我们将紧接着上一次的话题,继续探索RAG技术。未阅读上一期的小伙伴可以点进我们的主页,查看文章测试18种RAG技术,找出最优方案(一)。
文档增强
我们已经见识过通过在块的周围添加上下文(比如相邻块或标题)能带来帮助。现在,让我们尝试另一种增强方式:从文本块中生成问题。
核心思路是,这些生成的问题可以作为替代"查询",或许比原始文本块本身更能匹配用户的意图。
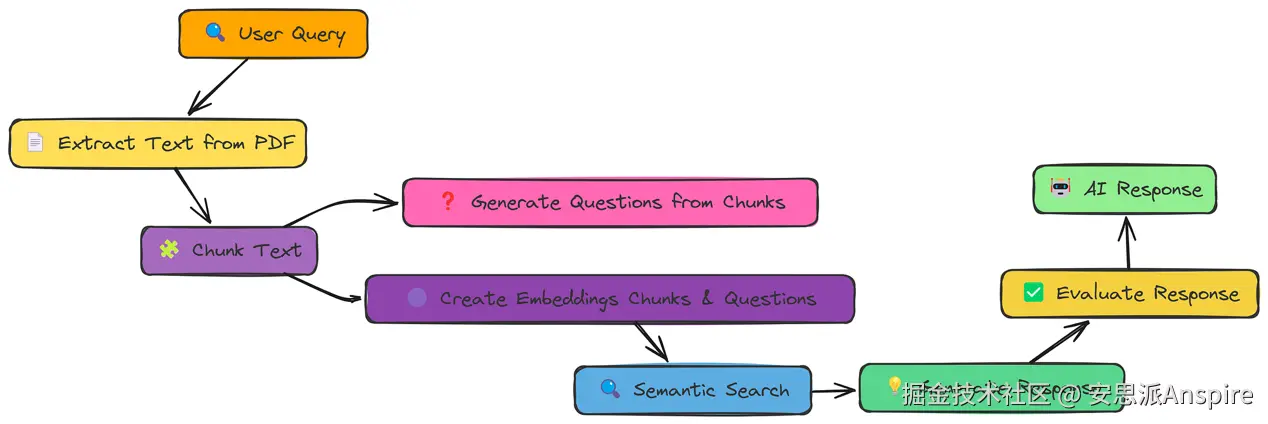
文档增强工作流程
我们在分块和创建嵌入之间加入这一步骤。我们可以直接使用generate_questions函数来实现,该函数接收一个text_chunk,并返回基于该文本块生成的若干问题。
让我们先看看如何通过问题生成实现文档增强:
ini
# 处理文档(提取文本、创建块、生成问题、构建向量存储)
text_chunks, vector_store = process_document(
pdf_path,
chunk_size=1000,
chunk_overlap=200,
questions_per_chunk=3
)
print(f"向量存储包含 {len(vector_store.texts)} 个条目")
### 输出 ###
Vector store contains 214 items这里,process_document函数完成了所有工作。它接收pdf路径、块大小、重叠度和每个块生成的问题数量,并返回一个vector_store。
现在,vector_store不仅包含文档的嵌入,还包含生成的问题的嵌入。
接下来,我们可以像之前一样使用这个vector_store执行语义搜索。我们这里用一个简单的函数来查找相似向量:
scss
# 执行语义搜索以找到相关内容
search_results = semantic_search(query, vector_store, k=5)
print("查询:", query)
print("\n搜索结果:")
# 按类型整理结果
chunk_results = []
question_results = []
for result in search_results:
if result["metadata"]["type"] == "chunk":
chunk_results.append(result)
else:
question_results.append(result)这里的重要变化是我们处理搜索结果的方式。现在向量存储中有两种条目:原始文本块和生成的问题。这段代码将它们分开,这样我们就能看出哪种类型的内容与查询匹配得更好。
最后几步是生成上下文并进行评估:
ini
# 从搜索结果中准备上下文
context = prepare_context(search_results)
# 生成响应
response_text = generate_response(query, context)
# 从验证数据中获取参考答案
reference_answer = data[0]['ideal_answer']
# 评估响应
evaluation = evaluate_response(query, response_text, reference_answer)
print("\n评估:")
print(evaluation)
### 输出 ###
根据评估标准,我会给AI助手的响应打0.8分。我们的评估显示得分约为0.8!
