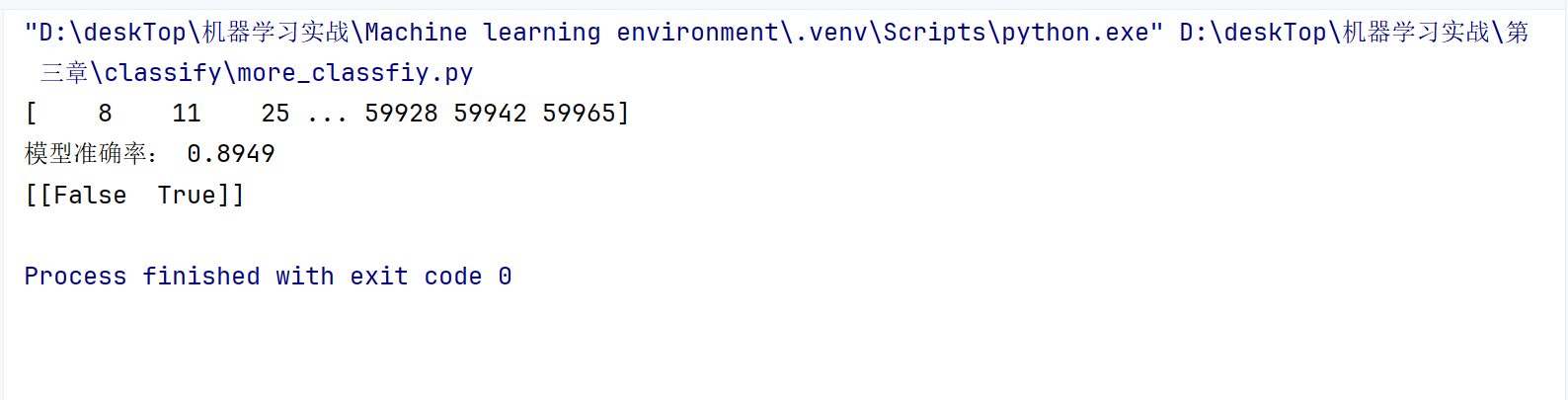
2.1.6 ROC曲线
ROC 曲线简单说就是评估二分类模型好不好用的一张图。
-
横纵轴是啥?
纵轴:模型抓对 "正例" 的比例(比如真正把癌症患者查出来的概率);
横轴:模型冤枉 "负例" 的比例(比如把健康人错当成癌症患者的概率)。
-
曲线怎么看?
曲线越往左上角靠,说明模型越牛 ------ 能多抓对正例,少冤枉负例。
如果曲线是从左下角到右上角的对角线,那模型跟瞎猜差不多(比如抛硬币)。
-
AUC 是啥?
就是 ROC 曲线下面的面积,用来给模型打分。面积越接近 1,模型越好;0.5 就是瞎猜
python
# 导入需要的库
# fetch_openml用于获取公开数据集,这里用于加载MNIST手写数字数据集
from sklearn.datasets import fetch_openml
# numpy用于数值计算和数组操作
import numpy as np
# matplotlib.pyplot用于数据可视化
import matplotlib.pyplot as plt
# SGDClassifier是随机梯度下降分类器,适用于大规模数据集
from sklearn.linear_model import SGDClassifier
# cross_val_score用于交叉验证评分,cross_val_predict用于交叉验证预测
from sklearn.model_selection import cross_val_score, cross_val_predict
# roc_curve用于计算ROC曲线所需的假正例率和真正例率
from sklearn.metrics import roc_curve
# 设置matplotlib支持中文显示
# 解决中文显示为方框的问题
plt.rcParams["font.family"] = ["SimHei", "WenQuanYi Micro Hei", "Heiti TC"]
# 解决负号显示异常的问题
plt.rcParams["axes.unicode_minus"] = False
# 获取MNIST数据集
# 'mnist_784'是数据集名称,包含70000张28x28像素的手写数字图片
# version=1指定数据集版本
# data_home指定数据集下载后保存的本地路径(可根据实际情况修改)
# as_frame=False表示返回numpy数组格式而非DataFrame
mnist = fetch_openml('mnist_784', version=1, data_home="D:\\deskTop\\机器学习实战\\第三章", as_frame=False)
# 提取特征数据和标签
# X包含所有图像的像素数据,形状为(70000, 784),每行代表一张图片的784个像素(28×28)
# y包含所有图像对应的标签,形状为(70000,),存储的是0-9的字符串形式数字
X, y = mnist.data, mnist.target
# 划分训练集和测试集
# MNIST数据集默认前60000个样本为训练集,后10000个为测试集
X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:]
# 打乱训练集顺序
# 生成0-59999的随机排列索引,用于打乱训练集,避免数据顺序对模型产生影响
shuffle_index = np.random.permutation(60000)
