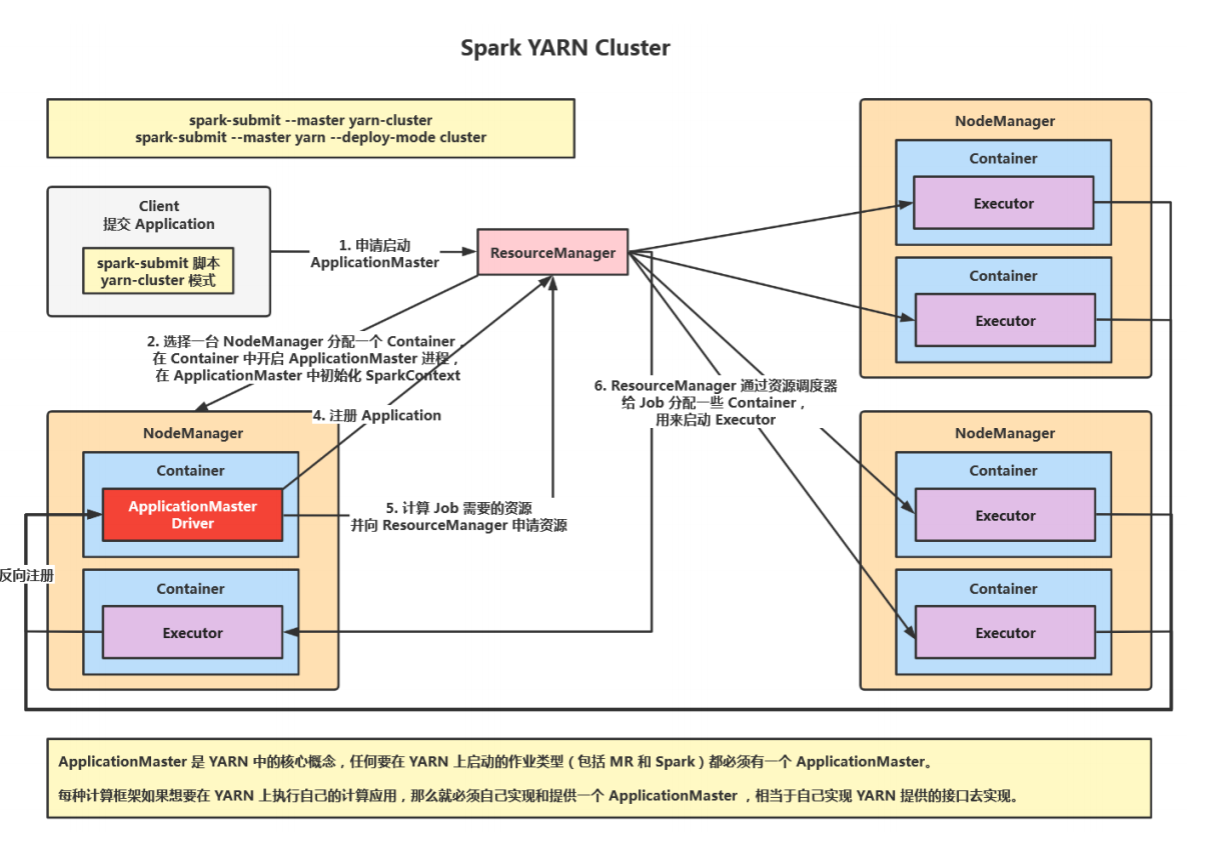
1.Spark比较Hive
由于MapReduce只适合做离线,计算复杂逻辑,存储到HDFS中的时间会比较长,会很效率底下。如果将一个MR的输出作为一个MR的输入频繁的读写HDFS会很耗费时间和IO资源。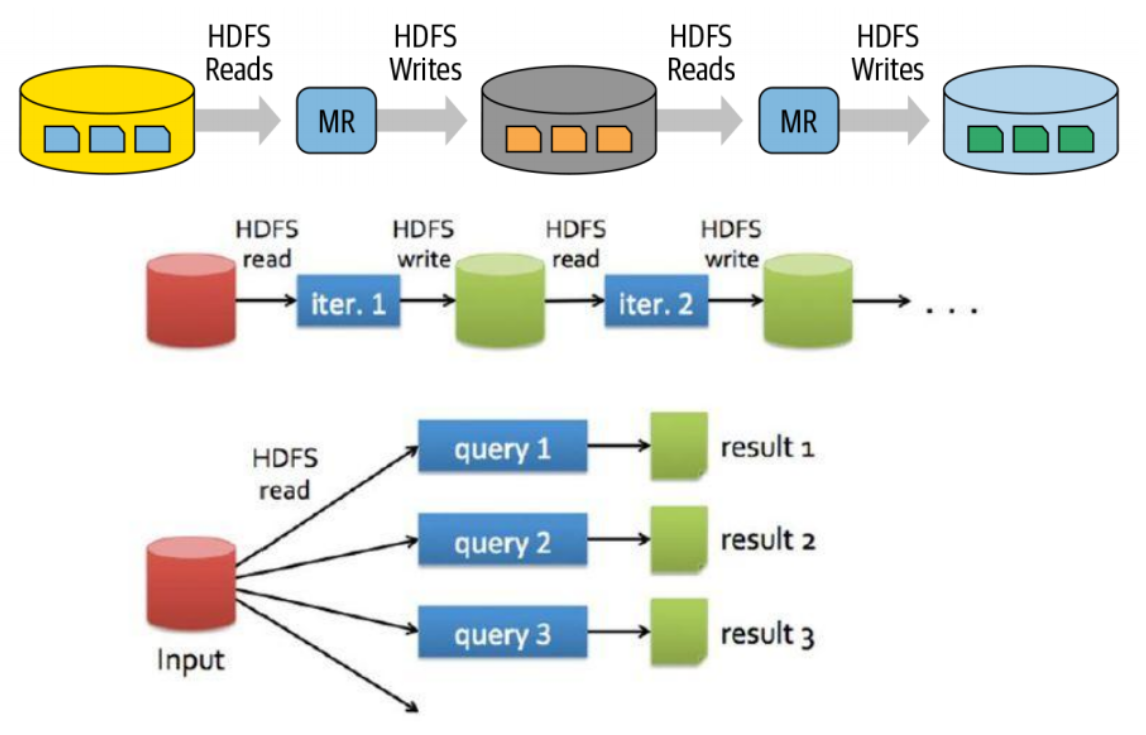
Spark既可以做离线,也可以做实时,提供了抽象的数据集,有API算子,丰富的算子,并且使用了更先进的 DAG 有向无环图调度思想,可以对执行计划优化后再执行,并且数据可以缓存到内存中进行复用(通过控制算子)。