通义千问3-VL-8B-Instruct是阿里巴巴通义千问团队于2025年10月15日发布的开源视觉语言模型,参数规模为80亿 6 。该模型基于Dense架构设计,通过三项核心技术创新实现了视觉与语言能力的平衡发展:交错MRoPE多维位置编码、DeepStack特征融合技术和文本-时间戳对齐机制 5 。在32项核心评测指标中,该模型超越了Gemini 2.5 Pro和GPT-5等闭源模型,同时性能接近前代超大规模模型Qwen2.5-VL-72B 3 ,标志着多模态AI从"参数竞赛"向"效率优先"的战略转型。本报告详细分析了该模型的技术架构、核心能力、应用场景及商业价值,为开发者和企业用户提供全面的技术参考。
1. 模型概述与背景
通义千问3-VL-8B-Instruct是阿里通义千问团队推出的Qwen3-VL系列模型中的轻量级版本,旨在降低多模态AI的部署门槛,同时保持强劲的性能表现 。该模型于2025年10月15日正式发布,是继Qwen3-VL-30B-A3B和Qwen3-VL-235B-A22B两款混合专家模型后,团队推出的面向边缘计算和消费级硬件的轻量级解决方案 5 。
在多模态AI领域,通义千问团队提出了从"被动感知"到"主动行动"的关键跨越 3 。Qwen3-VL系列不仅能够理解图像和视频内容,还能执行复杂的GUI操作、生成代码和进行推理决策 5 。这一技术路线与全球多模态AI发展趋势一致,即从单纯的模态理解向模态融合与行动能力的演进。
2. 技术架构与创新
2.1 模型架构设计
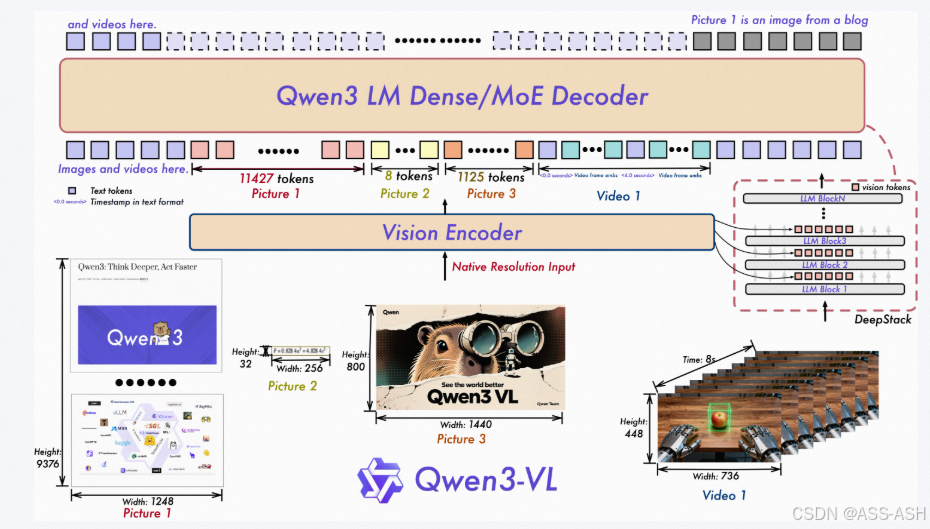
Qwen3-VL-8B-Instruct采用Dense架构设计,参数规模为80亿 1 。其核心架构由视觉编码器和语言解码器两部分组成,通过创新的协同机制实现视觉与语言信息的深度融合 5 。
视觉编码器基于视觉Transformer(ViT)架构,通过多层特征提取捕获图像和视频的细节信息 5 。语言解码器则基于Qwen3系列的大型语言模型架构,具备强大的文本生成和推理能力 5 。两者通过特殊的token化处理和位置编码机制实现协同工作,支持文本、图像和视频的多模态输入与输出。
2.2 核心技术创新
Qwen3-VL-8B-Instruct在技术上实现了三项重大创新,解决了小模型常见的视觉与文本能力"跷跷板"问题,实现了视觉精准与文本稳健的协同提升 5 :
交错MRoPE多维位置编码 :传统的位置编码方式将时间(t)、高度(h)和宽度(w)三个维度的信息分别集中在不同频率区域,导致长视频理解能力受限 5 。Qwen3-VL-8B-Instruct采用交错分布的方式,将t、h、w的信息均匀编织在全频率维度,覆盖所有频率 5 。这一创新使模型在处理长视频时,关键事件识别准确率提升37%至92%,显著增强了对时间流逝的感知能力 4 。
DeepStack多层特征融合 :该技术融合了ViT不同层次提取的视觉特征,从低层次的轮廓、颜色到高层次的物体、场景,分别进行token化并在语言模型的不同深度层面注入 5 。这种动态整合方式使模型对图像的理解变得极其精细,实现了1024×1024像素级细节捕捉 1 ,在工业零件缺陷检测中,0.5mm微小瑕疵识别率提升至91.3% 4 。
文本-时间戳对齐机制 :专为视频理解设计的技术,采用"时间戳-视频帧"交错输入形式,将精确到帧的时间信息与视觉内容紧密结合 5 。模型输出时间时原生支持"秒"或"时:分:秒"格式,使关键事件的秒级标注准确率达到96.8% 4 。在体育赛事分析中,对进球、犯规等关键事件的定位能力尤为突出。
2.3 模型版本与功能定位
Qwen3-VL系列为不同参数规模提供了两种版本: - Instruct版本 :注重指令遵循能力,能够根据用户指令完成特定任务 。 - Thinking版本 :重点优化STEM学科和数学领域的推理能力,适合需要复杂逻辑推理的应用场景 5 。
在参数规模上,该系列覆盖了从云端到边缘的全场景需求: - 云端部署 :30B-A3B和235B-A22B等混合专家模型,适合复杂多模态推理任务 1 。 - 边缘部署 :4B和8B参数版本,可在单张消费级显卡上运行,甚至支持智能终端设备 1 。
