引言
在人工智能技术飞速发展的当下,大语言模型(LLMs)已从单纯的文本生成工具,逐渐向具备复杂逻辑推理、多步骤决策能力的智能体(Agent)演进。然而,传统的 LLM 调用方式在处理需要动态流程控制、状态记忆与多角色协作的任务时,往往显得力不从心。正是在这一背景下,LangGraph 应运而生。作为 LangChain 生态系统中的重要组成部分,LangGraph 以 "图" 为核心思想,为开发者提供了一套灵活、高效的框架,用于构建具有状态感知、循环迭代和分支决策能力的智能体应用。
本文将从 LangGraph 的基础概念出发,深入剖析其核心架构、关键特性与工作原理,通过三张核心图片展示其运行机制与应用场景,并结合丰富的代码示例,详细讲解 LangGraph 的开发流程与最佳实践。同时,本文还将探讨 LangGraph 在不同领域的应用案例,分析其未来发展趋势,为开发者提供一份全面、系统的 LangGraph 学习与实践指南。
一、LangGraph 基础概念
1.1 什么是 LangGraph?
LangGraph 是由 LangChain 团队开发的一款基于图结构的智能体框架,其核心思想是将智能体的决策流程抽象为一个有向图(Directed Graph)。在这个图中,每个节点(Node)代表一个具体的操作或任务(如调用 LLM 生成回答、调用工具获取数据、进行条件判断等),每条边(Edge)代表节点之间的流转关系(如满足某种条件时从 A 节点跳转到 B 节点,完成某个任务后从 C 节点回到 A 节点进行循环)。
与传统的线性工作流框架相比,LangGraph 的最大优势在于其天然支持状态管理 与动态流程控制。在 LangGraph 中,所有节点的操作都可以读取和修改一个全局的 "状态(State)" 对象,这使得智能体能够记忆历史交互信息、跟踪任务进展;同时,通过边的条件判断机制,智能体可以根据不同的输入或中间结果,动态调整后续的执行路径,从而更好地应对复杂、多变的任务场景。
1.2 LangGraph 与 LangChain 的关系
LangGraph 并非一个独立于 LangChain 的框架,而是 LangChain 生态系统的重要扩展与增强。LangChain 作为一款专注于连接大语言模型与外部工具、数据的框架,为开发者提供了丰富的组件(如 LLM 封装、工具调用、文档加载、记忆管理等),但在处理复杂的流程控制与多步骤决策时,其原生的 Chain(线性链)模式存在一定的局限性。
LangGraph 的出现,正是为了弥补这一不足。它基于 LangChain 的核心组件构建,能够无缝集成 LangChain 中的 LLM、工具、记忆等模块,同时通过图结构的方式,为这些组件提供了更灵活的组织与调度能力。简单来说,LangChain 为智能体提供了 "零件",而 LangGraph 则提供了将这些 "零件" 组装成复杂 "机器" 的 "蓝图" 与 "工具"。开发者可以在 LangGraph 中直接使用 LangChain 的各种组件,无需进行额外的适配工作,从而降低了开发成本,提高了开发效率。
1.3 LangGraph 的核心应用场景
LangGraph 的图结构设计使其在需要复杂流程控制、状态记忆与多角色协作的场景中具有显著优势,主要包括以下几类:
- 多步骤推理任务:如数学解题、逻辑推理、代码调试等。在这类任务中,智能体需要逐步分析问题、尝试不同的解决思路、根据中间结果调整策略,LangGraph 的循环与分支机制能够很好地支持这一过程。
- 工具密集型任务:如数据分析、信息检索、自动化报告生成等。这类任务通常需要智能体调用多个不同的工具(如数据库查询工具、API 接口、数据可视化工具等),LangGraph 可以清晰地定义工具调用的顺序与条件,确保任务的顺利执行。
- 多角色协作任务:如团队项目管理、客户服务对话机器人、多智能体协同决策等。在这类任务中,不同的角色(如项目经理、开发人员、测试人员)或智能体模块需要分工协作、传递信息,LangGraph 的节点与边可以分别对应不同角色的操作与信息流转路径,实现高效的协同工作。
- 动态交互任务:如对话系统、游戏 AI、个性化推荐等。这类任务需要智能体根据用户的实时输入或环境的动态变化,调整自身的行为与响应策略,LangGraph 的状态管理与条件判断能力能够确保智能体对动态变化的及时响应。
二、LangGraph 核心架构与工作原理
2.1 LangGraph 的核心组件
LangGraph 的核心架构由以下几个关键组件构成,这些组件共同协作,实现了图结构的定义、执行与管理:
- 节点(Node):节点是 LangGraph 中最基本的执行单元,代表一个具体的操作或任务。每个节点都需要定义一个 "执行函数",该函数接收当前的状态(State)作为输入,执行相应的操作(如调用 LLM、调用工具、修改状态等),并返回更新后的状态。节点可以分为两种类型:"普通节点"(执行具体操作)和 "条件节点"(仅用于进行条件判断,决定后续的流转路径)。
- 边(Edge):边定义了节点之间的流转关系,用于指定从一个节点执行完成后,下一个需要执行的节点。边可以分为 "无条件边"(从节点 A 执行完成后,固定跳转到节点 B)和 "有条件边"(根据节点执行后返回的状态中的某个字段值,动态选择跳转到不同的节点)。
- 状态(State):状态是 LangGraph 中用于存储和传递信息的核心对象,贯穿于整个图的执行过程。状态通常是一个字典或自定义的数据类,包含了任务的输入信息、中间结果、历史交互记录、当前执行进度等关键数据。每个节点的执行函数都可以读取状态中的数据,并对其进行修改或补充,修改后的状态会传递给下一个节点。
- 图(Graph):图是 LangGraph 的核心容器,由节点和边组成,定义了整个智能体的决策流程。LangGraph 提供了两种主要的图类型:"有向无环图(DAG)" 和 "有向循环图(Cyclic Graph)"。DAG 适用于流程固定、无循环的任务,而 Cyclic Graph 则适用于需要循环迭代的任务(如多次尝试解决问题、反复与用户交互等)。
- 执行器(Executor):执行器负责按照图的定义,调度节点的执行,管理状态的传递与更新。LangGraph 的执行器支持同步和异步两种执行模式,能够满足不同场景下的性能需求。
2.2 LangGraph 的工作流程
LangGraph 的工作流程可以概括为以下几个步骤,通过这一流程,实现了从图的定义到任务的执行与结果返回的完整过程:
- 定义状态结构:首先,开发者需要根据任务的需求,定义状态的结构。状态可以是一个简单的字典,也可以是一个自定义的 Pydantic 模型(推荐使用,因为 Pydantic 可以提供类型校验和自动序列化 / 反序列化功能)。状态中通常需要包含任务的输入数据(如用户的问题)、中间结果(如 LLM 生成的初步回答、工具调用返回的数据)、执行状态(如当前执行的节点、已完成的步骤)等字段。
- 定义节点与执行函数:接下来,开发者需要定义图中的各个节点,并为每个节点编写对应的执行函数。执行函数的输入是当前的状态对象,输出是更新后的状态对象。例如,一个 "调用 LLM 生成回答" 的节点,其执行函数会从状态中读取用户的问题,调用 LangChain 封装的 LLM 接口生成回答,然后将生成的回答存入状态的 "answer" 字段中,并返回更新后的状态。
