本文旨在掌握 LangGraph 的核心运行机制:状态建模、节点执行、条件边路由与调度 ;理解它如何让 Agent 的决策循环变得可视、可测、可控。
关键词:节点状态机、边转换、图调度(invoke/stream)、条件路由、可组合的可重入执行。
一、为什么是 LangGraph:从"链"到"图"的范式升级
-
LangChain Chain :更像"线性管道/表达式"(LCEL),易上手,但 分支/循环/并发 表达力有限。
-
LangGraph :把 Agent 的 思考-行动-观察 过程建模为 状态图(StateGraph):
- 节点(Node)= 可运行单元(函数/Runnable/模型调用/工具)
- 边(Edge) = 节点间的有向连接 ,可静态或按条件动态跳转
- 状态(State) = 图在运行过程中唯一可靠的"真相记录",它要么不断追加信息,要么按规则覆盖更新。
优点:显式的控制流、可观察的中间态、易持久化与恢复(下一篇文章会介绍)。
二、最小心智模型:State / Node / Edge / Scheduler
- State :使用
TypedDict或 Pydantic/dataclass定义。LangGraph 通过Annotated[..., op]指定合并规则(例如多节点更新同一字段如何合并)。 - Node :接受
state,返回增量更新 (partial state);纯函数最佳(可测试、可复现)。 - Edge :
add_edge(src, dst)或add_conditional_edges(src, router_fn, mapping);END代表终止。 - Scheduler/Runner :
graph.compile()得到可执行应用(app),支持.invoke()/.stream()/.astream()。
三、一个"迷你 ReAct 风格"图式 Agent
功能:
-
根据问题内容决定:
- 走 计算工具(乘法)
- 走 百科检索(内置小字典)
- 或直接 回复
-
把思考日志(scratchpad)与最终答案写入状态
-
展示 条件路由 、多节点更新合并 、流式调度(逐节点事件)
运行前安装:
bashpip install -U langgraph langchain-core
python
from __future__ import annotations
import json
import os
import re
from typing import TypedDict, List, Literal, Annotated
import operator
from langchain_core.messages import SystemMessage, HumanMessage
from langchain_openai import ChatOpenAI
from langgraph.graph import StateGraph, END
# -------- 1) 定义状态 State --------
class AgentState(TypedDict):
# 用户问题
question: str
# 计划的下一步动作:calc / wiki / respond / end
next: Literal["calc", "wiki", "respond", "end"]
# 工具输入与工具输出
tool_input: str
tool_output: str
# 思考过程(scratchpad):每个节点可以追加日志
scratchpad: Annotated[List[str], operator.add]
# 最终答案
final_answer: str
# -------- 2) Planner 节点:由LLM驱动基于问题决定路线 --------
SYSTEM = """你是一个路由器,负责为问题选择下一步动作。
可选动作:
- "calc": 数学/乘法等计算
- "wiki": 百科/释义类查询
- "respond": 直接回答
- "end": 结束
输出严格的 JSON,格式为:
{"next": "calc|wiki|respond|end", "tool_input": "<传给工具或回复节点的文本>", "reason": "<简要原因>"}
