本文较长,建议点赞收藏。更多AI大模型开发学习视频籽料, 都在这>>Github<<
随着AI技术的爆发式发展,大语言模型已经从实验室走向千家万户。然而,面对GPT-5、Claude 4、Gemini 2.5等数十个模型,许多用户陷入了选择困境。
本文基于2025年8月的最新研究报告,旨在帮助读者建立对主流AI模型的全景认知,并根据实际需求做出最优选择,让AI真正成为提升效率的利器而非负担。

一、从ChatGPT独角兽到AI模型群雄争霸
还记得2022年底ChatGPT横空出世时的震撼吗?那时候,提到AI对话,几乎所有人想到的都是ChatGPT。然而仅仅两年多时间,AI大模型领域已经发生了翻天覆地的变化。

如今的2025年8月,当我们谈论AI大模型时,选择已经多到让人眼花缭乱:
- 国际巨头阵营:OpenAI的GPT-5、Anthropic的Claude 4、Google的Gemini 2.5、xAI的Grok 4
- 中国力量崛起:阿里的通义千问Qwen 3、字节的豆包Doubao、Moonshot的Kimi K2、DeepSeek R1
- 开源先锋队伍:Meta的Llama 4、智谱的GLM-4.5、腾讯的混元Hunyuan、MiniMax M1
每个模型都有其独特的"性格"和专长,就像不同的专业人士:有的是全能型学霸(GPT-5),有的是编程高手(Claude 4),有的是多媒体达人(Gemini 2.5),还有的是长篇大论专家(Llama 4 Scout)。
那么问题来了:面对如此多的选择,我们该如何找到最适合自己的AI助手?
二、认识12大AI模型家族:各有千秋的智能助手
让我们深入了解每个模型家族的特点,就像认识不同性格的朋友一样。
1. OpenAI GPT系列:综合实力的王者
最新旗舰:GPT-5
想象一下,如果AI模型是学生,GPT-5就是那个门门功课都优秀的学霸。它拥有惊人的1.5万亿参数,支持400K词元的上下文窗口(相当于能记住一本300页的书)。

GPT-5的核心优势:
- 超强推理能力:在AIME数学基准测试中得分94.6%,几乎达到数学竞赛选手水平
- 多模态全能:不仅能处理文字,还能理解图片、音频甚至视频内容
- 速度翻倍:比前代GPT-4o快2倍,让对话更加流畅
- 幻觉大幅减少:错误率降低45-80%,在健康查询中的幻觉率仅为1.6%
真实使用体验: 小王是一名产品经理,他用GPT-5来分析用户反馈数据、生成产品需求文档,甚至让它根据UI草图生成详细的功能说明。"GPT-5就像一个永远不会疲倦的高级顾问,"他说,"虽然每百万词元要75美元(输入),但考虑到节省的时间和提升的质量,完全值得。"
适用场景组合:
- 企业级应用:GPT-5 + 公司知识库 = 智能客服系统
- 创意工作流:GPT-5 + 设计软件 = 自动化创意生成
- 教育场景:GPT-5 + 个性化学习系统 = AI家教
成本考量:
- Pro模式:输入 75/百万词元,输出150/百万词元
- Mini版本:约$0.38/百万词元(适合预算有限的用户)
2. Anthropic Claude系列:程序员的最佳拍档
最新版本:Claude 4.1 Opus、Claude 4 Opus
如果说GPT-5是全能学霸,Claude 4就是那个特别擅长理科的尖子生,尤其在编程方面表现卓越。
Claude 4的独特魅力:
- 编程领导者:在代理编码评估中得分64%,处理复杂代码库时表现最佳
- 深度思考模式:具备"DeepThink"功能,能进行长链条的逻辑推理
- 超长记忆:支持100万词元上下文,相当于能同时阅读10本技术手册
