default。
python
database = client.collections.get("Database")
# 通过uuid获取对象信息,并且返回向量信息
data_object = database.query.fetch_object_by_id(
"a60f4b19-9c97-4eb0-ba02-8c7b0a6cfcb1",
include_vector=True
)
# 打印向量信息
print(data_object.properties)
print(data_object.vector["default"])执行结果如下:
python
{'document_id': '1', 'segment_id': '1000', 'title': None}
[0.12345000356435776, 0.12345000356435776, 0.12345000356435776, 省略部分数据...]3.6 查询所有对象
Weaviate 提供了相关API来遍历集合所有的数据,这个方法在迁移数据时非常有用,通过如下方式可以遍历集合内的全部对象信息。
python
collection = client.collections.get("Database")
for item in collection.iterator(
include_vector=True
):
print(item.properties)
print(item.vector)执行结果如下,返回了元数据信息和向量信息。
python
{'title': '标题1', 'segment_id': None, 'document_id': None}
{'default': [0.10000000149011612, 0.10000000149011612, 省略部分数据...]}
{'document_id': None, 'segment_id': None, 'title': '标题2'}
{'default': [0.10000000149011612, 0.10000000149011612, 省略部分数据...]}
省略部分数据...3.7 更新对象信息
Weaviate支持对对象部分更新,也支持对对象进行整体替换。
首先来介绍对象的部分更新,使用示例如下,根据uuid去更新对象属性信息、向量信息,没有指定更新的属性不会发生变化。
python
database = client.collections.get("Database")
database.data.update(
uuid="a60f4b19-9c97-4eb0-ba02-8c7b0a6cfcb1",
# 更新属性
properties={
"segment_id": "2000",
},
# 更新向量信息
vector=[1.0] * 1536
)在执行上面的程序之前,uuid为a60f4b19-9c97-4eb0-ba02-8c7b0a6cfcb1的向量信息如下。
python
{'document_id': '1', 'segment_id': '1000', 'title': None}
[0.12345000356435776, 0.12345000356435776, 0.12345000356435776, 省略部分数据...]执行上述程序,重新查询该对象信息如下,数据已经修改成功,由于没有指定document_id因此该属性没有变化。
python
{'title': None, 'document_id': '1', 'segment_id': '2000'}
[1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 省略部分数据...]除了使用update方法进行属性更新,也可以使用replace方法对整个对象数据进行替换,代码示例如下:
python
database = client.collections.get("Database")
database.data.replace(
uuid="a60f4b19-9c97-4eb0-ba02-8c7b0a6cfcb1",
properties={
"segment_id": "3000",
},
vector=[1.0] * 1536
)执行成功之后,重新查询对象信息,可以看到除了segment_id属性和向量信息都进行更新之外,document_id也被设置为None,因此可以判断整个对象进行了替换。
python
{'document_id': None, 'segment_id': '3000', 'title': None}
[1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 省略部分数据...]3.8 删除对象
Weaviate支持按uuid删除、批量删除、删除全部三种删除方式。
按照uuid删除方法
python
database = client.collections.get("Database")
database.data.delete_by_id(
"a60f4b19-9c97-4eb0-ba02-8c7b0a6cfcb1"
)按条件批量删除方法,使用示例如下,对属性title进行模糊匹配,匹配成功的对象将会被删除。
python
database = client.collections.get("Database")
database.data.delete_many(
where=Filter.by_property("title").like("标题*")
)所有对象都属于一个集合,因此删除集合就相当于删除全部对象,删除集合方法如下:
python
client.collections.delete(
"Database"
)四、总结
本文首先介绍了向量数据库的基本概念 ,分析了它与传统关系型数据库的区别与优势:关系型数据库主要用于精确匹配或模糊搜索,而向量数据库能够基于语义进行相似性检索,更适用于文本、图像、音频等非结构化数据的搜索场景。
接着,我们了解了当前在 AI 应用中非常流行的开源向量数据库 Weaviate ,介绍了Weaviate的主要特性和四种部署方式,详细讲解了使用 Docker 部署 Weaviate 的方法。
在Weaviate向量数据库使用方法部分,主要介绍了数据库连接、创建集合、对象的增删改查等操作。
通过本文,相信你已经掌握了什么是向量数据库,以及Weaviate向量数据库的基本用法,在下一篇文章中,我们将深入介绍在LangChain中如何使用向量数据库,欢迎持续关注~