前言
首先展示下Embedding,本文使用阿里的模型,需要按照相关的依赖,参考 大模型服务平台百炼控制台
词嵌入
- embed_query 处理单个文本
- embed_documents 处理多个文本
python
# embeddings
# from langchain_openai import OpenAIEmbeddings
from langchain_community.embeddings import DashScopeEmbeddings
from dotenv import load_dotenv
import os
load_dotenv()
embeddings = DashScopeEmbeddings(
dashscope_api_key=os.getenv("OPENAI_API_KEY"),
model="text-embedding-v4",
)
text = 'This is a test document.'
query_result = embeddings.embed_query(text)
print(f"query_result[:2] {query_result[:2]} size={len(query_result)}")
# query_result[:2] [-0.038538604974746704, 0.03440577909350395] size=1024
text2 = '这是一个测试文本'
query_results = embeddings.embed_documents([text, text2])
print(f"len(query_results)={len(query_results)}")
# len(query_results)=2嵌入返回的结果是一个1024的浮点数数组,这就是词嵌入,把一段话转成一个数组
json
[-0.038538604974746704, 0.03440577909350395,...] 索引存储与检索示例
嵌入把问题和文档都转换成向量(就是一串数字),然后把这些向量存储在一个向量数据库里(比如 LangChain 的 InMemoryVectorStore)。这样,我们就可以通过计算向量之间的相似度,快速准确地找到最相关的文档。
python
from langchain_community.embeddings import DashScopeEmbeddings
from dotenv import load_dotenv
import os
from langchain_core.vectorstores import InMemoryVectorStore
load_dotenv()
embeddings = DashScopeEmbeddings(
dashscope_api_key=os.getenv("OPENAI_API_KEY"),
model="text-embedding-v4",
)
text = 'LangChain is the framework for building context-aware reasoning applications.'
# 1. 向量化并存储
vectorstore = InMemoryVectorStore.from_texts([text], embedding=embeddings, )
# 2. 检索器
retriever = vectorstore.as_retriever()
# 3. 检索文档
query = 'What is LangChain?'
retrieved_documents = retriever.invoke(query)
print(retrieved_documents[0].page_content)嵌入把文本转换成高维向量,相似的文本在向量空间中会靠得很近。这样,我们可以通过测量向量之间的"距离"或"角度"来快速比较它们的意思。一般有余弦相似度 和欧几里得距离的测量方法
一个计算余弦相似度的示例,使用numpy库
python
from langchain_community.embeddings import DashScopeEmbeddings
from dotenv import load_dotenv
import os
from langchain_core.vectorstores import InMemoryVectorStore
import numpy as np
load_dotenv()
embeddings = DashScopeEmbeddings(
dashscope_api_key=os.getenv("OPENAI_API_KEY"),
model="text-embedding-v4",
)
text1 = 'LangGraph is a library for building stateful, multi-actor applications with LLMs.'
text2 = 'LangChain is a framework for building context-aware reasoning applications.'
text3 = 'The quick brown fox jumps over the lazy dog.'
