
概要
在人工智能领域,大语言模型(LLMs)如GPT系列的发展已经彻底改变了自然语言处理的面貌。然而,传统LLMs通常需要巨大的计算资源和存储空间,这限制了它们在资源受限环境(如移动设备或边缘计算)中的应用。为了应对这一挑战,1-bit量化技术应运而生,它通过将模型权重大幅压缩到极低比特数(如1.58比特),显著降低了模型大小和推理成本。微软推出的BitNet正是这一趋势下的重要成果,它是官方推出的1-bit LLMs推理框架,专为高效运行BitNet b1.58等模型而设计。BitNet不仅基于成熟的llama.cpp框架构建,还引入了优化的内核,支持在CPU和GPU上实现快速、无损的推理。其性能表现令人瞩目:在ARM CPU上,速度提升可达1.37倍至5.07倍,能耗降低55.4%至70.0%;在x86 CPU上,速度提升甚至高达2.37倍至6.17倍,能耗减少71.9%至82.2%。更令人振奋的是,BitNet能够在一颗CPU上运行100B参数的模型,生成速度接近人类阅读水平(每秒5-7个token),这为本地化部署LLMs开辟了新的可能性。本文将深入解析BitNet的整体架构、关键技术名词、实现细节,并总结其在实际应用中的价值。类似于OpenAI GPT模型从初代到ChatGPT的演进,BitNet代表了LLMs向高效、轻量化方向发展的关键一步,有望推动AI技术更广泛地普及。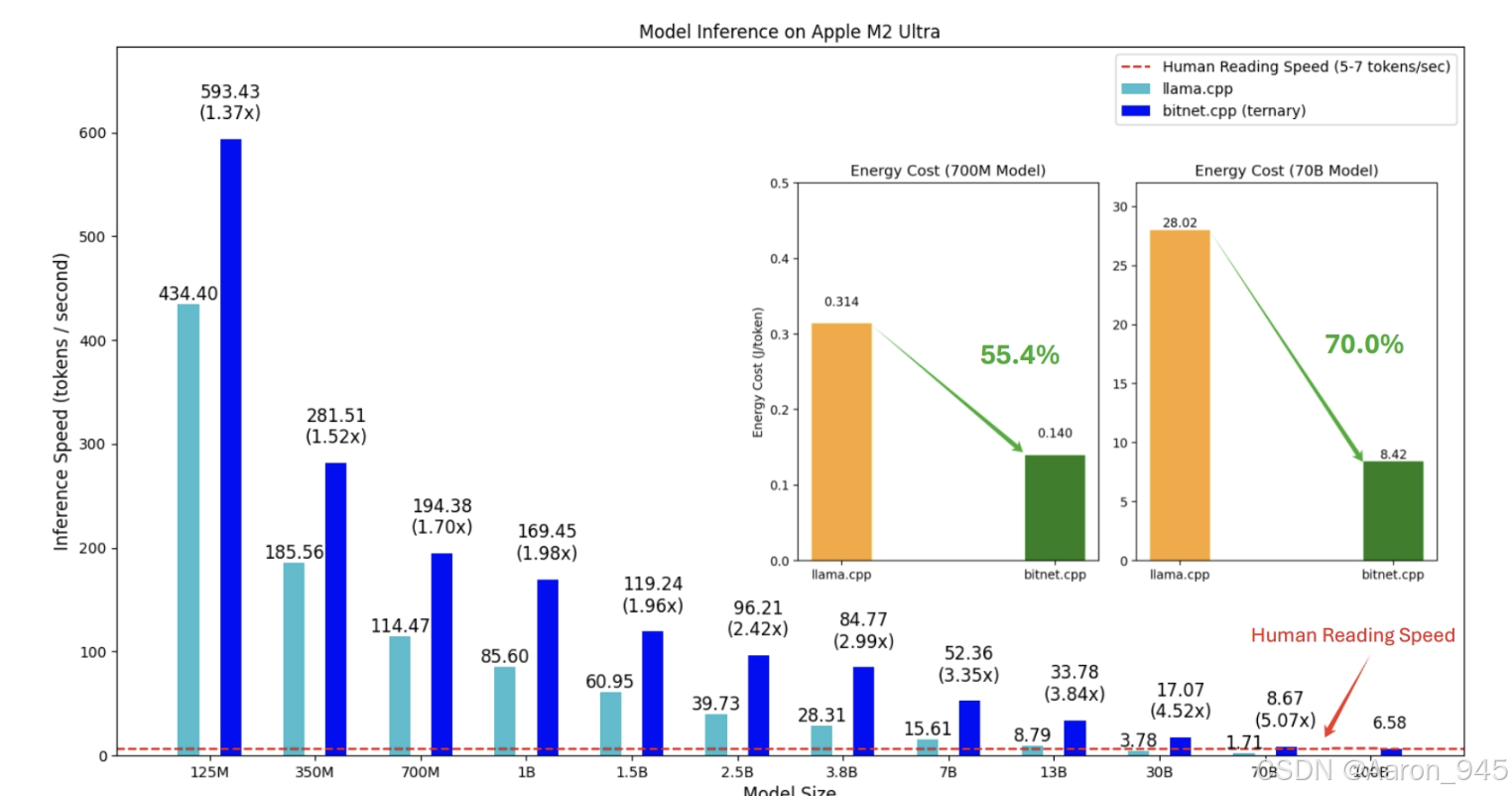
整体架构流程
BitNet的整体架构建立在llama.cpp框架之上,这是一个广泛使用的开源LLM推理引擎,以其高效性和可移植性著称。BitNet通过引入专为1-bit模型优化的内核,扩展了llama.cpp的能力,使其能够无缝支持三元权重(1.58比特)的LLMs。架构流程可以分为几个核心部分:模型加载、内核优化、推理执行和资源管理。
首先,在模型加载阶段,BitNet支持多种模型格式,包括GGUF(一种优化的模型格式)和从Hugging Face下载的.safetensors检查点。用户可以通过提供的工具(如convert-helper-bitnet.py)将.safetensors格式转换为GGUF,以确保兼容性。模型本身基于Transformer架构,但权重被量化为1.58比特(即每个权重仅取-1、0、+1三个值),这大幅减少了内存占用。BitNet的架构允许模型参数从数亿到千亿级别灵活缩放,例如支持的模型包括BitNet-b1.58-2B-4T(24亿参数)到Llama3-8B-1.58-100B-tokens(80亿参数)。