Spark中多个作业之间的数据通信是基于内存(Spark 中除了基于内存计算这一个计算快的原因,还有 DAG 有向无环图来切分任务的执行先后顺序),而 MR 是基于磁盘。 Spark不具有存储的能力,存储是在HDFS中。Spark是可以替代MR的计算框架,还可以用SparkSQL替换Hive的查询框架。Spark 是基于内存的,所以在实际的生产环境中,由于内存的限制,可能会由于内存资源不足导致 Job 执行失败。此时,MapReduce 其实是一个更好的选择,所以 Spark 并不能完全替代 MR。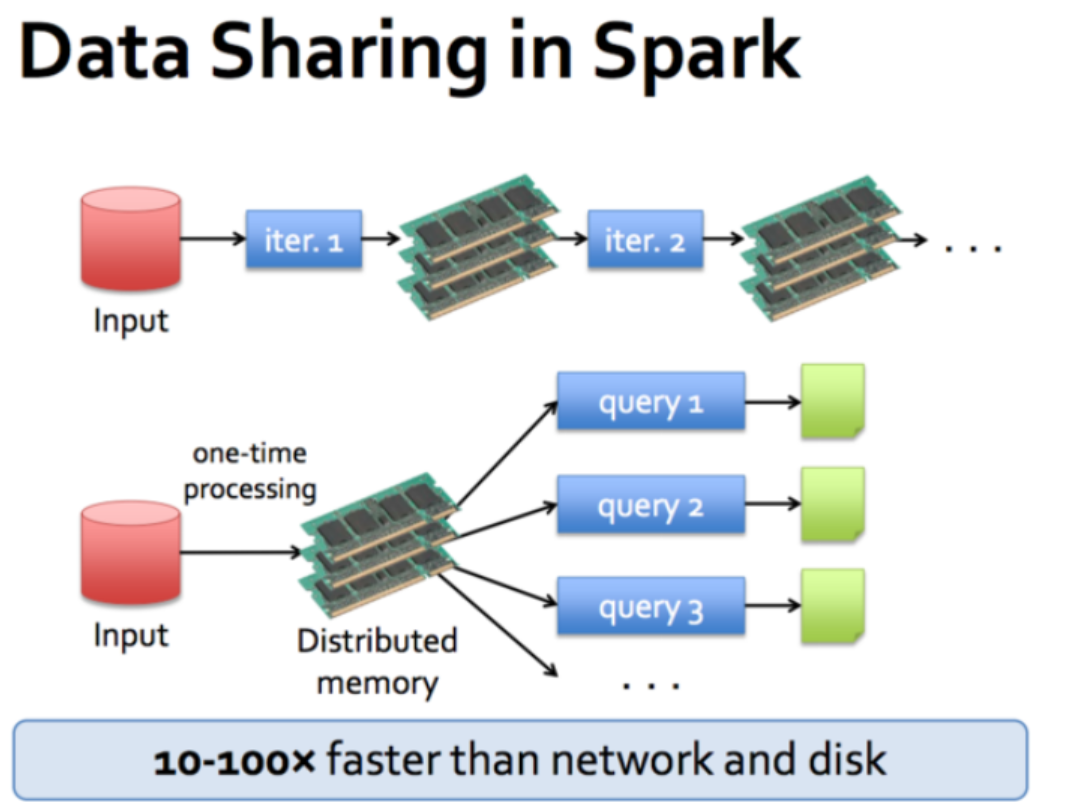
特点
快:计算不走MR会,基于内存会快不止100倍,基于磁盘快10倍以上
