文章目录
有需要本项目的代码或文档以及全部资源,或者部署调试可以私信博主
项目介绍
随着我国农业数字化进程的加快,农产品批发市场每天都会产生海量的价格数据,这些数据涵盖了丰富的时空、品类和价格信息。然而,传统的处理方式在应对大规模、动态性强的数据时,往往存在计算速度慢、扩展性不足、分析维度有限等问题,难以满足政府、市场与生产者对实时监测与深度挖掘的需求。针对这一现状,本项目依托 Hadoop 生态体系,构建了一套集数据采集、存储、处理、分析和可视化于一体的分布式农产品价格分析平台,为农业经济决策与市场调控提供技术支持。
在数据采集环节,项目针对"惠农网"和"食品商务网"等公开渠道开发了爬虫程序,抓取了近 10 万条包含品类、品种、价格区间、产地和时间等核心字段的数据。采集过程中,通过字段映射、格式统一及初步异常剔除,确保了数据在进入后续处理环节前的完整性与规范性。
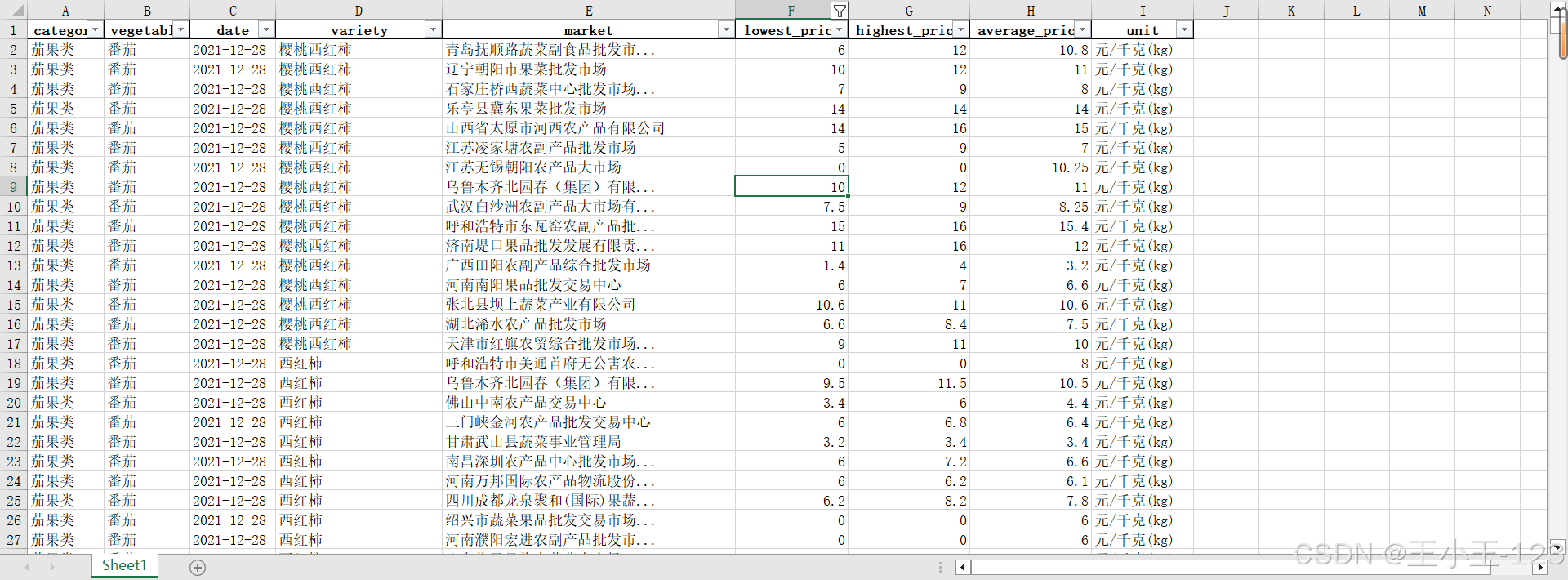
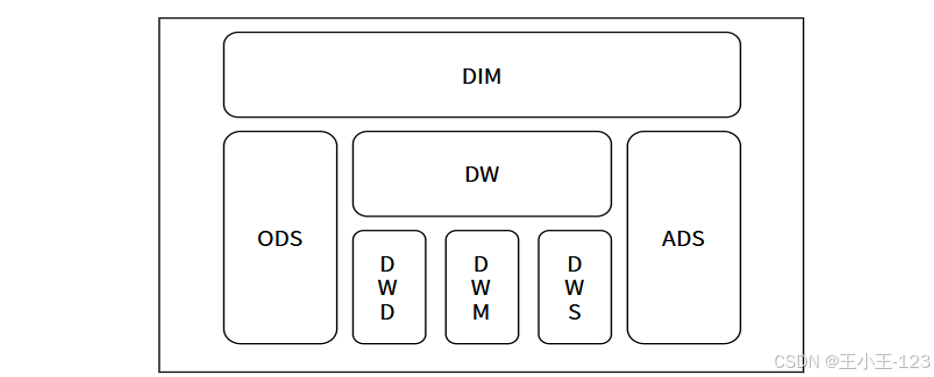
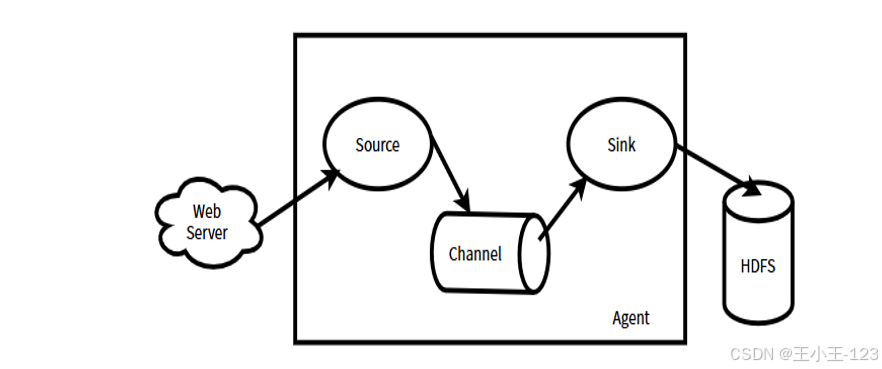
在存储与传输方面,项目利用 Flume 搭建了实时数据汇聚通道,将原始数据高效导入到 Hadoop 分布式文件系统(HDFS)中,依托其高容错和线性扩展能力实现海量数据的安全存储。为便于后续分析,项目采用 Hive 构建了分层数据仓库,将数据按原始层、明细层和汇总分析层进行结构化管理,从而提升了查询效率和数据可追溯性。