接下来,内核优化是BitNet的核心。框架提供了多种量化内核,如I2_S、TL1和TL2,这些内核针对不同硬件平台(ARM和x86 CPU)进行了高度优化。内核的工作原理基于查找表(Lookup Table)方法,灵感来源于T-MAC项目,它通过预计算常见操作来加速推理。例如,在ARM CPU上,TL1内核利用ARM NEON指令集实现并行处理,而在x86 CPU上,I2_S内核则使用AVX指令集来提升吞吐量。内核选择取决于模型类型和硬件:对于BitNet-b1.58-2B-4T模型,x86平台推荐使用I2_S内核,而ARM平台则支持TL1内核。这种优化确保了推理过程不仅是"无损"的(即保持模型精度),还能实现显著的加速。
在推理执行阶段,BitNet采用标准的自回归生成流程。用户通过run_inference.py脚本输入提示(prompt),框架会先加载模型到内存,然后利用多线程(通过-threads参数控制)进行token生成。推理过程支持可配置的上下文大小(-ctx-size)、生成token数量(-n-predict)和温度参数(-temperature),以平衡生成速度和质量。此外,BitNet还支持对话模式(-cnv选项),允许用户将提示作为系统提示,实现更自然的交互。例如,在Apple M2芯片上运行3B模型时,BitNet可以实现实时响应,演示视频显示其流畅性堪比云端服务。
资源管理方面,BitNet通过动态内存分配和线程池优化,确保在有限资源下高效运行。框架还提供了基准测试工具(e2e_benchmark.py),用于评估不同配置下的性能,帮助用户调优。整体上,BitNet的架构流程体现了"轻量高效"的设计哲学:从模型准备到推理执行,每个环节都经过精心优化,以最小化开销,最大化效率。这与传统LLMs的厚重架构形成鲜明对比,为边缘AI部署树立了新标杆。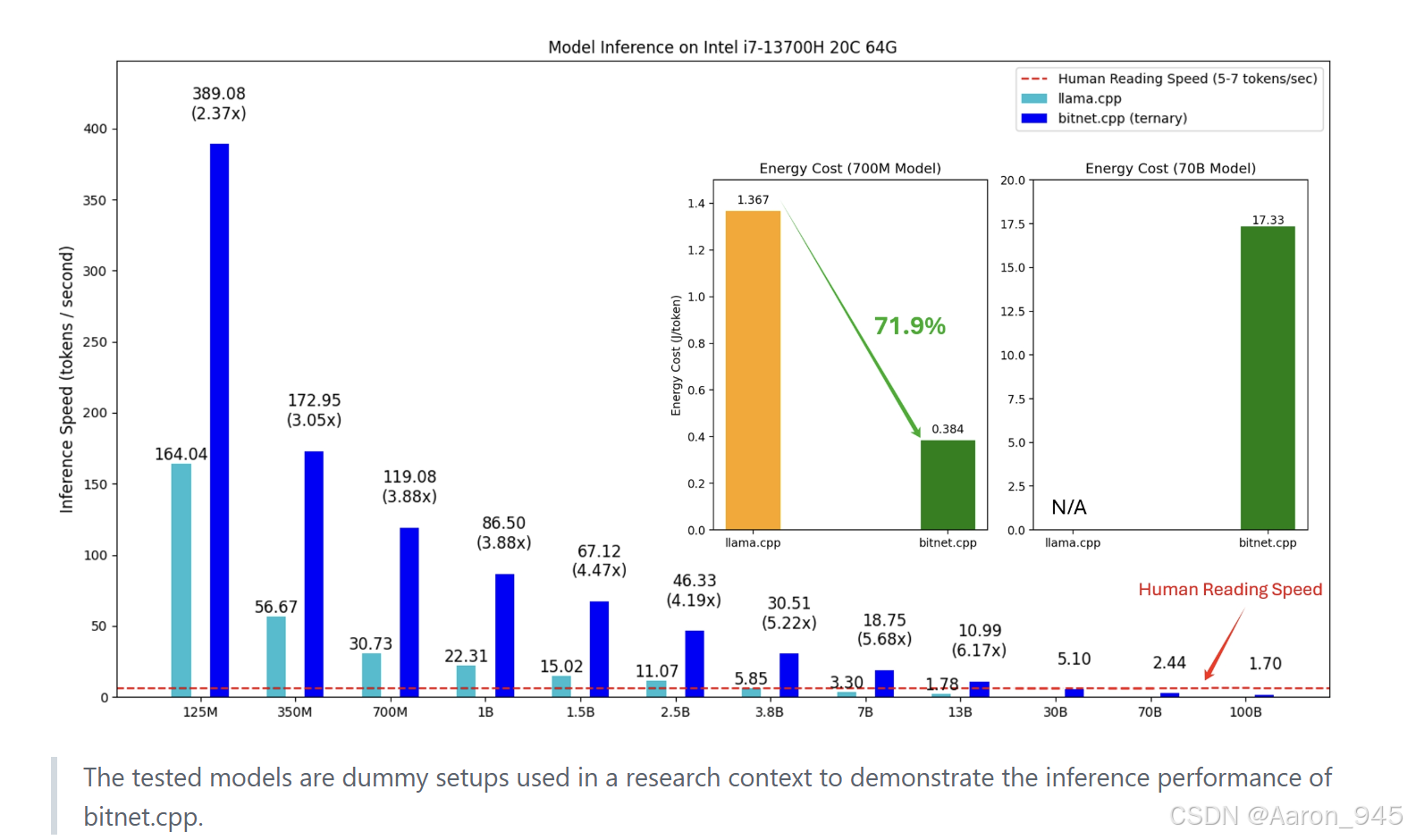
技术名词解释
在深入BitNet的技术细节前,有必要先解释一些关键术语,这些名词是理解框架的基础。
-
1-bit LLMs(1-bit大语言模型):这是一种通过量化技术将模型权重压缩到极低比特数(如1比特或1.58比特)的LLMs。传统LLMs使用32位或16位浮点数表示权重,而1-bit LLMs将权重限制在少数几个值(例如-1、0、+1),从而大幅减少模型大小和计算需求。BitNet专注于1.58比特模型,即三元量化,每个权重仅占约1.58比特,这在保持模型性能的同时,实现了高效的存储和推理。
-