生成问题并将其添加到可搜索索引中,让我们的性能再次得到提升。
看来有时候,一个问题比原始文本块更能体现信息需求。
查询转换
到目前为止,我们的重点是改进RAG系统使用的数据。但对于查询本身,我们能做些什么呢?
通常,用户提出问题的方式并不一定是搜索知识库的最佳方式。查询转换旨在解决这个问题。我们将探索三种不同的方法:
-
查询重写(Query Rewriting):让查询更具体、更详细。
-
后退提示法(Step-back Prompting):创建一个更宽泛、更通用的查询来检索背景上下文。
-
子查询分解(Sub-query Decomposition):将复杂查询拆分为多个更简单的子查询。
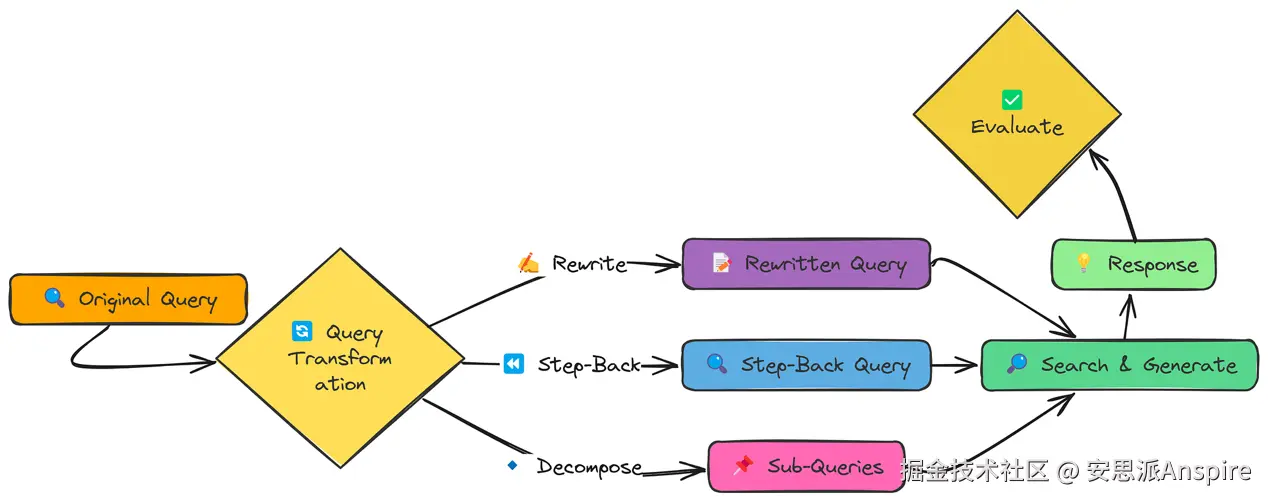
查询转换工作流程
让我们看看这些转换的实际应用。我们将使用标准测试查询:
ini
# 查询重写
rewritten_query = rewrite_query(query)
# 后退提示法
step_back_query = generate_step_back_query(query)generate_step_back_query的作用与重写相反:它创建一个更宽泛的查询,可能会检索到有用的背景信息。
最后是子查询分解:
ini
# 子查询分解
sub_queries = decompose_query(query, num_subqueries=4)decompose_query将原始查询拆分为几个更小、更聚焦的问题。其思路是,这些子查询合在一起,可能比任何单个查询都更能涵盖原始查询的意图。
现在,为了看看这些转换如何影响我们的RAG系统,让我们使用一个结合了所有先前方法的函数:
python
def rag_with_query_transformation(pdf_path, query, transformation_type=None):
"""
运行完整的RAG流程,支持可选的查询转换。
参数:
pdf_path (str):PDF文档的路径
query (str):用户查询
transformation_type (str):转换类型(None、'rewrite'、'step_back' 或 'decompose')
返回:
Dict:包含查询、转换后的查询、上下文和响应的结果
"""
# 处理文档以创建向量存储
vector_store = process_document(pdf_path)
# 应用查询转换并搜索
if transformation_type:
# 使用转换后的查询执行搜索
results = transformed_search(query, vector_store, transformation_type)
else:
# 不进行转换,执行常规搜索
query_embedding = create_embeddings(query)
results = vector_store.similarity_search(query_embedding, k=3)
# 合并搜索结果中的上下文
context = "\n\n".join([f"段落 {i+1}:\n{result['text']}" for i, result in enumerate(results)])
# 基于查询和合并后的上下文生成响应
response = generate_response(query, context)
# 返回结果,包括原始查询、转换类型、上下文和响应
return {
"original_query": query,
