论文基本信息 (Basic Information)
| 标题 (Title) | AIM: Adaptive Inference of Multi-Modal LLMs via Token Merging and Pruning |
|---|---|
| Adress | http://arxiv.org/abs/2412.03248 |
| Journal/Time | ICCV 2025 |
| Author | 香港中文大学 |
| Code | https://github.com/LaVi-Lab/AIM |
1. 核心思想 (Core Idea)
让多模态大语言模型(MLLMs)跑得更快、更省资源,而且不需要重新训练模型。
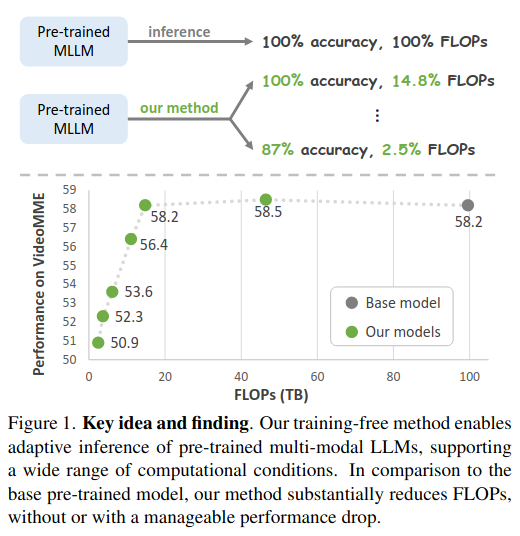
输入: 视觉数据(图像或视频)和文本提示(Text Prompts)。
任务: 多模态理解与推理任务,比如视频问答(VideoQA)、图像描述等。模型需要理解视觉内容并根据文本指令做出回答。
形式: 这是一个**无需训练(Training-free)**的推理加速框架,即插即用。
流程: 视觉编码后: 在视觉Token进入大语言模型(LLM)之前,先根据相似度合并一部分。LLM推理中: 在LLM的层与层之间,根据重要性逐步丢弃(剪枝)一部分视觉Token。
2. 研究背景与动机 (Background and Motivation)
现在的MLLM(如LLaVA-OneVision)在处理视频时,视觉编码器会生成成千上万个Visual Tokens。这导致推理时的计算量(FLOPs)巨大,显存占用高,推理速度慢,很难在移动设备等资源受限的环境下运行。视觉Token太冗余且需要计算资源太昂贵了。
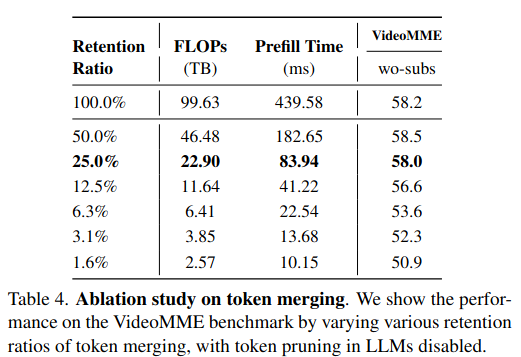
根本不需要那么多Token,保留**25%**的视觉Token通常就能维持原有的性能。
提出了一种"自适应推理(Adaptive Inference)"方法。这意味着你可以根据算力预算,动态调整Token的压缩比例,在速度和精度之间找到完美的平衡点。
3. 方法论 (Methodology)
- 双阶段设计(Dual-Stage Reduction):现有的方法要么只在LLM内部剪枝(如FastV),要么只在外部处理。同时在进入LLM之前做合并(Merging),和在LLM内部做剪枝(Pruning)。这种组合拳极大地压榨了冗余空间.
