企业级图学习与推理的强大能力
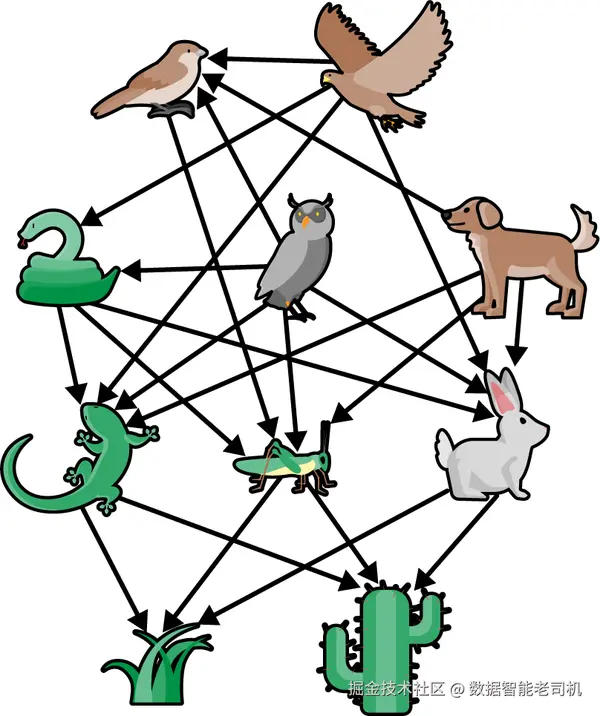
图是表示各种自然现象的基础工具,在生态网络和水文网络中尤为明显。在生态网络中,如图 1-1 所示的食物网,节点代表不同物种,边则表示捕食--被捕食关系或营养级联系。同样,在水文网络中,节点表示水体(如湖泊、溪流和河流),边则描绘它们之间的水流方向。图结构在第一个生态示例中,封装了能量在自然生态系统中的流动方式。
而在第二种场景中,图表示法帮助研究人员理解水分布模式的复杂性。在生物学和神经科学等自然系统中,其内部组织形式也类似于图。在生物学中,图可模拟分子间的相互作用,如蛋白质--蛋白质相互作用网络、代谢通路和基因调控网络。同样,在神经科学中,图用于展示大脑中的神经元连接,有助于揭示脑结构与功能。通过将这些系统以图的形式表示,研究者可以直观地可视化并分析它们,从而推动医学、神经科学和生物技术领域的进步。
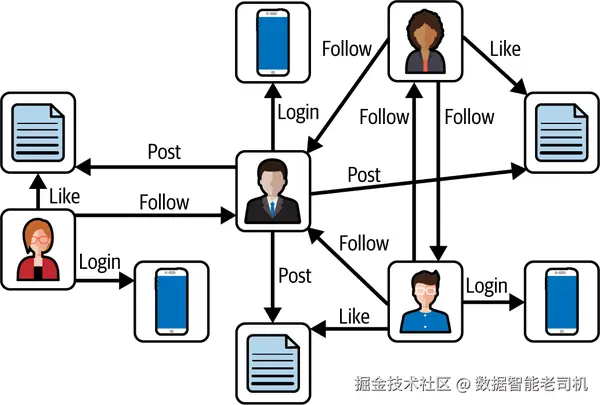
此外,图的强大作用在于它们可在人工设计的技术系统中得到体现,例如图 1-2 所示的社交网络和交通网络。这两种系统均可用图来表示。在社交网络中,个体对应节点,他们之间的好友关系由边来表示,构成了一个覆盖全球数百万用户的巨大图。可针对该网络应用图算法,例如通过推荐新的好友连接(新增边)来为用户提供社交建议。
同样,交通网络也利用图来建模公路网络、铁路网、航空航线以及公共交通网络。节点表示地理位置(如城市、路口、车站),边表示它们之间的连接(如道路、铁轨、飞行航线)。然后,可对该图应用算法以优化各种操作,例如路径规划(在两个地点之间建立最优连接)。
这些场景具有一个共同特征:它们都涉及具有复杂关系的复杂系统。所谓复杂系统,是指由大量相互连接的节点组成的网络,这些节点展示出涌现行为和非线性动力学,使得系统难以预测或理解。这些系统还具有复杂的关系特征,即节点之间存在多重连接,进一步增加了其复杂性。例如,在生态食物网中,各物种通过捕食、竞争、互利共生等多种生态相互作用相互连接。每个物种都通过这些摄食关系与其他物种相连,形成了一张依赖关系错综复杂的网络。
所有这些图应用的示例都凸显了图的内在威力。而这种威力的另一个方面,体现在应用于图上的学习算法上。这些算法是图学习的核心,能够用于推荐新好友连接或寻找最优路径等任务。图学习为解决以图形方式表示的问题提供了一个全面框架,这也正是本书的重点。
图学习的核心能力在于提炼复杂的关系和结构。通过将数据表示为节点和边,图能够抽象掉冗余细节,使我们专注于驱动洞见和理解的关键连接。因此,各领域的专业人士能够更高效地分析海量数据,发现那些被庞大数据量掩盖的模式和趋势。
在当今快节奏、高度互联的世界中,充分利用图的力量能够为企业、政府和个人带来巨大益处。本书深入探讨了大规模图学习与推理的重要性,介绍了基于图的算法和推理技术如何用于分析海量数据集,并展示这些方法如何改变数据分析、解读和应用,揭示其广泛潜能。
