在人工智能飞速发展的今天,机器学习作为其核心技术,正深刻改变着我们的生活与工作。从 AlphaGo 战胜围棋世界冠军,到日常的智能推荐、人脸识别,机器学习的应用无处不在。本文将从基础概念出发,带你系统了解机器学习的核心逻辑、关键术语、学习类型及模型评估方法,为入门机器学习打下基础。
一、什么是机器学习?
本质:
机器学习的本质是让计算机从数据中自主学习规律,并利用这些规律解决实际问题。
**1.**处理某个特定的任务,以大量的经验为基础。
**2.**对任务完成的好坏给予一定的评判标准。
**3.**通过分析经验数据,使任务完成的更好。
简单来说,传统编程是 "人类写规则,机器执行",而机器学习是 "机器从数据中找规则,自主优化"。
二、机器学习核心术语:读懂数据的 "语言"
1. 数据相关术语
数据集:数据记录的集合称为一个"数据集"
样本:数据集中每条记录是关于一个事件或对象的描述,称为"样本"
特征(属性):反映事件或对象在某方面的表现或性质的事项
属性空间:所有特征构成的多维空间,每个样本对应空间中的一个点(如 "色泽 + 根蒂 + 敲声" 构成三维空间,每个西瓜对应一个三维坐标)。
2. 学习过程术语
训练集:用于模型学习的数据,包含 "特征 + 标签"(如标注了 "好瓜 / 坏瓜" 的西瓜数据)。
测试集:用于验证模型性能的数据,通常不包含标签,由模型预测后与真实结果对比(如未标注的西瓜数据,测试模型能否正确判断好坏)。
模型:通过训练得到的 "规律总结器",能根据新样本的特征输出预测结果(如 "色泽青绿 + 根蒂蜷缩→好瓜" 的规则集合)。
三、机器学习的两大核心类型:监督与无监督
1. 监督学习:有 "老师" 指导的学习
监督学习的训练数据包含特征 + 标签(即 "正确答案"),模型通过学习特征与标签的对应关系,实现对新数据的预测。
分类:标签是离散值(如 "好瓜 / 坏瓜""垃圾邮件 / 正常邮件"),目标是将新样本归入已知类别。
回归:标签是连续值(如房价、温度),目标是预测新样本的具体数值(如 "88 平米房屋→价格 88 万元")。
2. 无监督学习:无 "答案" 的自主探索
无监督学习的训练数据只有特征,没有标签,模型需自主发现数据中的隐藏结构。无需人工标注标签,让机器从无标签数据中自主探索规律
聚类任务:将相似样本自动归为一类(如无需标注,自动将用户按消费习惯分为 "高消费群""低频消费群")。
3.集成学习:通过构建并结合多个学习器来完成学习任务。
集成学习通过组合多个基础模型的预测结果,利用 "群体智慧" 提升性能,核心是整合优势、弥补单一模型局限。
关键前提
基础模型需具有多样性(预测误差不高度相关)
单个模型需具备一定准确性(不能太差)
四、模型评估:如何判断模型好坏?
1. 基础评估指标
错误率与精度:错误率是分类错误的样本数占样本总数的比例,精度 =' 1 - 错误率'。
残差:回归任务中,预测值与真实值的差异(如预测房价 100 万,实际 95 万,残差 5
查准率(P)与查全率(R):
查准率:预测为 "正类" 的样本中,实际为正类的比例(如预测 10 个好瓜,其中 8 个真的好,查准率 80%)。
查全率:所有实际正类中,被正确预测的比例(如实际 10 个好瓜,模型预测对 8 个,查全率 80%)。两者通常存在权衡:追求 "选的都是好瓜"(高查准率)可能漏掉部分好瓜(低查全率),反之亦然。


2. 数据划分方法
为确保评估客观,需合理划分训练集与测试集:
留出法:直接将数据集D划分为两个互斥的部分,其中一部分作为训练集S,另一部分用作测试集T 。
交叉验证法:先将数据集D划分为k个大小相似的互斥子集,每次采用k−1个子集的并集作为训练集,剩下的那个子集作为测试集。
3. 常见问题:欠拟合与过拟合
欠拟合:模型未学好数据规律(如仅用 "色泽" 判断西瓜好坏,忽略根蒂、敲声等关键特征),表现为训练误差和测试误差都高。
欠拟合的处理方式: 1. 添加新特征,当特征不足或者现有特征与样本标签的相关性不强时,模型容易出现欠拟合。 2. 增加模型复杂度:简单模型的学习能力较差,通过增加模型的复杂度可以使模型拥有更强的拟合能力。 3. 减小正则化系数:正则化是用来防止过拟合的,但当模型出现欠拟合现象时,则需要有针对性地减小正则化系数。
过拟合:模型 "死记硬背" 训练数据,甚至学到噪声(如认为 "有锯齿的才是树叶",误判光滑树叶为非树叶),表现为训练误差低但测试误差高。
过拟合的处理方式: 1. 增加训练数据:更多的样本能够让模型学习到更多更有效的特征,减小噪声的影响。 2. 降维:即丢弃一些不能帮助我们正确预测的特征。 3. 正则化(regularization)的技术,保留所有的特征,但是减少参数的大小(magnitude),它可以改善或者减少过拟合问题。 4. 集成学习方法:集成学习是把多个模型集成在一起,来降低单一模型的过拟合风险。
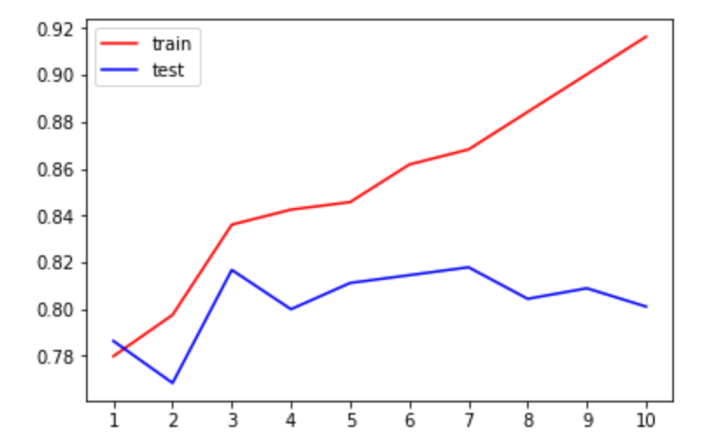
上为过拟合,test低。若欠拟合,train和test都低。正常时都高或走向一致。
五、机器学习的核心原则
1.奥卡姆剃刀原理:
"如无必要,勿增实体", 在所有可能选择的模型中,我们应该选择能够很好的解释已知数据,并且十分简单的模型。 如果简单的模型已经够用,我们不应该一味的追求更小的训练误差,而把模型变得越来越复杂。
2.没有免费的午餐(NFL):
不存在 "万能算法",算法优劣取决于具体问题。对于基于迭代的最优化算法,不存在某种算法对所有问题(有限的搜索空间内)都有效。
六、总结:机器学习的本质是 "数据驱动的智能"
机器学习不是神秘的 "黑科技",而是一套 "从数据中找规律、用规律解决问题" 的系统化方法。从监督学习的 "有答案学习" 到无监督学习的 "自主探索",从模型训练到评估优化,每个环节都围绕 "让机器更好地理解数据" 展开。掌握核心概念(特征、标签、训练 / 测试集)、理解两大学习类型(监督 / 无监督)、识别常见问题(欠拟合 / 过拟合)是关键。