- 安全可靠:内置严格的安全策略,几乎不会产生有害内容
开发者故事: 李明是一位全栈工程师,他这样评价Claude 4:"它不仅能写代码,更重要的是能理解整个项目的架构。我曾经让它分析一个包含500多个文件的代码库,它准确地找出了潜在的性能瓶颈和安全隐患。"
最佳实践组合:
- 代码审查流程:Claude 4 + Git = 自动化代码质量检查
- 技术文档生成:Claude 4 + 代码库 = 智能文档助手
- 算法优化:Claude 4 + 性能分析工具 = 代码优化顾问
3. Google Gemini系列:多模态处理的先锋
旗舰型号:Gemini 2.5 Pro
Gemini就像一个感官特别发达的天才,它最大的特点是原生支持100万词元的超长上下文,并且在处理图像、音频、视频方面有着无与伦比的能力。
Gemini 2.5 Pro的超能力:
- 百万级上下文:业界领先,可以一次性处理整个图书馆的内容
- 原生多模态:不是简单地"看"图片,而是真正理解视频中的情节发展
- 实时搜索集成:接入Google搜索,永远掌握最新信息
- Flash版本超值:仅需$0.15/百万词元,性价比极高
多媒体创作者的福音: 视频博主小李分享道:"我用Gemini 2.5 Pro分析我的视频内容,它不仅能生成精准的字幕,还能识别情绪变化、提取关键画面,甚至给出剪辑建议。配合Flash版本的低成本,我的内容生产效率提升了300%。"
4. xAI Grok系列:实时信息的掌控者
最新版本:Grok 4
Grok就像一个永远在线的新闻记者,它最大的特色是与X平台(原Twitter)深度集成,能够实时获取和分析网络信息。
Grok 4的独特优势:
- 实时搜索能力:原生集成网络搜索,信息永远是最新的
- 工具调用精准:准确率高达99%,能够主动调用各种外部工具
- 性价比超高:输入成本仅$3/百万词元,在同级别模型中极具竞争力
- 个性鲜明:回答带有独特的幽默感,让对话更有趣味
5. 阿里通义千问Qwen系列:开源世界的领军者
旗舰版本:Qwen 3
通义千问是中国开源AI的骄傲,其Qwen3-235B模型采用先进的MoE(专家混合)架构,总参数达2350亿,但激活参数仅220亿,实现了性能与效率的完美平衡。
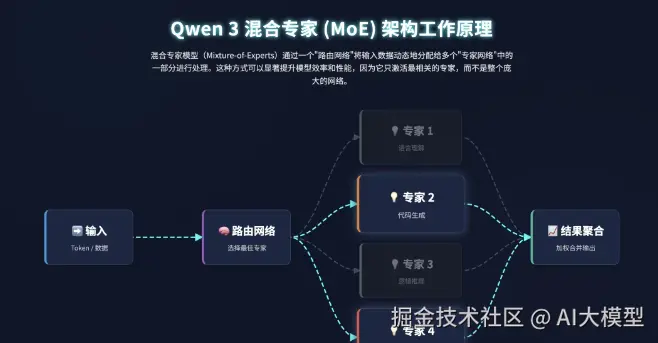
Qwen 3的核心竞争力:
- 完全开源:代码、权重全部开放,支持商用
- 多语言支持:精通119种语言,中文能力尤其出色
- 效率极高:MoE架构让它在保持高性能的同时大幅降低计算成本
- 成本极低:API调用仅需约$0.60/百万词元
企业应用案例: 某金融科技公司的CTO分享:"我们基于Qwen 3搭建了内部的智能分析系统。由于它是开源的,我们可以完全掌控数据安全,同时根据业务需求进行定制化训练。相比使用闭源模型,我们的成本降低了90%以上。"
6. 字节跳动豆包Doubao系列:极致性价比的代表
最新版本:Doubao-1.5-Pro
豆包就像一个精打细算但能力超强的助手,它以极低的成本提供接近顶级模型的性能,在中国市场拥有1.1亿月活用户。
豆包的惊人性价比:
- 成本仅为竞品的1/50:API价格低至$0.8/百万词元
- 速度快2倍:比同级别模型响应更快
- 深度思考模式:在AIME基准测试中甚至超越了o1
- 多模态原生支持:包括实时语音、视频通话等功能
7. Moonshot Kimi系列:长文本处理的革命者
里程碑产品:Kimi K2
Kimi K2创造了历史------全球首个开源的万亿参数模型,更令人震惊的是它支持400万词元的上下文窗口,相当于能一次性阅读40本书!