对于企业而言,理解复杂数据能够带来更优决策、流程优化和营收增长。例如,零售公司可以利用图学习深入分析消费者行为和偏好,从而制定精准营销策略和个性化推荐。这种细致入微的洞察让他们的市场投入与客户期望高度契合,提高了业务成效。同样,金融机构也可借助图检测欺诈交易并更准确地评估信用风险。掌握图的力量,专业人士便能为当代挑战提供新颖解决方案,在行业中脱颖而出。
在科学研究领域,图学习与推理可用于建模诸如蛋白质相互作用或生态网络等复杂系统,为新发现打开大门。通过阐明这些系统中不同组件之间的联系,科学家能够构建更精确的模型、预测结果并做出推动人类知识前沿的明智决策。
对于政府和公共机构而言,图学习与推理在应对当今最紧迫的挑战时至关重要。无论是追踪传染病传播,还是理解社会动荡的动态,图都能提供指导决策的宝贵洞察。
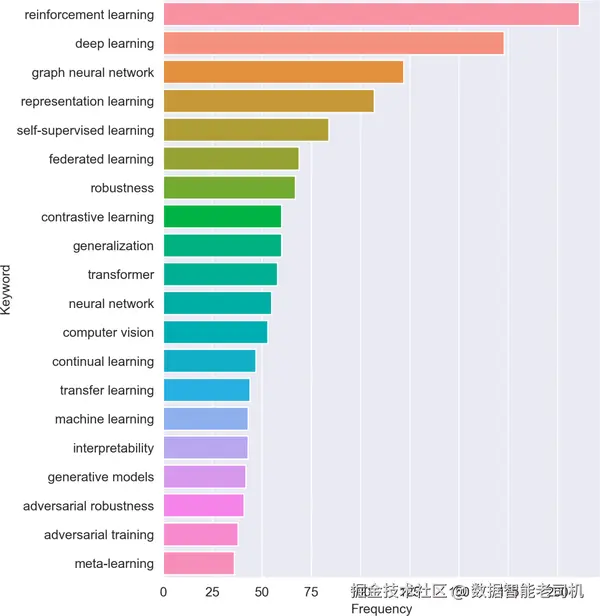
随着我们迈向通用人工智能(AGI)的实现¹,图学习与推理的重要性只增不减。在 2022 年国际学习表征会议(ICLR)上,图表关键词的显著增长便清晰地反映了这一趋势(见图 1-3)。
在本书中,我们将探讨面向企业的大规模图学习与推理的理论和实践,解决构建端到端图学习与推理流水线所面临的挑战,以实现低延迟和高吞吐量的目标。我们会带您掌握图论基础,引入最前沿的技术与应用,并提供一个全面的框架,帮助您驾驭图的复杂世界。
本书的一个核心关注点是应对图学习与推理的可扩展性挑战。随着数据量和复杂度的增长------节点和边的数量可能达到数百万,数据集规模突破 TB 级别,图中深层关系的多样性不断增加------就必须开发能够在大规模上高效管理这些增长的系统。我们将深入探讨各种策略与技术,帮助您设计并实现可扩展的图学习与推理流水线,确保随着数据规模的增长,您的解决方案依然保持高效与稳定。
为了加速基于图的学习方法和推理系统的发展,本书将介绍一个开源工具包,它整合了广泛使用的开源组件,并融入了图解决方案设计与实现的最佳实践。这个工具包不仅能为您节省时间和精力,还将为您构建高级、可定制的图学习与推理系统奠定坚实基础。
通过掌握大规模图学习与推理的能力,您将能够应对复杂挑战,并为个人和职业发展开辟新机遇。借助本书提供的知识与工具,您将做好准备,在这个日益互联的世界中游刃有余,变革数据的分析、解读与应用方式。
本书篇章全览
如果您想了解本书的整体结构及阅读顺序,请继续往下看:
- 第 1--3 章:带您入门图的世界,介绍图的基础知识、图学习流水线,以及传统的图学习方法,并配以动手示例。
- 第 4 章:介绍开源库 PyGraf²,讲解其架构、模块及使用方法。
- 第 5--9 章:深入高级主题,如图神经网络及大规模网络构建,并运用 PyGraf 的能力进行实现。
- 第 10 章:聚焦联邦学习与差分隐私,深入探讨如何构建隐私保护的图学习与推理流水线。
- 第 11 章:覆盖多种推理策略,提供更深层的洞见。
- 第 12 章:指导如何通过反馈回路有效监控与优化这些流程。
现在,让我们开始第 1 章的旅程!本章将引领您走进企业级图学习的精彩世界。我们先从图与图学习的基本概念入手,确保大家对核心术语达成共识;接着,探索图机器学习(GML)在各类应用中的惊人效益;并结合真实案例,展示图学习的潜力与威力。章节末尾,我们还将讨论图学习在企业级场景中的局限,奠定后续章节中如何主动解决这些挑战的基础。敬请期待!