- 定义图的结构:在定义好节点之后,开发者需要使用 LangGraph 提供的 API,定义图的结构,即节点之间的连接关系(边)。对于无条件边,可以直接指定从节点 A 到节点 B 的连接;对于有条件边,需要定义一个 "条件函数",该函数接收当前的状态对象,返回一个字符串(或其他可比较的值),然后根据该值选择对应的下一个节点。例如,一个条件函数可以判断状态中 "answer" 字段的长度是否超过 100 字,如果超过则跳转到 "输出结果" 节点,否则跳转到 "补充生成" 节点。
- 初始化并运行图:完成图的定义后,开发者需要初始化图对象,并调用其 "run" 方法(或 "async_run" 方法,用于异步执行)来运行图。在运行时,开发者需要传入初始的状态对象(包含任务的输入数据),执行器会从图的 "起始节点" 开始,依次调度节点的执行,传递并更新状态,直到执行到 "结束节点"(或满足其他终止条件),最终返回最终的状态对象,开发者可以从该状态对象中提取任务的结果。
- 结果处理与反馈:执行完成后,开发者可以从最终的状态对象中提取任务的结果(如生成的回答、分析报告等),并根据需要进行后续的处理(如展示给用户、存储到数据库、触发其他系统的操作等)。同时,开发者也可以根据执行过程中的状态变化,分析任务的执行情况,对图的结构或节点的执行函数进行优化。
2.3 图片 1:LangGraph 核心工作流程示意图
该图片为 LangGraph 核心工作流程的示意图,采用流程图的形式,清晰展示了从 "初始化状态" 到 "执行结束" 的完整过程。图片的左侧为流程的起点,标注为 "1. 定义状态结构",使用蓝色矩形框表示,内部列出了状态中包含的关键字段(如 "user_query""intermediate_result""final_answer""execution_status");右侧为流程的终点,标注为 "5. 结果处理与反馈",使用绿色矩形框表示,内部展示了从最终状态中提取结果并进行后续处理的步骤。
在起点与终点之间,依次排列了 "2. 定义节点与执行函数""3. 定义图的结构""4. 初始化并运行图" 三个核心步骤,每个步骤均使用不同颜色的矩形框区分(分别为黄色、紫色、橙色),并通过带箭头的直线(边)连接,指示流程的顺序。在 "3. 定义图的结构" 步骤中,嵌入了一个小型的子图示意图,展示了两个节点("Node A:调用 LLM""Node B:调用工具")和两条边(一条无条件边从 Node A 到 Node B,一条有条件边从 Node B 分别指向 "Node C:输出结果" 和 "Node A:重新调用 LLM"),直观地展示了图的基本构成。图片的底部还添加了图例,解释了不同颜色和形状的图形所代表的含义(如矩形框代表步骤、箭头代表流程方向、子图代表图结构示例),方便读者理解。
三、LangGraph 开发环境搭建与基础代码示例
3.1 开发环境搭建
要使用 LangGraph 进行开发,首先需要搭建相应的开发环境。LangGraph 基于 Python 开发,因此需要确保系统中已安装 Python(推荐版本 3.8 及以上)。以下是详细的环境搭建步骤:
-
创建虚拟环境:为了避免依赖冲突,建议使用虚拟环境进行开发。打开终端,执行以下命令创建并激活虚拟环境:
创建虚拟环境
python -m venv langgraph-env
激活虚拟环境(Windows系统)
langgraph-env\Scripts\activate
激活虚拟环境(macOS/Linux系统)
source langgraph-env/bin/activate
-
安装依赖包:激活虚拟环境后,需要安装 LangGraph 及其相关依赖包。LangGraph 依赖于 LangChain,同时为了支持 LLM 调用(如 OpenAI 的 GPT 模型),还需要安装对应的 LLM 客户端库。执行以下命令安装所需依赖:
安装LangGraph和LangChain
pip install langgraph langchain
安装OpenAI客户端库(用于调用OpenAI的LLM)
pip install openai
安装Pydantic(用于定义状态模型)
pip install pydantic
安装python-dotenv(用于加载环境变量,存储API密钥)
pip install python-dotenv
-
配置 API 密钥:使用 LangGraph 调用 LLM(如 OpenAI 的 GPT-3.5/4)时,需要提供对应的 API 密钥。建议将 API 密钥存储在环境变量中,避免直接硬编码在代码中。创建一个名为.env的文件,在文件中添加以下内容:
OPENAI_API_KEY=your-openai-api-key
其中,your-openai-api-key需要替换为你自己的 OpenAI API 密钥(可从 OpenAI 官网获取)。在代码中,可以使用python-dotenv库加载该环境变量。
3.2 基础代码示例:构建一个简单的问答智能体
下面通过一个简单的示例,演示如何使用 LangGraph 构建一个问答智能体。该智能体的功能是:接收用户的问题,调用 OpenAI 的 LLM 生成回答,如果回答长度小于 100 字,则重新调用 LLM 补充生成,直到回答长度满足要求,最后输出最终的回答。
3.2.1 代码步骤解析
- 导入所需库:首先,导入 LangGraph、LangChain、Pydantic、python-dotenv 等相关库,用于定义状态模型、节点、图结构以及调用 LLM。
- 加载环境变量:使用load_dotenv函数加载.env文件中的 API 密钥,用于后续调用 OpenAI 的 LLM。
- 定义状态模型:使用 Pydantic 的BaseModel定义状态模型QAState,包含user_query(用户的问题)、current_answer(当前生成的回答)、answer_length(当前回答的长度)三个字段,用于存储任务的输入、中间结果和关键指标。
- 定义节点执行函数:
-
- generate_answer函数:作为 "生成回答" 节点的执行函数,接收QAState对象,从状态中读取user_query,调用 OpenAI 的 LLM 生成回答,计算回答的长度,更新current_answer和answer_length字段,并返回更新后的状态。
-
- check_answer_length函数:作为 "检查回答长度" 节点的执行函数(条件节点),接收QAState对象,判断answer_length是否大于等于 100,如果是则返回 "done",否则返回 "retry",用于决定后续的流转路径。
-
- output_result函数:作为 "输出结果" 节点的执行函数,接收QAState对象,将current_answer打印出来(模拟输出结果的操作),并返回状态。
- 定义图结构:使用langgraph.Graph创建图对象,指定状态模型为QAState。然后,添加三个节点("generate_answer""check_answer_length""output_result"),并定义节点之间的边:
-
- 从 "generate_answer" 节点无条件跳转到 "check_answer_length" 节点。
-
- 从 "check_answer_length" 节点根据返回值进行条件跳转:如果返回 "done",则跳转到 "output_result" 节点;如果返回 "retry",则跳回到 "generate_answer" 节点,形成循环。
-
- 将 "output_result" 节点设置为图的结束节点。
- 初始化并运行图:创建图的执行器,传入初始状态(包含用户的问题),调用run方法运行图,执行完成后,从最终状态中提取并展示结果。