# 根据随机索引重新排列训练集的特征和标签
X_train, y_train = X_train[shuffle_index], y_train[shuffle_index]
# 创建二分类标签:是否为数字5
# 将原始标签转换为布尔值,True表示该样本是数字5,False表示不是
# 这样就将问题转化为"是5"和"不是5"的二分类问题(便于演示ROC曲线)
y_train_5 = (y_train == '5') # 训练集的二分类标签
y_test_5 = (y_test == '5') # 测试集的二分类标签
# 初始化并训练SGD分类器
# SGDClassifier使用随机梯度下降算法,适合处理大型数据集
# random_state=42设置随机种子,保证结果可复现
sgd_clf = SGDClassifier(random_state=42)
# 使用训练集训练模型,学习如何区分数字5和非5
sgd_clf.fit(X_train, y_train_5)
# 使用交叉验证获取决策分数
# cross_val_predict进行交叉验证,并返回每个样本的决策分数
# cv=3表示3折交叉验证,将训练集分成3份,轮流用2份训练1份验证
# method="decision_function"表示返回决策函数的值(而非预测类别),用于后续计算不同阈值下的性能
y_scores = cross_val_predict(
sgd_clf, X_train, y_train_5,
cv=3, method="decision_function"
)
# 计算ROC曲线的关键参数
# fpr: 假正例率数组,tpr: 真正例率数组,threshold: 对应的阈值数组
fpr, tpr, threshold = roc_curve(y_train_5, y_scores)
# 定义绘制ROC曲线的函数
def plot_roc_curve(fpr, tpr, label=None):
# 绘制ROC曲线
plt.plot(fpr, tpr, linewidth=2, label=label)
# 绘制随机猜测的基准线(对角线)
plt.plot([0, 1], [0, 1], 'k--')
# 设置坐标轴范围
plt.axis([0, 1, 0, 1])
# 设置坐标轴标签
plt.xlabel('假正例率 (FPR)')
plt.ylabel('真正例率 (TPR)')
# 调用函数绘制ROC曲线并显示
plot_roc_curve(fpr, tpr)
plt.show()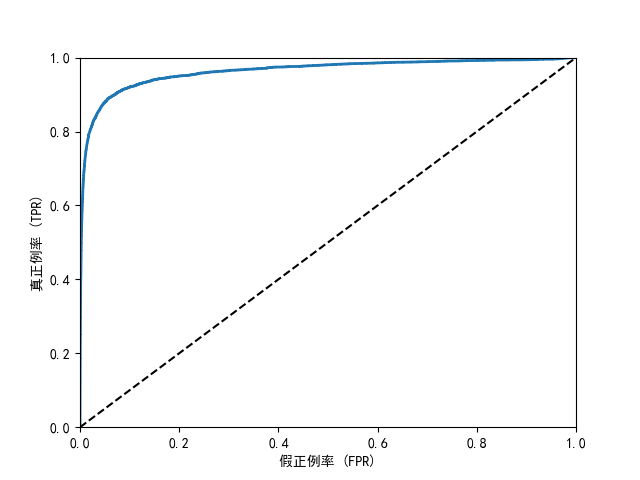
计算AUC
python
from sklearn.metrics import roc_auc_score
......
print(roc_auc_score(y_train_5, y_scores))
三、多类别分类器
SGDClassifier 能够直接处理多分类任务(识别 0-9 共 10 个数字),核心原因是它内部默认使用了 "一对多"(One-vs-Rest,简称 OvR) 的策略来实现多分类。
当面对 MNIST 这种 10 个类别(0-9)的分类任务时,SGDClassifier 会自动创建 10 个二分类器:
- 第 1 个分类器:区分 "是 0" 和 "不是 0"
- 第 2 个分类器:区分 "是 1" 和 "不是 1"
- ...