图与图学习
在正式展开本书内容之前,让我们先夯实图学习的基础。首先,从最基本的图与图学习概念说起,了解它们的应用场景,并探讨在企业环境中实施图学习所面临的挑战及可行的解决方案。
什么是图?
在离散数学、尤其是图论领域,图(graph) 是一种由节点(vertex,也称为 node 或 point)和节点间连边(edge,也称为 link 或 line)构成的结构,用于表示一组对象及其两两之间的关系³。
- 无序复杂性
图的节点与边没有固定的顺序或参照点,其结构可大可小,可简单可复杂。 - 静态图(Static Graph)
节点与边都保持不变,例如拍摄公路网的"快照",路口为节点,道路为边。 - 动态图(Dynamic Graph)
随时间推移,节点或边可被添加或移除而不改变整个图的连通性。典型例子是社交网络(如 Facebook、X⁴),随着新用户加入、旧用户退出、好友关系建立与解除,图在动态演化。
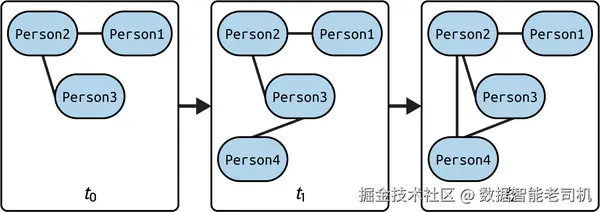
图 1-4 所示的社交网络动态图,将时间演变表示为一系列异步事件:
- t = 0:网络中仅有三人,Person1--Person2 与 Person2--Person3 存在好友边;
- t = 1:Person4 加入,生成新节点并连接到 Person3;
- t = 2:Person4 关注 Person2,新增一条边连接二者。
通过这种异步事件流,动态图能够捕捉网络结构随时间的演变。
我们将图中所包含的数据称为图数据,它指的是以图的形式表示的结构化信息,由相互连接的节点和边组成。图数据覆盖多个领域,例如交通网络、社交网络、生物网络、金融、语言学等。数据的具体特性各异,我们将在"图数据及其层次定义"一节详细阐述。
在讨论图数据及其特征时,需明确图的不同形式。图可以分为有向图和无向图,也可允许节点间存在多条边。以下是这些区分:
-
有向图 vs. 无向图
- 有向图(Directed Graph)中,边具有方向性,表示节点间的关系是单向的。
- 无向图(Undirected Graph)中,边无方向,表示节点间的关系是双向的。
-
多重边(Multiedges)
虽然通常假设任意一对节点间只有一条边,但在**多重图(Multigraph)**中,两节点间可以存在多条边。
-
边标签(Edge Labeling)
边可以带有标签,以传递额外信息。例如,在社交网络中,标签可表示加好友的时间戳;在路网中,标签可表示距离或通行成本;或其他与节点关系相关的属性。
而图学习指的是利用机器学习技术,从图结构数据中提取有价值的洞见与模式的过程。图学习算法借助图的特性,能够发现数据中隐藏的模式与关系,例如基于交互、兴趣或隶属关系,在社交网络中识别紧密关联的社区,从而支持更有效的决策与预测。
在初步了解了图与图数据的概念后,"图数据表示"一节将探讨如何将实际问题映射为图数据的方法。
图数据表示
图同样是一种将场景或问题简化表达的方式。图数据表示(Graph Data Representation) 即将任何场景映射为图的过程:将实体抽象为节点,将它们之间的关系抽象为边。映射的第一步是识别出要表示的实体(节点)及它们之间的关系(边)。
识别完成后,就可以通过节点与边的可视化方式构建图模型,这称为图建模(Graph Modeling) 。图模型有助于直观理解问题及各节点之间的关系。虽然可视化仅为辅助展示,但常用工具有 Gephi、Cytoscape、Graphviz 等。此外,还有一些文本到图的自动化工具,它们利用自然语言处理技术,从非结构化文本中自动识别节点与边并生成图表示,典型如 Neo4j、IBM Watson Knowledge Studio。不过,这类可视化工具通常仅在节点规模可控时才适用。⁵
图 1-5 示意了对简化路网的图建模:节点为路口,边为连接各路口的道路。
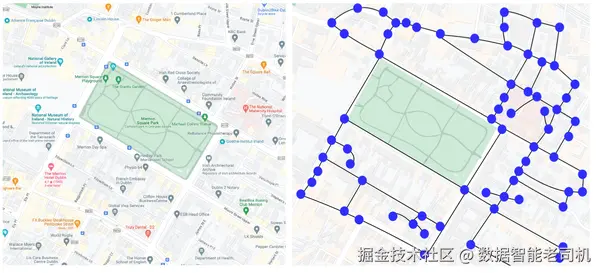
使用上一步识别出的节点和边后,图表示的第二步是找到一种数学表示,以捕捉图的结构。这通常意味着使用矩阵或向量来对结构建模,后续可用于基于图的计算。一般而言,这种数学表示既可以通过传统技术完成,也可以使用更先进的方法。传统的图表示技术包括邻接矩阵和邻接表:
- 邻接矩阵 是一个方阵,用于表示图中各节点之间的关系,其中 1 表示两个节点之间存在边,0 表示不存在;
- 邻接表 则为每个节点维护一个相邻节点列表。
在第 2 章我们会详细介绍这些内容。