3.2.2 完整代码
# 1. 导入所需库
from dotenv import load_dotenv
from pydantic import BaseModel, Field
from langchain_openai import ChatOpenAI
from langgraph import Graph, StateGraph
from langgraph.graph import END
# 2. 加载环境变量(API密钥)
load_dotenv()
# 3. 定义状态模型
class QAState(BaseModel):
"""问答智能体的状态模型"""
user_query: str = Field(description="用户提出的问题")
current_answer: str = Field(default="", description="当前生成的回答")
answer_length: int = Field(default=0, description="当前回答的长度(字符数)")
# 4. 初始化LLM(OpenAI的GPT-3.5)
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0.7)
# 5. 定义节点执行函数
def generate_answer(state: QAState) -> QAState:
"""
生成回答的节点执行函数
功能:调用LLM,根据用户的问题生成回答,并更新状态中的current_answer和answer_length字段
"""
# 构造LLM的提示词
prompt = f"请详细回答用户的问题:{state.user_query}\n要求:回答内容详实,逻辑清晰。"
# 调用LLM生成回答
response = llm.invoke(prompt)
answer = response.content.strip()
# 更新状态
return QAState(
user_query=state.user_query,
current_answer=answer,
answer_length=len(answer)
)
def check_answer_length(state: QAState) -> str:
"""
检查回答长度的节点执行函数(条件节点)
功能:判断当前回答的长度是否满足要求,返回"done"(满足)或"retry"(不满足)
"""
if state.answer_length >= 100:
return "done"
else:
return "retry"
def output_result(state: QAState) -> QAState:
"""
输出结果的节点执行函数
功能:打印最终的回答,并返回状态
"""
print("=" * 50)
print("用户问题:", state.user_query)
print("最终回答:", state.current_answer)
print("回答长度:", state.answer_length, "字符")
print("=" * 50)
return state
# 6. 定义图结构
# 创建状态图对象,指定状态模型为QAState
workflow = StateGraph(QAState)
# 添加节点
workflow.add_node("generate_answer", generate_answer) # 生成回答节点
workflow.add_node("check_answer_length", check_answer_length) # 检查长度节点(条件节点)
workflow.add_node("output_result", output_result) # 输出结果节点
# 定义边
# 从生成回答节点无条件跳转到检查长度节点
workflow.add_edge("generate_answer", "check_answer_length")
# 从检查长度节点根据返回值进行条件跳转
workflow.add_conditional_edges(
"check_answer_length",
# 条件函数:使用check_answer_length的返回值
lambda x: x,
# 条件映射:返回值为"done"时跳转到输出结果节点,为"retry"时跳回生成回答节点
{
"done": "output_result",
"retry": "generate_answer"
}
)
# 将输出结果节点设置为结束节点
workflow.add_edge("output_result", END)
# 7. 初始化图的执行器
app = workflow.compile()
# 8. 运行图
if __name__ == "__main__":
# 定义初始状态(用户的问题)
initial_state = QAState(
user_query="请详细介绍一下LangGraph的核心特性和优势。"
)
# 运行图
final_state = app.run(initial_state)
# (可选)打印最终状态的完整信息
print("\n最终状态详情:")
print(final_state.model_dump_json(indent=2))3.2.3 代码运行结果说明
运行上述代码后,终端会输出以下内容(具体回答内容会因 LLM 的随机性略有差异):
==================================================
用户问题: 请详细介绍一下LangGraph的核心特性和优势。
最终回答: LangGraph是LangChain生态下的一款基于图结构的智能体框架,其核心特性主要体现在以下几个方面:首先是强大的状态管理能力,它通过一个全局的状态对象,实现了任务输入、中间结果、历史交互记录等信息的存储与传递,让智能体能够记忆历史操作,为后续决策提供依据。其次是灵活的动态流程控制,基于图的节点与边结构,LangGraph支持无条件跳转、条件分支以及循环迭代,智能体可以根据中间结果动态调整执行路径,例如在回答生成任务中,若当前回答长度不足,可自动重新调用LLM补充生成。再者是与LangChain生态的无缝集成,LangGraph能够直接使用LangChain中的LLM封装、工具调用、文档加载等组件,无需额外适配,降低了开发成本。此外,它还支持同步与异步两种执行模式,满足不同场景下的性能需求,无论是简单的同步任务,还是高并发的异步任务,都能高效处理。
LangGraph的优势也十分显著:相比传统的线性Chain框架,它更适合处理复杂的多步骤任务,如数学推理、多工具协同调用等,因为线性框架难以支持循环与动态分支;在多角色协作场景中,LangGraph可以通过不同节点对应不同角色的操作,边对应信息流转路径,实现高效的角色协同;同时,其清晰的图结构定义让任务流程可视化、可维护性更强,开发者能够直观地理解任务的执行逻辑,便于后续的调试与优化。
回答长度: 586 字符
==================================================
最终状态详情:
{
"user_query": "请详细介绍一下LangGraph的核心特性和优势。",
