- 什么是模拟?
是一种通过模仿现实世界或问题场景的运行过程来求解问题的算法思想。它不依赖复杂的数学推导或逻辑优化,而是按照问题的实际规则、步骤或流程,一步步地 "复现" 过程,最终得到结果。
使用场景:
当问题的逻辑规则明确、步骤可分解,且难以用数学公式直接求解时,模拟算法是直观有效的选择。常见场景包括:
过程性问题:如交通流量模拟、电梯运行调度、银行排队系统等;
规则性问题:如模拟棋牌游戏(围棋、扑克)的出牌逻辑、模拟电路时序等;
数值计算模拟:如天气预报中的大气环流模拟、物理实验中的粒子运动模拟等。
总结 :模拟算法是一种 "按部就班" 的求解思路,通过复现问题的实际过程得到结果,适合规则明确、步骤可模拟的场景。它的优势在于直观和易实现,缺点是在大规模问题中可能效率较低,需根据具体场景权衡使用。
一. (1576.) 替换所有的问号

解法:
要求不能包含连续的重复字符,根据题目模拟,从前往后遍历整个字符串,找到问号之后就用a~z的每一个字符去尝试替换
cpp
class Solution
{
public:
string modifyString(string s)
{
int n = s.size();
for(int i = 0; i < n; i++)
{
if(s[i] == '?') // 替换
{
for(char ch = 'a'; ch <= 'z'; ch++)
{
if((i == 0 || ch != s[i - 1]) && (i == n - 1 || ch != s[i
+ 1]))//巧妙的判断了头尾边界情况,不是边界情况时要满足i位置字符与左右两边不同
{
s[i] = ch;
break;
}
}
}
}
return s;
}
};二. (495.) 提莫攻击

模拟 + 分情况讨论。
计算相邻两个时间点的差值:
i. 如果差值⼤于等于中毒时间,说明上次中毒可以持续 duration 秒;
ii. 如果差值⼩于中毒时间,那么上次的中毒只能持续两者的差值。
注意:最后一次中毒时间要全部加上,因为没法与后一个元素计算差值
cpp
class Solution {
public:
int findPoisonedDuration(vector<int>& t, int d) {
int ret=0;
for(int i=1;i<t.size();i++)
{
int add=t[i]-t[i-1];//判断要增加的秒数
if(add<d) ret+=add;
else ret+=d;
}
//处理最后一个元素,秒数全部加上
ret+=d;
return ret;
}
};三. (6.) N 字形变换

