论文标题:U-Cast: Learning Hierarchical Structures for High-Dimensional Time Series Forecasting
作者: Juntong Ni(倪浚桐), Shiyu Wang(王世宇), Zewen Liu(刘泽文), Xiaoming Shi(师晓明), Xinyue Zhong(钟鑫玥), Zhou Ye(叶舟), Wei Jin(金卫)
机构:埃默里大学(Emory)
论文链接 :++https://arxiv.org/abs/2507.15119++
Cool Paper :++https://papers.cool/arxiv/2507.15119++
Code :++https://github.com/UnifiedTSAI/Time-HD-Lib++
Hugging Face :++https://huggingface.co/datasets/Time-HD-Anonymous/High_Dimensional_Time_Series++
TL;DR:本文针对金融时间序列预测的挑战,采用基于Mixture of Experts(MoE)的FinCast模型,通过激活每个token的top-k专家实现条件计算,显著提升了预测精度和计算效率。通过三类实验(基准数据集性能测试、跨数据集泛化能力测试、实际应用场景验证),证明了FinCast模型在金融时间序列预测中的有效性。
关键词:金融时间序列预测、基础模型、混合专家系统、条件计算

🌟【紧跟前沿】"时空探索之旅"与你一起探索时空奥秘!🚀
欢迎大家关注时空探索之旅时空探索之旅
摘要
时间序列预测(TSF)是时间序列分析中的核心问题。然而,当时间序列数据集的通道数量达到数千甚至更多时(我们将这种场景定义为高维时间序列预测,即HDTSF),它带来了显著的新建模挑战,而这些挑战往往不是传统TSF研究的主要焦点。HDTSF具有挑战性,因为通道相关性通常会形成复杂的层级模式。现有的TSF模型要么忽略这些相互作用,要么在维度增加时难以扩展。为解决这一问题,我们提出了U-Cast,这是一种依赖通道的预测架构,它通过创新的基于查询的注意力机制来学习潜在的层级通道结构。为了分离高度相关的通道表示,U-Cast在训练过程中加入了满秩正则化。我们还发布了Time-HD,这是一个大型、多样化的高维数据集基准。我们的理论表明,利用跨通道信息可以降低预测风险,并且在Time-HD上的实验证明,U-Cast在准确性和效率方面都超过了强大的基线模型。U-Cast和Time-HD共同为未来的HDTSF研究提供了坚实的基础。