"transformation_type": transformation_type,
"context": context,
"response": response
}evaluate_transformations函数会将原始查询通过不同的查询转换技术(重写、后退提示、分解)运行,然后比较它们的输出。
这有助于我们了解哪种方法能检索到最相关的信息,从而生成更好的响应。
ini
# 运行评估
evaluation_results = evaluate_transformations(pdf_path, query, reference_answer)
print(evaluation_results)
### 输出 ###
Evaluation Score: 0.5评估得分是0.5。
这表明我们的查询转换技术并没有持续优于更简单的方法。
虽然查询转换可能很强大,但它们并非万能良药。有时候,原始查询已经足够好,强行"改进"反而可能弄巧成拙。
重排序器
我们已经尝试过改进数据(通过分块策略)和查询(通过转换)。现在,让我们聚焦于检索过程本身。简单的相似度搜索往往会返回一堆相关和不相关的结果。
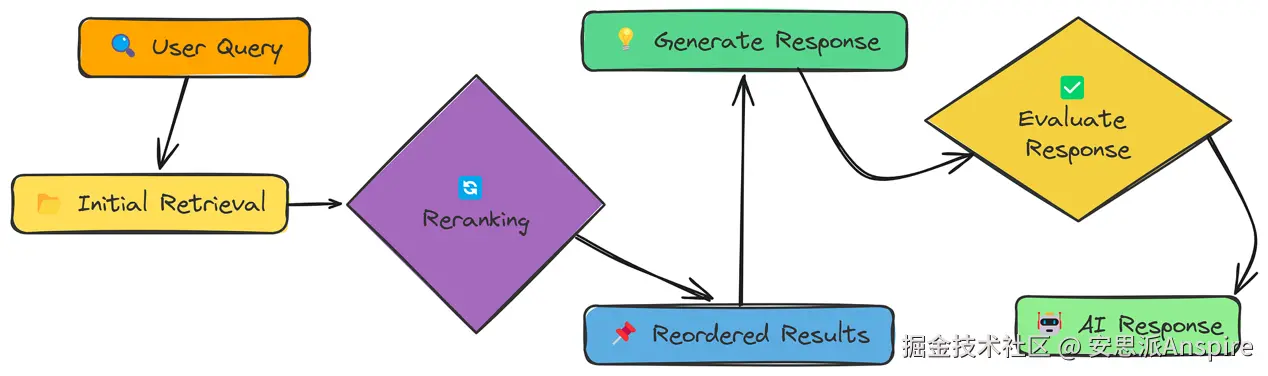
重排序器
重排序是第二次处理,会对初始检索到的结果重新排序,把最好的结果放在最前面。
rerank_with_llm函数接收初始检索到的块,并使用LLM根据相关性对它们重新排序。这有助于确保最有用的信息排在前面。
重排序后,一个名为generate_final_response的最终函数会接收重新排序后的块,将其格式化为提示词,然后发送给LLM以生成最终响应。
ini
def rag_with_reranking(query, vector_store, reranking_method="llm", top_n=3, model="meta-llama/Llama-3.2-3B-Instruct"):
"""
包含重排序的完整RAG流程。
"""
# 创建查询嵌入
query_embedding = create_embeddings(query)
# 初始检索(获取比需要更多的结果用于重排序)
initial_results = vector_store.similarity_search(query_embedding, k=10)
# 应用重排序
if reranking_method == "llm":
reranked_results = rerank_with_llm(query, initial_results, top_n=top_n)
elif reranking_method == "keywords":
reranked_results = rerank_with_keywords(query, initial_results, top_n=top_n) # 我们不使用这个
else:
# 不进行重排序,只使用初始检索的前几名结果
reranked_results = initial_results[:top_n]
# 合并重排序结果中的上下文
context = "\n\n===\n\n".join([result["text"] for result in reranked_results])
# 基于上下文生成响应
response = generate_response(query, context, model)
return {
"query": query,
"reranking_method": reranking_method,
"initial_results": initial_results[:top_n],