而更先进的图表示技术,则以**嵌入(embeddings)**为基础。图嵌入将图中节点和边表示为数值向量,便于作为机器学习算法的输入,旨在保留图的结构和语义信息。生成图嵌入的方法多种多样,第 3--8 章将通过交互式示例逐一讲解它们的实现。
到目前为止,我们已经了解了如何将复杂现象或真实网络映射为可视化的图,并如何用传统或先进的技术将其转化为矩阵或向量形式,进而作为机器学习模型的输入。那么,这些表示究竟如何在模型中发挥作用呢?
一旦生成了这样的表示,我们就可以应用图算法------一系列用于解决图相关问题的算法,比如在地图服务中寻找最短路径,或预测新节点/新边等⁶。图数据表示让机器学习模型能够直接利用结构信息,从而提升性能和准确度。
图学习
图学习 是指将机器学习算法应用于图结构数据,以分析、学习并进行预测的过程。常见的图机器学习(GML)任务包括节点分类(给节点打标签)、链接预测(预测节点间连接)和聚类(根据相似度将节点分组),这些内容将在第 2 章(任务概览)和第 3 章(示例实践)中展开。
在完成"图数据表示"所述的表示后,我们可以将其输入到图学习算法中,解决图上的各种问题。例如,可使用图卷积网络(GCN)完成节点分类任务。
近年来,图表示学习(graph representation learning) ------更高级的图数据表示方式------备受关注。它的核心思想是将图结构映射到一个低维空间(通常是非欧几里得的),在该空间中节点和边用坐标表示,从而保留图的本地和全局连通性信息。例如,通过嵌入可以体现节点之间的近邻关系,或揭示它们在不同子图中的角色。
常见的图表示学习方法包括深度神经网络架构,例如图卷积网络(GCN)、图自编码器(GAE)、图注意力网络(GAT)和图同构网络(GIN)⁷。这些方法通过迭代地汇聚邻居特征(卷积或注意力机制),最终生成固定长度的节点嵌入。第 3 章和第 4 章将详细介绍这些模型。
此外,还有基于随机游走的算法(如 DeepWalk、node2vec 等),它们利用节点序列来训练嵌入,从而捕捉图的局部与全局结构;我们将在第 2 章深入探讨。
生成的节点嵌入可用于多种机器学习任务,例如节点分类、链接预测和图聚类,也可作为算法(如 PageRank⁸、最短路径算法⁹)输入的特征向量。高质量的嵌入有助于模型在图数据上进行更准确的预测。
举例来说,在社交网络中,你可能想预测未来的用户互动(如潜在好友关系)、推荐内容或识别用户可能感兴趣的社区。要应用机器学习,需要对节点对之间的关系特性(如两人间的关系类型与强度)进行编码,同时可能需要每个节点的全局位置信息,以便模型捕获其本地邻域结构。
注意
图数据表示侧重于以图结构组织数据,而图表示学习则是通过学习将图的部分或整体映射为可用于各种任务的低维向量(嵌入)。
尽管图学习在各类用例中取得了显著进展,但在企业环境中,大规模可扩展性仍是关键考量点,于是出现了可扩展图学习的需求。
可扩展图学习:满足企业级需求
由于企业生态系统的动态特性,理想的图学习应具备可扩展性。可扩展图学习 指能高效处理大规模图数据集的能力,包括数百万甚至数十亿的节点与边,并通过分布式和并行计算合理利用资源。其核心需求包括:
- 数据质量与集成
需要处理并整合多源异构数据(结构化、非结构化),确保数据准确、一致且实时更新。 - 图存储
要能存储企业级大图(数百万/亿级连接),常见方案有 HDFS、Apache Cassandra 等分布式存储系统。 - 分布式计算
需要分布式框架(如 Apache Spark),将数据和计算分散到多台机器以并行处理。 - 系统集成
与企业现有基础设施(数据仓库、BI 工具、可视化平台)无缝对接,提供兼容的 API 与连接器。 - 可伸缩性
系统需在超大规模多源数据环境下保持低延迟,这是阻碍图技术工业应用的核心挑战。 - 安全与隐私
对敏感数据必须做到严格保护,包括安全的数据管道、强认证、审计日志、合规控制;必要时可采用联邦学习、差分隐私等技术,第 8、9 章将深入介绍。 - 硬件加速
图算法计算量大,可借助 GPU、TPU 等硬件加速,显著提升大规模图数据训练与推理速度。
企业级可扩展图学习的优势
从技术角度来看,可扩展图学习能够:
- 强化数据表示,捕捉实体间高阶交互;
- 与现有数据管理系统无缝集成;
- 结合隐私保护技术,满足合规要求;
- 提升模型鲁棒性与预测准确性。
从业务视角来看,它可以:
- 揭示数据中隐藏的模式与关系,支持更明智的决策;
- 发掘市场机会,提升竞争力;
- 推动个性化服务与精准营销,提升客户留存与营收。