不要输出除 JSON 外的任何内容。
"""
USER_TEMPLATE = """问题:{question}
请只输出 JSON。
"""
llm = ChatOpenAI(
temperature=0,
model="glm-4.5",
openai_api_key=os.getenv("ZAI_API_KEY"),
openai_api_base="https://open.bigmodel.cn/api/paas/v4/"
)
def planner(state: AgentState) -> dict:
q = state["question"].strip()
messages = [
SystemMessage(content=SYSTEM),
HumanMessage(content=USER_TEMPLATE.format(question=q)),
]
resp = llm.invoke(messages) # 同步调用(也可 .stream)
text = getattr(resp, "content", "").strip()
# 解析 JSON,出错则回退为 respond
try:
data = json.loads(text)
nxt = data.get("next", "respond")
tool_input = data.get("tool_input", q)
reason = data.get("reason", "")
except Exception as e:
nxt = "respond"
tool_input = q
reason = f"LLM 输出不可解析({e}),回退为 respond"
sp = [f"[planner_llm] next={nxt} | reason={reason}"]
# 将路由与工具输入写入状态
return {"next": nxt, "tool_input": tool_input, "scratchpad": sp}
# -------- 3) 工具节点:calc(乘法) --------
def tool_calc(state: AgentState) -> dict:
q = state["tool_input"]
# 极简解析:抽取两个整数相乘
nums = list(map(int, re.findall(r"\d+", q)))
if len(nums) >= 2:
ans = nums[0] * nums[1]
sp = [f"[calc] 解析到数字:{nums[0]} * {nums[1]} = {ans}"]
return {"tool_output": str(ans), "scratchpad": sp, "next": "respond"}
else:
sp = ["[calc] 解析失败,切换为直接回答"]
return {"tool_output": "无法计算", "scratchpad": sp, "next": "respond"}
# -------- 4) 工具节点:wiki(内置小知识库) --------
WIKI = {
"LangChain": "LangChain 是一个用于构建 LLM 应用的编排框架。",
"LangGraph": "LangGraph 是一种基于有向图的 Agent 工作流引擎。",
}
def tool_wiki(state: AgentState) -> dict:
q = state["tool_input"]
hit = None
for k, v in WIKI.items():
if k.lower() in q.lower():
hit = v
break
if hit:
sp = ["[wiki] 匹配到词条,返回片段"]
return {"tool_output": hit, "scratchpad": sp, "next": "respond"}
else:
sp = ["[wiki] 未命中词条"]
return {"tool_output": "未查到相关百科", "scratchpad": sp, "next": "respond"}
# -------- 5) 响应节点:整合工具结果或直接回答 --------
def respond(state: AgentState) -> dict:
q = state["question"]
tool_out = state.get("tool_output", "")
if tool_out:
final = f"问题:{q} | 工具结果:{tool_out} | 回答:{tool_out}"
sp = ["[respond] 基于工具结果输出最终答案"]
else:
final = f"针对你的问题「{q}」,这是我的直接回答:这是一个示例 Agent 的回复。"
sp = ["[respond] 无工具结果,直接输出答案"]
return {"final_answer": final, "scratchpad": sp, "next": "end"}
# -------- 6) 条件路由函数:把 planner 的 next 映射到边 --------
def route_from_planner(state: AgentState) -> str:
return state["next"]
# -------- 7) 构图:添加节点与边 --------
def build_app():
graph = StateGraph(AgentState)
graph.add_node("planner", planner)
graph.add_node("calc", tool_calc)
graph.add_node("wiki", tool_wiki)
graph.add_node("respond", respond)
graph.set_entry_point("planner")
# 从 planner 的输出,按 next 字段动态路由
graph.add_conditional_edges(
"planner",
route_from_planner,
{
"calc": "calc",
"wiki": "wiki",
"respond": "respond",
"end": END,
},
)
# 工具节点统一流向 respond
graph.add_edge("calc", "respond")
graph.add_edge("wiki", "respond")
# respond 再流向 END(也可不写,respond 内已把 next=end)
graph.add_conditional_edges(
"respond",
route_from_planner,
{"end": END, "respond": "respond"} # 预留可二次回答的可能
)
return graph.compile()
# -------- 8) 运行演示:invoke / stream --------
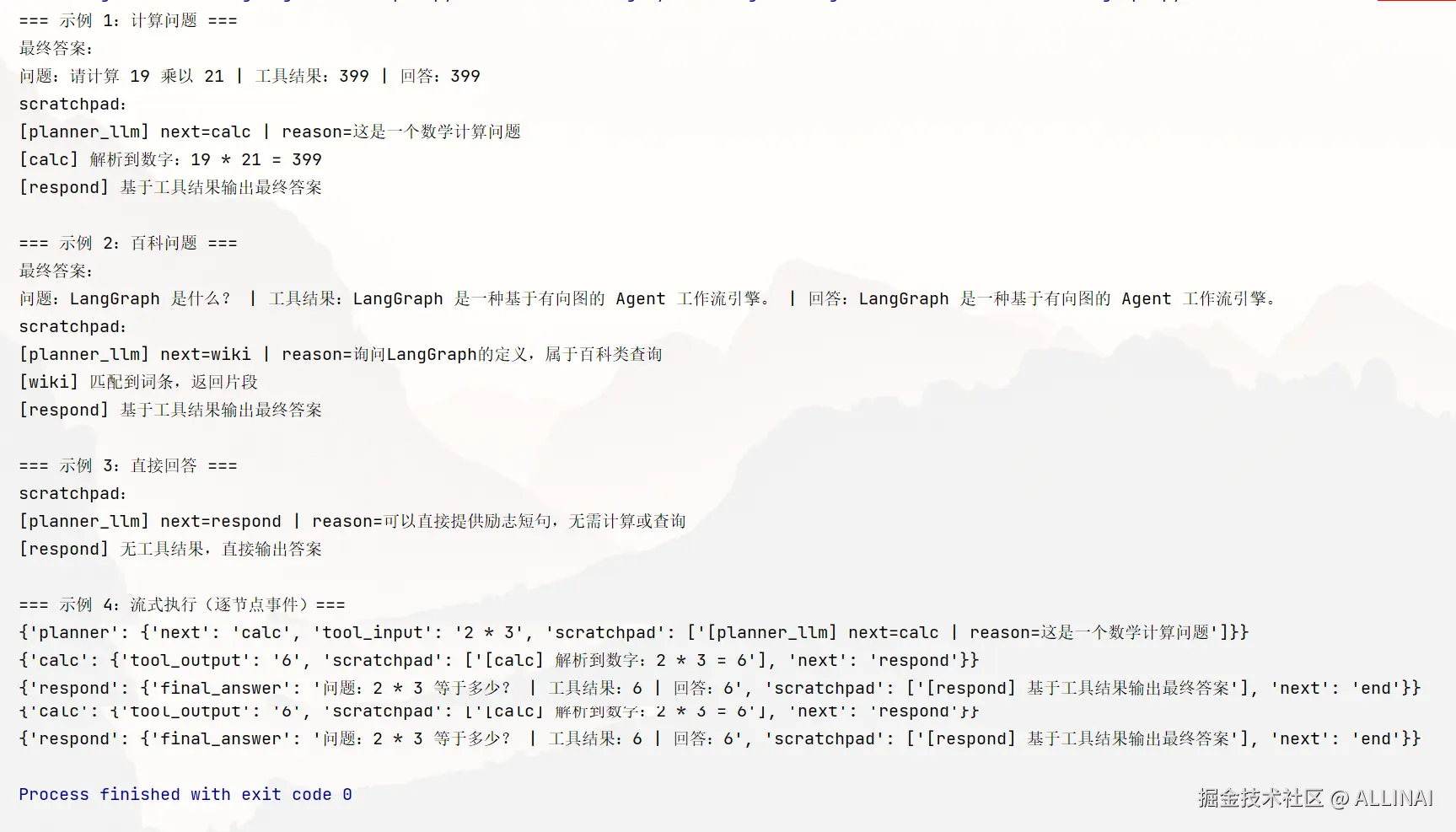
if __name__ == "__main__":
app = build_app()
print("=== 示例 1:计算问题 ===")
out = app.invoke({"question": "请计算 19 乘以 21"})
print(f"最终答案:\n{out['final_answer']}")
print("scratchpad:")
print("\n".join(out["scratchpad"]))
print()
print("=== 示例 2:百科问题 ===")
out = app.invoke({"question": "LangGraph 是什么?"})
print(f"最终答案:\n{out['final_answer']}")
print("scratchpad:")
print("\n".join(out["scratchpad"]))
print()
print("=== 示例 3:直接回答 ===")
out = app.invoke({"question": "给我一句励志短句"})
print("scratchpad:")
print("\n".join(out["scratchpad"]))
print()
print("=== 示例 4:流式执行(逐节点事件)===")
for event in app.stream({"question": "2 * 3 等于多少?"}):