易用性:Spark 支持 Scala、Java、Python、R 和 SQL 多种语言,还支持超过 80 种高级算法,使用户可以快速构建不同的应用。
通用:Spark 提供了统一的解决方案。Spark 可以用于批处理(Spark Core)、交互式查询(Spark SQL)、实时流处理
(Spark Streaming)、机器学习(Spark MLlib)和图计算(GraphX)。
2.运行架构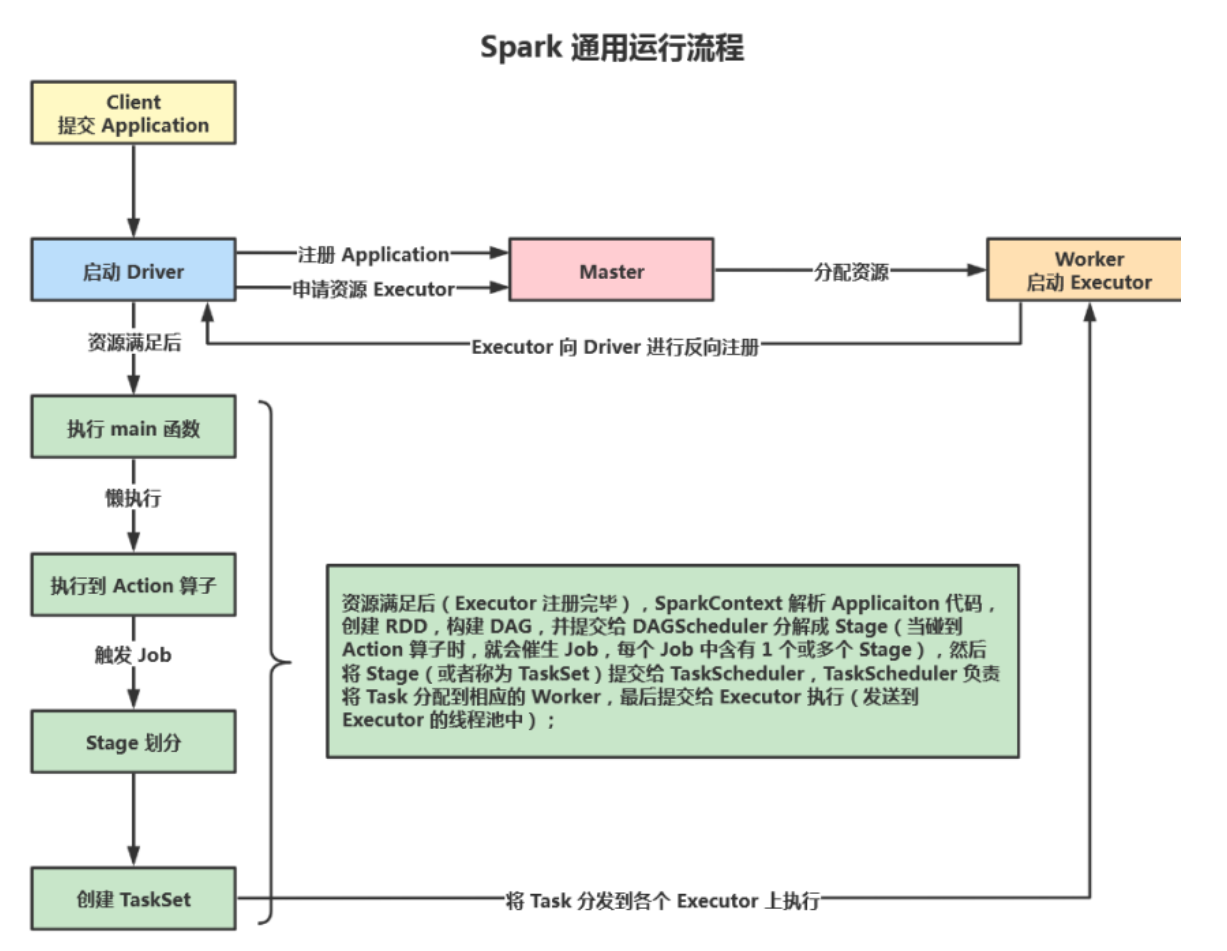
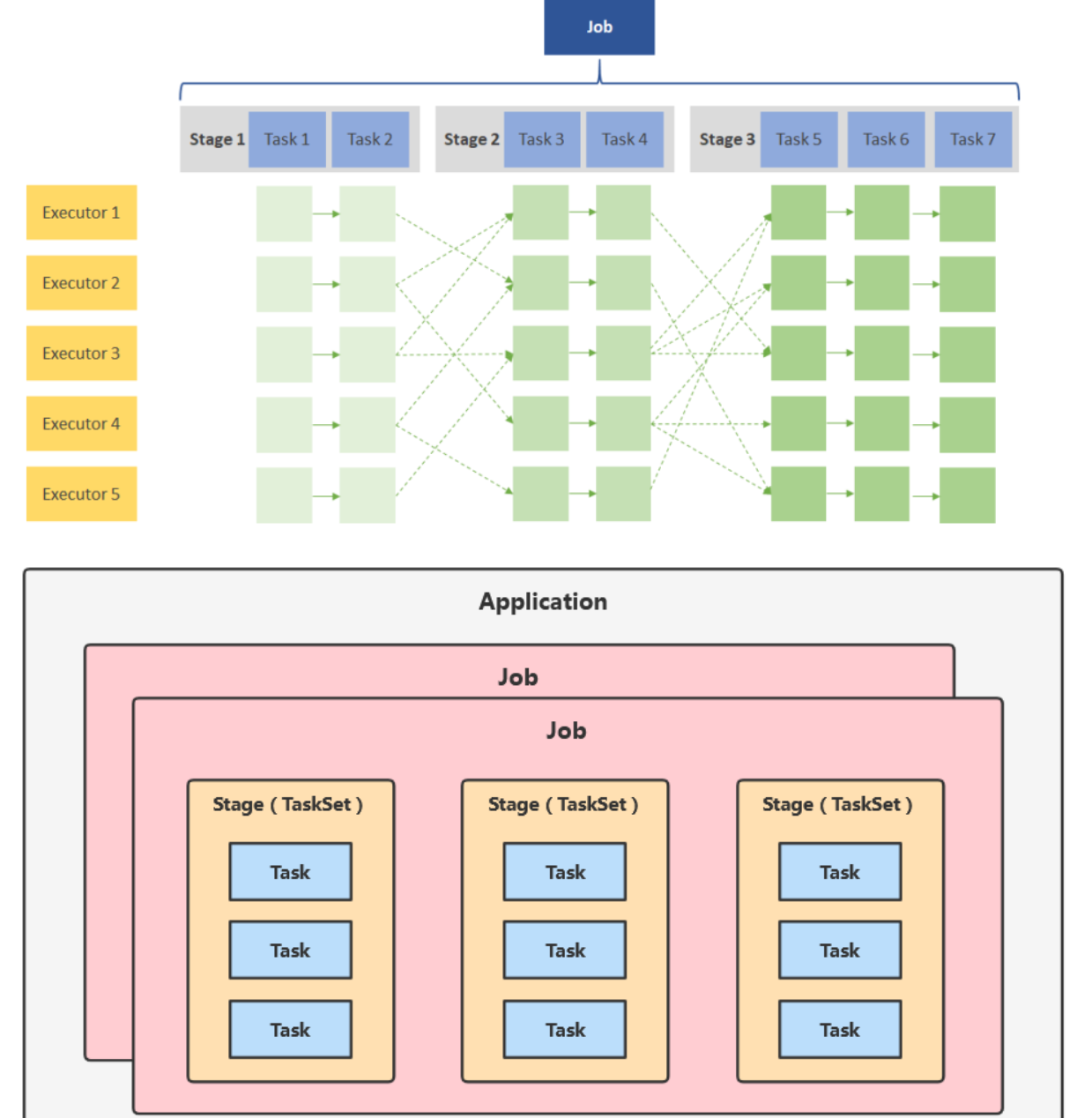
启动集群,Worker节点向Master汇报资源情况(CPU和内存)