embedding1 = embeddings.embed_query(text1)
embedding2, embedding3 = embeddings.embed_documents([text2, text3])
print('Embedding for text1 (first 10 values):', embedding1[:10])
print('Embedding for text2 (first 10 values):', embedding2[:10])
print('Embedding for text3 (first 10 values):', embedding3[:10])
# Define a function to calculate cosine similarity
def cosine_similarity(vec1, vec2):
"计算余弦相似度"
dot_product = np.dot(vec1, vec2)
norm_vec1 = np.linalg.norm(vec1)
norm_vec2 = np.linalg.norm(vec2)
return dot_product / (norm_vec1 * norm_vec2)
# Calculate similarity scores
similarity_1_2 = cosine_similarity(embedding1, embedding2)
similarity_1_3 = cosine_similarity(embedding1, embedding3)
similarity_2_3 = cosine_similarity(embedding2, embedding3)
# Display similarity scores
print('Cosine Similarity between text1 and text2:', similarity_1_2) # 0.6875611669530656
print('Cosine Similarity between text1 and text3:', similarity_1_3) # 0.18784711323151998
print('Cosine Similarity between text2 and text3:', similarity_2_3) # 0.20749644904732326由于similarity_1_2的值最大,就说明text1和text2的相似度更大
向量存储
向量数据库是一种专门用来存储和检索高维向量的数据库。在检索增强生成(RAG)系统中,向量数据库非常重要,因为它可以帮助我们快速找到和查询向量最相似的文档,从而获取上下文相关的信息。
常见的向量数据库
- FAISS:Facebook AI 开发的高性能、开源库,适合本地部署。
- Chroma:轻量级,作为本地库运行,与 Python 集成良好。
- Lance:开源向量数据库,优化了存储和检索效率。
- Milvus:开源,可以本地部署或在云端部署,支持动态索引。
- Weaviate:可以在本地或云端运行,支持强大的查询语言和知识图谱。
- Vespa:开源引擎,适合搜索和推荐,适合本地部署。
- Pinecone:基于云的向量数据库,提供可扩展且托管的向量存储。
- Google Vertex Matching Engine:Google 提供的托管服务,用于快速且可扩展的相似性搜索。
- AWS Kendra:与 AWS 集成的完全托管搜索服务。
- Redis Vector Search:Redis 模块,支持向量相似性搜索,优化了云环境。
Chroma使用示例
需要安装pip install langchain_chroma
pyhon
from langchain_community.embeddings import DashScopeEmbeddings
from dotenv import load_dotenv
import os
from langchain_chroma import Chroma
from langchain.schema import Document # Import the Document class
# Chroma demo
load_dotenv()
embeddings = DashScopeEmbeddings(
dashscope_api_key=os.getenv("OPENAI_API_KEY"),
model="text-embedding-v4",
)
documents = [
Document(page_content="LangChain is a framework for building context-aware reasoning applications."),
Document(page_content="FAISS is a library for efficient similarity search and clustering of dense vectors."),
Document(page_content="The quick brown fox jumps over the lazy dog.")
]
# 索引
db = Chroma.from_documents(documents, embeddings)
print("索引ok")
# 按照文本查询
query = "What is LangChain?"
docs = db.similarity_search(query)
print("Most similar document to the query:")
print(docs[0].page_content) # LangChain is a framework for building context-aware reasoning applications.
# 按照向量查询
query_embedding = embeddings.embed_query(query)
docs_by_vector = db.similarity_search_by_vector(query_embedding)
print("Most similar document to the query (vector search):")
print(docs_by_vector[0].page_content) # LangChain is a framework for building context-aware reasoning applications.使用LLM使用RAG生成问题答案
用RAG和LLM来回答问题,就是先在向量存储里通过相似性搜索找到最相关的文件,然后把找到的文件内容当背景,让语言学习模型(LLM)来生成回答。这种办法在检索增强生成(RAG)场景里特别关键,LLM能把从向量存储里检索到的外部知识和自己的生成能力结合起来,搞定答案。
示意图 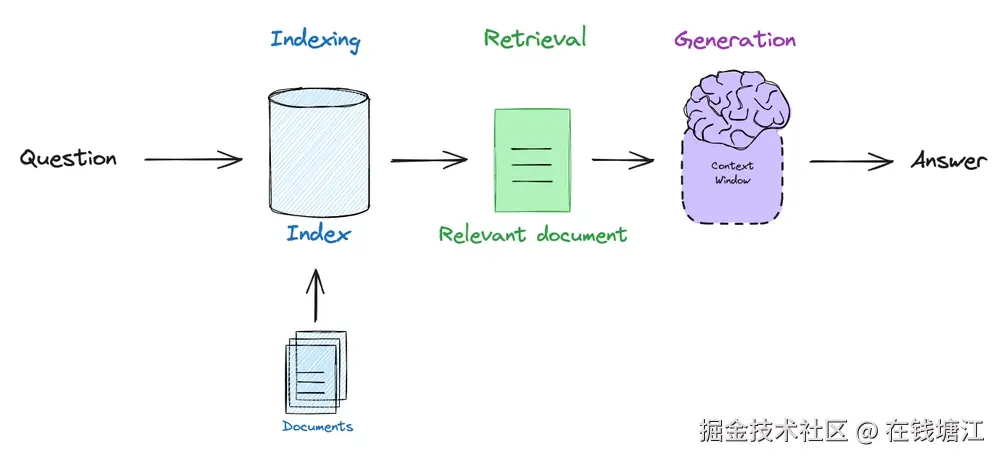
咱们来瞅瞅怎么用LLM,根据检索到的文件内容来生成回答。
用LLM生成回答的步骤
- 检索相关文件:通过相似性搜索,找到跟用户问题最相关的文件。
- 组合上下文和问题:把检索到的文件和用户的问题拼成一个提示词给LLM用。
- 生成回答:让LLM根据拼好的提示词来生成回答。
