在上一篇文章中,介绍了 VectorStore 接口的常用方法,以及 VectorStore 接口的常见实现类,并以 WeaviateVectorStore 为例,演示了如何使用 WeaviateVectorStore 进行向量数据库的存储和检索。本文将继续介绍如何使用检索器组件 Retrievers 进行高效的数据检索。
文中所有示例代码:github.com/wzycoding/l...
一、BaseRetriever接口
BaseRetriever 是检索器相关类的顶层接口。当给定一个查询文本需要进行非结构化查询时,它比 VectorStore 更为通用。检索器本身不需要存储文档,只要能够对文档进行检索并返回检索到的文档即可。检索器可以通过 VectorStore 创建,也可以对诸如维基百科等数据源进行检索。
最重要的是,BaseRetriever 是一个可运行组件,它可以方便地使用 LECL 表达式对检索器组件进行集成。检索器接受一个查询文本作为输入,返回一个 Document 对象列表作为输出。BaseRetriever 的 invoke 方法定义如下:
python
def invoke(
self, input: str, config: Optional[RunnableConfig] = None, **kwargs: Any
) -> List[Document]:二、VectorStoreRetriever使用
在 RAG 应用中,当需要基于向量数据库进行文档检索时,就可以使用VectorStoreRetriever。它封装了向量数据库检索的底层逻辑,能够直接调用 VectorStore 的方法,从向量数据库中检索最相关的文档。
在前面介绍 VectorStore 常用方法时,包括了 as_retriever() 方法,该方法可以构建一个检索器对象,这个检索器就是 VectorStoreRetriever。
在介绍VectorStoreRetriever用法之前,首先将如下测试数据插入到向量数据库中,为避免过多重复代码,具体的插入实现已省略,大家可以到 GitHub 中自行查看。
python
# 准备好要保存的文本数据、元数据
texts = [
"光明科技公司总部位于北京市朝阳区,是一家专注于人工智能与大数据分析的高新技术企业,现有员工500人。",
"董事长张三,男,40岁,籍贯黑龙江漠河市,毕业于清北大学,曾在硅谷工作十年,现负责公司战略规划与重大项目决策。",
"总经理李四,男,38岁,江苏南京人,拥有十五年软件工程经验,主导过多个国家重点科技项目。",
"副总经理王五,男,35岁,四川成都人,负责公司运营管理与市场拓展。",
"技术部拥有120名开发人员,主要从事机器学习模型训练、数据挖掘、云计算平台研发等工作。",
"光明科技公司在2024年获得国家科技进步二等奖,并与多所高校建立产学研合作关系。",
"公司设有技术部、市场部、运营部和人力资源部,其中技术部是公司的核心部门。",
"张三不仅担任董事长,还热衷公益事业,曾多次捐助贫困地区教育项目。",
"总经理李四毕业于上海交通大学计算机系,擅长分布式系统与云架构设计。",
"副总经理王五在加入光明科技公司前,曾任某知名互联网企业运营总监,具有丰富的企业管理经验。"
]
metadatas = [
{"segment_id": "1"},
{"segment_id": "2"},
{"segment_id": "3"},
{"segment_id": "4"},
{"segment_id": "5"},
{"segment_id": "6"},
{"segment_id": "7"},
{"segment_id": "8"},
{"segment_id": "9"},
{"segment_id": "10"},
]使用示例如下,使用as_retriever()方法创建了一个VectorStoreRetriever 对象,之后调用invoke()方法传入query进行文档检索。
python
import dotenv
import weaviate
from langchain_openai import OpenAIEmbeddings
from langchain_weaviate import WeaviateVectorStore
# 读取env配置
dotenv.load_dotenv()
# 1.创建Weaviate客户端
client = weaviate.connect_to_local(
host="localhost",
port=8080,
grpc_port=50051,
)
# 2.创建文本嵌入模型
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
# 3.创建Weaviate向量数据库
vector_store = WeaviateVectorStore(