# event 是一个字典,键是节点名或 END,值是该步的状态增量
print(event)你会看到:
StateGraph(AgentState)显式定义了状态结构 ,且scratchpad使用了operator.add合并,便于多节点增量写日志。planner决策 → 条件路由到calc/wiki/respond→respond整合,并最终到END。.invoke()返回最终状态 ;.stream()会逐节点输出事件(非常适合可视化调试与监控)。
四、LangGraph 的"节点状态机"要点理解
-
节点就是"状态转移函数" :
new_state = reduce(merge(old_state, node(old_state)))- 输入:当前全量状态
- 输出 :状态的增量(partial dict)
- 合并 :按字段定义的 merge 规则(如
operator.add)对同名 key 进行可控合并
-
边就是"转移关系":
- 固定边 :
add_edge(A, B) - 条件边 :
add_conditional_edges(A, router_fn, mapping),router_fn从状态里读出"路由键",mapping指向目标节点或END
- 固定边 :
-
图调度/编排:
graph.compile()→app:可.invoke()、.stream()、.ainvoke().stream()让你在运行时按节点颗粒度观察中间态,利于排错/指标采集/可视化
五、进阶提示
- Planner 节点常由 LLM + Prompt 决策(例如 ReAct 思路),输出动作/工具名/参数到状态;
- 工具节点一般封装成 Runnable 或 BaseTool ,在节点中读取
tool_input并执行; - 你可以把"LLM 调用"与"工具执行" 各自做成独立节点,由条件边控制顺序和分支;
- 在 LangGraph 架构中,针对需要同时调用多个工具(如多路检索、多个子模型并行推理等)场景,通常会使用 分叉节点(Fork) 与 合流节点(Join) 实现并行执行和结果聚合:
- 分叉节点:在图的某个状态下,生成多个分支,分别调用不同的工具或执行不同子任务,实现真正的并行处理。
- 合流节点:等待所有分支执行完成,将结果汇总、清洗或合并,形成统一的上下文或决策依据。
- 这种设计大幅提升了复杂多模态、多工具 Agent 的效率与灵活性,避免串行调用带来的瓶颈
python
# 伪代码,展示分叉合流逻辑示意
def fork_node(state):
return [
execute_tool_a(state),
execute_tool_b(state),
execute_tool_c(state),
]
def join_node(results):
combined = aggregate_results(results)
return combined
# 在 LangGraph 图中,fork_node 是分叉点,join_node 是合流点六、常见问题与工程建议
- 状态设计 :尽量小而清晰,把"可复现的事实"放入状态,把"临时上下文"放在局部变量。
- 合并策略 :对列表/字典等可被多个节点并发写入的字段,一定要用
Annotated[..., operator.add]等方式明确 merge 规则。 - 可观测性 :优先用
.stream()接上你的日志/指标系统;节点输出的增量就是最好的可视化材料。 - 可测试性 :节点都是纯函数,给定输入状态,输出应可预测;单测直接调用节点函数而不是整图。
- 安全与回退:在节点中处理异常,必要时路由到"补救/回退"节点(例如 fallback 检索、降级回答)。
✅ 小结
- LangGraph 用 显式状态 + 条件边 表达 Agent 的控制流,是将"思考-行动-观察"工程化的抓手。
- 节点是状态机 、边是路由 、调度是执行器 :这三者让系统具备了可读、可测、可维护的架构基础。
- 通过
.invoke()与.stream(),你可以在同步 或流式维度检视每一步的中间态与决策证据。
接下来我们将接入 Checkpointer 与外部存储,让图在多轮对话/长任务中持续保存状态 、断点续跑 ,并实现异步工具与并行分支的稳健协作。