本篇依然来自于我们的 《前端周刊》 项目!

译者小结
JSON.stringify 提速的核心为以下6点:
- 快速路径:避开一大堆通用检查(节省 CPU 时间)
- 专用版本:按字符串类型分开编译(减少分支判断)
- 批量扫描:一次看多字符(降低循环次数)
- 缓存形状:重复对象直接批量处理(跳过重复工作)
- 更快算法:数字转字符串的计算加速(核心耗时优化)
- 分段缓冲:内存分配更聪明(避免大搬家)
原文
JSON.stringify 是 JavaScript 中用于序列化数据的核心函数。它的性能直接影响着 Web 上的常见操作------从为网络请求序列化数据,到将数据保存到 localStorage。更快的 JSON.stringify 意味着页面交互更迅速、应用响应更灵敏。这就是为什么我们很高兴地分享:最近的一次工程改进,使得 V8 中的 JSON.stringify 性能提升了两倍以上。本文将拆解实现这一提升的技术优化。
无副作用的快速路径
此次优化的基础是一条新的快速路径,建立在一个简单的前提上:如果我们能够保证序列化对象时不会触发任何副作用,就可以使用更快的专用实现。这里的"副作用"指的是任何会打破对象简单、顺序遍历的情况。
这不仅包括明显的情况,比如在序列化过程中执行用户定义的代码,还包括一些更隐蔽的内部操作,比如可能触发垃圾回收的过程。有关哪些情况会导致副作用,以及如何避免它们的更多细节,请参见 Limitations。
只要 V8 能确定序列化过程不会出现这些情况,就可以一直停留在高度优化的路径上。这使它能够绕过通用序列化器中许多昂贵的检查和防御逻辑,从而在处理最常见的、代表纯数据的 JavaScript 对象时获得显著加速。
此外,这条新快速路径是迭代式的,而不是像通用序列化器那样递归。这一架构选择不仅免去了栈溢出检查,并允许我们在编码改变后快速恢复,还能让开发者序列化比以前更深层嵌套的对象图。
处理不同的字符串表示
在 V8 中,字符串可以用单字节或双字节字符表示。如果一个字符串只包含 ASCII 字符,它会被存储为单字节字符串,每个字符占 1 个字节。但如果字符串中有一个字符超出 ASCII 范围,那么整个字符串都会使用双字节表示,内存占用翻倍。
为了避免统一实现中不断分支和类型检查的开销,整个字符串序列化器现在基于字符类型进行模板化。这意味着我们会编译两个独立的、专门优化的版本:一个完全针对单字节字符串优化,另一个针对双字节字符串优化。这确实会影响二进制大小,但我们认为性能提升绝对值得。
该实现还能高效处理混合编码。在序列化过程中,我们必须检查每个字符串的实例类型,以检测无法在快速路径处理的表示形式(比如 ConsString,它在扁平化时可能触发 GC),这些会回退到慢路径。这个检查同时也能知道字符串是单字节还是双字节编码。
因此,从乐观的单字节序列化器切换到双字节版本几乎是零成本的。当检查发现双字节字符串时,就会新建一个双字节序列化器,并继承当前状态。最后,只需将初始单字节序列化器的输出与双字节版本的输出拼接即可。这种策略确保了在常见情况下保持高度优化的路径,同时转向处理双字节字符的开销很小且高效。
使用 SIMD 优化字符串序列化
在 JavaScript 中,任意字符串在序列化为 JSON 时都可能包含需要转义的字符(例如 " 或 ``)。传统的逐字符循环查找这些字符速度很慢。
为了加速这一过程,我们基于字符串长度采用了两级策略:
- 长字符串:使用专用的硬件 SIMD 指令(例如 ARM64 Neon)。这样可以将字符串的大块内容加载到宽 SIMD 寄存器中,并在几条指令内同时检查多个字节是否存在需要转义的字符。
- 短字符串:使用 SWAR(寄存器内 SIMD)技术。该方法通过在标准通用寄存器上进行巧妙的按位逻辑运算,以极低开销一次处理多个字符。
无论采用哪种方法,流程都很高效:按块快速扫描字符串。如果某个块中没有特殊字符(这是常见情况),就可以直接复制整个字符串。
快速路径上的"快速通道"
