本篇文章开始,内容展示形式会有所调整,具体可以看文末。
兄弟们,好久不见,最近事情有点多,所以停更了,对不住了兄弟们。
一方面是公司上的任务最近比较多,前几天都直接干到凌晨四点才下班了。
这让我想起之前我同事和我说:在某些互联网公司,加班到十一二点,那都只是热身,真给兄弟整麻了。
对于这种情况,我只能说,身体要紧,老命要紧,偶尔这么搞搞还行,总这么搞,我估计也没几个人能顶得住。
这里也给兄弟们看看广州的夜景,还是可以的。



放三张就行了,放多我怕你们说我水文章,虽然确实如此。
博主手机是大一的时候买的了,用了很多年,所以像素就那样了,再加上博主老直男一个,也不懂审美,兄弟们将就着看吧,
等博主有米了,就换新的,不过就一台够谁用啊,再来一台,一人一台,哈哈。


另一方面就是最近在跑一个闲鱼的训练营,所以我把很多精力都投到闲鱼上面了。
加了我好友的,应该刷朋友圈的时候也会看到吧,不说 100% 哈。
因为要开这个训练营嘛,我多少都得会一点闲鱼才行,虽然主讲老师不是我,但我也必须得会才行,不然兄弟们问起我来我不会的话,就会很尴尬。
我研究闲鱼并没有去报班,一方面是我确实囊中羞涩,另一方面是很急了,没办法看视频慢慢来。
所以我就去网上找了很多相关文章来看,这里不得不感谢互联网,即使我没花钱也能学到很多东西。
我边看文章边实践操作,一周多的时间我就跑通了整个流程,接下来我还会花半个月的时间进行深入学习与实践,来加深我对该平台的理解。
然后教教兄弟们怎么操作,即使你不做智能体,也能学习一些电商平台的运行方法论。
好了,言归正传,这是我在闲鱼上收到某位兄弟的一个需求,正好我觉得这个工作流也是大多数人的需求,所以我就拿出来讲了。