BitNet b1.58:这是微软提出的一种特定1-bit LLM架构,b1.58表示权重被量化为1.58比特(三元)。该模型在训练时采用特殊技巧,如梯度裁剪和量化感知训练,以确保低比特表示不损失准确性。BitNet b1.58是BitNet框架的主要支持对象,其参数规模可从0.7B到100B,适应不同应用场景。
-
量化(Quantization):在机器学习中,量化指将高精度数据(如FP32)转换为低精度格式(如INT8或三元值)的过程。BitNet使用后训练量化或量化感知训练,将模型权重压缩到1.58比特,以减少内存占用和加速推理。量化类型包括I2_S(一种针对x86的优化量化)和TL1/TL2(针对ARM的查找表量化),这些是BitNet内核的核心。
-
llama.cpp:一个开源的高效LLM推理框架,用C++编写,支持多种硬件平台。BitNet基于llama.cpp构建,继承了其跨平台性和优化能力,但添加了专为1-bit模型设计的扩展。llama.cpp本身使用Transformer架构组件,BitNet则在此基础上引入了自定义内核。
-
内核(Kernel):在计算中,内核指底层的优化代码例程,用于执行特定操作(如矩阵乘法)。BitNet提供了多种内核(如I2_S、TL1、TL2),每个内核针对不同硬件和量化类型优化。例如,I2_S内核利用x86的SIMD指令,而TL1内核使用ARM的查找表方法,以提升速度。
-
GGUF格式:一种模型文件格式,专为llama.cpp系列框架设计,支持高效的模型加载和推理。BitNet使用GGUF存储量化后的模型,该格式允许快速读取权重和元数据,减少启动时间。
-
Hugging Face:一个流行的AI模型共享平台,BitNet支持从Hugging Face下载预训练模型(如bitnet_b1_58-large),并通过转换工具将其集成到框架中。
-
Transformer架构:LLMs的基础架构,由编码器和解码器堆叠而成,使用自注意力机制。BitNet支持的模型基于Transformer,但权重被量化,使得架构更轻量。
理解这些名词有助于把握BitNet的创新点:它通过结合1-bit量化、优化内核和成熟框架,实现了LLMs的高效民主化。
技术细节
BitNet的技术细节涵盖了从安装部署到推理优化的方方面面,以下将分模块详细说明。
安装与环境配置