- 第 10 个分类器:区分 "是 9" 和 "不是 9"
当用训练好的模型预测新样本时:
- 10 个二分类器会分别对该样本进行预测,输出各自的 "置信度分数"(表示样本属于对应类别的可能性)
- 最终选择 置信度最高的类别 作为预测结果
python
from sklearn.datasets import fetch_openml
import numpy as np
from sklearn.linear_model import SGDClassifier
from sklearn.metrics import accuracy_score
mnist = fetch_openml('mnist_784', version=1, data_home="D:\\deskTop\\机器学习实战\\第三章", as_frame=False)
X, y = mnist.data, mnist.target
X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:]
shuffle_index = np.random.permutation(60000)
X_train, y_train = X_train[shuffle_index], y_train[shuffle_index]
sgd_clf = SGDClassifier(random_state=42)
# 使用训练集的特征和标签数据训练分类器,让模型学习数据中的模式
sgd_clf.fit(X_train, y_train)
# 使用训练好的分类器对测试集的特征数据进行预测,得到预测标签结果
sgd_pred = sgd_clf.predict(X_test)
# 打印预测的测试集标签结果,查看模型预测输出
print(sgd_pred)
# 打印测试集真实的标签结果,可用于后续对比评估模型预测效果
print(y_test)
#输出多分类器的精确率
print("准确率:", accuracy_score(y_test, sgd_pred))
将训练集进行标准化处理并交叉验证
python
# 导入需要的库
# fetch_openml用于获取公开数据集,这里将用于获取MNIST手写数字数据集
from sklearn.datasets import fetch_openml
# numpy用于数值计算和数组操作
import numpy as np
# SGDClassifier是随机梯度下降分类器,适用于大规模数据集
from sklearn.linear_model import SGDClassifier
# accuracy_score用于计算分类准确率
from sklearn.metrics import accuracy_score
# StandardScaler用于数据标准化处理
from sklearn.preprocessing import StandardScaler
# cross_val_score和cross_val_predict用于交叉验证
from sklearn.model_selection import cross_val_score, cross_val_predict
# 获取MNIST数据集
# 'mnist_784'是数据集名称,包含70000张28x28像素的手写数字图片
# version=1指定数据集版本
# data_home指定数据下载后保存的本地路径
# as_frame=False表示返回numpy数组形式而非DataFrame
mnist = fetch_openml('mnist_784', version=1, data_home="D:\\deskTop\\机器学习实战\\第三章", as_frame=False)
# 分离特征数据(X)和标签数据(y)
# X包含图像的像素信息,每个样本是784个特征(28x28)
# y包含对应的数字标签(0-9)
X, y = mnist.data, mnist.target
# 划分训练集和测试集
# 前60000个样本作为训练集,后10000个作为测试集
X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:]
# 打乱训练集顺序
# 生成0-59999的随机排列索引,用于打乱训练数据,避免数据顺序对模型产生影响
shuffle_index = np.random.permutation(60000)
# 应用打乱的索引,重新排列训练集的特征和标签
X_train, y_train = X_train[shuffle_index], y_train[shuffle_index]
# 初始化SGD分类器
# random_state=42设置随机种子,保证结果可重现
sgd_clf = SGDClassifier(random_state=42)
# 训练分类器
# 使用训练集的特征和标签数据进行模型训练,让模型学习数据中的模式
sgd_clf.fit(X_train, y_train)
# 使用训练好的分类器对测试集进行预测
# 对测试集的特征数据X_test进行预测,得到预测标签结果sgd_pred
sgd_pred = sgd_clf.predict(X_test)
# 打印测试集的预测结果
print("测试集预测结果:", sgd_pred)
# 计算并输出模型在测试集上的准确率
# 准确率 = 预测正确的样本数 / 总样本数
print("模型准确率:", accuracy_score(y_test, sgd_pred))
# 数据标准化处理
# StandardScaler会将数据转换为均值为0,标准差为1的分布
scaler = StandardScaler()
# 对训练集进行标准化处理(先拟合再转换)
# astype(np.float64)将数据转换为float64类型,便于标准化计算
X_train_scaled = scaler.fit_transform(X_train.astype(np.float64))
# 使用交叉验证评估标准化后的模型性能
# cv=3表示将训练集分成3份,进行3折交叉验证
# scoring='accuracy'表示使用准确率作为评估指标
# 输出每折交叉验证的准确率
print("标准化后交叉验证准确率:", cross_val_score(sgd_clf, X_train_scaled, y_train, cv=3, scoring='accuracy'))
什么叫标准化?