Q: 这篇论文试图解决什么问题?
A : A: 论文针对"高维时间序列预测"(High-Dimensional Time Series Forecasting,HDTSF)这一尚未被充分研究的场景,提出并解决以下核心问题:
- 维度灾难下的通道依赖建模
当变量(通道)数量从传统基准的数十到数百跃升至数千甚至两万时,现有通道依赖(CD)方法面临二次复杂度爆炸,而通道独立(CI)方法又无法利用跨变量信息。论文首先通过理论证明:只要通道间存在非冗余信息,CD 的贝叶斯风险严格低于 CI,且维度越高、优势越大。然而,现有 CD 架构要么忽略高维数据普遍存在的隐式层级结构(如地理嵌套、语义子行业),要么无法 scalable 地挖掘该类结构。 - 缺乏高维评测基准
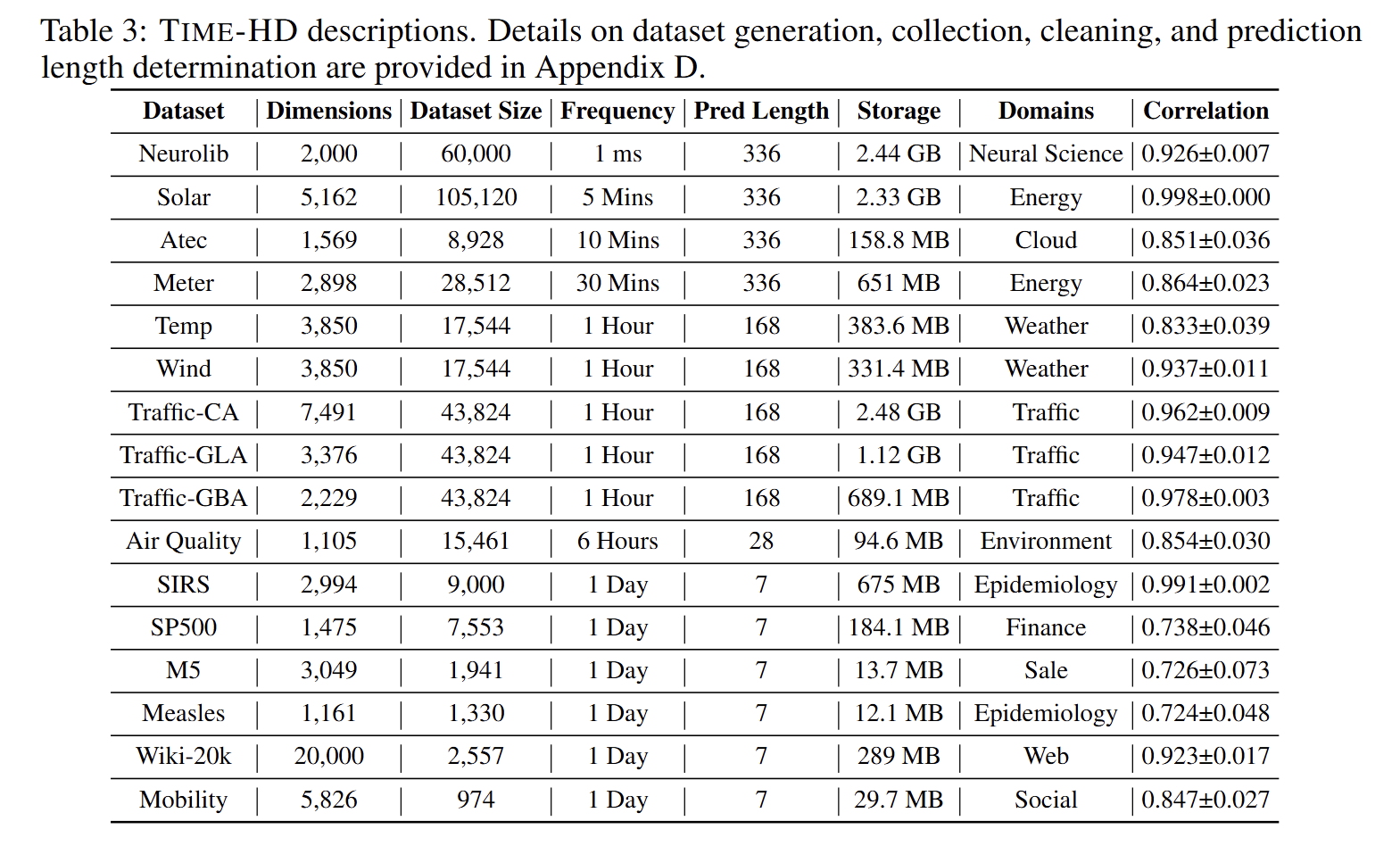
公开数据集普遍低于 1 000 通道,难以验证模型在真实高维场景下的可扩展性与结构学习能力。为此,作者发布 TIME-HD 基准,首次覆盖 16 个领域、1k--20k 通道、毫秒到天级采样频率,并配套标准化预处理与超参优化库 TIME-HD-LIB,填补 HDTSF 实验空白。 - 提出可扩展的层级通道建模框架 U-CAST
- Hierarchical Latent Query Network :利用可学习的潜在查询作为信息瓶颈,将通道数按固定比例 r 逐层缩减,把逐层缩减,把逐层缩减,把 O(C\^2) 的 full self-attention 降至 O(C2/r)O(C^2/r)O(C2/r),显式学习"通道组→子组→单通道"的多级表示。
- Hierarchical Upsampling Network:反向重采样,通过跨层 skip-connection 恢复原始通道维度,实现端到端预测。
- Full-Rank Regularization:在训练目标中加入通道协方差矩阵的负对数行列式,强制隐表示行满秩,解除高度相关通道的线性冗余,增强层级结构的可解释性与泛化性。