这里是我找到的一些该工作流案例需要的素材,如果涉及侵权,联系我删除哈。

这是工作流生成的效果。
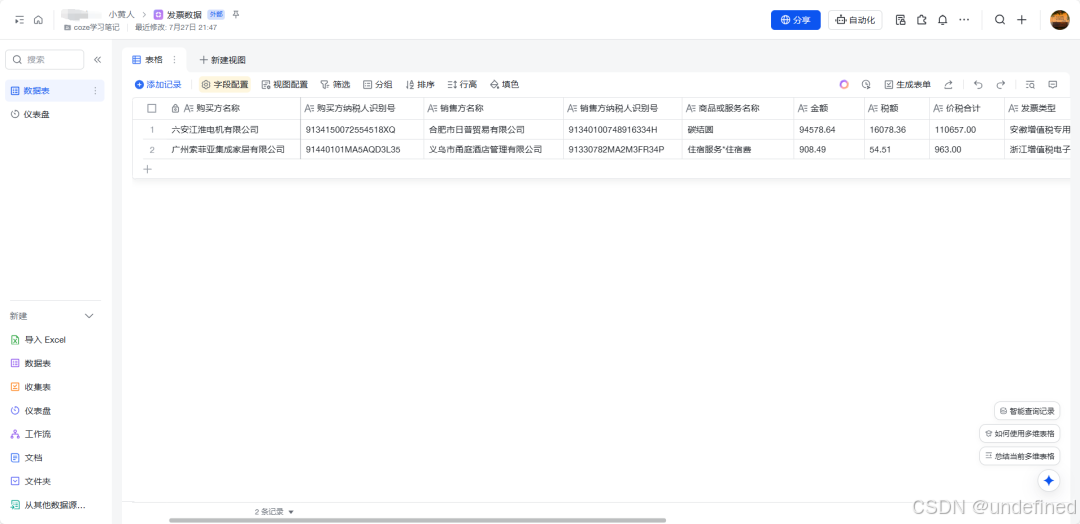
需求分析
这个发票记账的需求就不用说了吧,几乎所有经营性支出和收入都需要通过发票记账体现。
比如我们常见的采购和物资消耗,购买原材料,办公用品,设备等等都需要凭发票记账,作为成本核算依据。
再比如我这种打工牛马出差,业务招待,办公垫付等等费用,也需要发票向公司申请报销。
一般财务人员是作为发票录入的主要承担者,如果发票很多的话,对于财务人员来说手动录入的时间成本是非常非常大的。
从我们的生活来看,发票录入的场景是非常多的,需求是非常频繁且大的,当然工作量也大。
所以,我们可以通过这个智能体的方式,直接一键录入,减少极大的时间成本。
功能分析
需要具备上传图片功能。
需要具备识别图片功能。
需具备将识别的内容写入飞书功能。
以上功能需具备批量处理属性。
整体流程分析
整体事件流程如下。

整体扣子工作流流程如下。
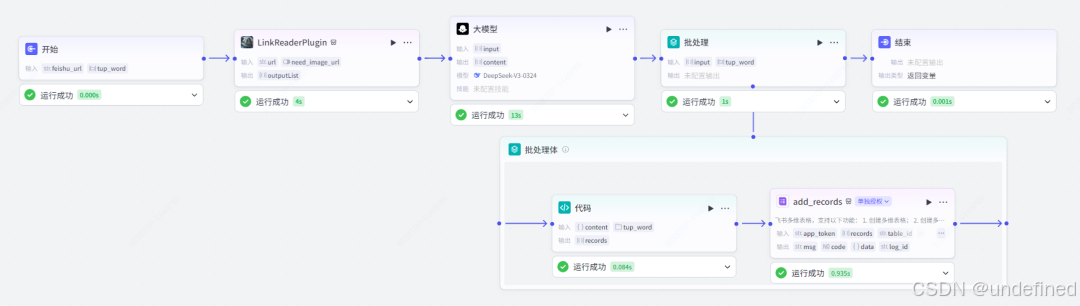
幼儿园版工作流教程
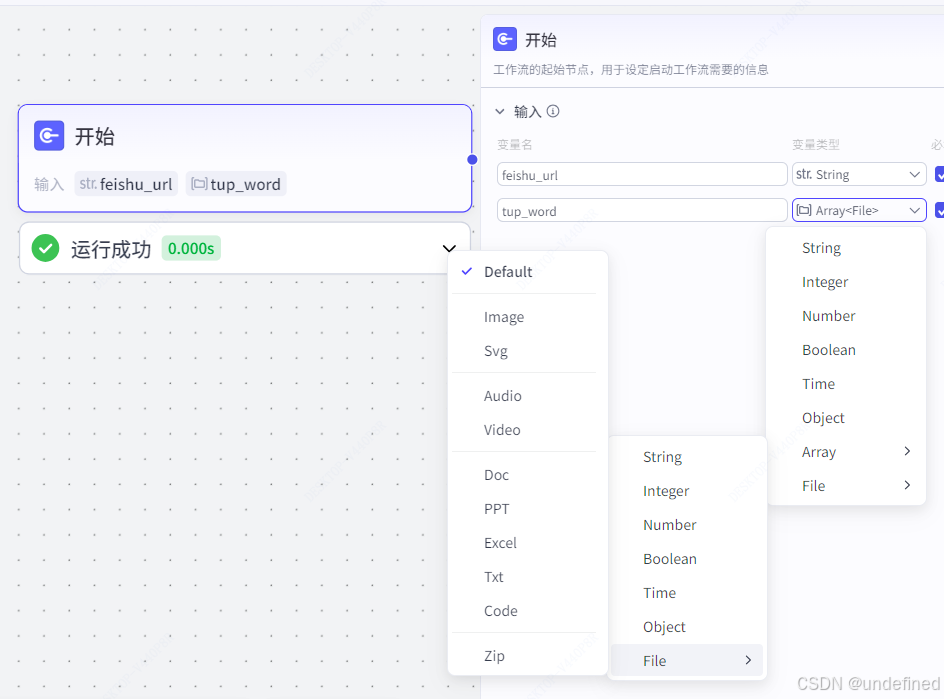
第一步,开始节点
开始节点我们设置两个参数,feishu_url 和 tup_word,前者是为了写入飞书做准备,后者是我们需要上传图片做准备。
这里我们设置 tup_word 的类型为数组的文件类型,采用这种方式的话可以增加输入的容错性。
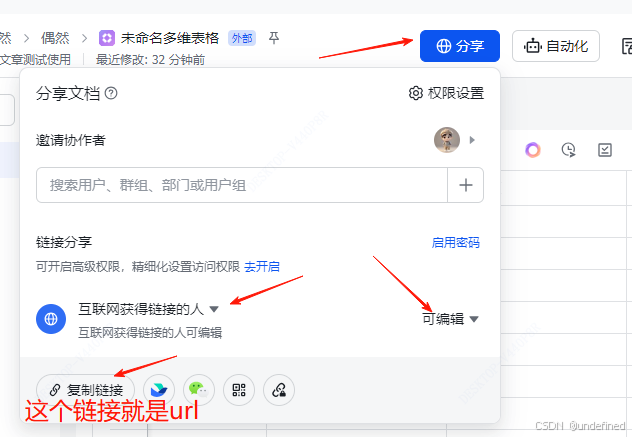