算法原理:
- 解法1 :模拟
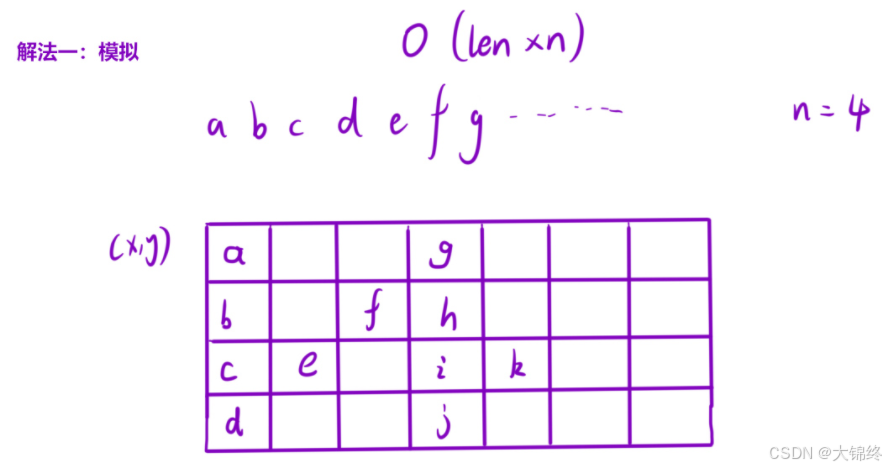
直接利用坐标规律填入数据,形成新字符串时也要再遍历一遍数组,总共需要两次,时间复杂度和空间复杂度都一样有点高
- 解法2:找规律
可以先通过具体行数的一个例证找到一种规律,再通过不同行数的例子来验证是否正确。
通过行数为4的情况来找规律
1.利用原字符串下标来进行找规律,就不需要遍历数组,直接在原字符串中操作添加到新字符串来提高效率。图中数组是为了方便找规律,不加入实际代码中
2.列数小于原字符串大小就够用,计算每一行元素之间的公差,找到规律并验证
3.第一行和最后一行的处理情况相同,中间行元素要两个两个一起递增相加
4.注意当行数等于1时的特殊情况,直接返回原字符串,避免进入死循环(公差为0)
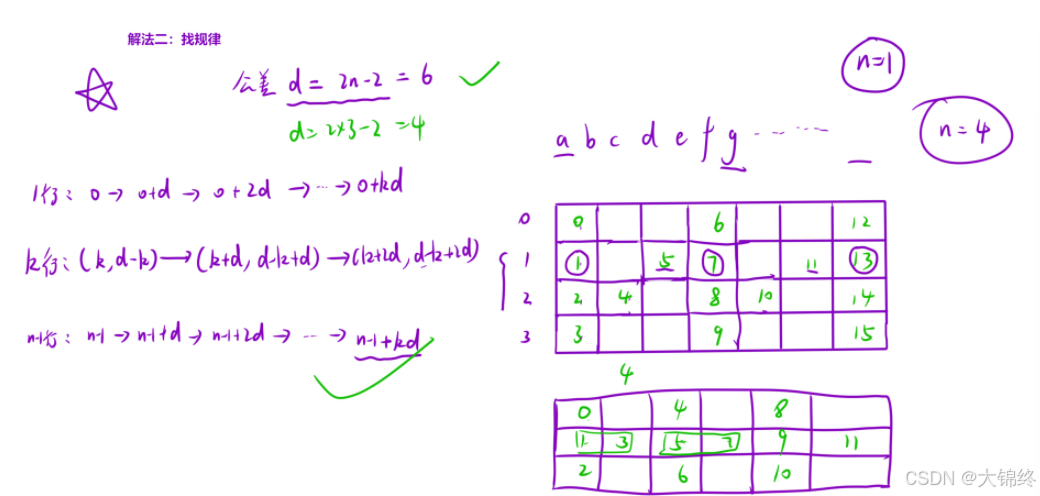
cpp
class Solution {
public:
string convert(string s, int n) {
//处理特殊情况
if(n==1) return s;
//公差
int d=2*n-2;
string ret;
//处理第一行元素
for(int i=0;i<s.size();i+=d) ret+=s[i];
//处理中间行元素
for(int i=1;i<n-1;i++)//遍历中间每一行
{
for(int k=i,j=d-i;k<s.size()||j<s.size();k+=d,j+=d)
{//||保证有一个元素在范围内,添加时要先进性判断
if(k<s.size()) ret+=s[k];
if(j<s.size()) ret+=s[j];
}
}
//处理最后一行元素
for(int i=n-1;i<s.size();i+=d) ret+=s[i];
return ret;
}
};四. (38.) 外观数列
解法:
利用双指针,开始都指向头位置,一个移动另一个不动,元素相等时后移直到不等时停止,计算差值即为不动指针所对应的元素个数,然后更新不动指针,如此循环往复
cpp
class Solution {
public:
string countAndSay(int n) {
string ret="1";
for(int i=1;i<n;i++)// 解释 n - 1 次 ret 即可
{
string tmp;//用于记录下一项的临时变量,ret为当前解析的字符串
int len=ret.size();
int count=1;//统计连续相同字符的个数,最少出现一次
for(int left=0,right=0;right<len;)
{// 移动right,找到与ret[left]不同的第一个位置
while(right<len&&ret[left]==ret[right]) right++;
count=right-left;
// 拼接:"连续的个数" + "字符本身"
tmp+=to_string(count)+ret[left];
// 移动left到right的位置,开始统计下一组连续字符
left=right;
}
ret=tmp;
}
return ret;
}
};解析:
得到外观数列第n项的结果,只需要解析前n-1项即可。第一项一定为1,所以从1开始解析,创建一个变量tmp来存储解析后作为下一次解析的字符串。内层循环中通过双指针遍历当前项,解析完后更新当前项,继续迭代下去
注意:
1.初始化方式完全不同
string ret="1":
是包含单个字符 '1' 的字符串,ret.size() 为 1,ret0 为 '1'(ASCII 码值为 49)。
string ret{1}:
此时会调用 std::string 的另一个构造函数:string(size_t n, char c),该构造函数的含义是 "创建一个包含 n 个字符 c 的字符串"。 1 会被隐式转换为size_t 类型(无符号整数),作为第一个参数(字符个数),整数 1 会被当作 char 类型的 ASCII 码值,即 string ret{1}; 等价于 string ret(1, '\x01'),其中 '\x01' 是 ASCII 码为 1 的控制字符(SOH,标题开始符)
这样初始化的结果 是一个长度为 1 的字符串,但包含的字符是 ASCII 码为 1 的不可见控制字符(而非字符 '1'),ret0 的值为 1(十进制),而非 49。
本质:用整数对应的ASCII 码值初始化,字符串内容是该 ASCII 码对应的字符(通常是不可见的控制字符)。
2.字符串拼接逻辑
std::string的operator+=支持以下常见形式:
追加单个字符:ret += 'a'
追加字符串:ret += "abc" 或 ret += another_str
不支持ret += {str1, str2}这种初始化列表形式,整数转为字符串要加to_string()
五. (1419.) 数⻘蛙