BitNet的安装过程强调跨平台兼容性,但需要满足特定依赖。首先,系统要求包括Python 3.9以上、CMake 3.22以上和Clang 18以上(或Visual Studio 2022 for Windows)。对于Windows用户,必须使用开发者命令提示符或PowerShell,并安装必要的组件(如C++开发工具和LLVM)。安装步骤包括:克隆仓库(使用--recursive选项确保子模块下载)、创建Conda环境、安装Python依赖(通过requirements.txt),然后构建项目。构建命令会编译llama.cpp和BitNet的自定义内核,整个过程可能因硬件而异,但FAQ提供了常见问题的解决方案,例如std::chrono错误可通过特定提交修复。安装完成后,用户需下载模型,BitNet支持从Hugging Face自动下载或手动准备模型文件,例如通过huggingface-cli下载microsoft/BitNet-b1.58-2B-4T到本地目录。
模型支持与量化类型
BitNet支持多种1-bit LLMs,包括官方模型和社区变体。核心模型如bitnet_b1_58-large(0.7B参数)、bitnet_b1_58-3B(3.3B参数)以及Llama3和Falcon系列的1-bit版本。每个模型对应不同的量化内核:在x86 CPU上,I2_S内核适用于大多数模型,而ARM CPU上则优先使用TL1或TL2内核。量化类型通过setup_env.py脚本选择,用户可指定--quant-type参数(i2_s或tl1),并可选择是否量化嵌入层(--quant-embd)。例如,运行BitNet-b1.58-2B-4T模型时,x86平台使用i2_s量化,ARM平台使用tl1量化,这确保了硬件特定优化。框架还支持生成虚拟模型(通过generate-dummy-bitnet-model.py),用于测试自定义架构,增强了灵活性。
推理API与使用方法
BitNet的推理入口是run_inference.py脚本,它提供了一系列API式参数来控制推理过程。关键参数包括:-m指定模型路径、-p输入提示、-n-predict控制生成token数、-threads设置线程数、-ctx-size定义上下文窗口、-temperature调整随机性,以及-cnv启用对话模式。例如,命令python run_inference.py -m models/BitNet-b1.58-2B-4T/ggml-model-i2_s.gguf -p "你好,世界!" -t 4 -cnv会使用4线程运行对话式推理。框架还支持服务器模式(run_inference_server.py),基于llama.cpp内置服务器,允许远程API调用,这便于集成到Web服务中。基准测试工具e2e_benchmark.py可用于性能评估,用户可指定token数和提示长度,输出包括吞吐量和延迟指标,帮助优化部署。
性能优化与内核细节