Kimi K2的革命性特征:
- 万亿参数开源:打破了超大模型只能闭源的格局
- 400万词元上下文:可以处理整个代码库或法律文书
- 智能代理能力:特别适合构建复杂的自动化系统
学术研究者的评价: 某大学AI实验室的教授说:"Kimi K2的开源对学术界意义重大。我们终于可以深入研究万亿级参数模型的内部机制,这将大大推动AI基础研究的发展。"
8. DeepSeek系列:数学和编程的专家
明星产品:DeepSeek R1
DeepSeek就像一个专注于理科的学霸,在数学推理和算法编程方面表现尤为出色。
DeepSeek R1的专业实力:
- 推理能力顶尖:数学和编码任务上接近GPT-4 Turbo水平
- 完全开源免费:包括训练代码和模型权重
- 链式思维推理:擅长一步步解决复杂问题
- API成本极低:仅$0.40/百万词元
9. 智谱GLM系列:智能代理的构建专家
最新版本:GLM-4.5
GLM就像一个超级项目经理,特别擅长协调各种工具和资源来完成复杂任务。
GLM-4.5的独特能力:
- 工具调用成功率90.6%:在自动化任务执行方面表现卓越
- 视觉推理领先:GLM-4.5V版本在GUI理解上超越人类水平
- 完全商业友好:Apache 2.0许可,无使用限制
- 3550亿参数:规模庞大但运行高效
10. 腾讯混元Hunyuan系列:效率与创造的平衡
代表产品:Hunyuan T1
混元采用创新的Mamba-MoE架构,在保持高质量输出的同时实现了极高的推理效率。
混元的特色功能:
- 推理速度翻倍:同等硬件下吞吐量是传统模型的2倍
- 3D生成能力:Hunyuan3D-2可以生成高质量3D模型
- 视频生成集成:HunyuanVideo支持AI视频创作
- 开源且低成本:约$0.8/百万词元
11. Meta Llama系列:开源社区的基石
巅峰之作:Llama 4 Scout
Llama就像开源世界的灯塔,其Scout版本支持惊人的1000万词元上下文------这相当于能记住一个小型图书馆的所有内容!
Llama 4 Scout的突破性特征:
- 史诗级长上下文:1000万词元,创造了新的世界纪录
- 高度优化:单张H100 GPU即可高效运行
- 庞大社区支持:数百万开发者共同贡献
- 边缘部署友好:量化后可在消费级设备运行
12. MiniMax系列:长文本推理的黑马
创新产品:MiniMax M1
MiniMax专注于解决一个核心问题:如何高效处理超长文本。其M1模型实现了400万词元上下文,处理成本仅为GPT-4的1/200。
MiniMax M1的技术突破:
- 4560亿参数:采用高效的MoE架构
- 成本革命:长文本处理成本降低99%
- 计算效率翻倍:独特的注意力机制大幅减少计算量
三、场景化选择指南:找到你的最佳AI搭档
了解了各个模型的特点后,让我们回到最实际的问题:在不同场景下,我该选择哪个模型?
场景1:日常办公与文档处理
需求特征:邮件撰写、报告生成、会议纪要、PPT制作
推荐组合:
- 预算充足:GPT-5 + Microsoft Office = 智能办公全家桶
- 性价比优先:豆包Doubao-1.5-Pro,成本仅为GPT-5的1/50
- 数据安全要求高:通义千问Qwen 3(可私有化部署)