- 无需训练(Training-free):很多加速方法(如Token Merging的一些变体)需要微调模型,而本文方法拿来预训练好的模型(如LLaVA-OV或LLaVA-1.5)直接就能用。
- 自适应能力(Adaptivity):可以通过调整参数,实现从2.5%到100% FLOPs的跨度调节,性能下降非常平滑

第一阶段:LLM之前的 Token Merging (基于相似度)
在视觉编码器输出Visual Tokens后,不直接把它们全部塞给LLM。很多图像块或视频帧是高度相似的。利用**余弦相似度(Cosine Similarity)来衡量Token之间的距离。
将Token分为集合A和集合B。计算相似度,找到最匹配的对。将高相似度的Token合并(平均它们的Embedding)。
对于视频,只在帧内(Spatial)合并,不在帧间(Temporal)**合并。跨帧合并会打乱时间顺序,破坏视频理解能力。
第二阶段:LLM内部的 Token Pruning (基于重要性)
当Token进入LLM后,在Transformer层之间进行逐步剪枝。
核心算法:PageRank。
利用Transformer的**自注意力图(Self-Attention Map)**作为邻接矩阵,运行PageRank算法。公式如下:sil=1Nl+Ml∑j=1Nl+MlAi,jl⋅sjls_{i}^{l}=\frac{1}{N^{l}+M^{l}}\sum_{j=1}^{N^{l}+M^{l}}A_{i,j}^{l}\cdot s_{j}^{l}sil=Nl+Ml1j=1∑Nl+MlAi,jl⋅sjl
其中,sils_{i}^{l}sil 是第 lll 层第 iii 个Token的重要性得分,Ai,jlA_{i,j}^{l}Ai,jl 是归一化后的注意力权重。