此外,通过 Sqoop 实现了 Hadoop 与关系型数据库的双向数据传输,使数据既可用于批量分析,又能灵活对接本地分析环境。

在数据处理环节,平台基于 MapReduce 对原始数据执行清洗与预处理,包括时间字段标准化、缺失值填补、异常值识别、市场名称归一化等操作,并提取多维特征以支撑后续分析。为了提高预测能力,项目分别构建了 ARIMA 时间序列模型与随机森林回归模型,对价格变化趋势进行建模与对比。结果显示,随机森林在捕捉非线性关系和多因素交互方面表现更优,拟合精度和预测稳定性均高于 ARIMA 模型,尤其在短期预测中优势明显。
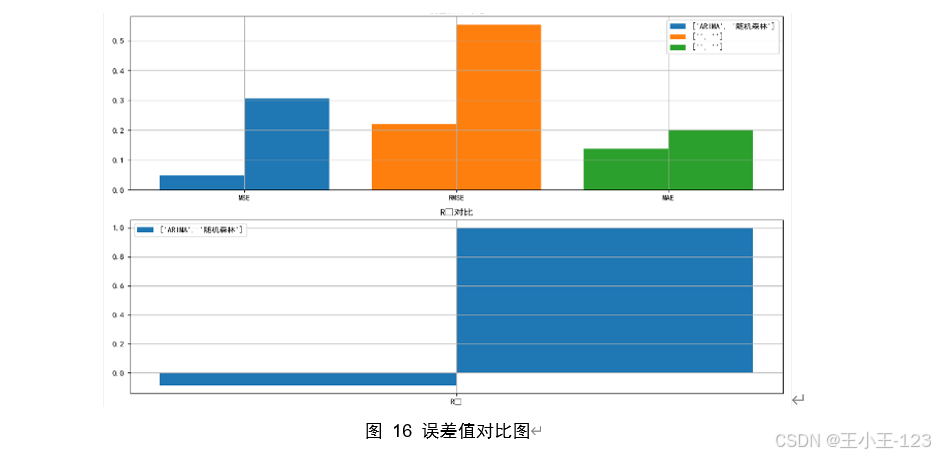