真实案例: 某咨询公司使用GPT-5配合自定义模板,将报告撰写效率提升了70%。"以前写一份行业分析报告需要3天,现在1天就能完成初稿,"项目经理王女士说。
场景2:软件开发与代码编写
需求特征:代码生成、Bug修复、代码审查、架构设计
最优选择矩阵:
| 开发阶段 | 推荐模型 | 组合方案 | 预期效果 |
|---|---|---|---|
| 架构设计 | Claude 4 Opus | Claude 4 + DrawIO | 自动生成系统架构图 |
| 代码编写 | Grok 4 / DeepSeek R1 | 模型 + VS Code | 实时代码补全与优化 |
| 代码审查 | Claude 4 | Claude 4 + GitLab | 自动化代码质量检查 |
| 性能优化 | DeepSeek R1 | DeepSeek + 性能分析工具 | 算法优化建议 |
开发者体验分享: "我们团队现在的工作流程是:用Claude 4做架构设计和代码审查,用DeepSeek R1解决算法问题,日常编码则用Grok 4。这样的组合让我们的开发效率提升了一倍多。" ------某科技公司技术总监
场景3:内容创作与营销
需求特征:文案撰写、视频脚本、社交媒体内容、SEO优化
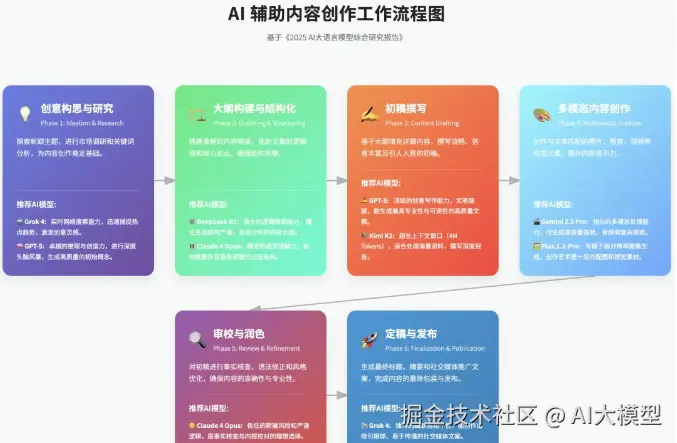
智能创作工作流:
-
- 创意阶段:GPT-5生成创意方向
-
- 内容制作:
- 文字内容:Claude 4(逻辑严谨)
- 视频脚本:Gemini 2.5 Pro(多模态理解)
- 中文内容:豆包Doubao(本土化表达)
-
- 内容优化:Grok 4(实时热点结合)
场景4:学术研究与数据分析
需求特征:文献综述、数据处理、论文撰写、统计分析
研究利器组合:
- 文献处理:Llama 4 Scout(1000万词元上下文)+ 学术数据库
- 数据分析:DeepSeek R1 + Python = 自动化数据处理
- 论文撰写:Claude 4(逻辑严谨)+ 学术写作规范
- 多语言研究:通义千问Qwen 3(支持119种语言)
研究员反馈: "Llama 4 Scout改变了我的研究方式。我可以一次性输入数百篇论文,让它帮我找出研究趋势和知识空白。这在以前是不可想象的。" ------某高校博士生
场景5:企业级应用部署
需求特征:数据安全、成本控制、定制化需求、规模化部署
企业解决方案对比:
| 需求类型 | 方案选择 | 核心优势 | 部署建议 |
|---|---|---|---|
| 完全自主可控 | Qwen 3 / GLM-4.5 | 开源、可私有化部署 | 本地服务器集群 |
| 成本极度敏感 | MiniMax M1 / 豆包 | 价格低至$0.4-0.8/M | API调用 |
| 性能要求极高 | GPT-5 / Claude 4 | 顶级性能 | 混合云部署 |
| 长文档处理 | Kimi K2 / Llama 4 | 超长上下文 | 专用GPU集群 |
场景6:个人学习与技能提升
需求特征:语言学习、编程学习、知识问答、个人助理
个性化学习方案:
- 入门级用户:GPT-4o-Mini(便宜且功能全面)
- 进阶学习者:
- 编程学习:DeepSeek R1(擅长解释算法)
- 语言学习:Gemini 2.5 Flash(多语言+低成本)