Client提交Application,根据不同的运行模式在不同的位置创建Driver进程。
Application中创建SparkContext链接Mater,并注册申请资源。
Mater根据Worker汇报的资源情况,分配资源Executer;
Worker像Driver反向注册,资源准备好,可以开始执行进程。
SparkContext解析Application代码,创建RDD,构建DAG有向图。
DAGScheduler 分解成 Stage(Shuffle),当碰到执行算子时,产生Job(一个Job中有一个或多个Stage),Stage分区数据(Task)提交给分配到的Work中的Executor中
最后Excutor启动多线程计算
计算处理后告诉SparkContext,SparkContext告知Mater数据处理完毕,可以注销,然后释放资源。
2.1资源申请粒度
粗粒度资源申请(Spark)
在执行Application之前申请好资源,给任务调度,所有的Task执行完成之后才会释放这些资源。。
**优点:**任务启动快,执行快,Stage快,Job快,Application的执行也快。
**缺点:**最后一个Task执行完了之后才会释放资源,资源利用的不充分
细粒度资源申请
让 Job 中的每一个 Task 在执行前自己去申请资源, Task 执行完成就立刻释放资源。
优点:集群的资源可以充分的利用。
缺点:Task自己申请资源,Task变慢了,Application也就慢了。
2.1Local本地模式
在本地执行 Spark 代码的环境,本地模式就是一个独立的进程,通过其内部的多个线程来模拟整个 Spark 运行时环境,每个线程代表一个 Worker。
2.2Standalone
Spark自带的集群模式,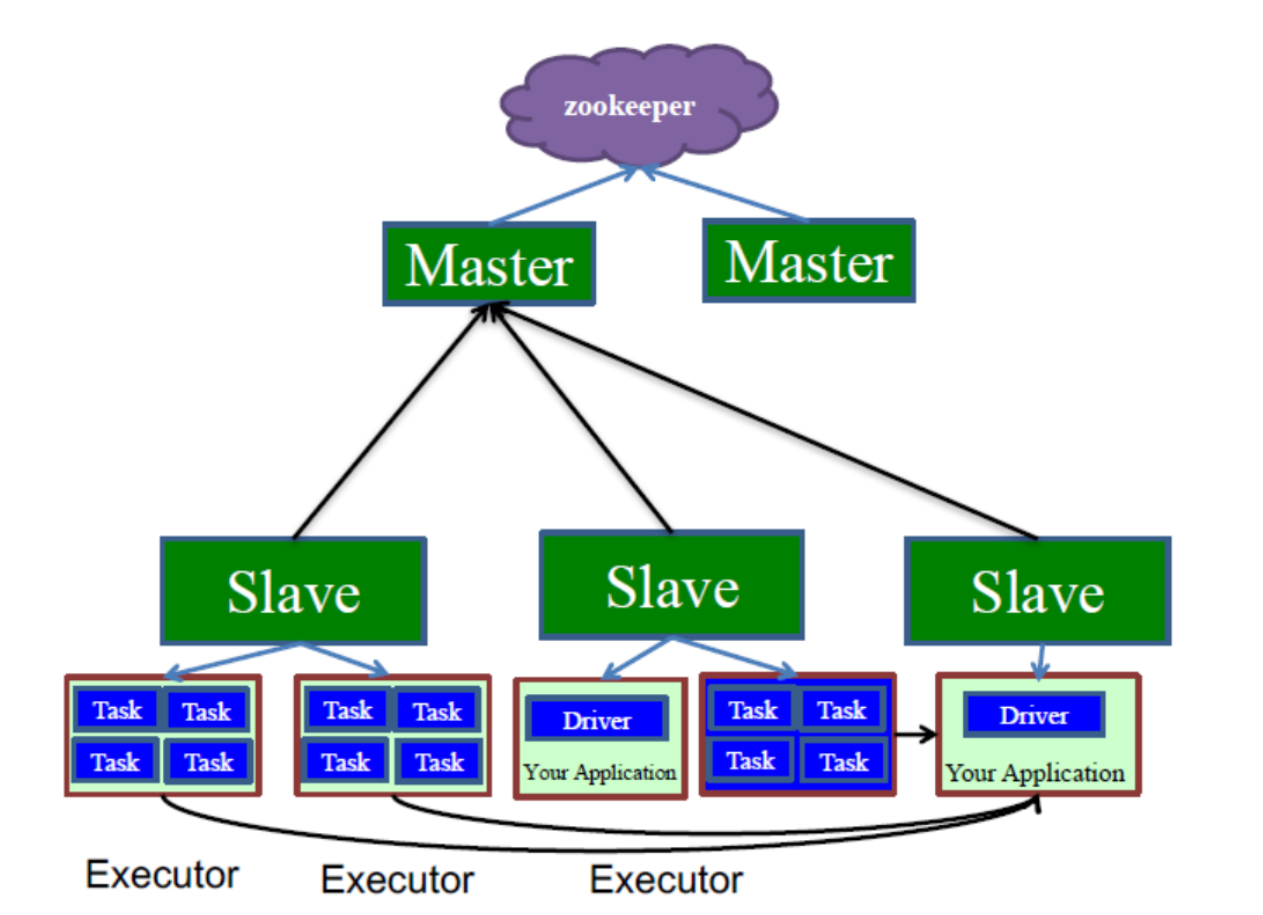
Standalone CLient
在 Standalone Client 模式下,如果在 Master 上提交应用,那么 Driver 就在 Master;如果在 Worker 上提交应用,那么Driver 就在 Worker,如果直接在自己的 PC 