代码处理的是 MNIST 手写数字图片,每张图片是 28×28 像素,所以每个样本有 784 个特征(每个特征就是一个像素的亮度值)。这些像素的原始值范围是 0-255(0 是黑色,255 是白色)。标准化在这里的作用就是把这 784 个像素的数值,都转换成「均值为 0、标准差为 1」的范围(大部分数值会落在 - 2 到 2 之间)。
为什么要这么做?
SGDClassifier(随机梯度下降分类器)它的学习过程受特征数值大小影响很大。如果不标准化,像素值 0-255 的范围对模型来说是 "大尺度",会导致模型在更新时不稳定,可能学不好。特征数值越大(比如 255),计算出的梯度就可能越大。这会让模型参数的更新幅度变得很极端 ------ 有时候跳得太猛,错过最优值;有时候又调整不足,停在较差的位置。标准化后,所有像素特征的数值尺度统一了,SGD 分类器能更稳定地 "学习" 每个像素对识别数字的影响,最终效果通常会更好。
四、错误分析
4.1 计算并绘制混淆矩阵
python
from sklearn.datasets import fetch_openml
import numpy as np
from sklearn.linear_model import SGDClassifier
from sklearn.metrics import accuracy_score, confusion_matrix
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import cross_val_predict
import matplotlib.pyplot as plt
mnist = fetch_openml('mnist_784', version=1, data_home="D:\\deskTop\\机器学习实战\\第三章", as_frame=False)
X, y = mnist.data, mnist.target
X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:]
shuffle_index = np.random.permutation(60000)
X_train, y_train = X_train[shuffle_index], y_train[shuffle_index]
sgd_clf = SGDClassifier(random_state=42)
sgd_clf.fit(X_train, y_train)
sgd_pred = sgd_clf.predict(X_test)
print("测试集预测结果:", sgd_pred)
print("模型准确率:", accuracy_score(y_test, sgd_pred))
# 数据标准化处理(优化模型性能)
# StandardScaler会将每个特征转换为均值为0、标准差为1的分布(消除尺度差异)
scaler = StandardScaler()
# 对训练集进行标准化处理:先拟合(计算均值和标准差)再转换(应用标准化公式)
# astype(np.float64)将数据转换为float64类型(原始为uint8,避免标准化时精度损失)
X_train_scaled = scaler.fit_transform(X_train.astype(np.float64))
# 使用交叉验证获取训练集的预测结果
# cross_val_predict:将训练集分为3折(cv=3),每次用2折训练、1折预测,最终返回所有样本的预测结果
y_train_pred = cross_val_predict(sgd_clf, X_train_scaled, y_train, cv=3)
# 生成混淆矩阵(评估分类器的错误模式)
# 混淆矩阵是10x10的矩阵(对应10个数字),行=实际类别,列=预测类别,值=样本数量
conf_mx = confusion_matrix(y_train, y_train_pred)
print(conf_mx) # 打印混淆矩阵的数值
# 可视化混淆矩阵(用灰度图直观展示错误分布)
# plt.matshow:绘制矩阵热力图,cmap=plt.cm.gray设置为灰度配色(值越大越亮)
plt.matshow(conf_mx, cmap=plt.cm.gray)
# 显示图像
plt.show()
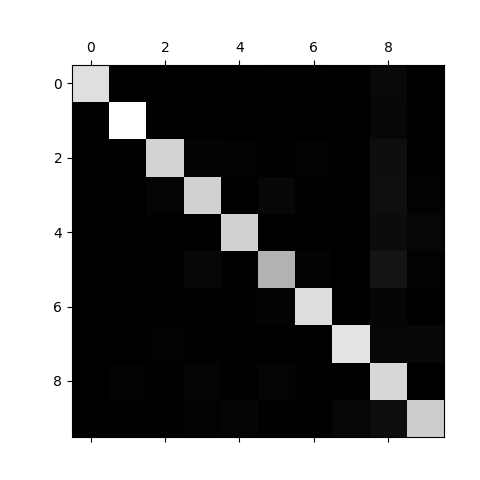
混淆矩阵是个 10x10 的表格(因为要识别 0-9 共 10 个数字),表格里的每个数字都代表「实际是 A 类,却被模型预测成 B 类」的样本数量。
行和列分别代表什么?
