探索之言:
你是否也有过这样的经历:向ChatGPT提出一个专业问题时,得到的回答听起来头头是道,细究之下却缺乏深度,甚至暗藏事实性错误?
今天,我们将深入探讨一项正在重塑AI专业能力的前沿技术------图检索增强生成(GraphRAG)。
它融合了知识图谱的强大结构化语义关系与检索增强生成(RAG)的精准信息调用,不仅让AI"知道更多",更让它"理解得更深"。这项创新正显著提升大模型在医疗、金融、科研等高要求领域的准确性与可信度,开启AI迈向真正专业智能的新篇章。
尽管以GPT系列为代表的大语言模型(LLM)在文本理解、问答交互和内容生成等任务中展现出卓越能力,但在应对需要深厚专业知识的场景时,其表现常常不尽如人意。这一局限主要源于以下三方面挑战:
**- 知识深度不足:LLM依赖预训练阶段获取的知识,虽然覆盖面广,但在医学、法律、工程等专业领域往往缺乏深入、精准的细节支撑;
- 复杂推理能力有限:专业任务常涉及多步骤、高精度的逻辑推导,而大模型在长链条推理过程中容易出现逻辑断裂或偏差;
- 语境理解不充分:专业术语在不同上下文中可能含义迥异,而LLM难以准确识别和区分这些细微的语义变化,导致理解偏差或错误输出**。
这些问题共同制约了LLM在高专业性、高准确性要求场景中的可靠应用,也推动了如检索增强、知识图谱融合等增强技术的发展。
1:传统RAG的挑战与局限:智能时代的瓶颈
传统的检索增强生成(RAG)技术通过接入外部知识库,已在一定程度上弥补了大语言模型在知识覆盖上的短板。然而,面对专业领域中高度复杂、语义密集的问题,传统RAG仍暴露出三大关键瓶颈:
1.1 难以理解复杂语义结构:
专业问题通常涉及多个实体及其深层关系,而传统RAG依赖向量相似度进行检索,本质上是基于关键词或语义近似匹配,无法有效建模实体间的多跳关联。这意味着它只能检索与查询中直接提及的"锚点"实体相关的文本片段,缺乏进行逻辑推理或跨文档关联的能力,尤其在处理细粒度知识时表现更显乏力。
1.2 碎片化知识导致上下文断裂:
为了提升检索效率,传统RAG常将文档切分为独立的文本块。然而,这种分块方式割裂了原本连贯的知识脉络,导致关键上下文信息丢失。当专业知识分散在多个片段中时,模型难以整合碎片化内容形成完整理解。更关键的是,向量数据库通常以扁平化方式存储信息,缺乏对抽象概念、层级关系和语义网络的组织,难以应对需要概念归纳或上下文敏感解析的查询。
1.3 检索效率与上下文容量失衡:
传统RAG普遍采用向量检索机制,面对海量知识库时,往往返回大量相关性参差的内容。而大语言模型受限于固定的上下文窗口(通常为2K至32K token),难以从冗余信息中筛选出真正关键的部分。虽然增大文本块粒度可在一定程度上缓解信息缺失,但这会显著增加计算开销和响应延迟,影响系统整体效率与实用性。
正是这些局限,推动了新一代增强生成技术的诞生------GraphRAG。它将结构化的知识图谱与RAG深度融合,利用图谱中的实体关系网络实现多跳推理、语义关联与知识整合,不仅提升了对复杂专业问题的理解能力,也显著优化了检索的精准性与生成的可靠性,为AI在高阶知识场景中的应用开辟了全新路径。
2:GraphRAG技术介绍