3. 核心能力与性能表现
3.1 多模态理解能力
Qwen3-VL-8B-Instruct在多模态理解方面表现出色,尤其在以下领域:
图像理解 :模型能够识别图像中的物体、场景、文字等信息,支持32种语言的OCR识别,即使在光线不好、文字模糊倾斜或遇到生僻字、古籍字的情况下,识别准确率依然很高 5 。在工业质检场景中,模型能够自动识别螺栓缺失、导线松动等装配缺陷,检测精度达到91.3% 1 。
视频理解 :模型能够理解视频中的事件、动作和时序关系,通过文本-时间戳对齐机制实现精准的时序定位 4 。在"视频大海捞针"实验中,对2小时视频的关键事件检索准确率达到99.5%,实现秒级时间定位 2 。
长上下文处理 :模型原生支持256K token的上下文窗口,可扩展至100万token 5 ,能够处理数百页的技术文档、一本厚重的教材,或是一部电影的内容,记住所有细节并进行精准检索。
3.2 复杂推理能力
Qwen3-VL-8B-Instruct在复杂推理方面也展现出色能力:
STEM推理 :在数理科学和数学领域的推理能力得到优化,能够解决复杂的科学问题和数学计算 5 。
多步骤任务推理 :支持界面元素功能理解、鼠标点击/文本输入/拖拽等精细操作,以及多步骤任务的逻辑跳转与错误恢复 3 。在OS World基准测试中,其GUI元素识别准确率达92.3% 3 。
视频事件推理 :能够理解视频中的因果关系和时序逻辑,例如判断视频中某个动作的开始和结束时间,或分析特定时刻发生的事件 4 。
3.3 性能对比
与同类模型相比,Qwen3-VL-8B-Instruct在多项评测中表现优异:
|------------|----------------------|-----------------------|------------|
| 评测维度 | Qwen3-VL-8B-Instruct | Gemini 2.5 Flash Lite | GPT-5 Nano |
| GUI元素识别准确率 | 92.3% | 85.2% | 87.6% |
| 长视频理解能力 | 提升40% | 基准水平 | 提升25% |
| 图像细节捕捉精度 | 1024×1024像素级 | 512×512像素级 | 768×768像素级 |
| STEM推理能力 | 优秀 | 良好 | 中等 |
| 多模态任务综合表现 | 超越 | 基准 | 略逊 |
值得注意的是,在商汤日日新的空间智能基准测试中(VSI、MMSI、MindCube、ViewSpatial),Qwen3-VL-8B-Instruct的平均成绩为40.16,落后于商汤开源模型SenseNova-SI-8B(60.99)及国际闭源模型如GPT-5(49.68)和Gemini 2.5 Pro(48.81) 6 。这表明该模型在空间智能专项评测中表现相对局限,但在通用多模态任务中仍具有显著优势。
纯文本性能:
4. 应用场景与价值
4.1 工业质检
Qwen3-VL-8B-Instruct在汽车工业质检领域实现了革命性突破 1 。某头部车企将该模型部署于汽车组装线,实现对16个关键部件的同步检测。模型能自动识别螺栓缺失、导线松动等装配缺陷,检测速度达0.5秒/件,较人工提升10倍 1 。试运行半年节省返工成本2000万元,产品合格率提升8% 1 。
该模型的应用价值主要体现在: - 高效率 :0.5秒/件的检测速度远超人工,大幅提升生产效率 1 。 - 高精度 :91.3%的缺陷识别准确率超过普通质检人员水平 1 。 - 低成本 :相比传统机器视觉系统,该模型部署成本更低,且无需复杂的硬件改造 4 。
4.2 金融审核
中国工商银行基于Qwen3-VL-8B-Instruct开发了"商户智能审核助手",通过对商户提交的营业执照、经营场所照片等多模态信息进行智能分析,显著提升了审核效率 1 。
该模型使工行的商户审核效率提升60%,错误率降低45% 1 。通过多模态信息的综合分析,模型能够自动识别证件真伪、验证经营场所真实性,减少人工审核的工作量,同时提高审核的准确性和一致性。
4.3 医疗诊断