client=client,
text_key="text_key",
embedding=embeddings,
index_name="Database"
)
# 4.创建检索器,进行数据检索
retriever = vector_store.as_retriever()
documents = retriever.invoke("介绍一下光明科技公司副总经理的情况。")
for document in documents:
print(document.page_content)
print(document.metadata)
print("=================================")执行结果如下:
python
副总经理王五在加入光明科技公司前,曾任某知名互联网企业运营总监,具有丰富的企业管理经验。
{'text': None, 'segment_id': '10'}
=================================
光明科技公司总部位于北京市朝阳区,是一家专注于人工智能与大数据分析的高新技术企业,现有员工500人。
{'text': None, 'segment_id': '1'}
=================================
董事长张三,男,40岁,籍贯黑龙江漠河市,毕业于清北大学,曾在硅谷工作十年,现负责公司战略规划与重大项目决策。
{'text': None, 'segment_id': '2'}
=================================
总经理李四,男,38岁,江苏南京人,拥有十五年软件工程经验,主导过多个国家重点科技项目。
{'text': None, 'segment_id': '3'}
=================================在默认情况下,检索器使用相似性检索方式进行检索。另一种检索方式是最大边际相关性检索(简称 MMR),可以在调用 as_retriever() 方法时通过 search_type="mmr" 指定,但前提是检索器所使用的底层数据库必须支持该检索方式。
python
retriever = vector_store.as_retriever(search_type="mmr")除了 search_type 之外,还可以使用 search_kwargs 将参数传递给 VectorStore 的底层搜索方法,例如传递 k 值,将默认匹配度最高的前三个文档返回(默认 k=4)。
python
retriever = vector_store.as_retriever(search_type="mmr", search_kwargs={"k": 3})三、MultiQueryRetriever使用
在向量检索过程中,查询文本会被转换为向量,并通过计算向量间距离来检索相似文档。然而,检索结果的准确性可能会受到查询文本表达方式的影响。
因此,为了提升查询结果的准确性,可以将查询文本传递给大语言模型,由其生成多个不同表达方式的查询文本变体。随后,使用这些不同的查询文本分别进行文档检索,并将所有检索结果汇总、排序,返回最相关的文档。
MultiQueryRetriever(多查询检索器)正是实现上述 RAG 检索优化逻辑的工具。可以使用 MultiQueryRetriever.from_llm() 方法创建一个多查询检索器。进入 from_llm() 源码可以看到,除了需要传递检索器对象和模型对象之外,还可以传入 prompt 参数,该参数用于调用大模型生成多个查询文本的提示词,并提供了默认值。
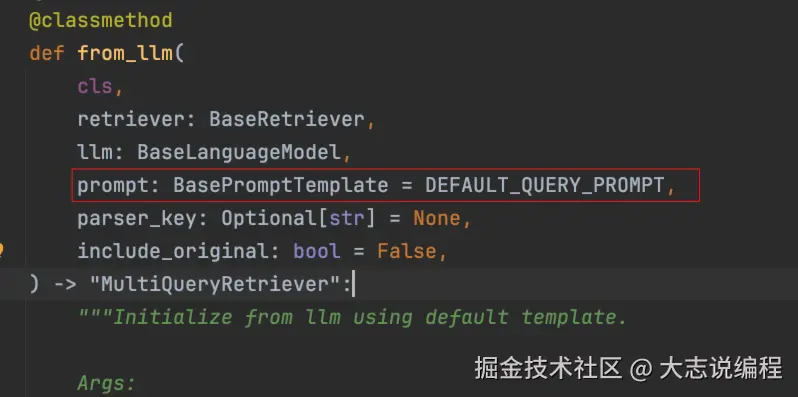
该默认提示词为英文版,在使用时需要进行汉化,否则返回的查询文本将全部为英文,导致检索效果下降。
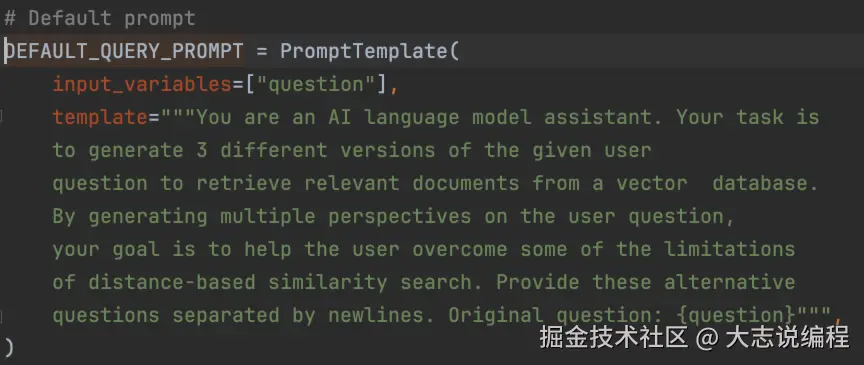
MultiQueryRetriever 使用示例如下,首先进行了日志设置,在调用大语言模型生成多个查询文本时,MultiQueryRetriever 会进行 INFO 级别的日志打印,将生成的文本输出,
在创建 MultiQueryRetriever 时,需要传入 BaseRetriever 对象、模型对象以及汉化后的 prompt,之后同样通过调用invoke()方法传入查询文本进行检索。
python
import logging
import dotenv
import weaviate
from langchain.retrievers import MultiQueryRetriever
from langchain_core.prompts import PromptTemplate
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain_weaviate import WeaviateVectorStore
