这篇文章主要总结了RAG技术方案及RAG关键技术点,同时基于开发项目对RAG也有一些思考,写出来大家一块讨论下。
如果您熟悉RAG,可以直接看【RAG技术思考】
1、概述
说起RAG(Retrieval Augmented Generation)大家都很熟悉-检索增强生成,但可能有人不理解为什么要有RAG,这里简单说明下。
文本大模型足以支撑80%的问答场景,但对于特定场景,大模型的回答不尽人意,甚至会产生幻觉进而输出错误的答案,比如以下场景:
- 时效性要求较高场景:人民银行发布新的利率(利率较之前有变化),如果马上问大模型新的利率,会出现之前的利率(对于幻觉度高的模型,甚至会输出错误利率)。
- 特定场景:比如律师、医生、标准件、智能客服等问答场景。就拿智能客服场景来说,如果客户问一些产品的参数信息问题,只靠文本大模型是绝对不足以回答客户问题。
- 文档问答:对于某一本书、某一个报告进行问答时,只靠文本大模型,我们肯定无法得到想要的答案,我们需要将书本输入到大模型中才会得到答案。
所以,我们为了提高大模型在特定场景、特定问答的准确性,可以给大模型提供一些输入参考,供大模型思考整理并输出正确答案,这便是RAG的价值。
2、RAG技术方案
RAG现有的技术方案比较成熟,如开源框架RAGFlow,下面图片便是RAGFlow的技术线路图,其他RAG框架的主要技术线路与RAGFlow差别不大,我们以下图为主进行探讨。
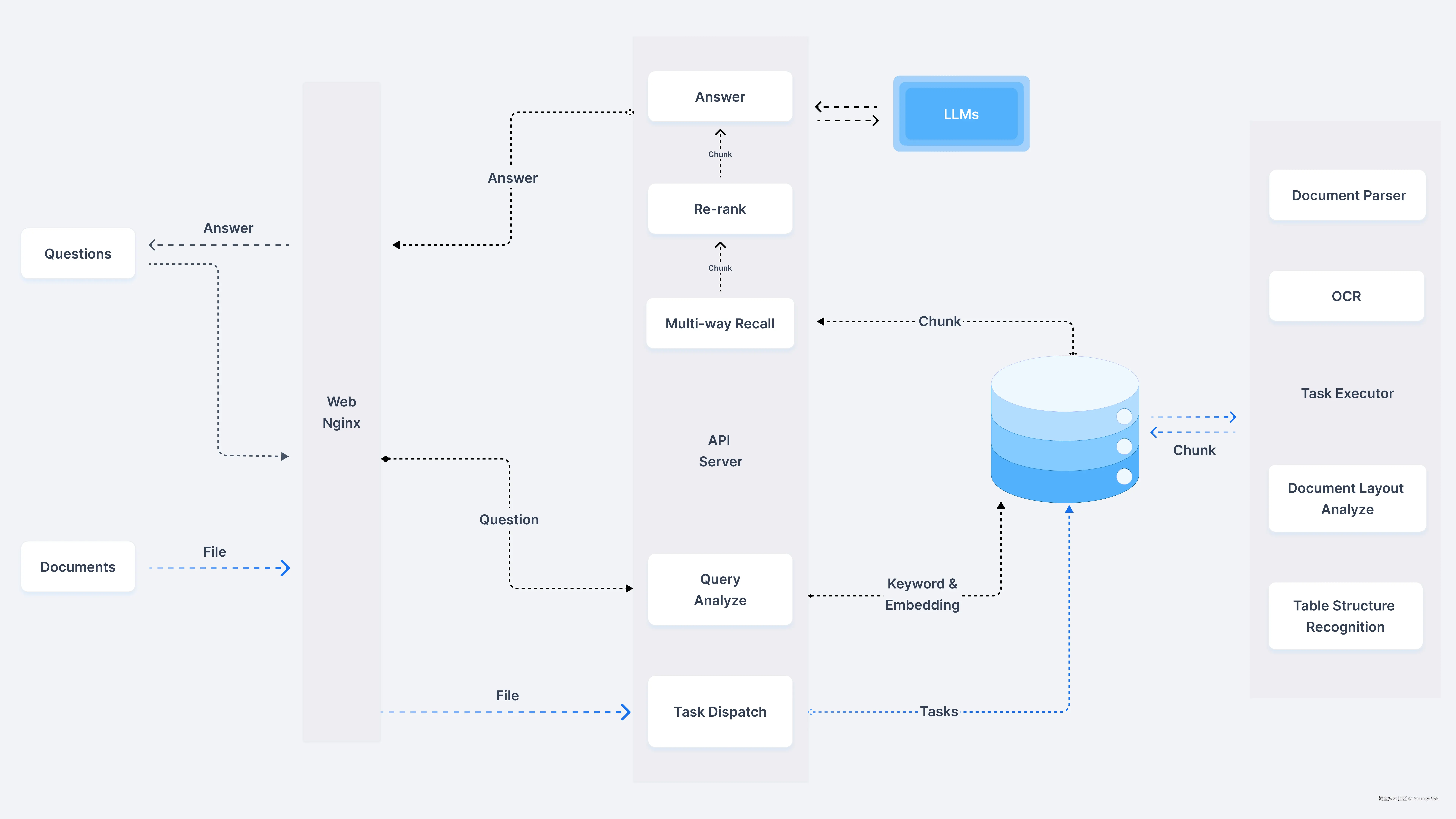
在上图中我们看到问答大模型之前,需要将文档向量化后放到向量数据库。当输入问题之后,我们根据用户的输入问题在向量数据库进行匹配(将问题向量化后,与向量数据库中文档块向量计算相似值),获取匹配度较高文档。将文档块和问题一块输入给大模型,进而获取答案。