- 行:代表「实际的数字类别」(比如第 1 行是实际为 0 的样本,第 2 行是实际为 1 的样本,...,第 10 行是实际为 9 的样本)。
- 列:代表「模型预测的数字类别」(比如第 1 列是预测为 0 的结果,第 2 列是预测为 1 的结果,...,第 10 列是预测为 9 的结果)。
看具体数值:
python[[5612 0 18 5 10 44 36 7 189 2] → 第0行(实际是0的样本) [ 0 6420 48 23 3 43 4 8 181 12]] → 第1行(实际是1的样本)看对角线(正确分类的情况):
- 第 0 行第 0 列的
5612:实际是 0,且被正确预测为 0 的样本有 5612 个(这是好事,数值越大越好)。- 第 1 行第 1 列的
6420:实际是 1,且被正确预测为 1 的样本有 6420 个(也是好事)。- 对角线其他位置的数值,都是「实际是 X,预测也是 X」的正确样本数。
看非对角线(错误分类的情况):
图中每个格子的亮度 对应数值大小(代码里用了
cmap=plt.cm.gray灰度配色):
- 第 0 行第 8 列的
189:实际是 0,但被模型错当成 8 的样本有 189 个(这是 0 最容易被认错的情况)。- 第 1 行第 8 列的
181:实际是 1,但被错当成 8 的样本有 181 个(1 也容易被认错成 8)。- 其他非对角线数值,比如第 0 行第 5 列的
44:实际是 0,被错当成 5 的有 44 个。
- 越亮的格子:数值越大,代表这类情况出现的样本越多。
- 越暗的格子:数值越小,代表这类情况出现的样本越少。
4.2 计算并绘制错误率
python
# 导入需要的库
# fetch_openml用于获取公开数据集,这里将用于获取MNIST手写数字数据集
from sklearn.datasets import fetch_openml
# numpy用于数值计算和数组操作
import numpy as np
# SGDClassifier是随机梯度下降分类器,适用于大规模数据集
from sklearn.linear_model import SGDClassifier
# accuracy_score用于计算分类准确率,confusion_matrix用于生成混淆矩阵
from sklearn.metrics import accuracy_score, confusion_matrix
# StandardScaler用于数据标准化处理
from sklearn.preprocessing import StandardScaler
# cross_val_score和cross_val_predict用于交叉验证(评估模型和获取交叉预测结果)
from sklearn.model_selection import cross_val_score, cross_val_predict
# matplotlib.pyplot用于数据可视化(这里用于绘制混淆矩阵)
import matplotlib.pyplot as plt
mnist = fetch_openml('mnist_784', version=1, data_home="D:\\deskTop\\机器学习实战\\第三章", as_frame=False)
X, y = mnist.data, mnist.target
X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:]
shuffle_index = np.random.permutation(60000)
X_train, y_train = X_train[shuffle_index], y_train[shuffle_index]
sgd_clf = SGDClassifier(random_state=42)
sgd_clf.fit(X_train, y_train)
sgd_pred = sgd_clf.predict(X_test)
print("模型准确率:", accuracy_score(y_test, sgd_pred))
# 数据标准化处理(优化模型性能)
# StandardScaler会将每个特征转换为均值为0、标准差为1的分布(消除尺度差异)
scaler = StandardScaler()
# 对训练集进行标准化处理:先拟合(计算均值和标准差)再转换(应用标准化公式)
# astype(np.float64)将数据转换为float64类型(原始为uint8,避免标准化时精度损失)
X_train_scaled = scaler.fit_transform(X_train.astype(np.float64))