综上,论文首次系统论证了"高维+通道依赖"带来的理论增益,提供了可复现的大规模评测环境,并给出兼顾精度与效率的 U-CAST 解决方案,为后续 HDTSF 研究奠定模型与数据基础。
Q: 有哪些相关研究?
A:论文在第 2 节与附录 A、B、C 中对相关研究做了系统梳理,可归纳为三大主线:高维时间序列数据、多变量预测建模策略、以及基准评测工作。以下按类别列出代表性文献,并指出其与 U-CAST/TIME-HD 的差异。
1. 高维时间序列数据集(≥1 000 通道)
| 工作 | 是否用于预测评测 | 是否时序对齐 | 通道规模 | 主要局限 |
|---|---|---|---|---|
| Chronos (Ansari et al., 2024) | ×(仅预训练) | × | 数千--万级 | 预训练时通道独立,下游回到低维 |
| Moment (Goswami et al., 2024) | ×(仅预训练) | × | 数千--万级 | 同上 |
| Moirai (Woo et al., 2024) | ×(仅预训练) | × | 数千--万级 | 同上 |
| TimesFM (Das et al., 2024) | ×(仅预训练) | × | 数千--万级 | 同上 |
| Time-MoE (Shi et al., 2024) | √(仅 1 个数据集) | √ | 1 000 | 评测维度单一 |
| TFB (Qiu et al., 2024a) | √(仅 1 个数据集) | √ | 2 000 | 评测维度单一 |
| TIME-HD(本文) | √(16 个数据集) | √ | 1k--20k | 首个专为 HDTSF 设计的综合基准 |
2. 多变量预测建模策略
2.1 通道独立(Channel-Independent, CI)
- DLinear (Zeng et al., 2023)
- PatchTST (Nie et al., 2023)
- PAttn (Tan et al., 2024)
- FiTS (Xu et al., 2023)
- ModernTCN (Luo & Wang, 2024)
共同点:共享骨干、逐通道前向,复杂度线性,但无法显式利用跨通道信息。