这里我先说一下 feishu_url 这个参数的获取方式。
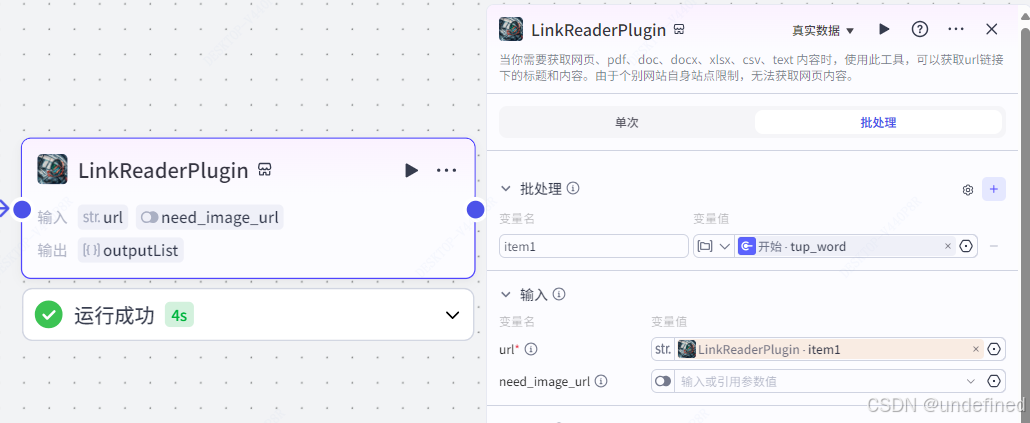
第二步,链接读取
链接读取的作用就是获取我们上传的那些图片的链接,进行读取。
这里我们要设置为批处理,因为我们上传的是批量的内容。
因此,我们设置批处理参数为 item1 ,数据类型为Array<File>Default,同时设置输入参数 url ,数据来源为链接读取节点的 item1。
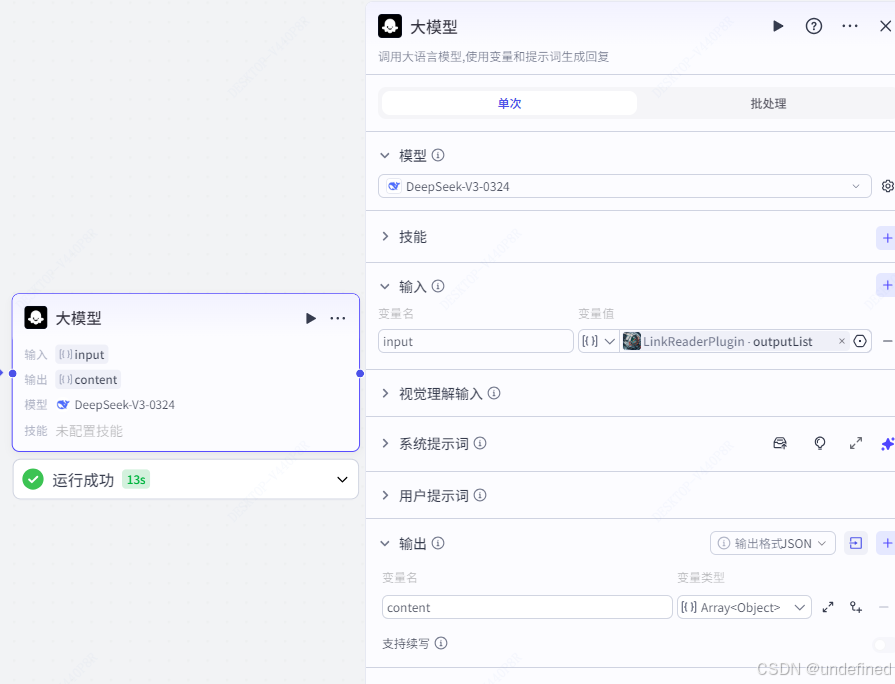
第三步,大模型节点
大模型节点的作用是从上一步中,把那些识别出来混乱的内容进行精准的提取我们想要的内容。
这里我们选择 deepseek v3 大模型,同时设置输入参数为 input ,数据来源为链接读取节点的 outputList ,数据类型为 Array<Object>
同时设置输出参数 content ,数据类型为 Array<Object>。
系统提示词:
# 角色
你是一个专业的发票信息提取专家,能够从输入的数据中{{input}}精准识别用户的发票图像中的关键信息
## 技能
### 技能1:提取发票信息
1. 当用户上传发票图像数据时,仔细分析数据内容
2. 从发票数据中准确提取以下字段信息:
-发票号码
-发票代码
-开票日期
-发票类型
-销售方名称
-销售方纳税人识别号
-购买方名称
-购买方纳税人识别号
-商品或服务名称
-金额
-税额
-价税合计
3. 按照以下格式返回信息:{
"发票号码":"XX",
"发票代码":"XX",
"开票日期":"XX",
"发票类型":"XX",
"销售方名称":"XX",