- 综合提升:GPT-5 Mini(平衡性能与价格)
四、成本效益深度分析:让每一分钱都物有所值
选择AI模型不仅要看性能,成本也是关键考量因素。让我们详细分析各模型的成本结构:
成本等级划分
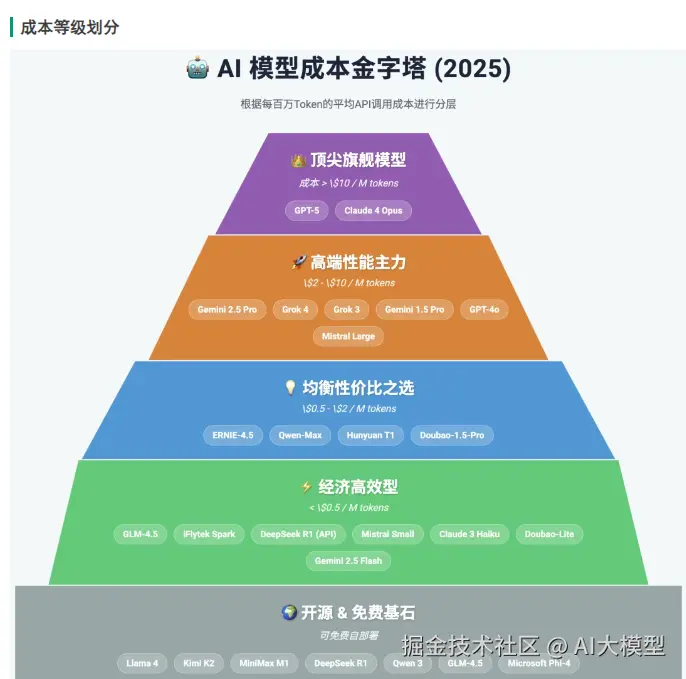
奢侈级(>$50/百万词元):
- GPT-5 Pro: 75/150(输入/输出)
- Claude 4 Opus: 15/75
高端级($10-50/百万词元):
- Gemini 2.5 Pro:平均$6.25
- GPT-4o: 2.5/10
经济级($1-10/百万词元):
- Grok 4:$3(输入)
- 豆包Doubao:$0.8
超值级(<$1/百万词元):
- 通义千问Qwen 3:$0.60
- DeepSeek R1:$0.40
- Gemini 2.5 Flash:$0.15
免费开源:
- Llama 4、Kimi K2、GLM-4.5、MiniMax M1(自行部署)
成本优化策略
-
- 混合使用策略:
- 复杂任务用高端模型
- 日常任务用经济模型
- 批量处理用开源模型
-
- Token优化技巧:
- 使用系统提示词模板减少重复输入
- 采用流式输出避免无效生成
- 利用缓存机制减少重复计算
-
- 场景化成本计算示例: 假设每月处理100万词元的内容:
- 全部使用GPT-5:$75(奢侈但顶级体验)
- 智能分配方案:
- 20%复杂任务用GPT-5:$15
- 50%常规任务用豆包:$0.4
- 30%简单任务用开源:$0
- 总成本:$15.4(节省79%)
五、技术趋势洞察
基于2025年8月的最新发展,我们可以清晰地看到几个重要趋势:
1. 上下文窗口的指数级增长
从最初的4K到如今的1000万词元,上下文窗口的增长速度超出了所有人的想象:
- 2023年:32K是顶级配置
- 2024年:100K成为标配
- 2025年:百万级普及,千万级出现
影响:这意味着AI可以处理整个项目代码库、完整的法律案卷,甚至是个人的终身记忆。
2. 混合推理成为标准
几乎所有顶级模型都采用了"快速+深度思考"的双模式设计:
- 快速模式:毫秒级响应,适合日常对话
- 深度模式:数秒到数分钟,解决复杂问题
这种设计让AI既能进行流畅对话,又能处理需要深度推理的任务。
3. 开源力量的崛起
2025年见证了开源模型的爆发:
- Kimi K2:首个开源万亿参数模型
- Qwen 3:性能媲美闭源顶级模型
- Llama 4:千万级上下文的开源先驱
意义:这打破了AI巨头的垄断,让中小企业和个人开发者也能使用顶级AI技术。
4. 多模态原生化
新一代模型不再是"文本为主,其他为辅",而是真正的多模态原生:
- Gemini 2.5:可以理解整部电影
- GPT-5:实时处理音视频流
- GLM-4.5V:GUI操作理解超越人类
5. 成本的断崖式下降
AI使用成本正在快速下降:
- 2023年:GPT-4约$30/百万词元
- 2025年:同等性能模型低至$0.4/百万词元
- 降幅超过98%!
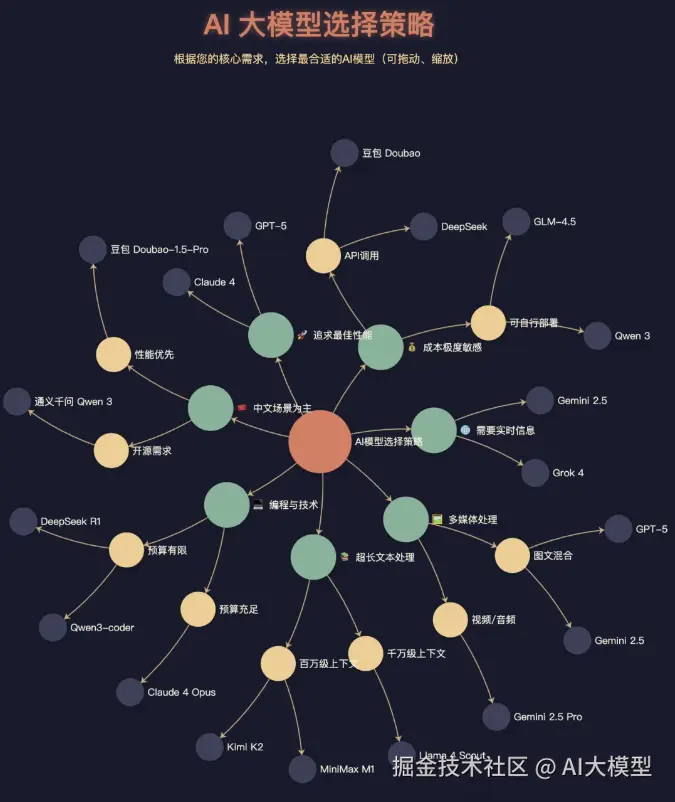
六、实用选择决策树
为了帮助你快速做出选择,我们设计了这个决策树:
markdown
你的主要需求是什么?