上提交应用,比如在 IDEA 中使用 val sc = new SparkContext("spark://node01:7077","AppName") 去连接 Master 的话,Driver 就在自己的 PC 上,但是不推荐这样的方式,因为 PC 和 Workers 可能不在一个局域网,Driver 和 Executor 之间的通信会很慢。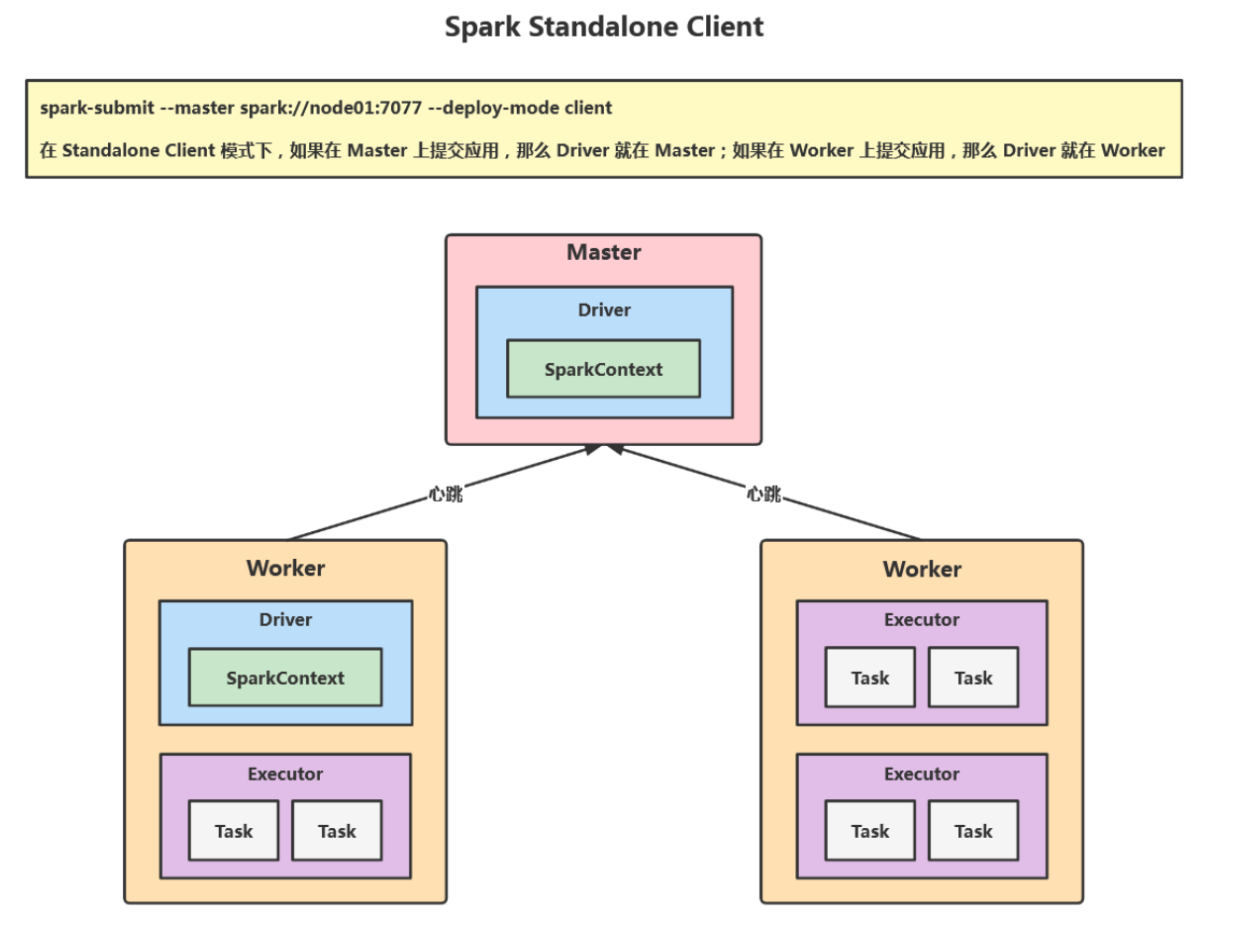
Standalone CLuster
在 Standalone Cluster 模式下,任务提交后,* *Master** 会找到一个 Worker 启动 Driver 进程 ,这时候Driver在Work中。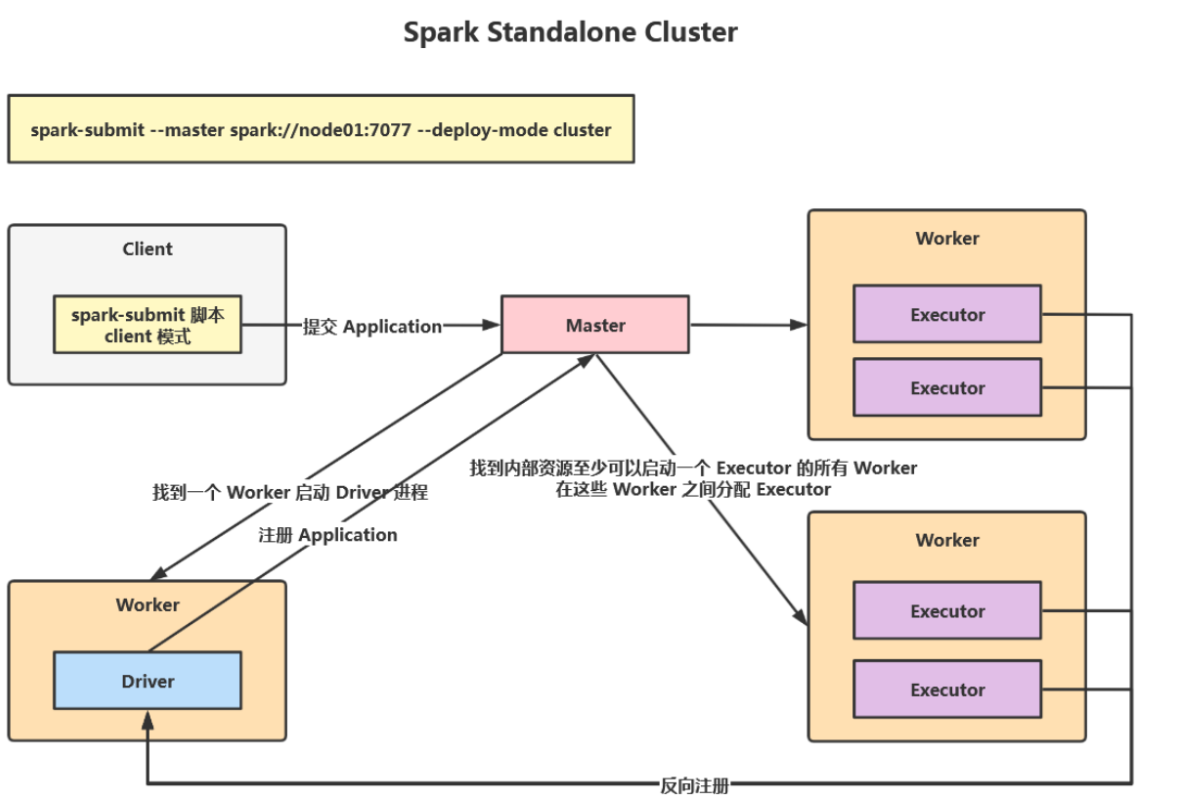