2.2 通道依赖(Channel-Dependent, CD)
| 子类 | 代表方法 | 通道相关性建模粒度 | 高维可扩展性 | 是否显式层级结构 |
|---|---|---|---|---|
| position-wise | TSMixer (Chen et al., 2023) TimesNet (Wu et al., 2022) | 每个时间步内 C×CC\times CC×C 相关 | 需 O(C2T)O(C^2T)O(C2T),显存爆炸 | × |
| token-wise | iTransformer (Liu et al., 2024a) TimeXer (Wang et al., 2024c) | 整条序列作为 token,O(C2)O(C^2)O(C2) | 显存 O(C\^2),万级通道困难 | × |
| cluster-wise | CCM (Chen et al., 2024) DUET (Qiu et al., 2024b) | 先聚类→簇内 attention | 聚类开销 + 簇间忽略,单层 | 单层,非层级 |
| hierarchical latent query | U-CAST(本文) | 逐层压缩 C_{\\ell}=C/r^{\\ell},O(C^2/r) | 16× 时间/显存降低 | √ 可解释多级注意力 |
3. 基准与评测体系
| 基准 | 最高通道数 | 是否覆盖高维 | 是否标准化预处理 | 是否开源工具链 |
|---|---|---|---|---|
| M3/M4 (Makridakis et al., 2000; 2018) | 1(单变量) | × | √ | √ |
| Monash (Godahewa et al., 2021) | <200 | × | √ | √ |
| BasicTS/+ (Liang et al., 2022) | <200 | × | √ | √ |
| TFB (Qiu et al., 2024a) | 2 000 | 仅 1 个 | √ | √ |
| TIME-HD | 20 000 | 16 个 | √ | TIME-HD-LIB(自动超参、分布式) |
4. 理论分析