解法 :

◦ 当遇到 'r' 'o' 'a' 'k' 这四个字符的时候,我们要去看看每⼀个字符对应的前驱字符,
有没有⻘蛙叫出来。如果有⻘蛙叫出来,那就让这个⻘蛙接下来喊出来这个字符;如果没有,直接返回 -1 ;
◦ 当遇到 'c' 这个字符的时候,我们去看看 'k' 这个字符有没有⻘蛙叫出来。如果有,就让这个⻘蛙继续去喊 'c' 这个字符;如果没有的话,就重新搞⼀个⻘蛙。
- if-else方法
完全模拟上图过程即可,只需注意返回值时的多种情况
cpp
class Solution {
public:
int minNumberOfFrogs(string croakOfFrogs) {
int c=0,r=0,o=0,a=0,k=0;
for(auto ch:croakOfFrogs)
{
if(ch=='c')
{
if(k!=0){
k--;
c++;
}
else c++;
}
else if(ch=='r'){
if(c!=0){
c--;
r++;
}
else return -1;
}
else if(ch=='o'){
if(r!=0){
r--;
o++;
}
else return -1;
}
else if(ch=='a'){
if(o!=0){
o--;
a++;
}
else return -1;
}
else if(ch=='k'){
if(a!=0){
a--;
k++;
}
else return -1;
}
}
//判断一次完整的蛙叫都没有
if(k==0) return -1;
//判断c不能满足一次蛙叫的情况,可以和除k以外的字符比较是否相等
//不能和k比因为可以由一只蛙重复叫
else if(c!=r) return -1;
else return k;
}
};- 哈希表方法
cpp
class Solution {
public:
int minNumberOfFrogs(string croakOfFrogs) {
string t="croak";
int n=t.size();
vector<int>hash(n);//用数组模拟哈希表
unordered_map<char,int>index;//为了方便查找下标
for(int i=0;i<n;i++)
{
index[t[i]]=i;
}
for(auto ch:croakOfFrogs)
{
if(ch=='c')
{
if(hash[n-1])
{
hash[n-1]--;
hash[0]++;
}
else hash[0]++;
}
else{//其他情况都适用,避免了条件判断
int i=index[ch];//得到下标
if(hash[i-1]==0) return -1;
hash[i-1]--;
hash[i]++;
}
}
for(int i=0;i<n-1;i++)
{//判断蛙叫是否有效,除k外必须都为0
if(hash[i]) return -1;
}
return hash[n-1];
}
};适用于通用情况,当不知道给定字符串内容时适用,通过数组模拟哈希降低空间复杂度,再用哈希表存储字符所对应的下标,方便查找。循环时只用分两组,避免繁杂的情况讨论