"reranked_results": reranked_results,
"context": context,
"response": response
}它接收查询、向量存储(我们已创建)和重排序方法。我们使用"llm"表示基于LLM的重排序。该函数执行初始检索,调用rerank_with_llm对结果重新排序,然后生成响应。
notebook中定义了rerank_with_keywords,但我们这里不使用。
让我们运行它,看看是否能改进结果:
ini
# 使用基于LLM的重排序运行RAG
llm_reranked_result = rag_with_reranking(query, vector_store, reranking_method="llm")
# 评估
evaluation_prompt = f"User Query: {query}\nAI Response:\n{llm_reranked_result['response']}\nTrue Response: {reference_answer}\n{evaluate_system_prompt}"
evaluation_response = generate_response(evaluate_system_prompt, evaluation_prompt)
print(evaluation_response.choices[0].message.content)
### 输出 ###
Evaluation score is 0.7我们的评估分数现在约为0.7!
重排序带来了显著改进。通过使用LLM直接为每个检索到的文档的相关性打分,我们能够优先考虑用于生成响应的最佳信息。
这是一项强大的技术,能显著提升RAG系统的质量。
RSE
我们一直关注单个块,但有时最好的信息分布在多个连续的块中。相关片段提取(Relevant Segment Extraction,RSE)正是为解决这个问题而设计的。
RSE不只是获取前k个块,而是尝试识别并提取整个相关文本片段。
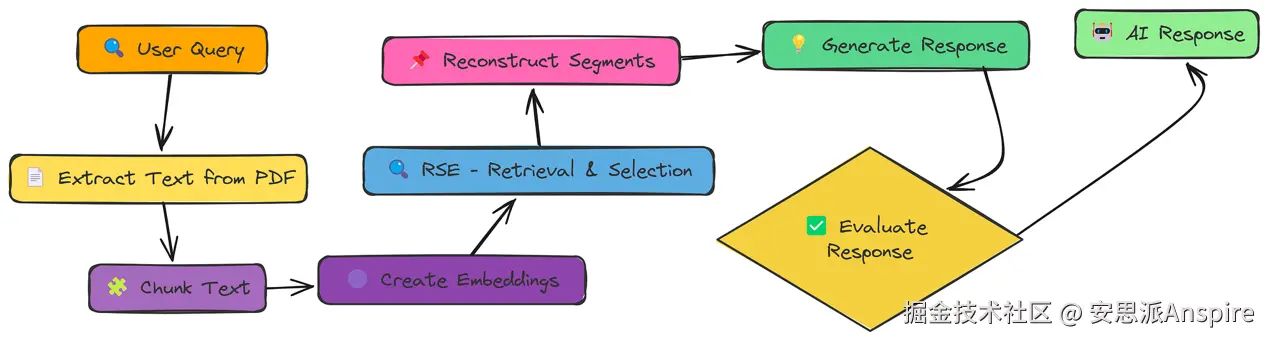
RSE
让我们看看如何在现有流程中实现它,我们会使用已定义的RSE相关函数。我们添加rag_with_rse函数调用,它接收pdf路径和查询并返回响应。
结合多个函数调用来执行RSE:
ini
# 使用RSE运行RAG
rse_result = rag_with_rse(pdf_path, query)这一行代码做了很多事情,它:
-
处理文档(提取文本、分块、创建嵌入,所有这些都在rag_with_rse内部处理)。
-
基于与查询的相关性和位置计算"块值"。
-
使用巧妙的算法找到最佳的连续块片段。
-
将这些片段合并为上下文。
-
基于该上下文生成响应。
现在进行评估:
python
# 评估
evaluation_prompt = f"User Query: {query}\nAI Response:\n{rse_result['response']}\nTrue Response: {reference_answer}\n{evaluate_system_prompt}"
evaluation_response = generate_response(evaluate_system_prompt, evaluation_prompt)
print(evaluation_response.choices[0].message.content)
### 输出 ###
然而,标准检索的响应包含......