YARN模式
YARN 是 Hadoop 的资源调度框架,Spark 也可以基于 YARN 来计算(将 Spark 应用提交到 YARN 上运行)。Spark 客户
端直接连接 YARN,不需要额外构建 Spark 集群,国内使用较多。Spark 中的各个角色运行在 YARN 的容器内部,并组成Spark 集群环境。
YARNClient
在 YARN Client 模式下,* *Driver** 在应用提交的本地机器上运行 ,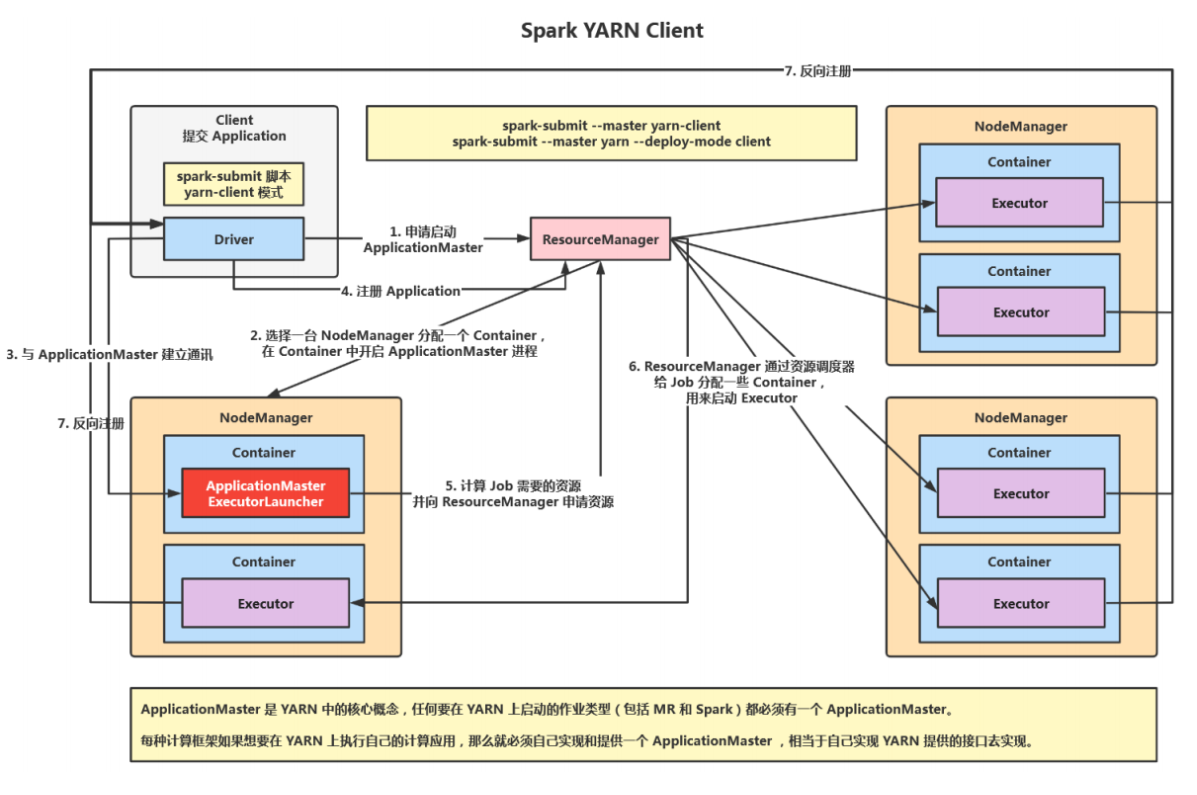
YARN Cluster