如果很多Token都关注(Attend to)某个Visual Token,那这个Visual Token就很重要,应该保留。
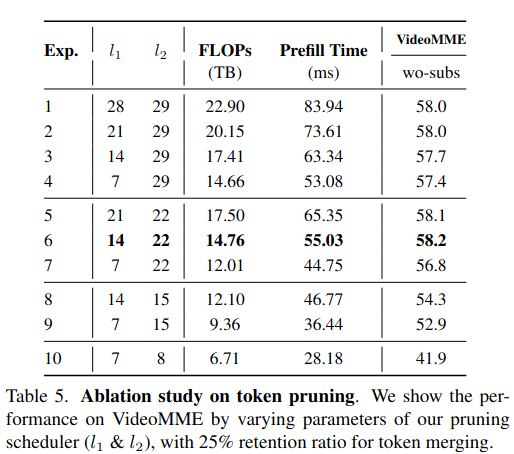
剪枝调度器 (Scheduler):不是每层都剪,而是设计了一个分段函数来控制保留率 rrr:
r={1,if l<l11−k(l−l1),if l1≤l≤l20,if l>l2 r = \begin{cases} 1, & \text{if } l < l_1 \\ 1 - k(l - l_1), & \text{if } l_1 \le l \le l_2 \\ 0, & \text{if } l > l_2 \end{cases}r=⎩ ⎨ ⎧1,1−k(l−l1),0,if l<l1if l1≤l≤l2if l>l2
这里 l1l_1l1 是开始剪枝的层,l2l_2l2 是剪完所有视觉Token的层19。
4. 实验结果 (Experimental Results)
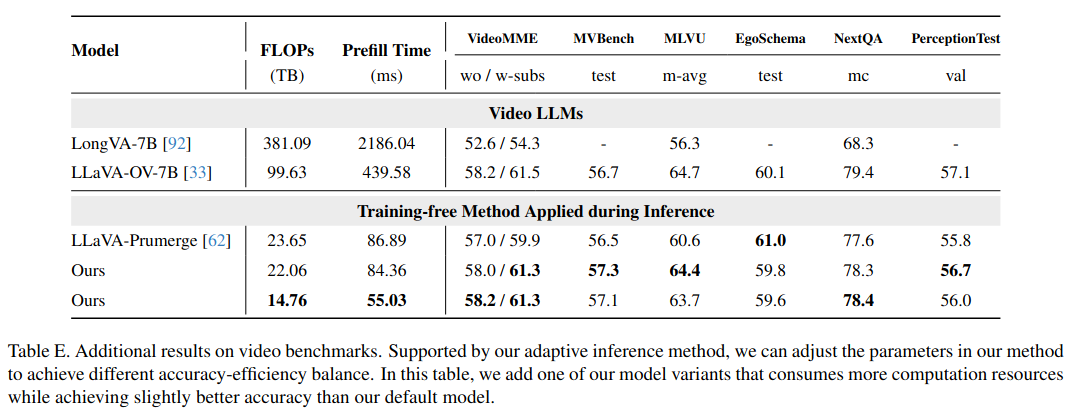
主要在 Video LLMs (LLaVA-OneVision) 和 Image LLMs (LLaVA-1.5) 上进行了测试。
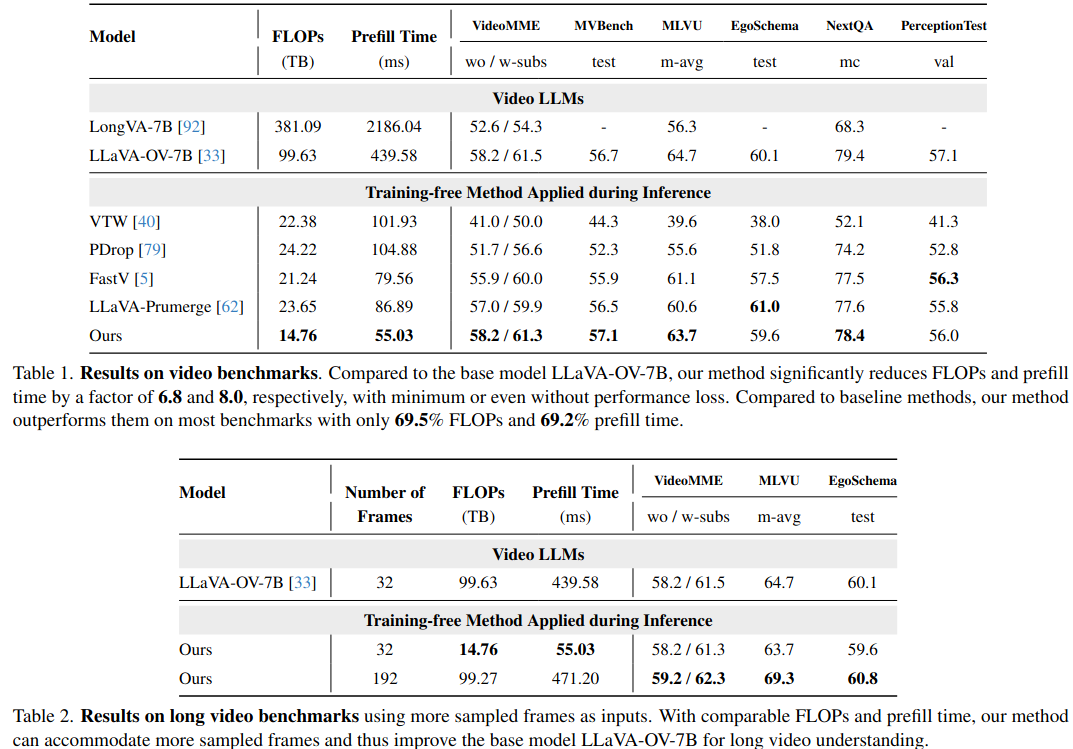
计算量降低,精度保持,优于其他剪枝方法。
通常加速意味着性能下降。但在视频理解中,Token压缩得足够小(FLOPs降低6.8倍)可以在同样的计算预算下,输入更多的视频帧。计算量每增加,但是性能提升。视频理解的瓶颈往往在于帧数太少丢失了时间信息,而不是单帧内的Token不够多。
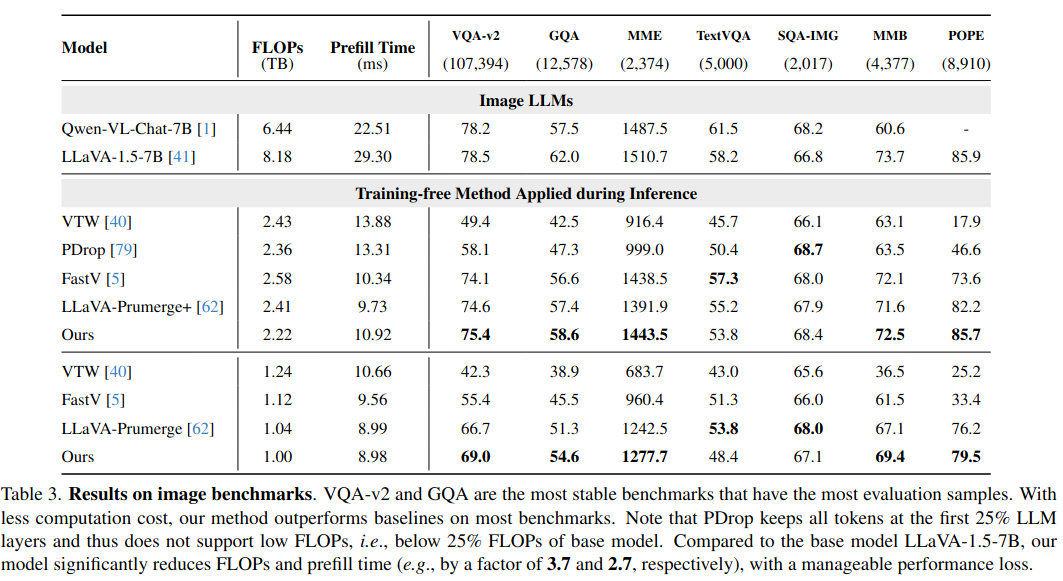