BitNet的性能优势源于其高度优化的内核。在CPU上,内核利用硬件特定指令:x86平台使用AVX/AVX2进行向量化计算,而ARM平台依赖NEON指令。内核实现基于查找表方法,将常见的1.58比特操作预计算为查找表,减少运行时计算开销。例如,TL1内核在ARM上通过查找表加速矩阵乘法,比浮点运算快数倍。能耗优化通过减少内存访问和并行化实现,BitNet在基准测试中显示,对于大模型(如100B参数),单CPU推理速度可达5-7 token/秒,接近实时。此外,框架支持多线程,用户可通过-threads参数平衡性能与资源使用,在高端CPU上,线程数增加可线性提升吞吐量。
故障排除与FAQ
BitNet的FAQ模块解决了常见问题,例如构建错误:如果出现std::chrono问题,需参考特定提交修改代码;在Windows上,Clang环境初始化需运行VsDevCmd.bat或PowerShell命令。这些细节确保了框架的稳定性,用户可通过日志目录(--log-dir)监控运行状态。
总之,BitNet的技术细节体现了"开箱即用"的理念:从安装到推理,每个环节都提供工具和选项,使1-bit LLMs的部署变得简单高效。与传统框架相比,BitNet的优化内核和轻量设计,使其在资源受限环境中更具竞争力。
小结
BitNet作为1-bit LLMs的官方推理框架,标志着大语言模型向高效化、普及化迈出了重要一步。通过本文的解析,我们可以看到,BitNet不仅在架构上基于成熟的llama.cpp,还通过自定义内核实现了显著的性能提升:在ARM和x86 CPU上,速度提升最高达6倍以上,能耗降低超过80%,这使其特别适合边缘计算、移动设备和低成本部署场景。技术层面,BitNet的创新体现在1.58比特量化、硬件优化内核以及易用的工具链上,支持从模型转换到基准测试的全流程。
与OpenAI GPT系列的发展历程类似,BitNet代表了LLMs演进的一个新方向------从追求规模转向注重效率。未来,随着1-bit技术的成熟,我们可以期待更大规模的模型和更广泛的应用,例如在物联网、实时翻译和个性化AI助手等领域。然而,BitNet目前仍处于早期阶段,模型生态和社区支持有待扩展,例如更多预训练模型和跨平台优化(如NPU支持)将是下一步重点。
对于开发者和研究者,BitNet提供了一个低门槛的入口,来探索高效AI的潜力。建议用户从官方模型入手,利用基准测试工具优化配置,并关注社区更新。总之,BitNet不仅是一个技术工具,更是推动AI民主化的催化剂,它证明了在有限资源下,LLMs依然可以发挥强大能力。随着开源生态的壮大,BitNet有望成为轻量级AI部署的标准框架,引领下一波AI创新浪潮。