"销售方纳税人识别号":"XX",
"购买方名称":"XX",
"购买方纳税人识别号":"XX",
"商品或服务名称":"XX",
"金额":"XX",
"税额":"XX",
"价税合计":"XX"
}
用户提示词:
{{input}}第四步,批处理节点
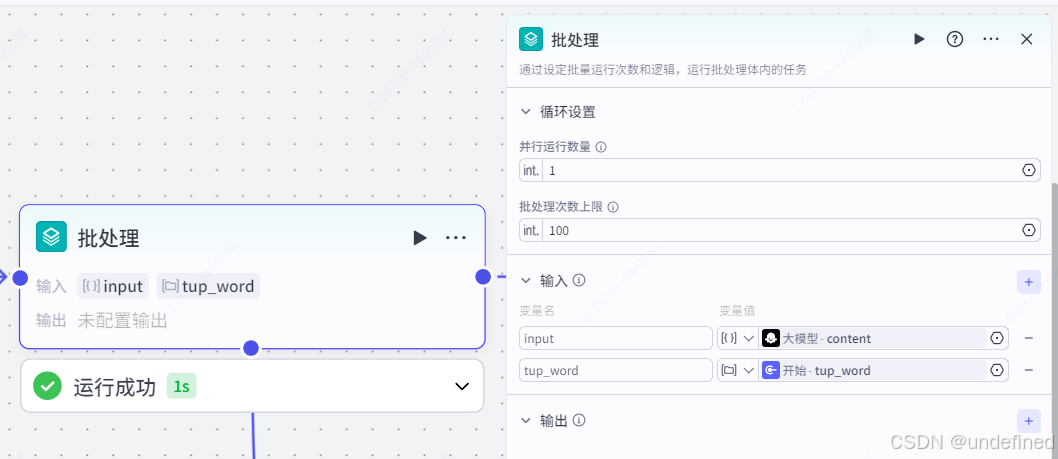
批处理节点的作用主要是用来批量将大模型提取的字段导入到飞书多维表格中。
这里我们设置并行运行数量为 1 ,别设置太高,容易报错,设置批处理次数上限为 100 即可。
同时我们设置输入参数为 input ,tup_word 两个参数,数据来源为大模型节点的 content ,数据类型为 Array<Object>,以及数据来源为开始节点的 tup_word,数据类型为 Araay<File>Default。
批处理体:代码节点
代码节点的作用就是实现将字段输入到飞书这一个功能。
这里我们设置输入参数 content ,tup_word,数据来源为批处理的 input ,数据类型为 Array<Object>,以及数据来源为批处理的 tup_word,数据类型为 File-Default 。
同时设置输出参数 records ,数据类型为 Array<Object>。
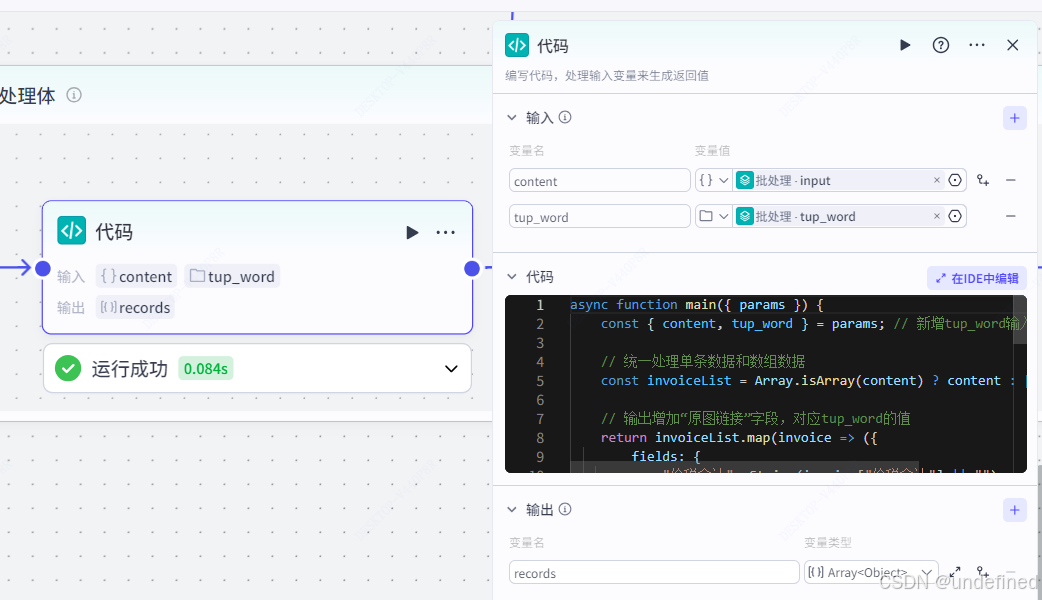
async functionmain({ params }) {
const { content, tup_word } = params; // 新增tup_word输入变量
// 统一处理单条数据和数组数据
const invoiceList = Array.isArray(content) ? content : [content];
// 输出增加"原图链接"字段,对应tup_word的值
return invoiceList.map(invoice => ({
fields: {
"价税合计": String(invoice["价税合计"] || ""),
"发票代码": String(invoice["发票代码"] || ""),
"发票号码": String(invoice["发票号码"] || ""),
"发票类型": String(invoice["发票类型"] || ""),
"商品或服务名称": String(invoice["商品或服务名称"] || ""),
"开票日期": String(invoice["开票日期"] || ""),
"税额": String(invoice["税额"] || ""),
"购买方名称": String(invoice["购买方名称"] || ""),
"购买方纳税人识别号": String(invoice["购买方纳税人识别号"] || ""),
"金额": String(invoice["金额"] || ""),
"销售方名称": String(invoice["销售方名称"] || ""),
"销售方纳税人识别号": String(invoice["销售方纳税人识别号"] || ""),
"原图链接": String(tup_word || "") // 新增输出字段,关联tup_word
}
}));
}这里可能有人会好奇,为什么我之前已经把图片的内容都提取出来了,这里我还要再进行图片的上传呢?