我会给AI响应打0.8分我们得到了约0.8的分数!
通过聚焦于连续的相关文本片段,RSE为LLM提供了更连贯、更完整的上下文,从而生成更准确、更全面的响应。
这表明,我们选择和呈现给LLM的信息的"方式",与我们选择的信息"内容"同样重要。
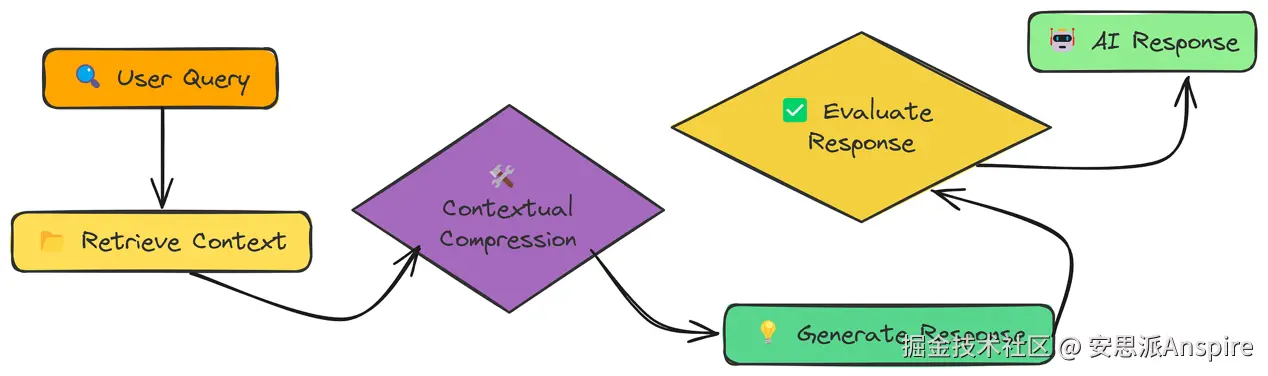
上下文压缩
我们一直在不断增加上下文------相邻块、生成的问题、完整片段等。但有时候,"少即是多"。
大语言模型(LLMs)的上下文窗口有限,塞满无关信息反而会影响性能。
上下文压缩
上下文压缩的核心是"选择性保留"。我们先检索足够多的上下文,然后对其进行压缩,只保留与查询直接相关的部分。这里的关键差异是生成响应前的"上下文压缩"步骤。我们没有改变检索到的内容,但在将其传递给LLM之前进行了优化。
我们在这里使用rag_with_compression函数调用,它接收查询和其他参数,实现上下文压缩。在内部,它利用LLM分析检索到的块,只提取与查询直接相关的句子或段落。
让我们看看实际应用:
python
def rag_with_compression(pdf_path, query, k=10, compression_type="selective", model="meta-llama/Llama-3.2-3B-Instruct"):
"""
带有上下文压缩的检索增强生成(RAG)流程。
参数:
pdf_path (str):PDF文档的路径。
query (str):用于检索的用户查询。
k (int):要检索的最相关块的数量。默认值为10。
compression_type (str):应用于检索到的块的压缩类型。默认值为"selective"。
model (str):用于生成响应的语言模型。默认值为"meta-llama/Llama-3.2-3B-Instruct"。
返回:
dict:包含查询、原始块与压缩块、压缩统计信息以及最终响应的字典。
"""
print(f"\n=== 带压缩的RAG ===\n查询:{query} | 压缩类型:{compression_type}")
# 处理文档以提取、分块和嵌入文本
vector_store = process_document(pdf_path)
# 基于查询相似度检索前k个相关块
results = vector_store.similarity_search(create_embeddings(query), k=k)
retrieved_chunks = [r["text"] for r in results]
# 对检索到的块应用压缩
compressed = batch_compress_chunks(retrieved_chunks, query, compression_type, model)
# 过滤掉空的压缩块;如果全部为空则回退到原始块
compressed_chunks, compression_ratios = zip(*[(c, r) for c, r in compressed if c.strip()] or [(chunk, 0.0) for chunk in retrieved_chunks])
# 合并压缩块以形成生成响应的上下文
context = "\n\n---\n\n".join(compressed_chunks)
# 使用压缩后的上下文生成响应
response = generate_response(query, context, model)
print(f"\n=== 响应 ===\n{response}")
# 返回详细结果
return {
"query": query,