# 日志设置
logging.basicConfig()
logging.getLogger("langchain.retrievers.multi_query").setLevel(logging.INFO)
# 读取env配置
dotenv.load_dotenv()
# 1.创建Weaviate客户端
client = weaviate.connect_to_local(
host="localhost",
port=8080,
grpc_port=50051,
)
# 2.创建文本嵌入模型
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
# 3.创建Weaviate向量数据库
vector_store = WeaviateVectorStore(
client=client,
text_key="text_key",
embedding=embeddings,
index_name="Database"
)
# 4.创建多查询检索器
retriever = vector_store.as_retriever()
retriever_from_llm = MultiQueryRetriever.from_llm(
retriever=retriever, llm=ChatOpenAI(model="gpt-3.5-turbo"),
prompt=PromptTemplate(
input_variables=["question"],
template="""你是一个 AI 语言模型助手。你的任务是:
为给定的用户问题生成 3 个不同的版本,以便从向量数据库中检索相关文档。
通过生成用户问题的多种视角(改写版本),
你的目标是帮助用户克服基于距离的相似性搜索的某些局限性。
请将这些改写后的问题用换行符分隔开。原始问题:{question}""")
)
# 5.进行数据检索
documents = retriever_from_llm.invoke("介绍一下董事长信息")
for document in documents:
print(document.page_content)
print(document.metadata)
print("=================================")
执行结果如下。通过日志可以观察到,LLM 生成了三个查询文本,并且最终检索结果中排在前面的前两条文档与查询文本的信息最为相关。
python
INFO:langchain.retrievers.multi_query:Generated queries: ['1. 请简要介绍一下董事长的背景和信息。', '2. 能否提供有关董事长的相关资料和详细介绍?', '3. 董事长的基本情况是什么?能给我更多的说明吗?']
董事长张三,男,40岁,籍贯黑龙江漠河市,毕业于清北大学,曾在硅谷工作十年,现负责公司战略规划与重大项目决策。
{'segment_id': '2', 'text': None}
=================================
张三不仅担任董事长,还热衷公益事业,曾多次捐助贫困地区教育项目。
{'segment_id': '8', 'text': None}
=================================
总经理李四,男,38岁,江苏南京人,拥有十五年软件工程经验,主导过多个国家重点科技项目。
{'segment_id': '3', 'text': None}
=================================
光明科技公司总部位于北京市朝阳区,是一家专注于人工智能与大数据分析的高新技术企业,现有员工500人。
{'segment_id': '1', 'text': None}
=================================
副总经理王五,男,35岁,四川成都人,负责公司运营管理与市场拓展。
{'segment_id': '4', 'text': None}
=================================四、自定义检索器实现
在前面已经介绍过 BaseRetriever 接口,我们可以通过继承 BaseRetriever 来实现自定义检索器。查看 BaseRetriever 的 invoke 方法(省略部分代码)可以发现,最终真正执行检索的核心方法是 _get_relevant_documents。
python
def invoke(
self, input: str, config: Optional[RunnableConfig] = None, **kwargs: Any
) -> List[Document]:
......