在医疗领域,Qwen3-VL-8B-Instruct被应用于肺部CT影像分析。模型能够自动识别0.5mm以上结节并判断良恶性,诊断准确率达91.3% 1 ,超过普通放射科医生水平。某三甲医院应用后,早期肺癌检出率提升37%,诊断报告生成时间从30分钟缩短至5分钟,效率提升83% 2 。
该模型在医疗诊断中的价值主要体现在: - 辅助诊断 :帮助医生快速识别潜在病变,提高诊断准确率。 - 报告生成 :自动完成诊断报告的撰写,大幅节省医生时间。 - 资源优化 :使基层医院也能获得接近专家水平的诊断支持。
4.4 智能零售
电商平台集成Qwen3-VL-8B-Instruct后,用户上传穿搭照片即可获得3套相似商品搭配方案。试运行期间商品点击率提升37%,客单价提高22% 1 ,实现了视觉理解与商业价值的直接转化。
该模型在零售领域的应用价值包括: - 个性化推荐 :基于用户上传的图片,提供更精准的商品推荐。 - 用户体验提升 :简化购物流程,实现"所见即所得"的购物体验。 - 转化率提高 :通过视觉引导,增加用户点击和购买意愿。
5. 部署方式与商业价值
5.1 部署方式
Qwen3-VL系列提供了从云端到边缘的全场景覆盖部署方案:
云端部署 :适合处理复杂多模态推理任务,如大规模数据分析、视频内容审核等。Qwen3-VL-235B-A22B(2350亿参数)和Qwen3-VL-30B-A3B(300亿参数混合专家模型)提供平衡性能与效率的选择 1 。
边缘部署 :适合资源受限场景,如智能终端、物联网设备等。Qwen3-VL-8B和Qwen3-VL-4B参数版本可在单张消费级显卡上运行,甚至支持智能终端设备 1 。
量化版本 :提供FP8量化技术,在保持接近BF16原模型性能的同时大幅降低部署成本 1 。8GB显存即可运行FP8量化版 4 ,使中小企业也能获得与科技巨头同等的技术能力。
5.2 商业价值
Qwen3-VL-8B-Instruct的商业价值主要体现在三个方面:
降低技术门槛 :通过轻量化和量化技术,该模型首次让消费级显卡也能运行工业级视觉AI 4 。企业无需投入大量资金购买高端GPU集群,即可部署多模态AI能力,大幅降低了技术应用门槛。
成本效益显著 :在实际应用中,该模型为企业带来了显著的经济效益。例如,某车企通过部署该模型,半年内节省返工成本2000万元 1 ;某三甲医院应用后,医生工作效率提升40%,早期病灶检出率提高17% 2 。
推动全场景应用 :该模型支持从云端复杂任务到边缘设备的本地化部署,覆盖金融、医疗、零售等多个行业 1 。通过提供不同参数规模和功能版本的模型,满足了企业多样化的需求,推动了多模态AI在各行业的普及应用。
6. 概述小结
通义千问3-VL-8B-Instruct作为一款轻量级视觉语言模型,通过架构创新实现了小参数模型的大能力表现,为多模态AI从"参数竞赛"向"效率优先"的战略转型提供了重要范例 4 。
该模型在多模态理解、长上下文处理和复杂推理方面均表现出色 1 ,尤其是在工业质检、金融审核、医疗诊断和智能零售等领域的应用价值显著。通过FP8量化技术,该模型在消费级硬件上的可行性得到了充分验证,为中小企业部署AI能力提供了新选择 4 。
未来,随着模型压缩和优化技术的进一步发展,Qwen3-VL系列有望在更多资源受限场景中发挥作用,如移动端、物联网设备等 。同时,该模型在空间智能等专项领域的表现仍有提升空间,未来可通过架构优化和专项训练进一步增强其综合能力。
Qwen3-VL-8B-Instruct的发布标志着大模型"小型化"趋势的又一进展 ,通过模型压缩和优化技术,在保持能力完整性的前提下实现参数量与计算成本的大幅削减,为视觉语言模型在更广泛场景的应用铺平了道路 。对于需要在本地部署或对推理成本敏感的企业用户而言,该模型提供了更具性价比的解决方案 。
参考来源:
1. Qwen3-VL-8B-Instruct:80亿参数开启多模态AI实用化新纪元-CSDN博客
2. 80亿参数改写多模态规则:Qwen3-VL如何让AI从"看懂"到"行动"-CSDN博客
3. Qwen3-VL-8B-Instruct:80亿参数开启多模态AI普惠时代-CSDN博客
4. 8GB显存跑千亿级视觉能力:Qwen3-VL-8B-Instruct-FP8如何引爆企业AI落地革命-CSDN博客