在"企业真实场景下的大规模图:用例"一节,我们将探讨可扩展图学习如何在各行业实际应用中产生突破与创新,帮助您更清晰地了解其对企业运营的深远影响。
大规模图在真实企业中的应用案例
图技术正迅速渗透到我们日常生活的各个方面,深刻影响着我们与周围世界的互动方式。从使用 Google 地图在城市间无缝导航,到在 X(原推特)和 Facebook 等社交平台上与他人互动,图应用正在改变我们的体验。
在接下来的章节中,我们将介绍多个领域中的大规模图应用示例,包括地理空间分析、药物发现以及金融行业的欺诈检测。通过这些案例,您将深入了解基于图的解决方案如何革新不同行业并推动创新。
Google 地图的行程时间预测
如果您使用过 Google 地图,就会亲身体验到其如何利用图论和图学习算法对路网建模并准确预测行程时间。Google 地图将路网抽象为图结构:节点代表路口或兴趣点,边代表道路或高速公路。系统通过在该图中寻找最短路径,结合 Dijkstra 算法和 A* 算法等图搜索技术,快速计算两点间的行程时间。此外,它还融入机器学习技术,将距离、限速和实时交通状况等控制变量纳入模型,从而提供精准、动态的导航指导。有关这些算法的更深入讲解,可参阅 Mark Needham 和 Amy E. Hodler 合著的《Graph Algorithms》(O'Reilly)。
药物开发:Halicin
在药物发现中,分子被建模为图:原子作为节点,化学键作为边,并为节点和边附加各类属性。图学习算法能够高效地分析这些分子结构,加速新药研发,例如预测溶解度和毒性等分子特性。特别是图卷积网络(GCN)------一种专门针对图数据的神经网络,我们将在后续章节详细介绍------已用于预测分子的抗菌活性,从而推动抗生素发现。
图 1-6 展示了利用图神经网络进行抗生素发现的端到端流程。该方法通过计算方式迅速筛选庞大化学空间,大大超越传统的实验筛选速度与成本。

该流程包括以下高层步骤:
- 数据准备与分析
编译一个包含有效针对大肠杆菌的分子结构和属性的大规模化学数据集。使用图卷积网络(GCN)分析这些数据,将分子建模为图:原子为节点,化学键为边。 - 模型训练与预测
在该分子数据上训练 GCN 模型,然后利用模型预测潜在的抗菌分子。预测基于模型识别出能够针对大肠杆菌发挥效用的结构模式。 - 评估与优化
对预测结果进行准确性评估,将最具潜力的候选分子标记为"先导化合物"。根据评估反馈,迭代优化模型以提升预测精度。 - 优化与验证
对先导化合物进行结构优化,以提高抗菌活性和安全性,并将模型预测扩展至更大规模的数据集。将机器学习方法的结果与传统实验方法的结果进行对比。
该流程展示了图机器学习在加速新药发现中的作用:一个仅以 2,335 个分子训练的模型,就能在超过 1.07 亿个分子中快速识别出针对大肠杆菌活性化合物,并按预测效力排序。其中一株创新候选------Halicin,不仅能对抗多种细菌,对人体细胞也安全,标志着抗生素抗性领域的一大突破。尽管仍需进一步研究其作用机制,但这一发现已极大推动了抗生素研发。
欺诈检测
图机器学习在实时检测金融欺诈交易方面具有强大优势。在金融机构中,交易通常在由账户、交易和各类关系构成的复杂网络中进行。这些网络可以表示为图:节点代表账户,边代表账户之间的交易或关联。
- 节点标签 可包含账户持有人姓名、账户余额、交易历史等信息。
- 边标签 可包含交易金额、交易日期和交易类型等额外属性。
此外,还可在图中引入其他实体节点,如商户或支付处理器,以丰富网络结构。图 1-7 展示了此类网络的示例表示:节点表示系统中的交互实体(如商户或持卡人),并通过标签附加位置信息;边表示交易发生,并通过标签突出交易属性(如金额和交易类型)。
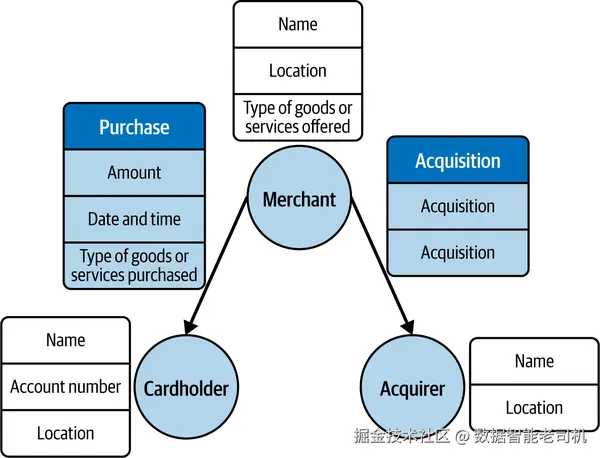
通过分析这些图,机器学习算法可以识别出可能表明欺诈活动的模式和异常情况,例如:持卡人在短时间内突然进行大量消费、一位持卡人在短时间内向多个商户发起大量交易、单一商户在短时间内向多个持卡人发起大量交易,或商户出现高比例的拒付(chargeback)等。这些都属于典型的欺诈模式。图机器学习系统通过分析图中的边及其标签来发现这些模式,并用于标记可疑交易以供进一步调查或直接触发欺诈警报。
图机器学习能够实时处理海量数据,甚至包括金融机构每天通常需要处理的数十万笔交易。因此,它非常擅长快速识别可疑交易并提醒金融机构,从而让他们在资金损失发生之前采取纠正措施。此外,图机器学习系统具备持续学习和自我调整的能力:随着算法处理的数据量增加,其识别欺诈活动和减少误报的准确性也会不断提升。在后续章节"图与图学习的演进:从早期发展到现代应用"中,我们将详细展示这一过程。