try:
_kwargs = kwargs if self._expects_other_args else {}
if self._new_arg_supported:
result = self._get_relevant_documents(
input, run_manager=run_manager, **_kwargs
)
else:
result = self._get_relevant_documents(input, **_kwargs)
except Exception as e:
run_manager.on_retriever_error(e)
raise e
else:
run_manager.on_retriever_end(
result,
)
return result并且 _get_relevant_documents 是一个抽象方法,需要由子类去实现。
python
@abstractmethod
def _get_relevant_documents(
self, query: str, *, run_manager: CallbackManagerForRetrieverRun
) -> List[Document]:因此,实现一个自定义检索器需要继承 BaseRetriever 并实现 _get_relevant_documents 方法。
假设有如下需求:需要一个自定义检索器,将传入的查询文本按空格拆分成关键词数组,并在文档中进行匹配。只要有任意一个关键词匹配成功,即返回该文档信息,同时支持通过传递参数控制检索器返回的文档数量。
具体实现该需求的代码示例如下:
python
from typing import List
from langchain_core.callbacks import CallbackManagerForRetrieverRun
from langchain_core.documents import Document
from langchain_core.retrievers import BaseRetriever
class KeywordsRetriever(BaseRetriever):
"""自定义检索器"""
documents: List[Document]
k: int
def _get_relevant_documents(self, query: str, *, run_manager: CallbackManagerForRetrieverRun) -> List[Document]:
# 1.去除kwargs中的k参数
k = self.k if self.k is not None else 3
documents_result = []
# 2.按照空格拆分query,为多个关键词
query_keywords = query.split(" ")
# 3.遍历文档,只要文档中包含其中一个关键词,添加到结果中
for document in self.documents:
if any(query_keyword in document.page_content for query_keyword in query_keywords):
documents_result.append(document)
# 4.返回前k条文档数据
return documents_result[:k]
# 1.定义文档列表
documents = [
Document("光明科技公司总部位于北京市朝阳区,是一家专注于人工智能与大数据分析的高新技术企业,现有员工500人。"),
Document("董事长张三,男,40岁,籍贯黑龙江漠河市,毕业于清北大学,曾在硅谷工作十年,现负责公司战略规划与重大项目决策。"),
Document("总经理李四,男,38岁,江苏南京人,拥有十五年软件工程经验,主导过多个国家重点科技项目。"),
Document("副总经理王五,男,35岁,四川成都人,负责公司运营管理与市场拓展。"),
Document("技术部拥有120名开发人员,主要从事机器学习模型训练、数据挖掘、云计算平台研发等工作。"),
Document("光明科技公司在2024年获得国家科技进步二等奖,并与多所高校建立产学研合作关系。"),
Document("公司设有技术部、市场部、运营部和人力资源部,其中技术部是公司的核心部门。"),
Document("张三不仅担任董事长,还热衷公益事业,曾多次捐助贫困地区教育项目。"),
Document("总经理李四毕业于上海交通大学计算机系,擅长分布式系统与云架构设计。"),
Document("副总经理王五在加入光明科技公司前,曾任某知名互联网企业运营总监,具有丰富的企业管理经验。"),
]
# 2.创建检索器
retriever = KeywordsRetriever(documents=documents, k=1)
# 3.检索得到结果
result = retriever.invoke("张三")
# 4.打印检索结果
for document in result:
print(document.page_content)
print("===========================")执行结果:
python
董事长张三,男,40岁,籍贯黑龙江漠河市,毕业于清北大学,曾在硅谷工作十年,现负责公司战略规划与重大项目决策。
===========================五、总结
本文介绍了 LangChain 的检索器组件 Retrievers 的使用方法,以及检索器组件的顶层接口 BaseRetriever。还介绍了多种不同类型的检索器,例如通过 VectorStoreRetriever 可以快速基于向量数据库进行文档检索,MultiQueryRetriever 则通过生成多个查询变体提升检索准确性。
除此之外,实现自定义检索器需要继承 BaseRetriever,并实现抽象方法,在抽象方法内实现特定的检索逻辑,例如按关键词匹配文档并控制返回数量。
相信通过本文的学习,你已经掌握了 LangChain 检索器的用法,在下一篇文章中,将对 RAG 整个流程进行总结,并编写一个基础的 RAG 应用,敬请期待。