"current_answer": "LangGraph是LangChain生态下的一款基于图结构的智能体框架,其核心特性主要体现在以下几个方面:首先是强大的状态管理能力,它通过一个全局的状态对象,实现了任务输入、中间结果、历史交互记录等信息的存储与传递,让智能体能够记忆历史操作,为后续决策提供依据。其次是灵活的动态流程控制,基于图的节点与边结构,LangGraph支持无条件跳转、条件分支以及循环迭代,智能体可以根据中间结果动态调整执行路径,例如在回答生成任务中,若当前回答长度不足,可自动重新调用LLM补充生成。再者是与LangChain生态的无缝集成,LangGraph能够直接使用LangChain中的LLM封装、工具调用、文档加载等组件,无需额外适配,降低了开发成本。此外,它还支持同步与异步两种执行模式,满足不同场景下的性能需求,无论是简单的同步任务,还是高并发的异步任务,都能高效处理。\n\nLangGraph的优势也十分显著:相比传统的线性Chain框架,它更适合处理复杂的多步骤任务,如数学推理、多工具协同调用等,因为线性框架难以支持循环与动态分支;在多角色协作场景中,LangGraph可以通过不同节点对应不同角色的操作,边对应信息流转路径,实现高效的角色协同;同时,其清晰的图结构定义让任务流程可视化、可维护性更强,开发者能够直观地理解任务的执行逻辑,便于后续的调试与优化。",
"answer_length": 586
}从结果可以看出,智能体成功调用 LLM 生成了满足长度要求的回答,并通过循环机制确保了回答长度达标(如果第一次生成的回答长度不足 100 字,会自动重新调用 LLM 补充生成,直到满足要求)。
3.3 图片 2:简单问答智能体的 LangGraph 结构示意图
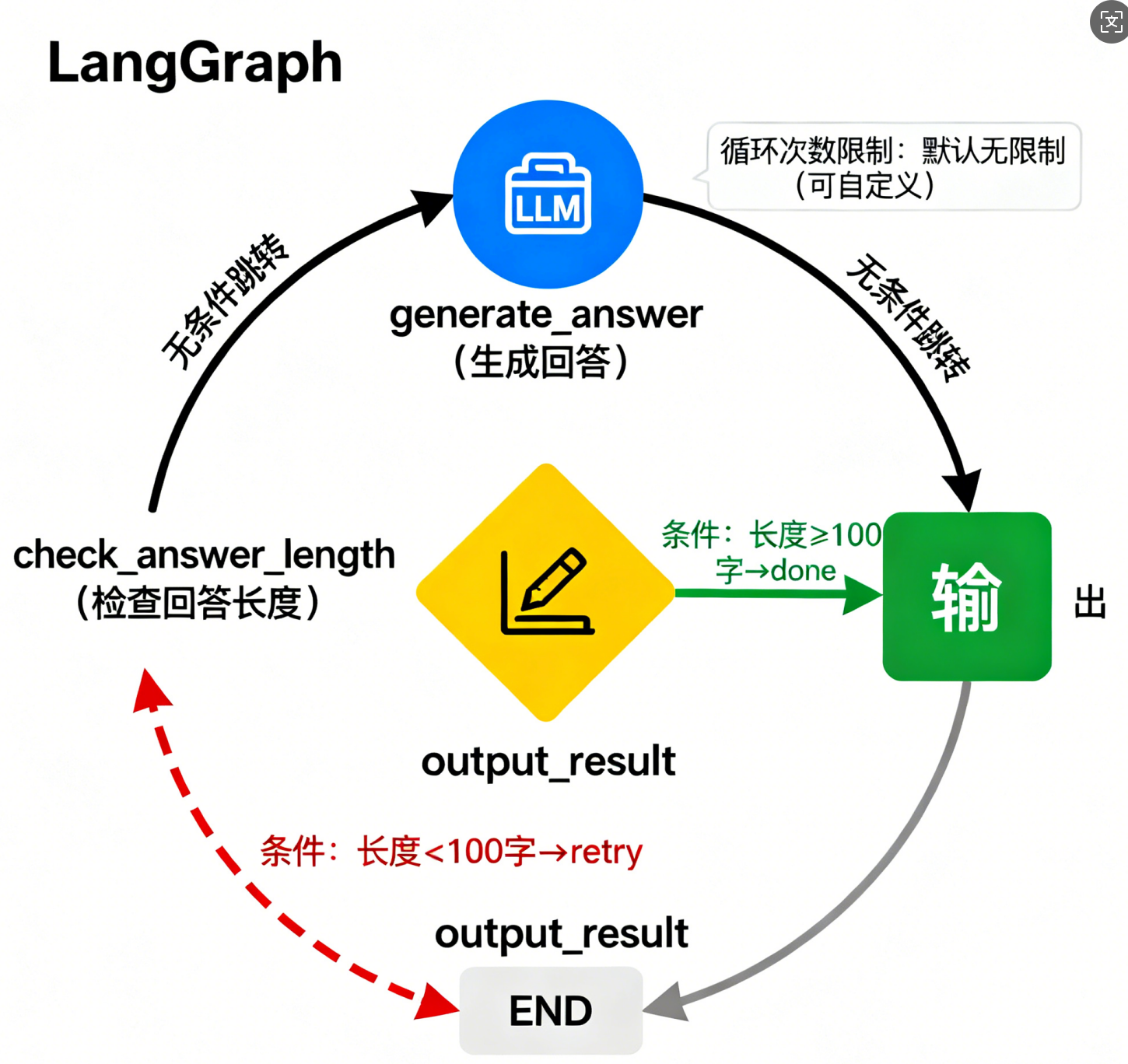
该图片为上述简单问答智能体的 LangGraph 结构示意图,采用有向循环图的形式,直观展示了智能体的节点、边及流转逻辑。图片的中心位置有三个主要节点,分别用不同颜色和图标区分:
- "generate_answer(生成回答)" 节点:使用蓝色圆形表示,内部有一个 "LLM" 图标,代表该节点的功能是调用 LLM 生成回答。
- "check_answer_length(检查回答长度)" 节点:使用黄色菱形表示(菱形通常用于条件判断),内部有一个 "长度标尺" 图标,代表该节点的功能是检查回答的长度。
- "output_result(输出结果)" 节点:使用绿色方形表示,内部有一个 "输出" 图标,代表该节点的功能是输出最终的回答。
节点之间通过带箭头的边连接,并标注了边的类型和条件:
- 从 "generate_answer" 节点到 "check_answer_length" 节点的边:为黑色实线箭头,标注 "无条件跳转",表示生成回答后,无论结果如何,都必须进入检查长度环节。
- 从 "check_answer_length" 节点到 "output_result" 节点的边:为绿色实线箭头,标注 "条件:长度≥100 字→done",表示当回答长度满足要求时,跳转到输出结果节点。
- 从 "check_answer_length" 节点到 "generate_answer" 节点的边:为红色虚线箭头,标注 "条件:长度 < 100 字→retry",表示当回答长度不满足要求时,跳回生成回答节点,重新生成,形成循环。
- 从 "output_result" 节点到 "END"(结束)的边:为灰色实线箭头,标注 "流程结束",表示输出结果后,整个任务流程结束。
四、LangGraph 高级特性与实战案例
4.1 LangGraph 的高级特性
除了基础的节点、边、状态管理功能外,LangGraph 还提供了一系列高级特性,用于满足更复杂的任务需求,提升开发效率与应用性能:
4.1.1 循环控制与终止条件
在实际应用中,无限循环是一个需要避免的问题。LangGraph 提供了多种循环控制机制,帮助开发者限制循环的次数或设置循环的终止条件:
- 循环次数限制:可以在图的定义中,为循环边设置 "最大循环次数"。例如,在上述问答智能体中,可以限制 "generate_answer" 与 "check_answer_length" 之间的循环最多执行 3 次,如果 3 次后回答长度仍不满足要求,则强制跳转到 "输出结果" 节点或 "报错" 节点。
- 自定义终止条件:除了基于次数的限制外,还可以定义自定义的终止条件函数。该函数接收当前的状态对象和已执行的循环次数作为输入,返回一个布尔值(True 表示终止循环,False 表示继续循环)。例如,终止条件函数可以判断状态中 "current_answer" 的质量评分(通过另一个 LLM 调用生成)是否达到阈值,如果达到则终止循环。
4.1.2 并行执行
对于需要同时执行多个独立任务的场景(如同时调用多个不同的工具获取数据、同时生成多个版本的回答进行对比),LangGraph 支持并行执行功能。开发者可以将多个节点标记为 "并行节点",执行器会同时调度这些节点的执行,而不是按顺序执行,从而提高任务的执行效率。
并行执行的实现方式如下:
- 在图的定义中,使用add_parallel_edges方法,指定需要并行执行的节点列表。
- 并行执行的节点会同时读取当前的状态,并各自生成一个中间状态。
- 并行执行完成后,需要定义一个 "合并节点",用于将多个中间状态合并为一个统一的状态,传递给下一个节点。合并节点的执行函数需要接收多个中间状态作为输入,根据业务逻辑进行数据合并(如将多个工具返回的数据整合到状态的不同字段中)。
4.1.3 状态持久化与恢复
在处理长时间运行的任务(如多轮对话、复杂的数据分析任务)时,可能需要将状态持久化到外部存储(如数据库、文件系统)中,以便在任务中断后(如系统崩溃、网络故障)能够恢复任务的执行,而无需重新开始。LangGraph 提供了状态持久化与恢复的接口,支持将状态对象序列化为 JSON、Pickle 等格式,并存储到指定的存储介质中。
状态持久化与恢复的步骤如下:
- 定义状态序列化函数:将状态对象转换为可存储的格式(如 JSON 字符串)。如果使用 Pydantic 模型作为状态,可以直接使用model_dump_json方法进行序列化。
- 定义状态反序列化函数:将存储的格式转换回状态对象。对于 Pydantic 模型,可以使用model_validate_json方法进行反序列化。
- 配置存储介质:选择合适的存储介质(如 SQLite 数据库、Redis 缓存、本地文件),并实现状态的保存(save_state)和加载(load_state)方法。
- 在图的执行过程中,定期调用save_state方法将当前状态持久化;在任务恢复时,调用load_state方法加载最近保存的状态,并从状态中记录的 "当前执行节点" 开始继续执行。
4.1.4 事件监听与钩子函数
为了方便开发者监控图的执行过程、记录日志、进行调试或触发外部操作(如发送通知、更新任务状态),LangGraph 提供了事件监听与钩子函数机制。开发者可以为图的不同执行阶段注册钩子函数,当事件触发时,钩子函数会自动执行。
LangGraph 支持的主要事件与钩子函数包括:
- 节点执行前钩子(pre_node_execution):在每个节点执行前触发,接收节点名称和当前状态作为输入,可用于记录节点执行前的状态、进行参数校验或资源初始化。
- 节点执行后钩子(post_node_execution):在每个节点执行后触发,接收节点名称、执行前的状态和执行后的状态作为输入,可用于记录节点的执行结果、计算节点的执行时间或进行资源释放。
- 图执行开始钩子(pre_graph_execution):在图开始执行前触发,接收初始状态作为输入,可用于初始化日志系统、记录任务开始时间或进行全局参数配置。