即使在主快速路径中,我们也找到了进一步加速的机会。默认情况下,快速路径仍需遍历对象的每个属性,并对每个键执行一系列检查:确认不是 Symbol、确保可枚举、扫描字符串是否包含需要转义的字符(例如 " 或 ``)。
为消除这些步骤,我们在对象的隐藏类上引入了一个标志。一旦我们序列化了对象的所有属性,就会将其隐藏类标记为 fast-json-iterable,前提是属性键都不是 Symbol、全部可枚举、且不包含需要转义的字符。
当我们序列化另一个具有相同隐藏类的对象(这种情况很常见,比如一组形状相同的对象数组)并且它是 fast-json-iterable 时,我们可以直接将所有键复制到字符串缓冲区,而无需进一步检查。
我们还将这种优化应用到了 JSON.parse,当解析数组时,如果数组中的对象通常有相同的隐藏类,就可以用它来进行快速键比较。
更快的数字转字符串算法
将数字转换为字符串是一个出乎意料的复杂且性能关键的任务。在 JSON.stringify 的优化中,我们发现可以显著加速这一过程,于是升级了核心的 DoubleToString 算法。我们用 Dragonbox 替换了长期使用的 Grisu3 算法,用于最短长度的数字转字符串转换。
虽然这一优化是为了 JSON.stringify,但新的 Dragonbox 实现会惠及 V8 中所有 Number.prototype.toString() 的调用。这意味着任何数字转字符串的代码,不仅仅是 JSON 序列化,都会自动获得这一性能提升。
优化底层临时缓冲区
任何字符串构建操作中的一个主要开销是内存管理。之前,我们的序列化器会在 C++ 堆上构建一个单一的连续缓冲区。虽然简单,但这种方式有一个显著缺点:一旦缓冲区空间耗尽,就必须分配更大的缓冲区,并将全部现有内容复制过去。对于大型 JSON 对象,这种反复分配和复制的过程会造成很大的性能损耗。
关键洞察是,强制这个临时缓冲区保持连续并没有真正的好处,因为最终结果只会在最后一步组装成一个字符串。
基于此,我们将旧系统替换为分段缓冲区。不再是一个大的、不断增长的内存块,而是使用 V8 的 Zone 内存分配一组较小的缓冲段。当一个段写满时,我们直接分配一个新的段继续写,完全消除了昂贵的复制操作。
限制
新的快速路径通过专门优化常见、简单的情况来实现速度提升。如果被序列化的数据不满足这些条件,V8 会回退到通用序列化器以确保正确性。要获得全部性能提升,JSON.stringify 调用需要满足以下条件:
- 无 replacer 或 space 参数:提供 replacer 函数或 space/gap 参数(用于美化输出)会使其进入通用路径。快速路径仅支持紧凑的、未转换的序列化。
- 纯数据对象和数组 :被序列化的对象应是简单的数据容器,即它们及其原型不能有自定义的
.toJSON()方法。快速路径假设标准原型(如 Object.prototype、Array.prototype),且无自定义序列化逻辑。 - 对象无索引属性:快速路径针对具有常规字符串键的对象进行优化。如果对象包含类数组的索引属性(如 '0'、'1'...),则会使用较慢的通用序列化器。
- 简单字符串类型:某些内部 V8 字符串表示(如 ConsString)在序列化前需要分配内存进行扁平化。快速路径避免执行可能触发这种分配的操作,最适合处理简单的顺序字符串。作为 Web 开发者,这一点难以直接控制,但大多数情况下都能正常工作。
对于绝大多数使用场景(如为 API 响应序列化数据、缓存配置对象),这些条件都是自然满足的,开发者可以自动享受到性能提升。
结论
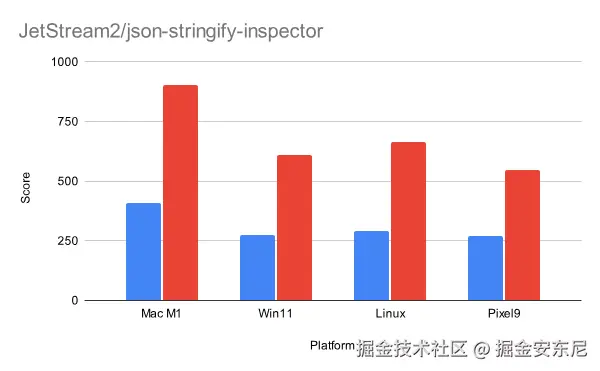
通过从高层逻辑到底层内存与字符处理的全方位重构,我们在 JetStream2 的 json-stringify-inspector 基准测试中实现了超过 2 倍的性能提升。下图展示了在不同平台上的结果。这些优化从 V8 版本 13.8(Chrome 138)开始可用。