- Bayes-risk 单调性:本文定理 2 推广了经典 VAR 信息集结论,首次形式化证明"每增加一个非冗余通道,贝叶斯风险非增",为 CD 在高维场景的优势提供理论背书。
- Full-rank 正则化:与常规协方差行列式最大化(Dinh & Bengio, 2014; Achille & Soatto, 2018)相比,U-CAST 将其嵌入层级注意力,并给出"行秩满 ⇒ 冗余消除"的定理 3,直接服务通道解耦目标。
5. 小结
现有工作要么停留在低维评测,要么虽用高维数据却仅做预训练且通道独立;CD 方法里,position-/token-/cluster-wise 均未专门设计"可扩展 + 层级"机制。U-CAST 与 TIME-HD 共同填补了"高维通道依赖建模"与"公开基准"双重空白,为后续研究提供了可复现的实验栈与强基线。
Q: 论文如何解决这个问题?
论文从"理论-模型-数据"三个层面系统性地解决高维时间序列预测(HDTSF)难题,具体路线如下:
1. 理论层面:量化通道依赖价值,奠定方法合理性
-
定理 1(双变量有效性):针对简单的双变量时间序列模型,首次推导出 "通道依赖(CD)" 与 "通道独立(CI)" 的预测风险差解析式。明确证明:只要两个通道不是完全冗余(存在交叉关联),CD 方法的预测误差一定比 CI 小,从数学上验证了 "利用变量关联" 的必要性。
-
定理 2(高维增益性):针对高维(P 维)时间序列,证明随着新增通道数量增加,预测风险会单调递减(新增通道只会提升或不影响预测效果)。且维度越高,累计的预测增益(相比只用 1 个通道)越大,为 "处理高维数据不仅可行,还能更精准" 提供理论支撑,也驱动后续模型向 "高效利用高维关联" 设计。
-
定理 3(满秩正则化依据):补充证明:通过优化特征协方差矩阵的满秩性,可强制消除变量间的线性冗余,让每个通道的信息更独特,同时显化变量的层级结构,为模型的正则化策略提供理论依据。
2. 模型层面:设计 U-CAST 模型,实现高效精准预测
2.1 核心流程(5 大模块,兼顾效率与精度)
-
通道嵌入(Channel Embedding):将原始长度为 T 的时间序列,一次性压缩为固定维度 d 的特征矩阵(维度从 "通道数 × 时间长度" 转为 "通道数 × 特征维度")。后续计算不再依赖原始时间长度 T,大幅降低计算负担。