# 使用交叉验证获取训练集的预测结果
# cross_val_predict:将训练集分为3折(cv=3),每次用2折训练、1折预测,最终返回所有样本的预测结果
y_train_pred = cross_val_predict(sgd_clf, X_train_scaled, y_train, cv=3)
# 生成混淆矩阵(评估分类器的错误模式)
# 混淆矩阵是10x10的矩阵(对应10个数字),行=实际类别,列=预测类别,值=样本数量
conf_mx = confusion_matrix(y_train, y_train_pred)
# 计算每行的总和(每个实际类别的总样本数)
# axis=1表示按行求和,keepdims=True保持结果为二维数组(便于后续除法广播)
rows_sums = conf_mx.sum(axis=1, keepdims=True)
# 对混淆矩阵进行归一化处理(将每个元素转换为占该行总和的比例)
# 目的是消除类别样本数量差异的影响,更清晰地展示错误比例
norm_conf_mx = conf_mx / rows_sums
# 将归一化混淆矩阵的对角线元素填充为0
# 对角线代表正确分类,填充为0后,图像仅展示错误分类的比例(更聚焦于错误模式)
np.fill_diagonal(norm_conf_mx, 0)
# 可视化归一化后的混淆矩阵(仅展示错误分类比例)
# cmap=plt.cm.gray设置为灰度配色,越亮的区域表示错误比例越高
plt.matshow(norm_conf_mx, cmap=plt.cm.gray)
# 显示图像
plt.show()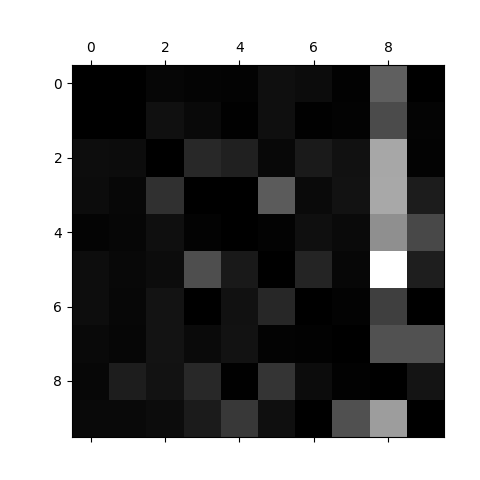
norm_conf_mx = conf_mx / rows_sums:
这段代码是用每行的错误数除以该行的总样本数(即该类别的总样本数),把 "错误数量" 转换成 "错误比例"。MNIST 中不同数字的样本数量可能不同(比如可能数字 1 的样本比数字 8 多)。如果不归一化,你看到的 "错误数" 可能受样本总量影响(样本多的数字错误数自然可能更多),无法判断是 "本身容易分错" 还是 "只是样本多所以错得多"。归一化后,每个数值都代表 "该类样本被错分成其他类的比例",直接反映了模型对该类别的分类难度,能更公平地比较不同类别的错误情况。
此外,第8、9列尤其是第8列的亮度比较亮说明说明许多的数字被混淆成8了,同样的第2、3、5、9行比较亮说明很容易和其他数字混淆。
五、多标签分类
在机器学习中,多标签分类(Multi-label Classification) 是一种特殊的分类任务,其核心特点是:一个样本可以同时属于多个类别标签,而非仅属于唯一的类别。与传统的单标签分类(如 "二分类""多类分类",每个样本仅对应一个标签)不同,多标签分类需要模型为每个样本预测出所有可能相关的标签集合。
- 《少年派的奇幻漂流》可以同时被标记为 "冒险""奇幻""剧情"。
- 《盗梦空间》可以同时属于 "科幻""悬疑""动作""犯罪"。
- 模型需要识别出所有符合电影内容的类型,而不是只能选一种类型。
- 一篇关于 "AI 在医疗领域用于癌症诊断" 的新闻,标签可能是 "科技""人工智能""医疗""健康"。
- 一篇关于 "冬奥会运动员饮食管理" 的新闻,标签可能是 "体育""冬奥会""营养学"。
python
# 导入需要的库
# fetch_openml用于获取公开数据集,这里将用于获取MNIST手写数字数据集
from sklearn.datasets import fetch_openml
# numpy用于数值计算和数组操作
import numpy as np
# SGDClassifier是随机梯度下降分类器,适用于大规模数据集
from sklearn.linear_model import SGDClassifier
# accuracy_score用于计算分类准确率,confusion_matrix用于生成混淆矩阵
from sklearn.metrics import accuracy_score, confusion_matrix
# StandardScaler用于数据标准化处理
from sklearn.preprocessing import StandardScaler
# cross_val_score和cross_val_predict用于交叉验证(评估模型和获取交叉预测结果)
from sklearn.model_selection import cross_val_score, cross_val_predict
# KNeighborsClassifier是K近邻分类器,基于实例的学习算法
from sklearn.neighbors import KNeighborsClassifier
# 设置numpy随机种子,确保实验结果可重现
np.random.seed(42)