在图像任务上,约 3.7倍 的 FLOPs 降低,同时在 VQA-v2, GQA 等榜单上保持了极具竞争力的性能 。
5. 结论与讨论 (Conclusion & Discussion)
-
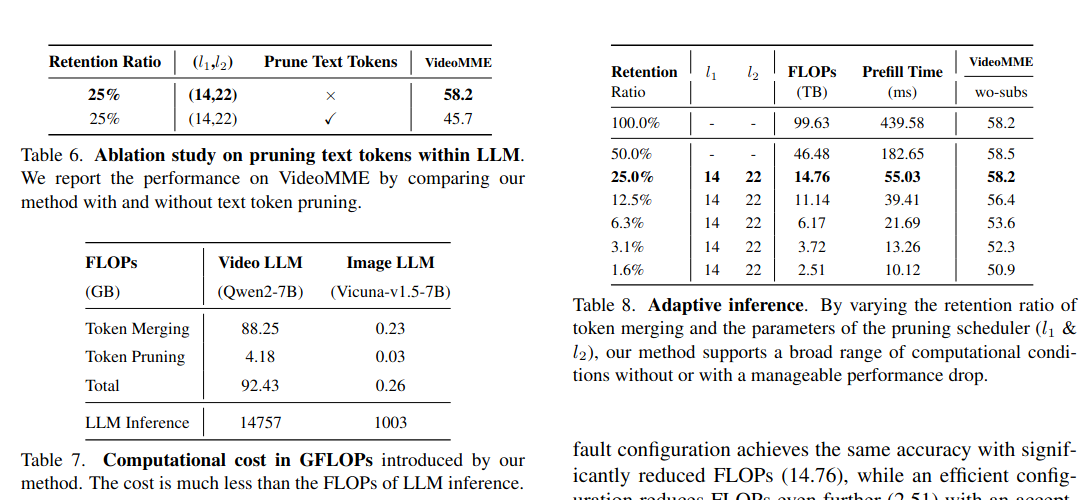
别剪文本Token(Text Tokens):尝试过也剪枝文本Token,结果性能崩盘(VideoMME上从58.2掉到45.7)。这说明MLLM的推理核心还是基于文本的,视觉只是辅助。
-
Token Merging 的比例。在进入 LLM 之前进行 Token 合并,测试了不同的保留比例(Retention Ratio)。75% 的视觉Token都是冗余的。
- Pruning Scheduler 与 LLM 的层级行为:在 LLM 内部进行剪枝,调节了开始剪枝的层(l1l_1l1)和完全剪完的层(l2l_2l2)
LLM的分层行为(Layer Behavior):
早期层(Early Layers): 侧重于跨模态融合(Cross-modal fusion),这时候剪掉视觉Token会严重伤害性能。
后期层(Later Layers): 侧重于纯文本推理。在很深的层(比如22层以后),即使把视觉Token全部丢掉,对结果几乎没有影响!这也是在l1l_1l1层之后才开始剪枝的原因。
6. 主要贡献总结 (Summary of Key Contributions)
证实了现有的多模态模型中,75% 的视觉 Token 都是多余的。LLM 的早期层侧重融合,后期侧重文本。提出了一套**无需训练(Training-free)**的双阶段框架,前端: 用相似度合并(Token Merging)去重。中端: 用注意力重要性(Token Pruning)剪枝 。FLOPs 降低 6.8 倍,推理速度大幅提升。
7. 附录