这是之前写的一个简单demo,大家感兴趣可以实操下:使用豆包模型API创建 RAG:一步一步的指南
2.1、RAG关键细节
整体流程我们知道后,对于方案的关键细节我们一起来看下。
2.1.1、文档解析
这个步骤非常关键,因为他会涉及原文还原度的问题,如果获取到的内容和原文相差较大,那么答案的准确度肯定会大大降低,对于txt、docx文本文档内容好处理,但是对于pdf、图片等及到OCR识别的内容,会增加文档识别难度。尤其对于旧书本扫描的PDF(字迹不清楚),如果高度还原原书本内容,具有较高的挑战。如下图为书本扫描版(这本还是比较清晰)

2.1.2、拆分chunk块
chunk块的拆分决定了语句的语义是否完整,如果只是简单粗暴的按照固定长度进行拆分,那么问答效果将大打折扣。不同的文体类型拆分也会有差别,比如法律相关的书籍和普通书籍(人物传记、报告等)文体结构会有较大差别,所以在chunk块拆分时,我们需要认真思考。
一般来说chunk块也不能太长,如果chunk块太长,他会影响整句话的语义,也会影响知识召回。
我们通常使用固定字数+段落拆分进行拆分chunk块,设置默认chunk长度为700,我们获取到文档识别内容后,尽量按照段落进行拆分chunk。比如,如果某一段长度小于700,那么我们不再添加其他文本,将这一段作为一个chunk块进行向量化存储。如果某一段的chunk块超过700,那么会分成两个chunk,同时两个chunk内容互相有冗余信息,尽量保证语义完整性。
2.1.3、向量化
关于向量化细节,不同的语言、领域,所需要的模型也是不一样的,没有一招鲜吃遍天的通用向量化模型,各个向量化模型的测试可以参考这个排行榜:向量化模型排行榜