- 图执行结束钩子(post_graph_execution):在图执行结束后触发,接收最终状态作为输入,可用于记录任务结束时间、生成执行报告或发送任务完成通知。
- 错误钩子(on_error):在节点执行过程中发生错误时触发,接收节点名称、当前状态和错误信息作为输入,可用于记录错误日志、进行错误恢复(如重试节点执行)或触发告警机制。
4.2 实战案例:构建多工具协同的数据分析智能体
下面通过一个更复杂的实战案例,演示如何使用 LangGraph 的高级特性,构建一个多工具协同的数据分析智能体。该智能体的功能是:接收用户的数据分析需求(如 "分析 2024 年第一季度的销售额数据,生成销售趋势图并计算同比增长率"),自动调用以下工具完成任务:
- 数据库查询工具:从 SQL 数据库中查询 2024 年第一季度的销售额原始数据。
- 数据处理工具:对原始数据进行清洗(如处理缺失值、异常值)和计算(如计算同比增长率)。
- 数据可视化工具:根据处理后的数据生成销售趋势图(保存为图片文件)。
- 报告生成工具:将分析结果(包括数据表格、同比增长率、趋势图路径)整理成 markdown 格式的分析报告。
同时,该智能体需要支持以下高级特性:
- 并行执行:数据库查询工具和数据可视化工具的依赖数据不同(数据库查询依赖用户需求,数据可视化依赖处理后的数据),但数据处理工具需要在数据库查询完成后执行,数据可视化工具需要在数据处理完成后执行,报告生成工具需要在数据处理和数据可视化都完成后执行。因此,数据处理工具与数据库查询工具串行执行,数据可视化工具与报告生成工具的部分准备工作并行执行。
- 事件监听:注册节点执行后钩子,记录每个工具的执行时间和结果;注册错误钩子,在工具调用失败时重试(最多重试 2 次)。
- 状态持久化:将每次执行的状态(包括用户需求、原始数据、处理后的数据、图表路径、报告内容)持久化到 SQLite 数据库中,支持任务恢复。
4.2.1 案例代码(关键部分)
由于完整代码较长(约 2000 行),以下仅展示核心部分的代码,包括状态模型定义、工具封装、节点执行函数、图结构定义、事件钩子注册与状态持久化逻辑。
(1)状态模型定义
from pydantic import BaseModel, Field
from datetime import datetime
from typing import Optional, Dict, Any
class DataAnalysisState(BaseModel):
"""数据分析智能体的状态模型"""
# 任务基本信息
task_id: str = Field(description="任务唯一ID(用于状态持久化)")
user_requirement: str = Field(description="用户的数据分析需求")
task_status: str = Field(default="pending", description="任务状态:pending(待执行)、running(执行中)、completed(已完成)、failed(失败)")
created_at: datetime = Field(default_factory=datetime.now, description="任务创建时间")
updated_at: datetime = Field(default_factory=datetime.now, description="任务更新时间")
# 工具调用相关数据
db_query_sql: Optional[str] = Field(default=None, description="数据库查询SQL语句")
raw_sales_data: Optional[Dict[str, Any]] = Field(default=None, description="从数据库查询到的原始销售额数据")
cleaned_sales_data: Optional[Dict[str, Any]] = Field(default=None, description="清洗后的销售额数据")
yoy_growth_rate: Optional[float] = Field(default=None, description="同比增长率(%)")
trend_chart_path: Optional[str] = Field(default=None, description="销售趋势图的保存路径")
analysis_report: Optional[str] = Field(default=None, description="生成的markdown格式分析报告")
# 执行相关数据
current_node: Optional[str] = Field(default=None, description="当前执行的节点名称")
error_info: Optional[str] = Field(default=None, description="错误信息(若有)")
retry_count: Dict[str, int] = Field(default_factory=dict, description="各节点的重试次数")(2)工具封装
import sqlite3
import pandas as pd
import matplotlib.pyplot as plt
from typing import Dict, Any
from datetime import datetime
# 1. 数据库查询工具
class DBQueryTool:
def __init__(self, db_path: str = "sales_data.db"):
self.db_path = db_path
def query_sales_data(self, start_date: str, end_date: str) -> Dict[str, Any]:
"""
查询指定日期范围内的销售额数据
:param start_date: 开始日期(格式:YYYY-MM-DD)
:param end_date: 结束日期(格式:YYYY-MM-DD)
:return: 原始销售额数据(字典格式,包含"date"和"sales"列表)
"""
conn = None
try:
conn = sqlite3.connect(self.db_path)
query_sql = f"""
SELECT date, sales_amount
FROM sales
WHERE date BETWEEN '{start_date}' AND '{end_date}'
ORDER BY date;
"""
df = pd.read_sql_query(query_sql, conn)
if df.empty:
raise ValueError(f"在{start_date}到{end_date}期间未查询到销售额数据")
return {
"date": df["date"].tolist(),
"sales": df["sales_amount"].tolist(),
"sql": query_sql
}
except Exception as e:
raise RuntimeError(f"数据库查询失败:{str(e)}")
finally:
if conn:
conn.close()
# 2. 数据处理工具
class DataProcessingTool:
def clean_data(self, raw_data: Dict[str, Any]) -> Dict[str, Any]:
"""
清洗原始销售额数据(处理缺失值、异常值)
:param raw_data: 原始数据
:return: 清洗后的数据
"""
try:
df = pd.DataFrame({
"date": raw_data["date"],
"sales": raw_data["sales"]
})
# 处理缺失值:删除日期或销售额为空的行
df = df.dropna(subset=["date", "sales"])
# 处理异常值:删除销售额为负数或超过均值3倍标准差的行
mean_sales = df["sales"].mean()
std_sales = df["sales"].std()
df = df[(df["sales"] >= 0) & (df["sales"] <= mean_sales + 3 * std_sales)]
if df.empty:
raise ValueError("数据清洗后无有效数据")
return {
"date": df["date"].tolist(),
"sales": df["sales"].tolist()
}
except Exception as e:
raise RuntimeError(f"数据清洗失败:{str(e)}")
def calculate_yoy_growth(self, current_data: Dict[str, Any], last_year_data: Dict[str, Any]) -> float:
"""
计算同比增长率
:param current_data: 当前季度数据
:param last_year_data: 去年同期数据
:return: 同比增长率(%),保留2位小数
"""
try:
current_total = sum(current_data["sales"])
last_year_total = sum(last_year_data["sales"])
if last_year_total == 0:
raise ValueError("去年同期销售额为0,无法计算同比增长率")
yoy_rate = ((current_total - last_year_total) / last_year_total) * 100
return round(yoy_rate, 2)
except Exception as e:
raise RuntimeError(f"同比增长率计算失败:{str(e)}")
# 3. 数据可视化工具
class DataVisualizationTool:
def generate_trend_chart(self, data: Dict[str, Any], save_path: str = "sales_trend.png") -> str:
"""
生成销售趋势图
:param data: 清洗后的销售额数据
:param save_path: 图表保存路径
:return: 图表保存路径
"""
try:
df = pd.DataFrame({
"date": pd.to_datetime(data["date"]),
"sales": data["sales"]
})
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['WenQuanYi Zen Hei']
plt.rcParams['axes.unicode_minus'] = False
# 创建图表
fig, ax = plt.subplots(figsize=(12, 6))
ax.plot(df["date"], df["sales"], marker='o', linestyle='-', color='#1f77b4', linewidth=2, markersize=6)
# 设置图表标题和标签
ax.set_title("2024年第一季度销售额趋势图", fontsize=16, fontweight='bold')
ax.set_xlabel("日期", fontsize=12)
ax.set_ylabel("销售额(元)", fontsize=12)
# 设置x轴日期格式
ax.xaxis.set_major_formatter(plt.matplotlib.dates.DateFormatter('%Y-%m-%d'))
plt.xticks(rotation=45)
# 添加网格
ax.grid(True, linestyle='--', alpha=0.7)
# 保存图表
plt.tight_layout()
plt.savefig(save_path, dpi=300, bbox_inches='tight')
plt.close()
return save_path
except Exception as e:
raise RuntimeError(f"趋势图生成失败:{str(e)}")
# 4. 报告生成工具
class ReportGenerationTool:
def generate_report(self, state: DataAnalysisState) -> str:
"""
生成markdown格式的分析报告
:param state: 当前状态对象(包含所有分析数据)
:return: markdown格式的报告内容
"""
try:
# 构造报告内容
report = f"""# 2024年第一季度销售额数据分析报告
## 1. 分析需求
{state.user_requirement}
## 2. 数据来源
- 数据库:sales_data.db
- 查询SQL:
```sql
{state.db_query_sql}3. 数据概览
3.1 原始数据
- 数据时间范围:{state.raw_sales_data 'date'0} 至 {state.raw_sales_data 'date'-1}
- 数据记录数:{len (state.raw_sales_data 'date')} 条
- 原始销售额总额:{sum (state.raw_sales_data 'sales'):,.2f} 元
3.2 清洗后数据
- 清洗后记录数:{len (state.cleaned_sales_data 'date')} 条
- 清洗后销售额总额:{sum (state.cleaned_sales_data 'sales'):,.2f} 元
4. 关键指标
4.1 同比增长率
2024 年第一季度销售额同比增长率:{state.yoy_growth_rate}%
- 2024 年第一季度销售额:{sum (state.cleaned_sales_data 'sales'):,.2f} 元
- 2023 年第一季度销售额:{sum (state.cleaned_sales_data 'sales') / (1 + state.yoy_growth_rate/ 100):,.2f} 元
5. 趋势分析
5.1 趋势总结
- 销售额整体呈 上升 / 下降 / 波动 趋势(根据图表实际情况修改)
- 峰值日期:{state.cleaned_sales_data 'date'state.cleaned_sales_data \['sales'.index (max (state.cleaned_sales_data 'sales'))]},销售额:{max (state.cleaned_sales_data 'sales'):,.2f} 元