│
├─ 追求最佳性能,预算充足
│ └─ GPT-5 或 Claude 4
│
├─ 需要编程和技术支持
│ ├─ 预算充足 → Claude 4 Opus
│ └─ 预算有限 → DeepSeek R1 或 Qwen3-coder
│
├─ 处理多媒体内容
│ ├─ 视频/音频为主 → Gemini 2.5 Pro
│ └─ 图文混合 → GPT-5 或 Gemini 2.5
│
├─ 需要超长文本处理
│ ├─ 千万级别 → Llama 4 Scout
│ ├─ 百万级别 → Kimi K2 或 MiniMax M1
│ └─ 十万级别 → 大部分模型都支持
│
├─ 成本极度敏感
│ ├─ 可以自行部署 → Qwen 3 或 GLM-4.5
│ └─ 只能用API → 豆包Doubao 或 DeepSeek
│
├─ 需要实时信息
│ └─ Grok 4(集成搜索)或 Gemini 2.5(Google搜索)
│
└─ 中文场景为主
├─ 性能优先 → 豆包Doubao-1.5-Pro
└─ 开源需求 → 通义千问Qwen 3七、不同预算下的最优配置方案
月预算$0(纯开源方案)
推荐配置:
- 主力模型:Qwen 3(通用任务)
- 编程辅助:DeepSeek R1
- 长文本处理:Llama 4(如有足够硬件)
硬件要求:至少48GB显存的GPU(如RTX A6000)
实际效果:能满足80%的日常AI需求,性能接近商业模型
月预算$10-50(个人用户)
智能组合方案:
- 日常对话:豆包Doubao($0.8/M)- 预算5美元
- 专业任务:Claude 4 Haiku - 预算20美元
- 编程需求:DeepSeek R1 API - 预算10美元
- 应急高端任务:GPT-5按需付费 - 预算15美元
使用技巧:设置任务优先级,简单任务用便宜模型,复杂任务才动用高端模型
月预算$100-500(专业用户/小团队)
专业配置建议:
- 核心工作:Claude 4 Opus(30%配额)
- 日常任务:Grok 4(40%配额)
- 批量处理:Gemini 2.5 Flash(20%配额)
- 实验创新:GPT-5(10%配额)
ROI分析:按此配置,一个5人团队每月可处理约5000万词元内容,相当于每人每天处理10万字,效率提升300%以上。
月预算$1000+(企业级)
企业级解决方案:
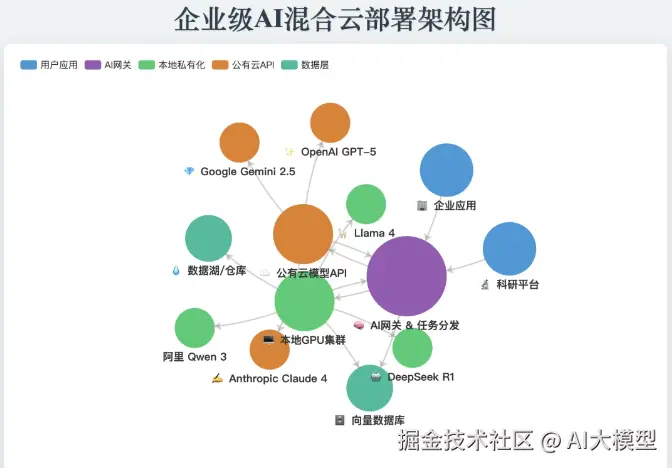
-
- 基础设施:
- 本地部署:Qwen 3 + GLM-4.5(日常任务)
- 云端备份:主流API服务
-
- 任务分配:
- 70%任务:本地开源模型处理(边际成本近零)
- 20%任务:中端API(Grok 4、豆包)
- 10%任务:顶级API(GPT-5、Claude 4)
-
- 专门系统:
- 客服系统:基于GLM-4.5定制
- 代码审查:Claude 4专线
- 数据分析:DeepSeek R1集群
八、避坑指南:那些容易踩的雷
1. 过度依赖单一模型
错误做法:所有任务都用GPT-5 问题:成本爆炸,每月可能花费数千美元 正确做法:建立任务分级机制,合理分配模型使用
2. 忽视隐私和安全
风险场景:
- 将公司机密数据发送给闭源API
- 使用未经安全审计的模型处理敏感信息
防范措施:
- 敏感数据只用本地部署的开源模型
- 建立数据分级制度
- 定期审计AI使用日志
3. 不了解模型局限性
常见误区:
- 以为AI永远正确(实际幻觉率1.6%-10%不等)
- 期望模型具有最新信息(大部分知识截止到2024年)
- 忽视输出长度限制(即使输入可以很长)
4. 选择困难症
症状:花大量时间比较模型,迟迟不开始使用 解药:先选一个适合的开始用,在实践中调整
九、快速上手行动指南
第一周:初步尝试
-
- Day 1-2:注册2-3个主流平台账号
- 国际路线:ChatGPT、Claude、Gemini
- 国内路线:通义千问、文心一言、智谱清言
-
- Day 3-4:进行基础任务测试
- 让不同模型完成同一任务
- 记录响应时间、质量和成本
-
- Day 5-7:确定主力模型
- 根据测试结果选择2-3个常用模型
- 设置快捷访问方式
第一个月:建立工作流
Week 2:深度集成
- 将AI集成到日常工具(VS Code、Office等)
- 创建常用提示词模板库
Week 3:优化使用
- 分析使用数据,优化模型选择
- 尝试更高级的功能(如代码解释、数据分析)
Week 4:效果评估
- 计算ROI(投入产出比)
- 制定下月使用计划
长期发展:构建AI增强能力
-
- 技能升级路径:
- 初级:学会基础对话和问答
- 中级:掌握提示词工程和任务分解
- 高级:构建自动化工作流和智能体
-
- 持续学习资源:
- 关注各大模型的官方博客和更新
- 加入AI社区交流使用经验
- 定期尝试新模型和新功能
十、2025年AI模型选择总结
经过详尽的分析,我们可以得出以下核心结论:
性能之王依然强大
GPT-5和Claude 4 Opus代表着当前AI技术的最高水平。如果你追求极致性能,预算充足,它们依然是首选。特别是在需要复杂推理、创意写作和多模态处理的场景下,它们的优势明显。
开源崛起改变格局
2025年是开源AI模型的爆发年。Qwen 3、Kimi K2、GLM-4.5等模型不仅免费,性能也直追顶级闭源模型。这给了中小企业和个人开发者前所未有的机会。
专业化趋势明显
不同模型正在形成自己的专业特长:
- 编程找Claude和DeepSeek
- 多媒体找Gemini
- 长文本找Llama和Kimi
- 实时信息找Grok
- 中文场景找豆包和通义千问
成本已不再是障碍
从 150到0.15,百倍的价格差距意味着AI已经真正平民化。即使是个人用户,每月花费$10-20也能享受到强大的AI助力。
混合使用是王道
没有一个模型能够完美应对所有场景。聪明的做法是根据任务特点选择最合适的模型,构建自己的"AI工具箱"。
写在最后:拥抱AI增强的未来
站在2025年8月这个时间节点,我们正在见证一个历史性的转变。AI不再是遥不可及的黑科技,而是每个人都能使用的生产力工具。
记住,最好的AI模型不是最贵的,也不是最新的,而是最适合你需求的那个。
今天,你可能还在为选择哪个模型而纠结。但相信很快,使用AI就会像使用搜索引擎一样自然。关键是要开始行动,在实践中找到最适合自己的AI伙伴。
正如开篇引用的弗里德曼所说:"选择的自由,是人类最大的财富。"现在,我们拥有了前所未有的选择自由------选择最适合的AI工具,增强我们的能力,创造更大的价值。
更多AI大模型开发学习视频籽料,都在这>>Github<<