-
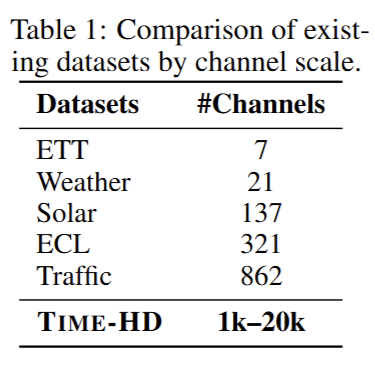
层级隐藏查询网络(HLQN):按 "指数递减" 方式逐步缩减通道数(比如每一层通道数变为上一层的 1/16),用 "可学习查询" 作为信息筛选瓶颈,只保留关键关联信息。通过注意力机制提炼特征,将传统模型 O (C²)(C 为通道数)的复杂度降至 O (C²/r)(r 为缩减比,典型值 16),轻松处理万级通道。
-
时序对齐(Temporal Alignment):在压缩后的低维特征上,用共享预测器提取时间动态规律,保证 "压缩通道" 和 "恢复通道" 过程中,时序信息不丢失、对齐一致,避免预测时出现时序偏差。
-
层级上采样网络(HUN):按 HLQN 的反向路径恢复通道数,每层用 "上一层特征作查询、当前层特征作数据" 的交叉注意力机制,结合残差连接(直接保留底层特征),低失真地重建原始通道维度的特征,避免信息丢失。
-
输出投影(Output Projection):融合 "原始嵌入特征" 和 "重建特征",通过线性变换输出预测结果,再逆标准化恢复原始数据的数值尺度(比如股价、温度的真实范围),保证预测结果的实用性。
2.2 优化目标(解耦冗余,显化结构)
-
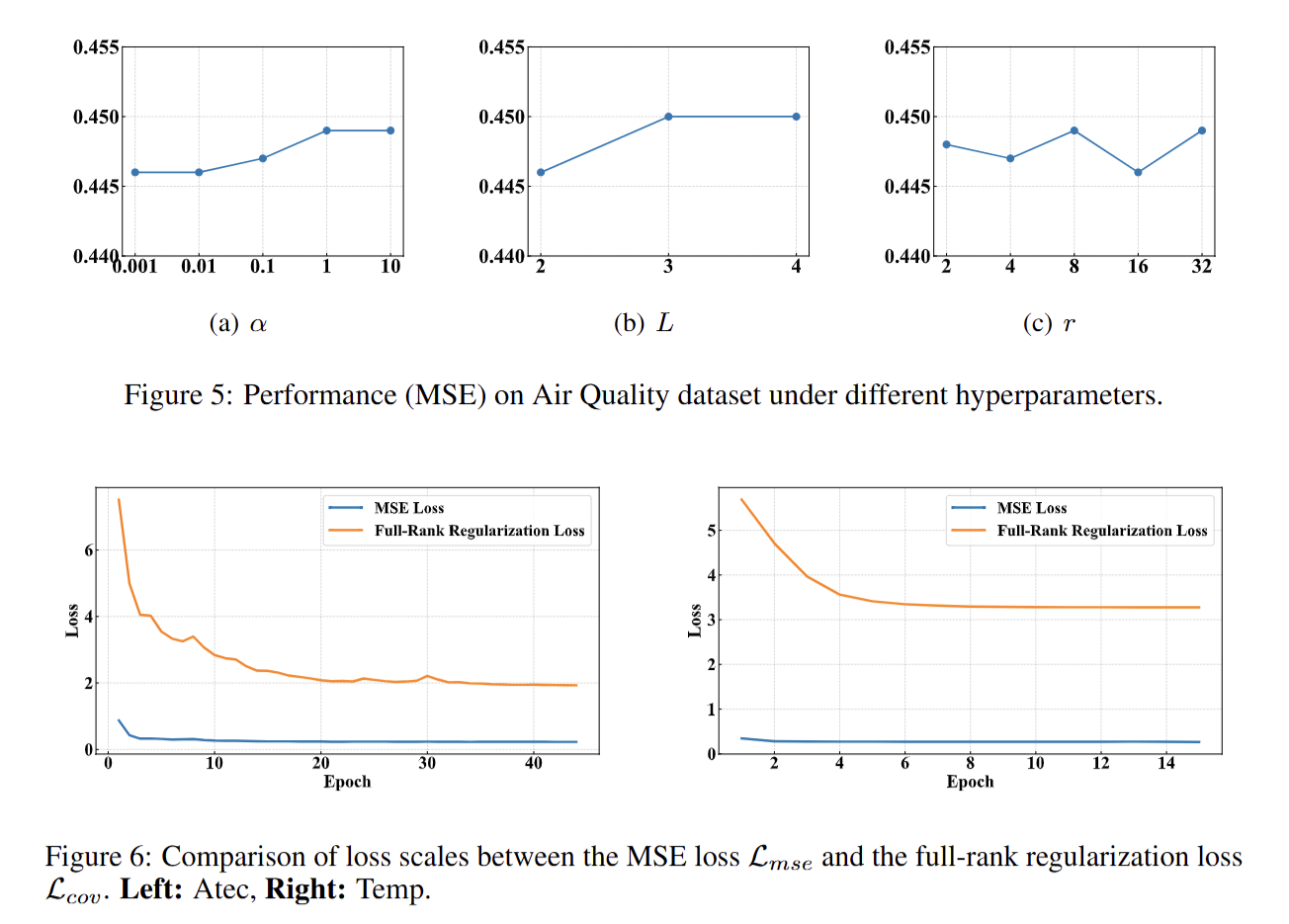
满秩正则化(Full-Rank Regularization):对每层特征的协方差矩阵,添加 "最大化行列式" 的正则化损失(等价于推离奇异值为 0 的情况)。强制让特征矩阵保持满秩,消除变量间的线性冗余(比如 A 通道信息完全可由 B 通道推导的情况),同时显化变量的层级关系(比如哪些通道属于同一类别)。
-
总体损失:结合 "预测误差损失(MSE,衡量预测值与真实值的差距)" 和 "满秩正则化损失",通过自适应权重 α(0.001~10 之间自动调整)平衡 "预测精度" 和 "变量解耦效果",避免过度压缩导致信息丢失。
2.3 效率优势(大幅提升速度,节省资源)
-
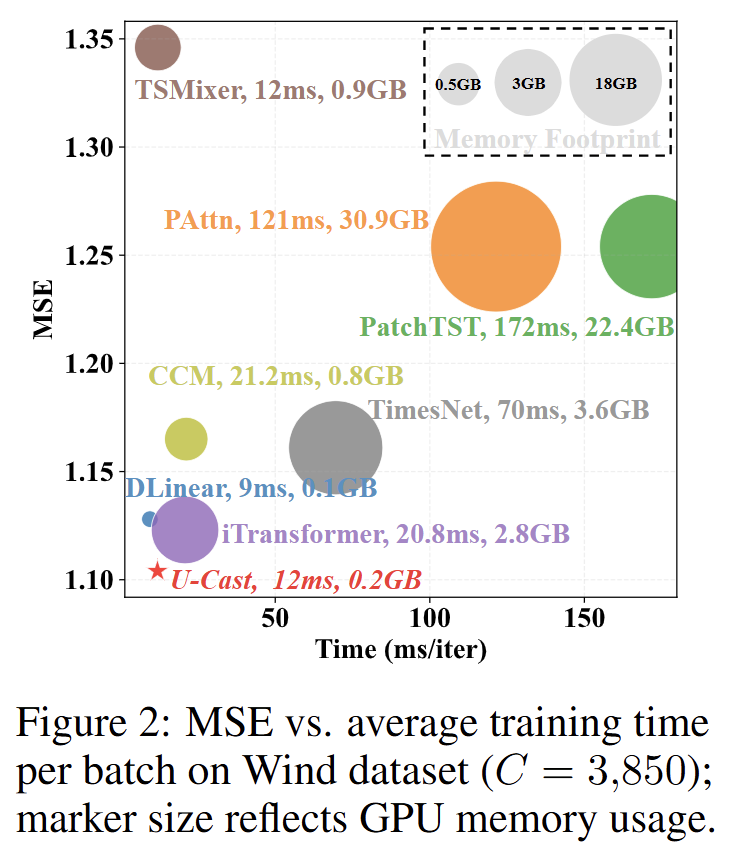
相比传统高维预测模型(如 iTransformer),U-CAST 通过 "层级压缩 + 固定维度嵌入",时间复杂度和显存占用均降至原来的 1/r(r=16 时,理论加速 16 倍、省显存 16 倍)。