这个例子的前提是我们已经在向量存储(比如Chroma)里存好了文件,并且根据用户的查询找到了最相似的文件。
一个简单的RAG示例
python
from langchain_community.embeddings import DashScopeEmbeddings
from dotenv import load_dotenv
import os
from langchain_chroma import Chroma
from langchain.schema import Document # Import the Document class
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
# Chroma demo
load_dotenv()
embeddings = DashScopeEmbeddings(
dashscope_api_key=os.getenv("OPENAI_API_KEY"),
model="text-embedding-v4",
)
model = ChatOpenAI(model="qwen-plus",
base_url=os.getenv("BASE_URL"),
api_key=os.getenv("OPENAI_API_KEY"),
temperature=0,
streaming=True)
documents = [
Document(page_content="LangChain is a framework for building context-aware reasoning applications."),
Document(page_content="FAISS is a library for efficient similarity search and clustering of dense vectors."),
Document(page_content="The quick brown fox jumps over the lazy dog.")
]
# 索引
db = Chroma.from_documents(documents, embeddings)
print("索引ok")
# 设置检索器 按照相似度最多检索5个
retriever = db.as_retriever(search_type="similarity", search_kwargs={"k": 5})
# RAG提示词
prompt = ChatPromptTemplate.from_template(
"""
您是问答任务的助理。使用以下检索到的上下文来回答问题。如果你不知道答案,就说你不知道。最多使用三句话,保持答案简洁。
Question: {question}
Context: {context}
Answer:
"""
)
# RAG链
rag_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| model
| StrOutputParser()
)
# Use the RAG pipeline to answer a user question
question = "狐狸做了什么?"
for chunk in rag_chain.stream(question):
print(chunk, end="", flush=True)
# 狐狸跳过了懒狗。从PDF中获取资料的RAG示例
加载一个PDF文档,将其拆分为更小的块,嵌入每个块,并将其存储在向量存储中。
具体步骤是:
- 加载文件:用PyPDFLoader加载PDF文件。
- 分割文件:用CharacterTextSplitter把文件切成小块。
- 生成嵌入向量:给每个小块生成嵌入向量。
- 存到Chroma:把小块索引到Chroma向量数据库里。
- 计算token数量:用tiktoken算每个小块的token数量。
python
from langchain_community.embeddings import DashScopeEmbeddings
from dotenv import load_dotenv
import os
from langchain_chroma import Chroma
from langchain.schema import Document # Import the Document class
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
from langchain_text_splitters import CharacterTextSplitter
import tiktoken
# pip install pypdf
from langchain_community.document_loaders import PyPDFLoader
load_dotenv()
embeddings = DashScopeEmbeddings(
dashscope_api_key=os.getenv("OPENAI_API_KEY"),
model="text-embedding-v4",
)
model = ChatOpenAI(model="qwen-plus",
base_url=os.getenv("BASE_URL"),
api_key=os.getenv("OPENAI_API_KEY"),
temperature=0,
streaming=True)
# 加载文档
file_path = os.path.join(os.getcwd(), "Faiss by FacebookAI.pdf")
raw_documents = PyPDFLoader(file_path).load()
print("size=", len(raw_documents)) # 12
# 拆分文档
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
print("documents size=", len(documents)) # documents size= 12
# Chroma
# 此处拆成10个一组是因为阿里云的词嵌入一次最多支持10个文档,所以我们分两批加载
db = Chroma.from_documents(documents=documents[:10], embedding=embeddings)
db.add_documents(documents[10:])
retriever = db.as_retriever(search_type="similarity", search_kwargs={"k": 3}) # Retrieve top 3 relevant chunks
# Rag提示词模板
prompt = ChatPromptTemplate.from_template(
"""
您是问答任务的助理。使用以下检索到的上下文来回答问题。如果你不知道答案,就说你不知道。最多使用三句话,保持答案简洁。
Question: {question}
Context: {context}
Answer:
"""
)
# RAG链
rag_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| model
| StrOutputParser()
)
# 测试
question = "你能解释一下FAISS的用途吗?"