# 获取MNIST手写数字数据集
# 'mnist_784'是数据集标识,包含70000张28x28像素的手写数字图片
# version=1指定数据集版本,data_home指定数据下载路径
# as_frame=False表示返回numpy数组而非pandas DataFrame
mnist = fetch_openml('mnist_784', version=1, data_home="D:\\deskTop\\机器学习实战\\第三章", as_frame=False)
# 提取特征数据(X)和标签数据(y)
# X是图像像素数据,形状为(70000, 784),每张图片展平为784个特征(28×28)
# y是对应的数字标签,形状为(70000,),取值为0-9的字符串
X, y = mnist.data, mnist.target
# 划分训练集和测试集
# 前60000个样本作为训练集,后10000个作为测试集(MNIST数据集的标准划分方式)
X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:]
# 打乱训练集顺序,避免数据中的潜在顺序对模型训练产生影响
# np.random.permutation生成0-59999的随机排列索引
shuffle_index = np.random.permutation(60000)
# 根据随机索引重新排列训练集特征和标签
X_train, y_train = X_train[shuffle_index], y_train[shuffle_index]
# 查找训练集中所有标签为'5'的样本索引
# np.where返回满足条件的元素索引,这里用于定位所有数字5的样本
five_indices = np.where(y_train == '5')[0]
# 打印这些索引(可用于后续分析或可视化数字5的样本)
print(five_indices)
# 初始化随机梯度下降分类器
# SGDClassifier适用于大规模数据集,通过随机梯度下降优化损失函数
# random_state=42确保初始化的随机性是可重现的
sgd_clf = SGDClassifier(random_state=42)
# 在训练集上训练模型
# 模型将学习从图像像素(X_train)到数字标签(y_train)的映射关系
sgd_clf.fit(X_train, y_train)
# 使用训练好的模型在测试集上进行预测
sgd_pred = sgd_clf.predict(X_test)
# 计算并打印模型在测试集上的准确率
# 准确率 = 预测正确的样本数 / 总样本数
print("模型准确率:", accuracy_score(y_test, sgd_pred))
# 数据标准化处理(优化模型性能)
# StandardScaler会将每个特征转换为均值为0、标准差为1的分布(消除尺度差异)
scaler = StandardScaler()
# 对训练集进行标准化处理:先拟合(计算均值和标准差)再转换(应用标准化公式)
# astype(np.float64)将数据转换为float64类型(原始为uint8,避免标准化时精度损失)
X_train_scaled = scaler.fit_transform(X_train.astype(np.float64))
# 使用交叉验证获取训练集的预测结果
# cross_val_predict:将训练集分为3折(cv=3),每次用2折训练、1折预测
# 最终返回所有样本的预测结果,可用于评估模型性能或生成混淆矩阵
y_train_pred = cross_val_predict(sgd_clf, X_train_scaled, y_train, cv=3)
# 创建多标签分类的目标变量
# 第一个标签:数字是否大于7(True/False)
y_train_large = (y_train.astype(int) > 7)
# 第二个标签:数字是否为奇数(True/False)
y_train_odd = (y_train.astype(int) % 2 == 1)
# 将两个标签组合成多标签目标矩阵,形状为(60000, 2)
y_multilabel = np.c_[y_train_large, y_train_odd]
# 初始化K近邻分类器
knn_clf = KNeighborsClassifier()
# 使用多标签目标训练K近邻模型
# K近邻算法通过寻找相似样本的标签进行预测,适合多标签分类
knn_clf.fit(X_train, y_multilabel)
# 对第11个样本进行预测(注意:这里使用的是原始数据集X,而非划分后的训练集)
# 预测结果将是一个包含两个布尔值的数组,表示[是否大于7, 是否为奇数]
knn_pred = knn_clf.predict([X[11]])
# 打印预测结果
print(knn_pred)