图与图学习的演进:从早期发展到现代应用
过去几十年中,图学习领域经历了显著的发展与突破。本节将回顾那些关键的里程碑事件,展示从早期研究到当今应用的演进历程。图 1-8 则展示了这一演进的若干快照。
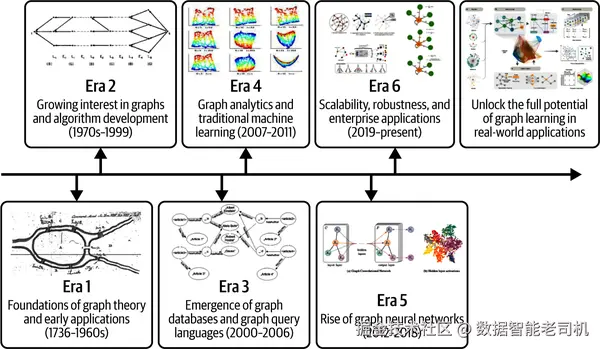
Era 1:图论与算法的奠基(1736--1970)
这一时期标志着图论的诞生。一切始于莱昂哈德·欧拉引入"图"的概念并解决了柯尼斯堡七桥问题。随着时间推移,图领域涌现出许多重要成果,最著名的当属迪杰斯特拉算法的发明,它成为了在图中寻找最短路径的利器。
Era 2:图算法与技术的更多进展(1970--1999)
在此期间,图技术和算法取得了重大突破,包括图数据结构、图遍历算法、图着色算法的发展,以及图论作为计算机科学基础学科的确立。
此外,这一时代也见证了图存储能力的早期探索------关系数据库作为主流数据存储与查询技术问世。关系数据库通过行与列的方式组织数据,形成表格;通常数据分散在多张表中,通过主键与外键进行关联操作(如 JOIN),实现高效的数据检索,但在建模复杂关系时存在局限。
1999 年,资源描述框架(RDF)被提出,为 Web 上的图数据描述奠定了基础,推动了关联数据与语义网的发展。每个 RDF 语句由三元组(主题Subject、谓词Predicate、客体Object)构成,均以统一资源标识符(URI)标识。RDF 的采用使得 AI 系统能够更快速地识别、消歧并互联信息。
与此同时,语义图技术也取得了重要进展,衍生出"知识图谱"概念------一种更灵活、可表达性更强的图数据库形式。知识图谱通过链接与语义元数据,构建实体与实体之间的上下文关系,实现数据的集成、统一、分析与共享。其核心是一套互联的知识模型,涵盖概念、实体、关系与事件的详尽描述。Google 知识图谱便是这一理念的典型应用。
Era 3:图数据库与图查询语言的出现(2000--2006)
随着图在各领域重要性日益凸显,对高效存储与检索图数据的需求变得迫切。本时期涌现出 Neo4j、OrientDB、ArangoDB 等图数据库,以及 Cypher、SPARQL、Gremlin 等图查询语言。图数据库(GDB)利用节点、边和属性来存储与管理数据,并支持复杂的语义查询,其图结构天生适合表达多元的关联关系。
Era 4:图分析与传统机器学习(2007--2011)
Apache Giraph、GraphX 等大规模图处理框架相继问世,实现了对海量图数据的并行分析。同时,研究人员开始尝试将传统机器学习方法应用到图数据上,使得链接预测、节点分类、图聚类等图机器学习(GML)任务逐渐成为热门。
Era 5:图神经网络的兴起(2012--2018)
图卷积网络(GCN)的出现标志着图机器学习的新纪元,研究者将深度学习技术引入图数据领域。本时期涌现了各类图神经网络架构------如 GraphSAGE、图注意力网络(GAT)、图同构网络(GIN)等------显著提升了图表示学习的表达能力。
Era 6:可扩展性、鲁棒性与企业应用(2019--至今)
当前阶段的重点是解决图学习在可扩展性、鲁棒性与隐私方面的挑战,并加速其在企业级场景中的落地。为应对大规模图学习问题,出现了图划分(graph partitioning)、Cluster-GCN 等新技术。
企业级图学习系统的挑战
图像和序列数据(如文本、音频)具有线性结构、顺序性和参考点;而图则具有任意维度、复杂拓扑,并且在网络中缺乏参考点或空间位置概念。此外,由于图本质上由节点和边构成,"图无法被表示为单一实体",这意味着图上的信息可能存在缺失或噪声,单一表示难以完整捕捉整个图。企业级图网络往往是动态且多模态的,也就是说它们同时承载文本、图像、音频等不同类型的数据。这些特点在企业环境中带来了诸多挑战,下面将对其中几点进行详细探讨。
数据协调挑战
企业级图学习系统需要处理并整合来自多个源和供应商的数据,同时保证数据的一致性。这些数据在格式(非结构化、半结构化、结构化)和粒度上各不相同。在图数据表示的场景下,数据协调尤其困难------图数据通常由大量相互连接的实体与关系组成,要在多源之间进行对齐和标准化并不容易。以下是两个典型难点:
- 模式与本体差异