关于向量维度,也不是维度越高越好,虽然说维度越高关注的细节越多,但是对于内存、向量化时间、向量匹配也有一定的影响。
因为我们是素材管理系统,主要是中文文本内容较多,因此我们使用的是【BAAI/bge-m3】,目前来看效果还不错。
2.1.4、检索重排
检索重排是一个非常关键的步骤,他会弥补向量检索的不足,使召回的内容主旨更加切合你的问题,下面我们举两个例子看下。
通过向量检索,你会找到相似度较高的文档内容排序,但是语义相关不一定是最高的,比如你要查询【减轻头疼】,向量化检索到如下结果且按照这个顺序【减轻胳膊疼】、【缓解头痛】返回。但是根据语义,【减轻】和【缓解】相似,【头疼】和【头痛】。所以我们要使用重排模型,让模型按照语义进行重新排序,从而得到【缓解头痛】、【减轻胳膊疼】这个顺序。只有相关顺序正确,我们才能获得想要的答案。
除了语义理解,还有要过滤一部分噪音,原始检索召回的文档中,可能存在部分与问题弱相关甚至无关的内容(例如,因包含个别相同词而被召回)。重排通过严格的相关性打分,将这些低质文档排在末尾(或直接过滤),确保输入生成模型的上下文 "信噪比" 更高。
3、RAG技术思考
假如我们把上面所有的关键步骤都做得非常好,我们就能使用RAG打遍天下无敌手了吗,显然是不可能的。在做系统过程中,遇到如下几个问题典型问题,这几个问题还没有最优的解决方案(如果你这边遇到过,且已解决,不妨在评论区讨论下)。
3.1、多模态问答
现在RAG大都是文本问答,但是对于视频、语音、图片(图片理解后的内容,不只是OCR结果)的问答,RAG能做的较少。如果是多模态内容,又该如何去解决呢?在做系统过程中也遇到了这个问题,我们的解决方案是将多模态转成文本,再进行向量化,如下图:
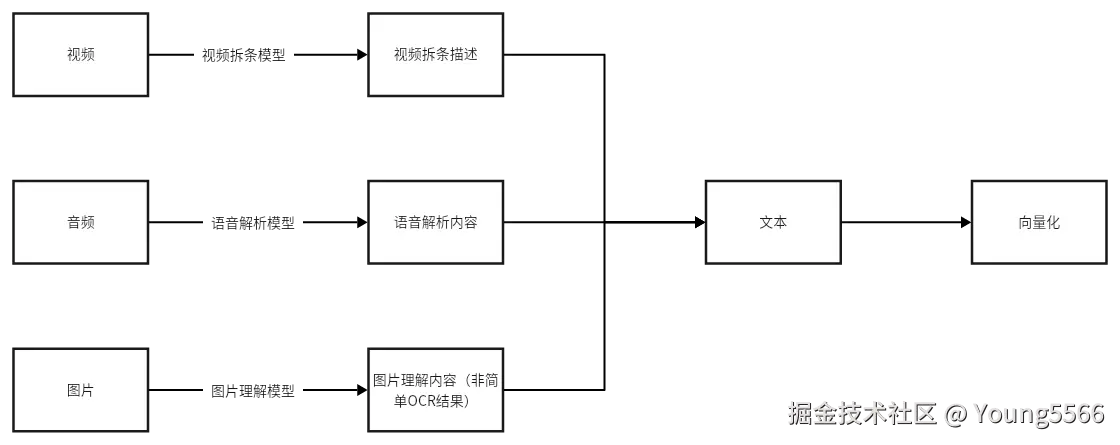