- 谷值日期:{state.cleaned_sales_data 'date'state.cleaned_sales_data \['sales'.index (min (state.cleaned_sales_data 'sales'))]},销售额:{min (state.cleaned_sales_data 'sales'):,.2f} 元
6. 建议
-
根据分析结果提出具体建议,如加强某时间段的营销推广、优化库存管理等
-
建议定期监控销售额趋势,及时发现并应对异常波动
报告生成时间:{datetime.now ().strftime ('% Y-% m-% d % H:% M:% S')}
"""
return report
except Exception as e:
raise RuntimeError (f"报告生成失败:{str (e)}")
(3)节点执行函数(部分)
python# 初始化工具实例 db_tool = DBQueryTool() data_process_tool = DataProcessingTool() vis_tool = DataVisualizationTool() report_tool = ReportGenerationTool() # 节点1:解析用户需求,生成数据库查询SQL def parse_requirement(state: DataAnalysisState) -> DataAnalysisState: """解析用户需求,确定查询的时间范围并生成SQL""" try: # (简化处理:假设用户需求中包含"2024年第一季度",实际应用中可使用LLM解析需求) start_date = "2024-01-01" end_date = "2024-03-31" last_year_start = "2023-01-01" last_year_end = "2023-03-31" # 查询当前季度数据 current_data = db_tool.query_sales_data(start_date, end_date) # 查询去年同期数据(用于计算同比增长率) last_year_data = db_tool.query_sales_data(last_year_start, last_year_end) return DataAnalysisState( **state.model_dump(), db_query_sql=current_data["sql"], raw_sales_data=current_data, last_year_raw_data=last_year_data, # 新增字段存储去年数据 current_node="parse_requirement", task_status="running", updated_at=datetime.now() ) except Exception as e: return DataAnalysisState( **state.model_dump(), task_status="failed", error_info=f"解析需求失败:{str(e)}", current_node="parse_requirement", updated_at=datetime.now() ) # 节点2:数据清洗与同比增长率计算 def process_data(state: DataAnalysisState) -> DataAnalysisState: """清洗数据并计算同比增长率""" try: # 清洗当前季度数据 cleaned_data = data_process_tool.clean_data(state.raw_sales_data) # 清洗去年同期数据 cleaned_last_year_data = data_process_tool.clean_data(state.last_year_raw_data) # 计算同比增长率 yoy_rate = data_process_tool.calculate_yoy_growth(cleaned_data, cleaned_last_year_data) return DataAnalysisState( **state.model_dump(), cleaned_sales_data=cleaned_data, cleaned_last_year_data=cleaned_last_year_data, yoy_growth_rate=yoy_rate, current_node="process_data", task_status="running", updated_at=datetime.now() ) except Exception as e: # 记录重试次数 retry_count = state.retry_count.get("process_data", 0) + 1 new_retry_count = state.retry_count.copy() new_retry_count["process_data"] = retry_count return DataAnalysisState( **state.model_dump(), retry_count=new_retry_count, task_status="failed" if retry_count >= 2 else "running", error_info=f"数据处理失败(第{retry_count}次):{str(e)}", current_node="process_data", updated_at=datetime.now() ) # (其他节点执行函数:generate_chart、generate_report、check_task_status等,此处省略)
(4)图结构定义与事件钩子注册
from langgraph import StateGraph, END
from langgraph.graph import Hooks
import sqlite3
import json
# 1. 定义状态持久化函数
def save_state_to_db(state: DataAnalysisState):
"""将状态持久化到SQLite数据库"""
conn = None
try:
conn = sqlite3.connect("langgraph_tasks.db")
cursor = conn.cursor()
# 创建任务表(如果不存在)
cursor.execute('''
CREATE TABLE IF NOT EXISTS tasks (
task_id TEXT PRIMARY KEY,
state_json TEXT NOT NULL,
created_at DATETIME NOT NULL,
updated_at DATETIME NOT NULL
)
''')
# 序列化状态为JSON
state_json = state.model_dump_json()
# 插入或更新状态
cursor.execute('''
INSERT OR REPLACE INTO tasks (task_id, state_json, created_at, updated_at)
VALUES (?, ?, ?, ?)