不同来源可能使用不同的模式或本体来表达相同概念。例如,一个来源可能通过 "name" 与 "age" 字段来表示一个人,而另一个来源则用 "first_name" 与 "last_name" 字段。要协调这些数据,必须将它们转换成所有来源都能理解的统一格式(也称为"调和"),而在此过程中要避免因表示格式不一致而引入错误。 - 标准化差异
不同来源可能采用不同的数据标准或约定。例如,一个来源使用 ISO 8601 标准表示日期,而另一个来源可能使用其他格式。为了使用这些数据,必须将所有数据转换为遵循单一标准的共同格式。
计算密集型工作负载
开发图机器学习(GML)系统通常需要大量计算和资源投入,因为 GML 流水线的每个阶段都依赖不同类型的资源------图数据存储需要空间,数据预处理与训练需要计算能力,而模型参数存储则占用大量内存。下面讨论与图数据、图复杂性及训练流程相关的计算挑战:
- 图数据处理挑战
图数据的两个关键特性------海量规模与高维度------给其存储和处理带来了额外负担。要对这些大规模且高维的数据集进行存储与计算,本身就需要庞大的资源;而当我们还要不断扩展训练过程时,所需的存储和计算资源需求更是成倍增长。 - 图复杂性挑战
图能够表达节点与边之间复杂的关系,这种多样且非结构化的模式对建模和分析提出了更高要求。高级的机器学习算法和技术常常是计算密集型的,从而进一步推高了资源消耗。 - 训练挑战
GML 系统往往需要分布式训练,即在多台机器或设备上并行训练模型。这不仅在搭建和管理上具有挑战,还会显著增加训练所需的计算资源和协调成本。
动态演化图
在图系统的复杂性方面,图的动态演化特性带来了独特挑战,因为图能够随着时间不断变化。这意味着图的结构及节点之间的关系可能频繁变动。假设图结构静态的传统算法在这种情况下已不足以应对,因此需要能够基于图数据进行准确预测或分类的动态模型。构建这些模型时必须具备高度的可适应性、灵活性和计算能力,才能准确且高效地分析不断变化的数据。在大规模应用中,要实现对变化数据的即时学习和更新,保持模型响应性,本身就是一大难题。此外,随着图的演化,不断产生海量新数据,模型必须能够实时处理并分析这些数据。
一些用于分析动态演化图的算法和技术包括图聚类、社区发现以及中心性度量等方法。这些方法可用于识别数据中的模式与趋势,并了解图随时间的演变。
主动监控与漂移检测
对于已投入生产的图机器学习系统,主动监控与漂移检测同样是难点,因为系统需要持续监控数据和模型性能,并识别模型何时不再提供准确预测。
主要障碍在于需实时处理和分析海量数据,精确评估复杂模型的效果,并将当前性能与历史性能进行比对,以发现数据或模型动态中的偏离或漂移。这需要一个在生产环境中既健壮又高效的历史数据与模型性能指标存储及访问系统,其设计与实现难度极高。此外,图机器学习模型本身往往结构复杂、参数众多,也给及时评估其性能、检测预测失准带来额外挑战。
实时推断
在实时预测场景下,图机器学习模型必须在毫秒级甚至更低的延迟内保持高精度。但由于此类模型通常涉及计算密集的复杂运算,要实现亚毫秒响应率并非易事。
影响模型实时推断速度的因素包括:图的规模与复杂度、所选机器学习算法、运行模型的软硬件基础设施等。因此,必须对模型设计和基础设施进行双重优化,以缩短每次预测所需时间。这可采用模型剪枝、量化和并行化等技术,同时精调软硬件环境,减少运行模型带来的额外开销。
总结
本章奠定了面向企业的图学习基础,强调了可扩展流水线的重要性。这些原则构成了全书内容的根基,为后续探索图学习潜力做好铺垫。
在结束本导论时,让我们先预览接下来的精彩旅程。本书的总体目标是帮助读者系统理解图学习、其在医疗、金融、生物等领域的多样化应用,以及其中独特的挑战与机遇。我们将从图的传统机器学习入手,涵盖流水线开发、特征工程、表征学习、半监督的节点分类,并介绍我们的开源图学习库。
在后续章节中,我们将深入各类图学习流水线,运用传统技术从图中学习;随后覆盖深度学习与图神经网络(GNN),探讨可扩展的节点嵌入,讨论大规模图神经网络,研究企业级应用,并处理隐私保护相关问题。最后,我们将介绍图推理策略,以及 GML 系统中的监控与反馈闭环。本路线图将带来一次充实的图学习之旅,并展示其对不同行业与应用的潜在影响。
1 AGI 指具有人类式智能与适应性的 AI 系统,能够在多个领域理解、学习并执行广泛任务。与面向特定问题(如人脸识别)的专用 AI 相比,AGI 是更高级的形态,目前仍是一个研究目标。
2 PyGraf 是我们开源库的暂定名称,未来可能变更。
3 Trudeau, Richard J. (1993). 《Introduction to Graph Theory》。Dover Publications。