-
实测验证(A100 显卡,850 通道数据):U-CAST 每步训练仅需 12 毫秒、0.2GB 显存,而 iTransformer 需 20.8 毫秒、2.8GB 显存;通道数越多(如 2 万通道),U-CAST 的速度和显存优势越明显,不会出现传统模型 "通道爆炸" 导致的训练卡死问题。
3. 数据层面:发布 TIME-HD 基准,统一高维测试标准
3.1 数据集特性(覆盖全面,贴近实际)
-
规模与多样性:包含 16 个数据集,通道数 1161~20000 个,覆盖神经科学(脑信号)、气象(全球气温)、交通(城市传感器)、金融(美股 500 指数)、流行病学(疫情数据)等 10 个领域,满足不同高维场景测试。
-
真实性与合理性:既有真实观测数据(如 Solar-5 光伏数据、Wiki-20k 网页流量数据),也有基于微分方程的仿真数据(如神经信号仿真、疫情传播仿真),避免单一数据的局限性;统一处理时间戳、缺失值(如插值填充),并按实际采样频率设定预测步数(毫秒 / 分钟级数据预测 336 步,小时级预测 168 步,天级预测 7 步),杜绝 "天级数据预测 720 步" 这种脱离实际的设定。
3.2 开源工具链(降低研究门槛)
- 配套发布 TIME-HD-LIB 工具包,集成 "数据标准化预处理、自动超参搜索、分布式训练、统一评估指标(如 MAE、RMSE)" 等脚本,研究者无需手动处理复杂的数据格式和训练流程,可直接用该基准测试自己的模型,方便公平对比不同方法的效果。
Q: 论文做了哪些实验?
A:
论文围绕"高维时间序列预测(HDTSF)"共设计了 4 类实验,覆盖合成控制、大规模基准评测、消融与可视化、以及效率剖析,形成从理论验证到实际可扩展性的完整证据链。
1. 合成数据控制实验(Section 3.2 & Appendix K)
- 目的:在已知通道依赖关系的理想场景下,验证 "通道关联(CD)模型随维度增加优势扩大" 的理论结论。
- 设计:生成两种特性的高维数据(通道独立、通道完全依赖),设置不同维度规模,对比 CD 和 CI 两类方法的预测效果。
- 意义:直接验证理论假设,证明维度越高、通道关联越丰富,CD 方法的预测增益越显著。