**GraphRAG(图检索增强生成)**通过融合知识图谱与检索增强生成技术,彻底革新了大语言模型处理专业领域知识的方式。与传统的RAG仅依赖文本片段匹配不同,GraphRAG首先将原始文本转化为结构化的知识图谱,精准刻画实体之间的语义关系。在此基础上,系统通过图遍历算法和多跳推理机制,动态检索与问题相关的知识子图,捕捉深层次的关联信息。最终,模型在保留图结构语义的前提下生成逻辑严密、上下连贯的回答。
**这一方法的核心突破在于:**不仅能揭示概念之间的隐含联系,还能支持复杂的多步推理过程,有效应对需跨多个知识点推导的难题。同时,由于推理路径以图结构显式呈现,整个生成过程具备更强的可解释性与透明度,让用户不仅能获得答案,还能清晰了解答案的来源与推导逻辑。GraphRAG由此实现了从"模糊匹配"到"结构化理解"的跃迁,显著提升了AI在科研、医疗、金融等高阶专业场景中的可靠性与实用性。
2.1工作流程
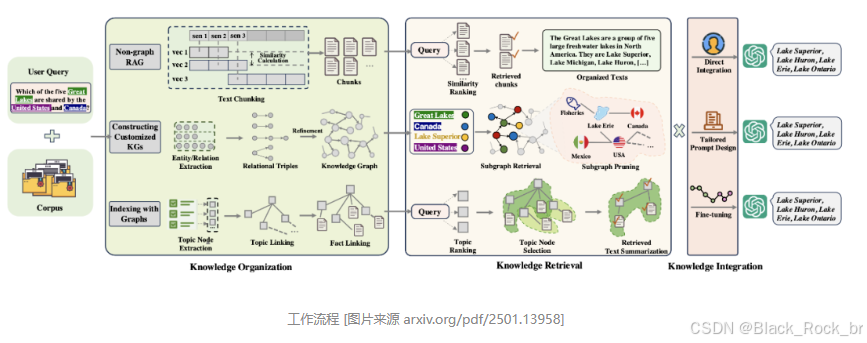
GraphRAG的工作流程由三个关键阶段构成。首先,通过自动提取实体和关系,构建出结构化的知识图谱。接着,在图检索阶段,根据问题定位相关节点,并沿着关系路径进行智能扩展。最后,在知识融合阶段,将检索到的结构化知识整合成连贯一致的回答,同时保留原始知识的逻辑关系。这种流程让AI能够像人类专家一样,通过关联不同知识点来解决复杂问题,极大地提升了AI的智能水平。
3:GraphRAG与传统RAG的对比
传统RAG(Retrieval-Augmented Generation)与GraphRAG在整体工作流程上存在根本性的差异,这种差异不仅体现在技术实现层面,更深刻地影响了模型对复杂知识的理解能力、推理深度以及生成结果的可解释性。
传统RAG:基于文本片段的"拼接式"增强
传统RAG采用一种相对简单、线性的三步流程:
-
文档分块与向量化
原始文档被切割成固定长度或语义边界的小块文本(chunks),每个文本块通过嵌入模型(如Sentence-BERT)转换为向量,并存储在向量数据库中。这一过程强调效率,但往往忽略了文本之间的上下文连续性和语义关联。
-
语义相似度检索
当用户提出查询时,系统将问题编码为向量,并在向量库中通过最近邻搜索(如余弦相似度)找出与之最接近的若干文本片段。这种检索方式本质上是"关键词+语义匹配"的扩展,依赖于表面语义的贴近程度。
-
上下文拼接与生成
检索到的文本块被简单地拼接在一起,作为附加上下文输入给大语言模型(LLM),由其生成最终回答。由于这些片段来自不同位置、缺乏结构关联,常常导致信息碎片化、逻辑断层,甚至出现自相矛盾的内容。
局限性凸显 :
尽管传统RAG有效缓解了LLM的知识时效性和幻觉问题,但它本质上仍是一种"扁平化"的信息检索机制。它无法理解实体之间的深层关系,难以支持多跳推理(multi-hop reasoning),也无法识别分散在不同文档中的隐含关联。面对需要综合判断、逻辑推导或上下文敏感理解的专业问题时,其表现往往力不从心。
GraphRAG:基于结构化知识的"图谱驱动"增强
相比之下,GraphRAG引入了知识图谱作为核心支撑,构建了一套更加精细、智能且可解释的三阶段工作流程:
第一阶段:知识组织 ------ 从文本到结构化知识图谱
GraphRAG不再将文档视为孤立的文本流,而是通过自然语言处理技术(如命名实体识别、关系抽取和事件抽取)对原始语料进行深度解析。
- 系统自动识别出关键实体(如"糖尿病"、"胰岛素"、"HbA1c指标"等);
- 明确标注实体之间的语义关系(如"导致"、"治疗"、"影响"、"属于"等);
- 将这些信息组织成一个结构化的知识图谱,其中节点代表实体或概念,边表示它们之间的语义联系。
这一过程实现了从"非结构化文本"到"结构化知识"的跃迁,使得知识具备了可查询、可推理、可追溯的特性。更重要的是,知识图谱天然支持层次化组织、语义泛化和跨文档关联,为后续的复杂推理打下坚实基础。
第二阶段:知识检索 ------ 基于图遍历的多跳推理