4 现称为 X(原 Twitter)。
5 无论是手工绘制还是多数图可视化软件,能绘制的节点与边的数量都存在限制。
6 本书将更详细地介绍这些算法。第 2 章回顾核心图算法与传统 GML,第 3--9 章研究图神经网络。
7 读者可进一步查阅这些网络的体系结构。
8 Brin, S., and Page, L. (1998). "The Anatomy of a Large-Scale Hypertextual Web Search Engine". Computer Networks and ISDN Systems, 30(1--7), 107--117。
9 Cormen, T. H., Leiserson, C. E., Rivest, R. L., and Stein, C. (1989). 《Introduction to Algorithms》。MIT Press。
10 Besta, M., and Hoefler, T. (2024). "Parallel and Distributed Graph Neural Networks: An In-Depth Concurrency Analysis". IEEE TPAMI。
11 柯尼斯堡七桥问题。Euler, L. (1741). 《Solutio problematis ad geometriam situs pertinentis》。Commentarii academiae scientiarum Petropolitanae, 128--140。
12 Hopcroft, J. E., and Karp, R. M. (1973). "An n^5/2 algorithm for maximum matchings in bipartite graphs". SIAM Journal on Computing, 2(4), 225--231。
13 Castillo, R., Rothe, C., and Leser, U. (2010). "RDFMatView: Indexing RDF Data for SPARQL Queries"。
14 Belkin, M., and Niyogi, P. (2003). "Laplacian Eigenmaps for Dimensionality Reduction and Data Representation"。Neural Computation, 15(6), 1373--1396。
15 Kipf, T. N., and Welling, M. (2017). "Semi-Supervised Classification with Graph Convolutional Networks"。arXiv:1609.02907。
16 Karagiannakos, Sergios. "Best Graph Neural Network Architectures: GCN, GAT, MPNN, and More"。2021 年 9 月 23 日。
17 Weis, J. W., and Jacobson, J. M. (2021). "Learning on Knowledge Graph Dynamics Provides an Early Warning of Impactful Research"。Nature Biotechnology, 39(10), 1300--1307。
18 "What Is a Relational Database?" IBM,2021 年 10 月 20 日。
19 Bourbakis, Nikolaos G. (1998). 《Artificial Intelligence and Automation》。World Scientific Publishing。
20 Hamilton, W., Ying, Z., and Leskovec, J. (2017). "Inductive Representation Learning on Large Graphs"。NeurIPS 30。
21 Velickovic, P. 等(2017)。"Graph Attention Networks"。arXiv:1710.10903。
22 Xu, K. 等(2018)。"How Powerful Are Graph Neural Networks?" arXiv:1810.00826。
23 ISO 8601 是用于表示日期与时间数据的国际标准。