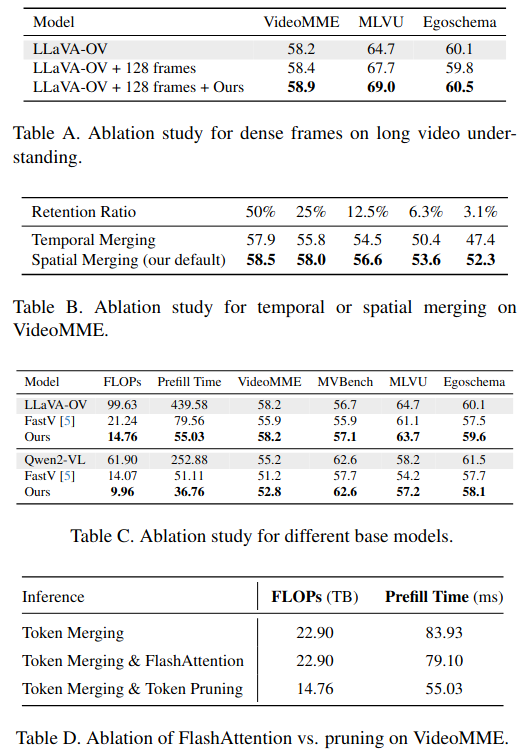
- Token Merging 仅在单帧图像内部进行(Spatial Merging)。在附录中会看到尝试了跨帧合并(Temporal Merging),也就是试图把相邻帧的相似 Token 揉在一起。效果很差。特别是在高压缩率下,性能下降明显 。视频理解极其依赖时间顺序。当我们强行合并不同帧的 Token 时,打乱了原本的时间序列信息。所以,保持帧与帧之间的独立性对于视频理解至关重要 。
- 主实验是基于 LLaVA-OV(LLaVA-OneVision)。在附录中,也尝试了架构差异很大的 Qwen2-VL。Qwen2-VL 的视觉编码器非常特殊,它没有单独的图像级 CLS token,而且它的编码方式会让特征在进入 LLM 之前就混合。方法依然有效,比基线方法 FastV 更强且更省资源 。
- FA 带来的加速(比如节省 ~5ms)远不如通过减少 Token 数量带来的加速(节省 ~29ms)多。FA 更适合训练阶段(节省显存I/O),而在推理阶段,减少计算量(Token数量)更重要
- 将参数调整到与基线方法 LLaVA-Prumerge 相同的 FLOPs 水平(约 22-23 TB)。
- 局限性
与FlashAttention的兼容性:目前的方法依赖于显式计算注意力矩阵(Attention Matrix)来运行PageRank。而FlashAttention(FA)的核心就是不显式存储这个矩阵以加速计算。因此,无法享受到FA的加速红利。虽然剪枝带来的加速远超FA,但如果能结合两者将是未来的方向。
文本密集型任务的短板: 在像TextVQA这类需要大量OCR(文字识别)的任务上,表现不如预期。这可能是因为PageRank有时候会误删那些包含细微文字信息的视觉Token。