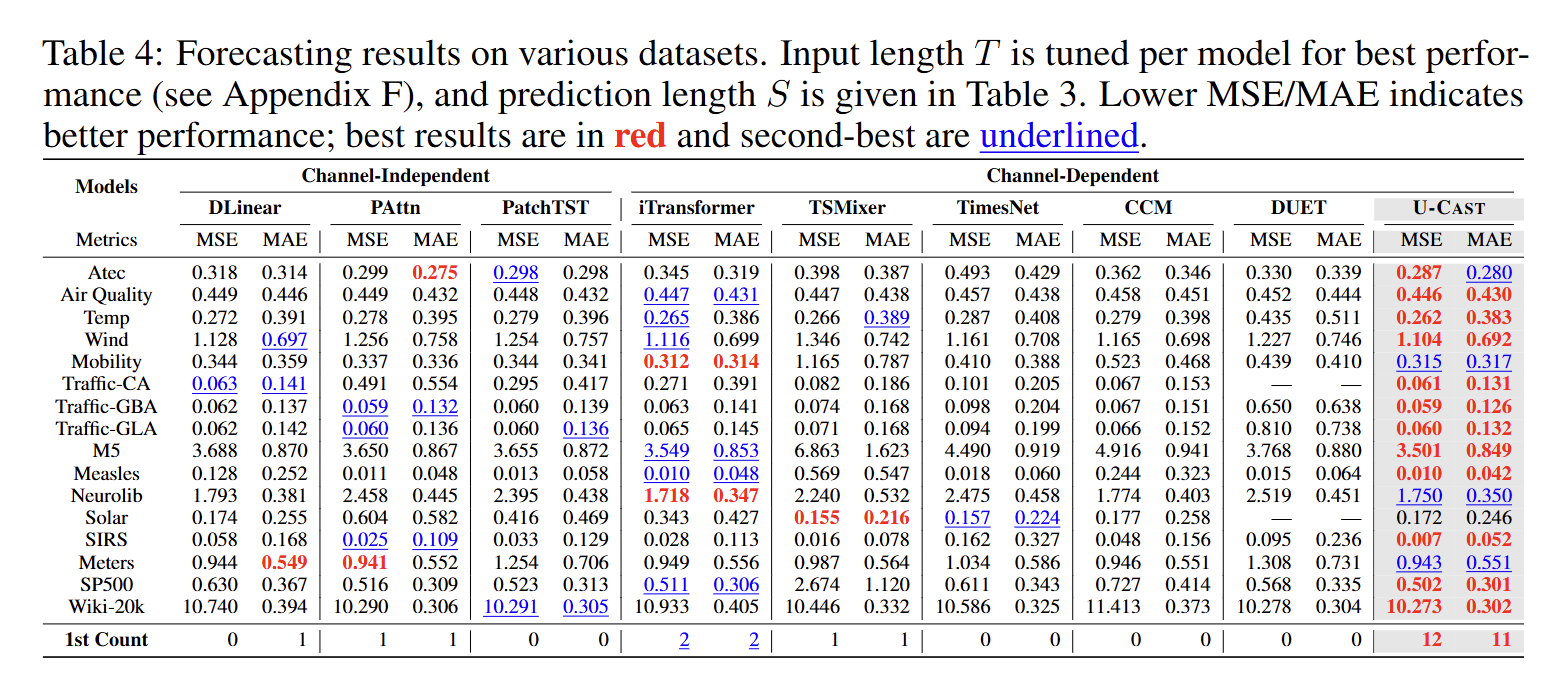
2. 大规模基准评测实验(Section 6 & Appendix F)
-
目的:在真实 / 仿真高维数据上,全面评估 U-CAST 模型的预测精度与训练效率。
-
设计:基于 TIME-HD 基准的 16 个数据集(覆盖 10 个领域,通道数 1k-20k),与主流 CI、CD 类模型对比;统一测试协议(按数据频率设定预测步数),同时记录训练时间、显存占用等效率指标。
-
意义:验证 U-CAST 在实际场景中的性能优势,确认其在精度和效率上均优于现有模型,且通道数越多优势越明显。
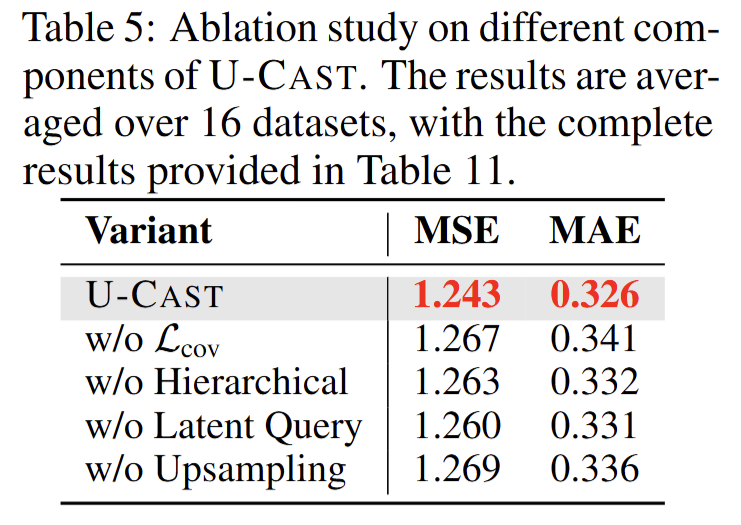
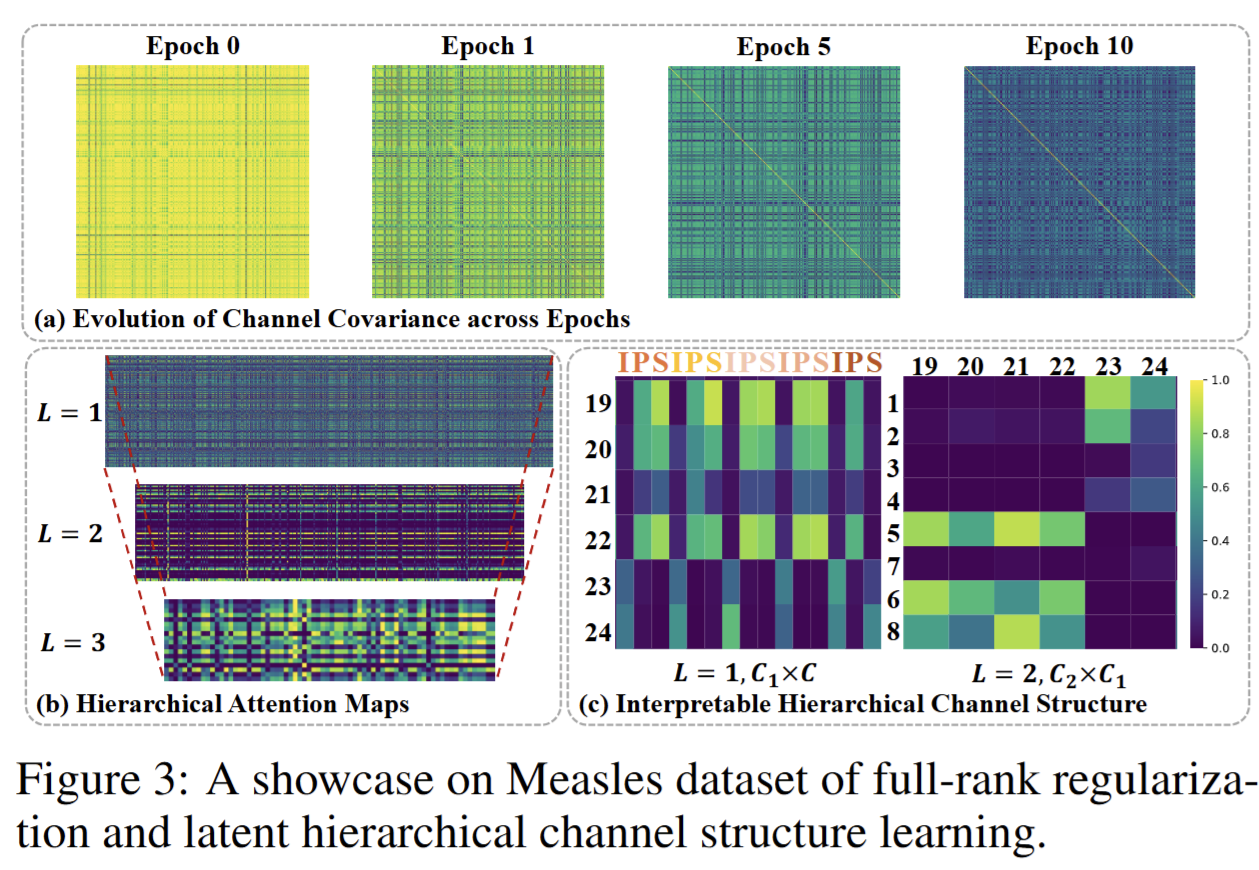
3. 模型消融与可视化分析实验(Section 6 & Appendix P/O)
-
目的:拆解模型核心组件的作用,分析超参敏感性,直观展示模型工作机制。
-
设计:
-
组件消融:逐一移除 U-CAST 的关键模块(满秩正则、层级结构、潜在查询、上采样),对比模型性能变化;
-
超参敏感性:测试正则权重、层级数、通道缩减比等超参对结果的影响,确定最优范围;
-
可视化:绘制通道协方差矩阵演化图(验证冗余消除效果)、层级注意力热图(展示特征提取的层级结构)。
- 意义:证明核心组件缺一不可,明确超参选择依据,让模型的决策过程更具可解释性。
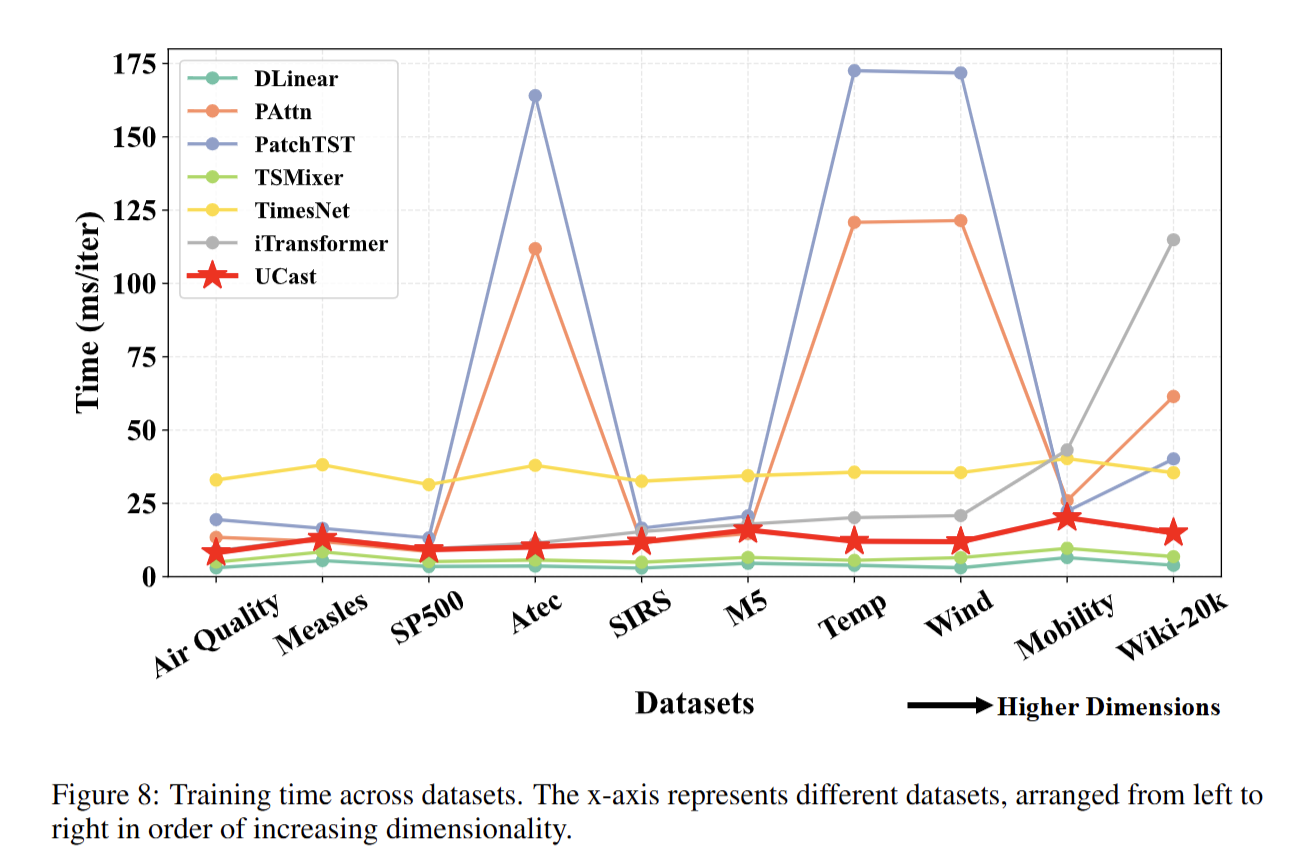
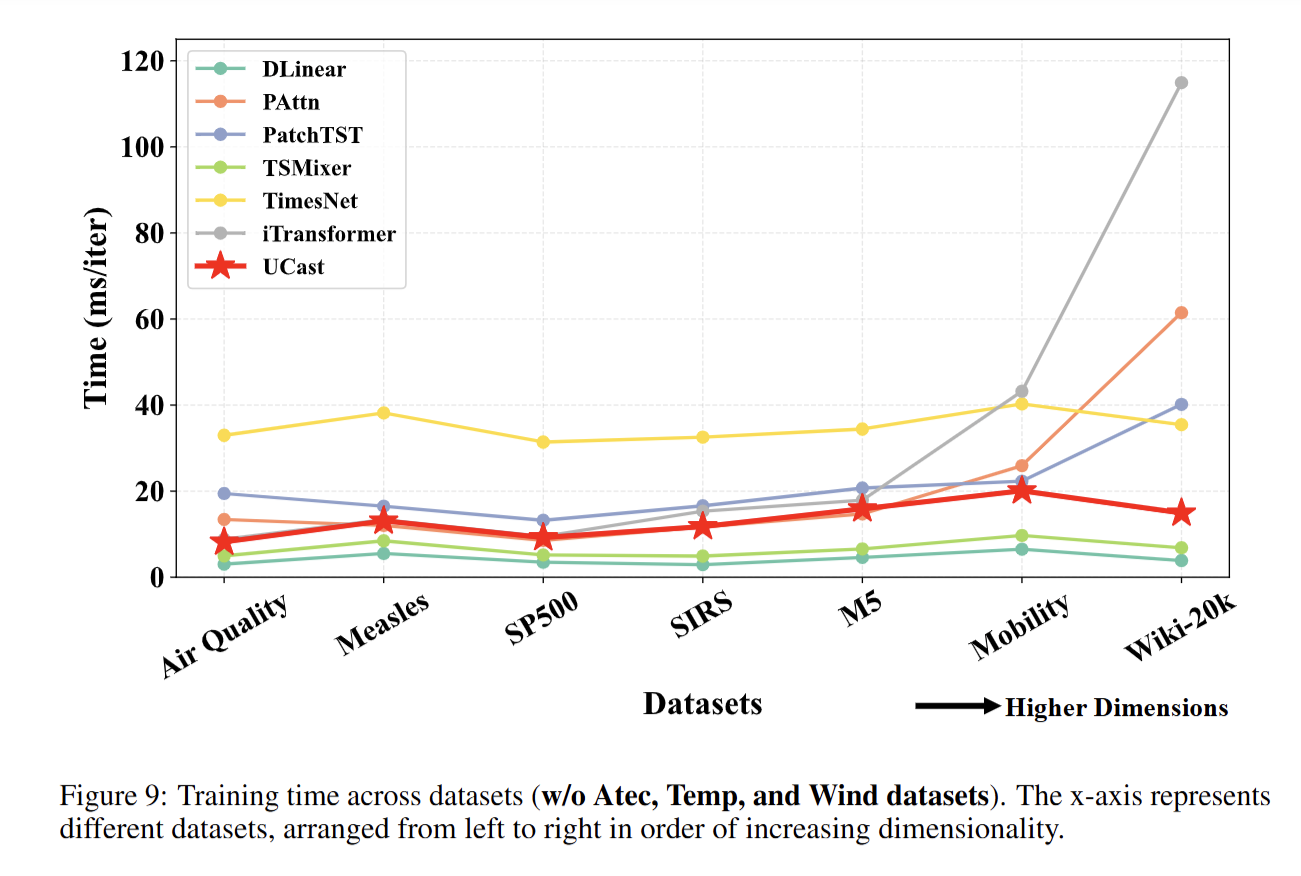
4. 效率与可扩展性剖析实验(Appendix L/Q)
-
目的:验证 U-CAST 在高维场景下的计算效率和可扩展性。
-
设计:从理论上推导模型的时间 / 显存复杂度,再在不同通道规模(尤其是 2 万通道的超大场景)下,实测训练 / 推理时间、峰值显存占用;对比传统模型在高维场景下的性能衰减情况。
-
意义:证明 U-CAST 的复杂度随通道数增长更平缓,在超大维度下仍能保持高效运行,具备实际部署价值。
🌟【紧跟前沿】"时空探索之旅"与你一起探索时空奥秘!🚀
欢迎大家关注时空探索之旅时空探索之旅