"original_chunks": retrieved_chunks,
"compressed_chunks": compressed_chunks,
"compression_ratios": compression_ratios,
"context_length_reduction": f"{sum(compression_ratios)/len(compression_ratios):.2f}%",
"response": response
}rag_with_compression提供了多种压缩类型选项:
-
"selective":只保留直接相关的句子。
-
"summary":生成聚焦于查询的简短摘要。
-
"extraction":仅提取包含答案的句子(非常严格!)。
现在,我们用以下代码运行压缩:
ini
# 使用上下文压缩运行RAG(采用'selective'模式)
compression_result = rag_with_compression(pdf_path, query, compression_type="selective")
# 评估
evaluation_prompt = f"User Query: {query}\nAI Response:\n{compression_result['response']}\nTrue Response: {reference_answer}\n{evaluate_system_prompt}"
evaluation_response = generate_response(evaluate_system_prompt, evaluation_prompt)
print(evaluation_response.choices[0].message.content)
### 输出 ###
Evaluation Score 0.75评估工具给了我们约0.75的分数。
上下文压缩是一项强大的技术,因为它平衡了"广度"(初始检索获取广泛信息)和"聚焦"(压缩去除噪声)。
通过只给LLM提供最相关的信息,我们通常能得到更简洁、更准确的答案。
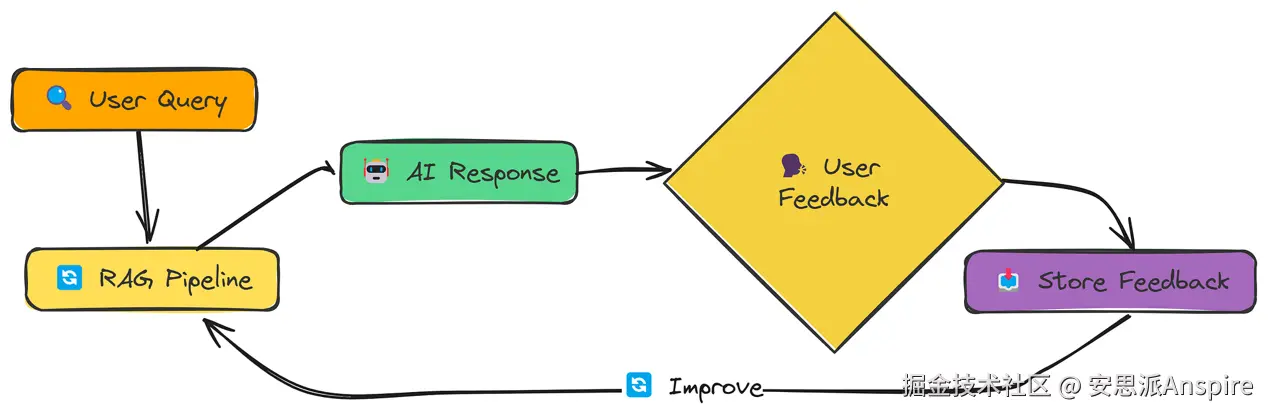
反馈循环
到目前为止,我们看到的所有技术都是"静态"的,它们不会从错误中学习。而反馈循环改变了这一点。
核心思路很简单:
-
用户对RAG系统的响应提供反馈(例如,好/坏、相关/不相关)。
-
系统存储该反馈。
-
未来的检索利用这些反馈进行改进。
反馈循环
我们可以使用full_rag_workflow函数调用来实现反馈循环。以下是函数定义:
python
def full_rag_workflow(pdf_path, query, feedback_data=None, feedback_file="feedback_data.json", fine_tune=False):
"""
执行完整的RAG工作流程,集成反馈以实现持续改进。
"""
# 步骤1:如果未明确提供,加载历史反馈用于相关性调整
if feedback_data is None:
feedback_data = load_feedback_data(feedback_file)
print(f"从{feedback_file}加载了{len(feedback_data)}条反馈记录")
# 步骤2:通过提取、分块和嵌入管道处理文档
chunks, vector_store = process_document(pdf_path)
# 步骤3:通过整合高质量的历史交互来微调向量索引
# 这会从成功的问答对中创建增强的可检索内容
if fine_tune and feedback_data:
vector_store = fine_tune_index(vector_store, chunks, feedback_data)
# 步骤4:执行带有反馈感知检索的核心RAG
# 注意:这依赖于rag_with_feedback_loop函数,该函数应在其他地方定义
result = rag_with_feedback_loop(query, vector_store, feedback_data)
# 步骤5:收集用户反馈以改进未来性能
print("\n=== 您想对这个响应提供反馈吗? ===")
print("评分相关性(1-5,5表示最相关):")
relevance = input()
print("评分质量(1-5,5表示最高质量):")
quality = input()
print("任何评论?(可选,按Enter跳过)")
comments = input()
# 步骤6:将反馈格式化为结构化数据
feedback = get_user_feedback(
query=query,
response=result["response"],
relevance=int(relevance),
quality=int(quality),
comments=comments
)
# 步骤7:持久化反馈以实现系统的持续学习
store_feedback(feedback, feedback_file)
print("反馈已记录。感谢您的参与!")
return result这个full_rag_workflow函数做了几件事:
-
加载现有反馈:检查feedback_data.json文件并加载任何先前的反馈。
-
运行RAG流程:这部分与我们之前做的类似。
-
请求反馈:提示用户对响应的相关性和质量进行评分。
-
存储反馈:将反馈保存到feedback_data.json文件。
反馈如何实际用于改进检索的机制更为复杂,发生在fine_tune_index、adjust_relevance_scores等函数内部(为简洁起见,此处未展示)。但核心思想是,正面反馈可以提高某些文档的相关性,而负面反馈可以降低其相关性。
让我们运行一个简化版本,假设没有任何现有反馈:
ini
# 我们没有先前的反馈,因此"fine_tune=False"
result = full_rag_workflow(pdf_path=pdf_path, query=query, fine_tune=False)
# 评估
evaluation_prompt = f"User Query: {query}\nAI Response:\n{result['response']}\nTrue Response: {reference_answer}\n{evaluate_system_prompt}"
evaluation_response = generate_response(evaluate_system_prompt, evaluation_prompt)
print(evaluation_response.choices[0].message.content)
### 输出 ###
Evaluation score is 0.7 because ....我们得到了约0.7的分数!
这并不是一个巨大的飞跃,这符合预期。反馈循环会随着时间的推移,通过反复交互来改进系统。本节仅展示其机制。真正的力量来自于积累反馈并利用它优化检索过程。这使得RAG系统能够根据接收的查询类型进行"自适应"调整和"个性化"优化。
今天的内容到这里就结束啦。接下来我们会继续更新对RAG技术的探索和分析,欢迎感兴趣的小伙伴们继续关注!