这里是为了进行一个原图的数据对比,比如在实际工作场景中,比方说仓库入库,不是说有数据就可以了的,还需要原始数据进行证明。
否则谁也不知道这个数据的真实性,是否是报假数据,造假等操作。
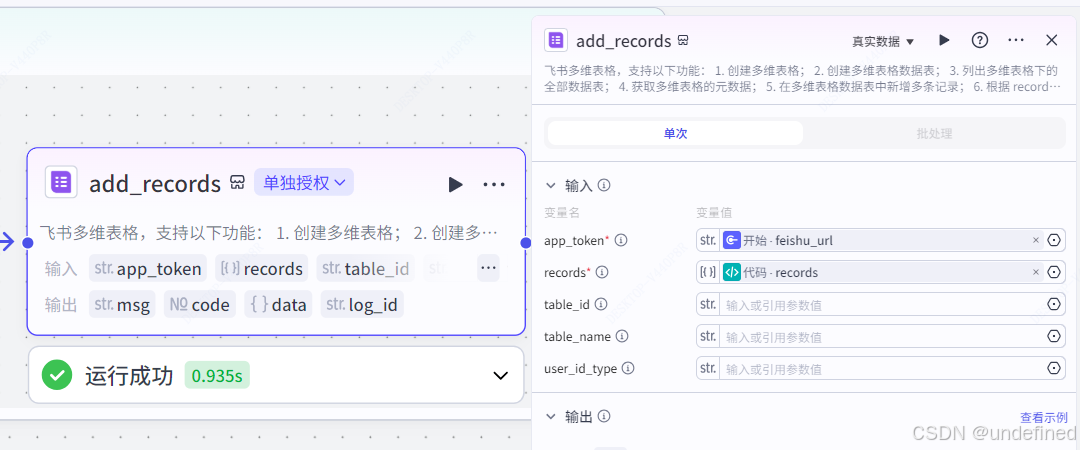
批处理体:飞书多为表格
飞书多维表格节点的作用就是用来承接数据的,记住要授权喔。
这里我们设置参数 app_token 数据来源为开始节点的 feishu_url,数据类型为 String ,设置参数 records 数据来源为代码节点的 records ,数据类型为 Array<Object>。
第五步,结束节点
结束节点我们不需要进行什么操作,但需要用来完成一个闭环,所以要添加。
总结
这个工作流,整体一共有 5 步,总体来看并不难,同时我也把一些代码,提示词都贴出来了,也很详细的说数据的类型是那些。
可以说这次是真的保姆级了,之前我一直没照顾一些小白的感受,有些节点直接一笔带过了,真的十分抱歉!
从本篇文章开始,接下来的文章我将持续秉持【利他】精神。
文章所有的内容都尽自己的能力,以小白的视角去内容输出,也从小白的的视角去写出操作过程可能遇到的问题以及问题的解决方案。
欢迎大家一起监督,一起进步!
本期的内容就到这里了,感谢你的耐心。
如果看完喜欢,请帮忙转发分享一下,你的点赞转发,就是我更新下去的动力!