for chunk in rag_chain.stream(question):
print(chunk, end="", flush=True)
# FAISS(Facebook AI Similarity Search)是一个用于高效相似性搜索的库,主要用于快速查找大规模数据集中相似的多媒体文档。它通过高效的最近邻搜索实现,支持数十亿高维向量的快速处理,比之前的最先进方法快8.5倍。FAISS适用于需要处理高维向量的AI应用,如图像和文本检索。从Web中获取资料的示例
langchain中提供了很多的Loader,比如WebLoader就可以从url中获取文件内容,下面是一个示例,展示了从pdf和url多个源中获取文档
python
from typing import List
from langchain_community.embeddings import DashScopeEmbeddings
from dotenv import load_dotenv
import os
from langchain_chroma import Chroma
from langchain.schema import Document # Import the Document class
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
from langchain_text_splitters import CharacterTextSplitter
# pip install pypdf
from langchain_community.document_loaders import PyPDFLoader
# pip install beautifulsoup4
from langchain_community.document_loaders import WebBaseLoader
load_dotenv()
embeddings = DashScopeEmbeddings(
dashscope_api_key=os.getenv("OPENAI_API_KEY"),
model="text-embedding-v4",
)
model = ChatOpenAI(model="qwen-plus",
base_url=os.getenv("BASE_URL"),
api_key=os.getenv("OPENAI_API_KEY"),
temperature=0,
streaming=True)
# 加载文档
def load_from_pdf(file_path: str) -> List[Document]:
raw_documents = PyPDFLoader(file_path).load()
return raw_documents
def load_from_url(url: str) -> List[Document]:
return WebBaseLoader(url).load()
def split_docs(docs: List[Document]) -> List[Document]:
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
return text_splitter.split_documents(docs)
def create_db(docs: List[Document]):
if len(docs) <= 10:
res = Chroma.from_documents(documents=docs, embedding=embeddings)
else:
first_docs = docs[:10]
res = Chroma.from_documents(documents=first_docs, embedding=embeddings)
left = 10
while left < len(docs):
right = min(left + 10, len(docs))
seg_docs = docs[left:right]
res.add_documents(seg_docs)
left += 10
return res
docs1 = load_from_pdf(os.path.join(os.getcwd(), "Faiss by FacebookAI.pdf"))
docs2 = load_from_url("https://faiss.ai/")
db = create_db(split_docs([*docs1, *docs2]))
retriever = db.as_retriever(search_type="similarity", search_kwargs={"k": 3}) # Retrieve top 3 relevant chunks
# 测试检索内容
docs_retrieved = retriever.invoke(input="你能解释一下FAISS的用途吗?")
for doc in docs_retrieved:
print(doc.id, doc.metadata["source"], f"{doc.page_content[:20]}...")
# Rag提示词模板
prompt = ChatPromptTemplate.from_template(
"""
您是问答任务的助理。使用以下检索到的上下文来回答问题。如果你不知道答案,就说你不知道。最多使用三句话,保持答案简洁。
Question: {question}
Context: {context}
Answer:
"""
)
# RAG链
rag_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| model
| StrOutputParser()
)
# 测试
question = "你能解释一下FAISS的用途吗?"
for chunk in rag_chain.stream(question):
print(chunk, end="", flush=True)运行结果
csharp
# 检索出的文档内容
1ce0d5a7-1690-40d6-8411-73335de65249 https://faiss.ai/ Welcome to
8c966424-78c1-4171-a249-6df55841d0b5 D:\code\support\LangGraphProjects\proj1\Faiss by FacebookAI.pdf AUG 23, 20
ce45fa21-5a3a-4106-a050-2d1c2bf994ff https://faiss.ai/ The faiss-
# llm的回答
FAISS 是一个用于高效相似性搜索和密集向量聚类的库,能够处理从内存到大规模数据集的各种向量集合。它支持相似性搜索操作,例如在给定向量时快速查找最接近的向量。FAISS 还提供 GPU 实现以加速计算,并主要用于 AI 研究领域。