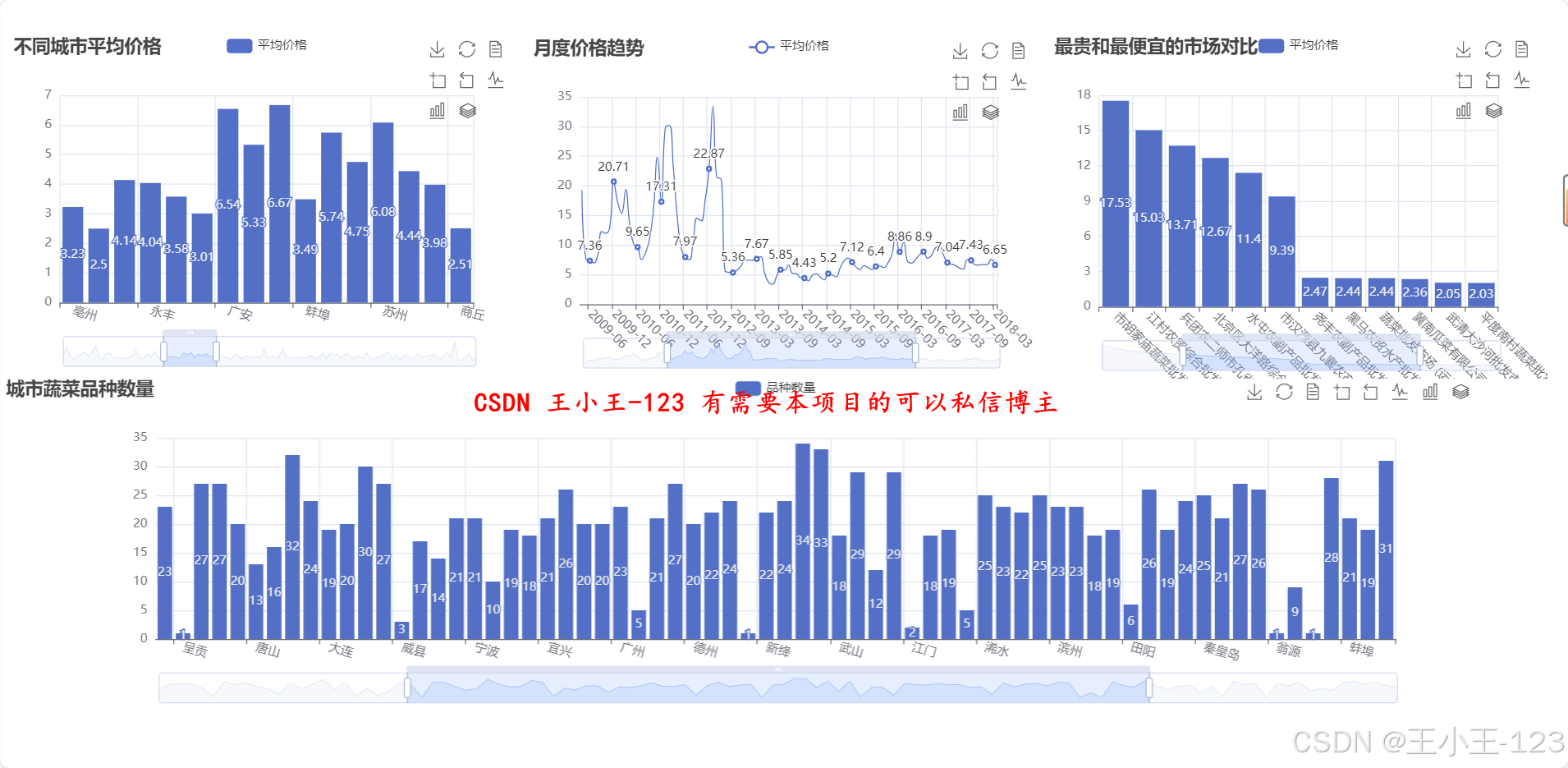
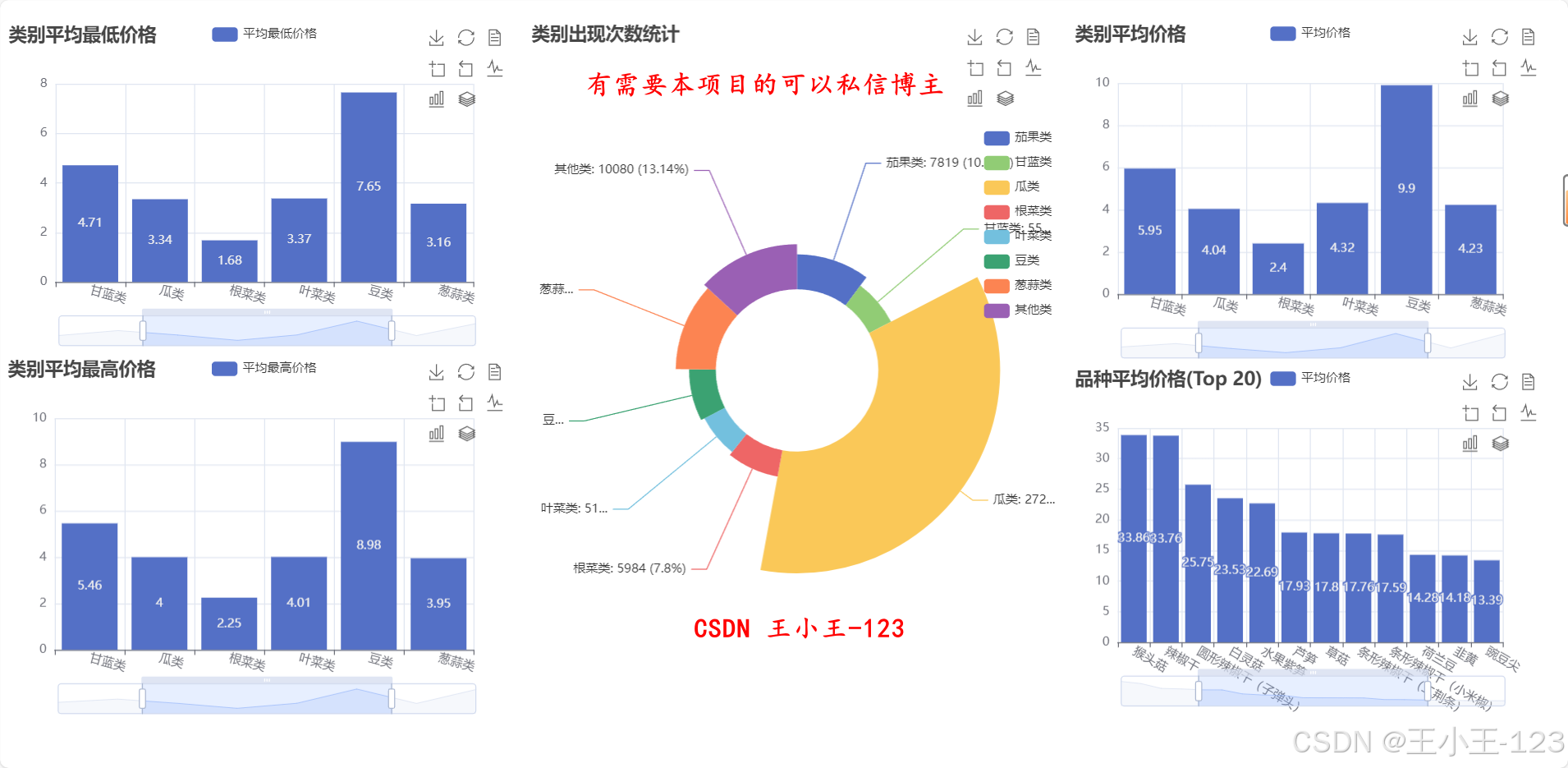
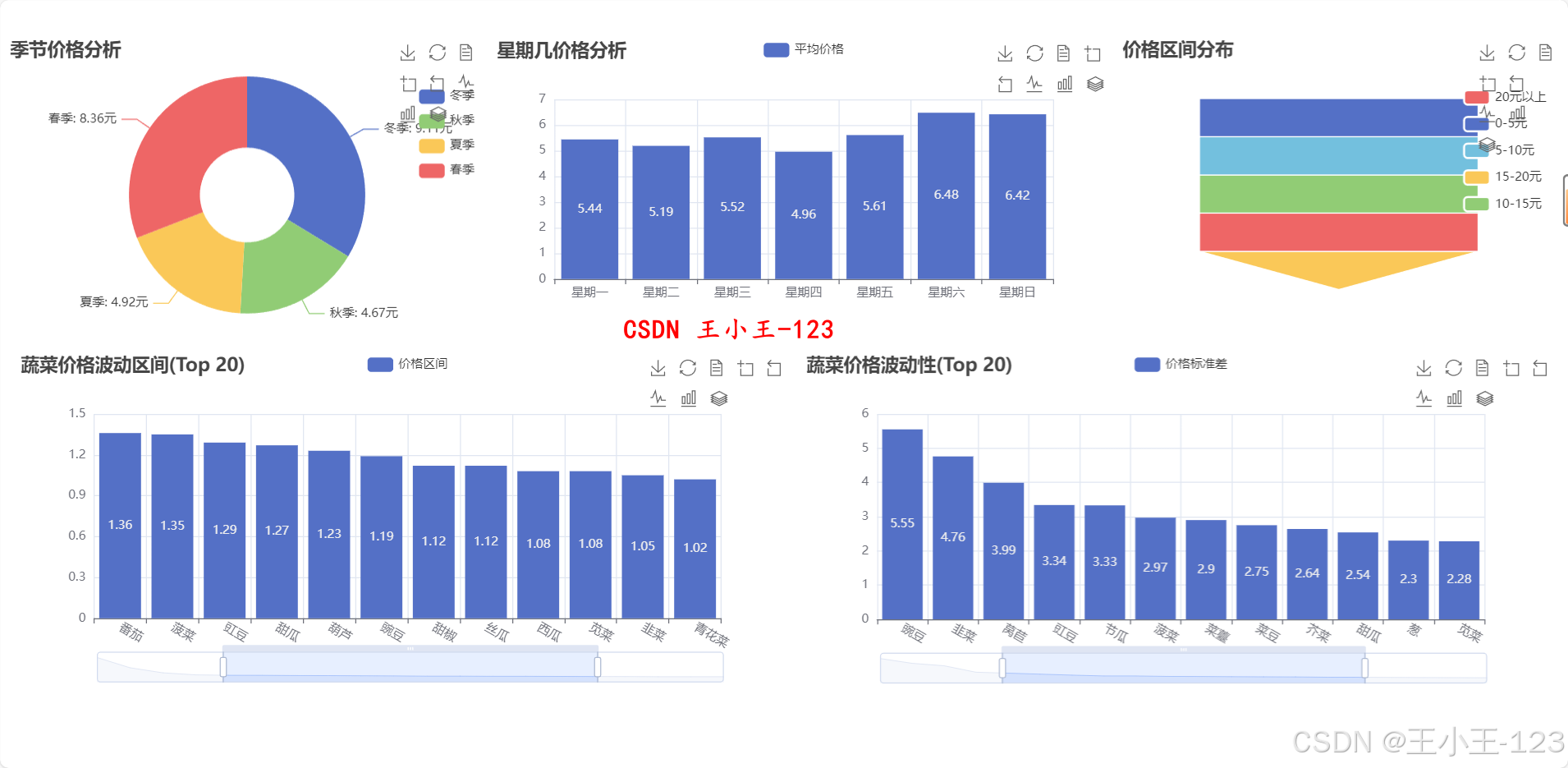
在可视化部分,平台采用 Echarts 和 Jupyter Notebook 结合的方式,将分析结果转化为直观的交互式图表。可视化内容涵盖多类主题:如不同城市价格分布、各品类价格区间、季节性波动趋势、市场供需差异等。通过这些可视化结果,可以直观揭示区域间价格差距、节令对价格的影响、品类结构变化等特征。例如,冬季平均价格显著高于秋季,部分高端品类在特定地区长期维持高价,周末价格存在小幅上升趋势等。这些发现可为农户优化种植计划、批发商调整采购策略以及政府制定调控政策提供参考。
项目研究表明,农产品价格不仅受产销两端的供求关系、运输与储存成本的影响,还会受到气候、季节、消费习惯等多种因素的共同作用。在当前的试验预测中,针对河南地区胡萝卜的短期价格预测显示价格在未来数日内趋于稳定,这印证了模型在特定场景下的实用性。
本项目的核心价值在于,将 Hadoop 的分布式存储与计算能力,与机器学习模型及可视化分析手段有机结合,构建了一个可扩展、可持续迭代的农产品价格分析体系。通过高效的数据管道和清晰的可视化呈现,能够帮助市场参与者更快速地掌握关键信息、降低决策风险、提升应对市场波动的能力。
每文一语
成功在于坚持