通过这样转化,多模态素材理解后的内容得以向量化(其实多模态素材本身可以向量化,但是素材向量化后对于问答帮助不大),根据这些内容,我们可以获取到想要的答案。
但是多模态理解还是如下两个问题
-
理解不到位:这么说有点抽象,我们举个例子,现在的图片(视频)理解是最直接的理解,如下图,他会理解为【这是一张一个留着齐肩头发的人的单色肖像照,穿着深色衬衫。脸部被一个模糊的矩形遮挡,使注意力集中在整体构图、头发和服装上。背景看起来很素净,强调了简约和艺术风格。灯光营造出柔和的阴影,突出了颈部和锁骨区域。】,但实际上她是【杜鹃】,如果你问【杜鹃锁骨突出吗】,你是检索不到这条文档记录,所以我们在做多模态内容理解时,需要加入人脸识别库,才能保证RAG检索内容的准确性。语音识别也是如此,加入声纹识别之后,才能完美闭环。

-
素材内容过长: 目前视频拆条耗时与视频时长比例是3:4,所以现在测试的素材都是小于十分钟,后续对于超长视频,它的拆条解析也需要优化解决。
3.2、语义理解
这里说的语义不是【减轻头疼】、【缓解头痛】的短句或者关键词的理解,而是长文本的理解。比如在语音识别中,存在着大量的代词(你、我、他,你们、我们、他们),这个代词是需要在较长的文本中才能找到答案,而在第一步通过向量检索相关文档时,由于代词和查询的关键词不一样,有很大几率会漏掉这段文本。因此,正确的语义文本没有召回,即使再怎么重排,答案也会失真。

3.3、多轮对话
文本大模型的多轮对话比较简单,把聊天内容直接给大模型就行,然后让大模型根据聊天上下文输出最新问题的答案,那么RAG多轮对话也可以这么做吗,那显然是不可以的,因为你最新问题的答案可能不在上下文聊天内容中。比如:
图中我们根据工作报告问答2024年最新的房地产政策,大模型根据问题帮我们梳理了如下几条,我们下次问答的问题是【请详细说下第一条】,如果只拿问题去检索,那我们一定获取不到想要的答案,我们需要对上面的对话对新问的问题进行改写,这样我们才能获取到想要的答案。
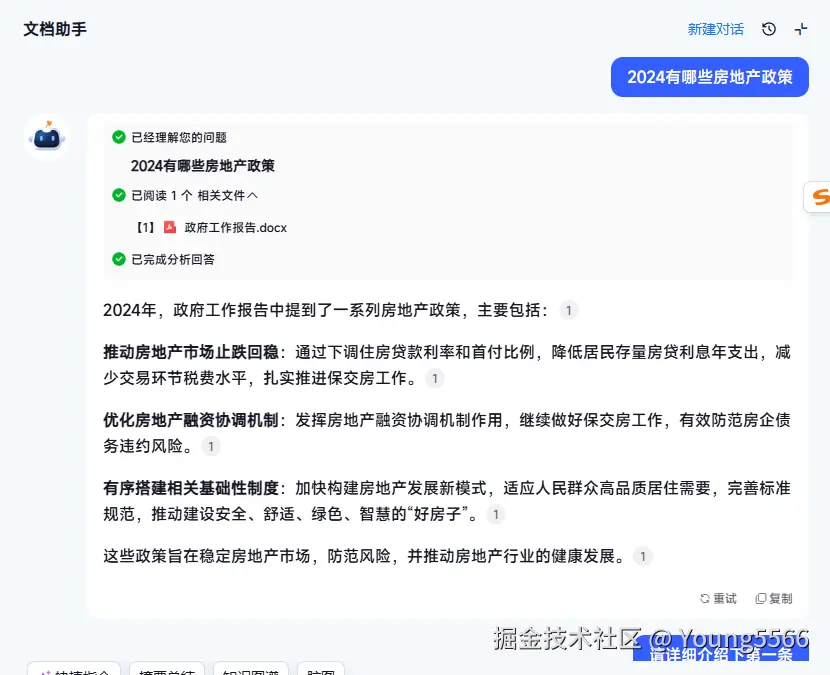

其实这个不算是一个难点,只加入一步让大模型改写就可以,但是聊天过程中有多个主题,要做到改写准确无误,那还是有一定的挑战。
3.4、原文件定位
这个难点其实不是所有RAG都会遇到,由于我们做文档问答,所以会遇到这个问题。
做文档问答,源文件定位是一个非常重要的功能,根据回答中的引用,可以直接定位到源文件内容,让我们知道答案的依据是来自于哪里。
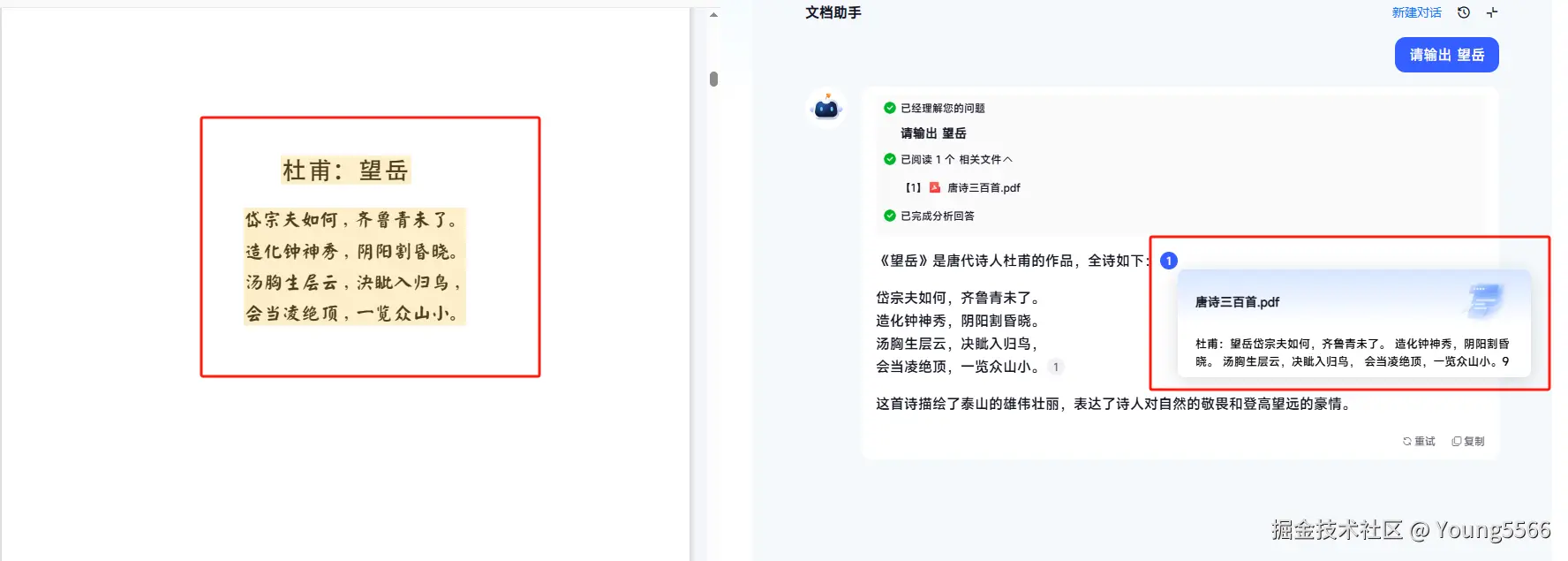
我们使用的解决方法是全部文档类型转换为pdf,然后再通过OCR识别,经过OCR识别会返回段落、页数以及chunk块的坐标内容,我们在对回答结果添加引用时,可以将页数、坐标数返回给前端,然后让前端根据坐标点进行添加遮罩层展示。
4、RAG总结
RAG已经大大提高了模型的回答准确率,并拓宽了大模型的使用场景。我们可以给大模型提供非常专业、特定场景的内容,让大模型成为这一领域的专家,然后对外提供服务。比如如下场景:
- 直播回答助手:对于直播卖书等销售场景,可以把产品信息放入到知识库中,然后获取直播评论后,通过大模型对直播评论进行回答。
- 律师:将法律相关图书向量化到知识库中,然后可以将大模型当成一个小律师进行相关法律问题问答。
实际应用场场景肯定还有非常非常多,但总的来说,RAG确实拓宽了大模型的使用场景。
尽管RAG提高了大模型的准确率,但是还是有一些不足,相信不久,RAG的技术会更加成熟。