当接收到用户查询时,GraphRAG不再依赖简单的向量匹配,而是启动图谱上的智能检索机制:
- 首先定位查询中的核心实体(锚点),作为图谱中的起始节点;
- 然后通过图遍历算法(如广度优先搜索、随机游走或图神经网络引导的路径发现)进行多跳推理,沿着关系边逐步扩展,挖掘与问题相关的间接关联信息;
- 最终形成一个围绕问题的"知识子图",其中不仅包含直接匹配的事实,还涵盖经过逻辑推导得出的隐含知识。
例如,在回答"长期高血糖如何影响心血管系统?"时,系统可能从"高血糖"出发,经过"导致胰岛素抵抗 → 引发高血压 → 加重动脉硬化 → 增加心脏病风险"这一系列路径,构建出完整的因果链条。
这种方式突破了传统RAG只能检索"显式提及"的局限,真正实现了"联想式"和"推理式"检索。
第三阶段:知识集成与生成 ------ 结构感知的回答合成
在获取知识子图后,GraphRAG进入最后的生成阶段。与传统RAG简单拼接文本不同,GraphRAG会:
- 分析子图的拓扑结构,识别关键路径、核心节点和逻辑依赖;
- 对多源信息进行融合,去除重复或冲突内容,确保知识一致性;
- 在生成过程中保留图谱的结构语义,使LLM能够基于清晰的逻辑框架组织语言;
- 输出不仅包含最终答案,还可附带推理路径、证据来源或可视化图谱片段。
这使得生成的回答不仅准确、连贯,而且具有高度的可解释性------用户不仅能知道"答案是什么",还能理解"为什么是这个答案"以及"它是如何被推导出来的"。
GraphRAG的核心优势与应用场景
GraphRAG的优势在于它超越了传统RAG"检索-拼接-生成"的浅层模式,转向"理解-推理-解释"的深度认知范式。其核心价值体现在:
- ✅ 支持复杂推理:通过多跳图遍历,解决需跨多个知识点推导的问题;
- ✅ 提升知识整合能力:打破信息孤岛,整合分散在不同来源中的相关知识;
- ✅ 增强可解释性:推理路径可视、可追溯,提升结果可信度;
- ✅ 便于知识更新与维护:新增数据可增量融入图谱,无需重新索引全部内容;
- ✅ 适应专业领域需求:特别适用于医疗诊断、法律判例分析、科研文献综述、金融风险评估等高精度、高逻辑性场景。
结语
GraphRAG通过将结构化知识图谱深度融入检索增强生成流程,从根本上突破了传统RAG在专业领域应用中的瓶颈。它不仅能够高效组织碎片化知识,更能通过图谱的多跳推理能力挖掘概念间的深层关联,构建逻辑清晰、路径可追溯的推理链条。这种"理解+推理+解释"一体化的能力,使其在医疗诊断、金融风险评估、法律条文分析等高复杂度、高准确性要求的场景中展现出显著优势,真正让AI具备了辅助专业决策的潜力。
对开发者而言,GraphRAG的落地正变得越来越可行。一系列开源项目的涌现大幅降低了技术门槛:
-
由浙江大学与蚂蚁金服联合推出的 --KAG-- 1,聚焦知识感知推理与领域适配;
-
英特尔开源的 --fast-graphrag-- 2,优化了图谱构建与检索效率,适合大规模知识处理;
-
微软发布的 --GraphRAG-- 3,提供了完整的端到端框架,支持从文本解析到图谱生成再到智能问答的全流程自动化。
这些工具不仅加速了技术普及,也为不同行业的定制化应用提供了坚实基础。结合已在医疗文献分析、金融情报挖掘、司法判例推荐等领域落地的实践案例,GraphRAG正在从理论走向规模化应用。
展望未来,随着知识图谱构建技术、图神经网络与大模型协同机制的持续演进,GraphRAG有望推动人工智能实现从"记忆式回答"到"理解式思考"的跃迁。它不仅是RAG的升级,更是通往真正"可解释、可推理、可信赖"AI的重要一步,为各行各业迈向智能化决策开启全新可能。