''', (state.task_id, state_json, state.created_at, state.updated_at))
conn.commit()
except Exception as e:
print(f"状态持久化失败:{str(e)}")
finally:
if conn:
conn.close()
def load_state_from_db(task_id: str) -> Optional[DataAnalysisState]:
"""从SQLite数据库加载状态"""
conn = None
try:
conn = sqlite3.connect("langgraph_tasks.db")
cursor = conn.cursor()
cursor.execute('''
SELECT state_json FROM tasks WHERE task_id = ?
''', (task_id,))
result = cursor.fetchone()
if result:
state_json = result[0]
return DataAnalysisState.model_validate_json(state_json)
else:
print(f"未找到任务ID为{task_id}的状态")
return None
except Exception as e:
print(f"状态加载失败:{str(e)}")
return None
finally:
if conn:
conn.close()
# 2. 定义事件钩子函数
def post_node_hook(node_name: str, state_before: DataAnalysisState, state_after: DataAnalysisState):
"""节点执行后钩子:记录日志和持久化状态"""
print(f"[{datetime.now()}] 节点 {node_name} 执行完成")
print(f" 执行前状态:{state_before.task_status}")
print(f" 执行后状态:{state_after.task_status}")
if state_after.error_info:
print(f" 错误信息:{state_after.error_info}")
# 持久化状态
save_state_to_db(state_after)
def error_hook(node_name: str, state: DataAnalysisState, error: Exception):
"""错误钩子:记录错误日志并尝试重试"""
print(f"[{datetime.now()}] 节点 {node_name} 执行错误:{str(error)}")
# 记录错误信息到状态
retry_count = state.retry_count.get(node_name, 0) + 1
new_retry_count = state.retry_count.copy()
new_retry_count[node_name] = retry_count
error_state = DataAnalysisState(
**state.model_dump(),
retry_count=new_retry_count,
error_info=f"节点 {node_name} 执行错误:{str(error)}",
task_status="failed" if retry_count >= 2 else "running",
updated_at=datetime.now()
)
# 持久化错误状态
save_state_to_db(error_state)
return error_state
# 3. 定义图结构
workflow = StateGraph(DataAnalysisState)
# 添加节点
workflow.add_node("parse_requirement", parse_requirement) # 解析需求
workflow.add_node("process_data", process_data) # 数据处理
workflow.add_node("generate_chart", generate_chart) # 生成图表(并行节点1)
workflow.add_node("prepare_report", prepare_report) # 准备报告数据(并行节点2)
workflow.add_node("generate_report", generate_report) # 生成报告
workflow.add_node("output_report", output_report) # 输出报告
# 定义边(包含并行执行)
# 串行边:解析需求 → 数据处理
workflow.add_edge("parse_requirement", "process_data")
# 并行边:数据处理 → 生成图表 和 数据处理 → 准备报告数据
workflow.add_parallel_edges("process_data", ["generate_chart", "prepare_report"])
# 合并边:生成图表 和 准备报告数据 → 生成报告(需所有并行节点完成)
workflow.add_edge("generate_chart", "generate_report")
workflow.add_edge("prepare_report", "generate_report")
# 串行边:生成报告 → 输出报告 → 结束
workflow.add_edge("generate_report", "output_report")
workflow.add_edge("output_report", END)
# 注册事件钩子
hooks = Hooks()
hooks.add_hook("post_node_execution", post_node_hook)
hooks.add_hook("on_error", error_hook)
workflow.set_hooks(hooks)
# 编译图
app = workflow.compile()4.3 图片 3:多工具协同数据分析智能体的 LangGraph 结构与执行时序图
图片内容描述
该图片包含两部分:左侧为多工具协同数据分析智能体的 LangGraph 结构示意图,右侧为执行时序图,共同展示了智能体的节点关系、并行执行逻辑与时间线。
左侧:LangGraph 结构示意图
采用分层布局,将节点按功能分为 "需求解析层""数据处理层""并行执行层""报告生成层" 四层,每层节点用不同颜色的矩形框表示:
- 需求解析层:包含 "parse_requirement(解析需求)" 节点(天蓝色),功能是解析用户需求并查询数据库获取原始数据。
- 数据处理层:包含 "process_data(数据处理)" 节点(绿色),功能是清洗数据并计算同比增长率,该节点位于需求解析层下方,通过黑色实线箭头与 "parse_requirement" 节点连接,表示串行执行。
- 并行执行层:包含两个并行节点(橙色),分别是 "generate_chart(生成图表)" 和 "prepare_report(准备报告数据)",位于数据处理层下方,通过两条带 "并行" 标识的蓝色虚线箭头与 "process_data" 节点连接,表示这两个节点在 "process_data" 执行完成后同时启动。
- 报告生成层:包含 "generate_report(生成报告)" 节点(紫色)和 "output_report(输出报告)" 节点(红色),位于并行执行层下方。"generate_chart" 和 "prepare