大家好,我是双越。前百度 滴滴 资深前端工程师,慕课网金牌讲师,PMP。我的代表作有:
- wangEditor 开源 web 富文本编辑器,GitHub 18k star,npm 周下载量 20k
- 划水AI Node 全栈 AIGC 知识库,包括 AI 写作、多人协同编辑。复杂业务,真实上线。
- 前端面试派 系统专业的面试导航,刷题,写简历,看面试技巧,内推工作。开源免费。
我最近整理了一些 AI Agent 开发 相关的资料,有兴趣的同学可以加入分享和讨论~
开始
最近我正在看 LangChain LangGraph 和 AI Agent 开发的相关内容,已分享过两篇相关文章: 30 行代码 langChain.js 开发你的第一个 Agent 和 使用 langChain.js 实现 RAG 知识库语义搜索
现在很多内容平台都有智能总结功能,把内容传递给 LLM 返回简短的总结,方便用户快速查看。
本文将 langChain.js 实现这一功能,同时会考虑几万字大文档和 LLM token 限制。
创建项目
创建一个 nodejs 项目,并安装 langchain 和 dotenv ,后面我们需要使用环境变量。
sh
npm i langchain dotenv然后新建文件 sum.js 后续在这里写代码。
方式1:上传全部文档内容
对于简短的文档,可以直接简单粗暴的把文档内容全部传递给 LLM 返回智能总结。但如果文档内容太长,超过 LLM token 限制的话,这种方式就不适用了。
加载文档内容
准备一个 Markdown 格式的博客文档,保存为本地文件 data/blog1.md,然后使用 TextLoader 加载文档内容。
js
import { TextLoader } from 'langchain/document_loaders/fs/text'
// 加载本地文档,模拟从数据库获取文档内容
async function loadMarkdownWithLoader(filePath) {
const loader = new TextLoader(filePath)
return await loader.load()
}
const doc = await loadMarkdownWithLoader('data/blog1.md')
console.log(
'doc content',
doc[0].pageContent.length,
doc[0].pageContent.substring(0, 300)
)执行代码,可打印文档内容长度和部分内容,说明加载成功了。

定义 LLM
langChain 集成了有很多 LLM 可供选择 js.langchain.com/docs/integr...
它默认推荐的是 OpenAI 但是在国内我们没法直接调用它的 API ,所以我当前选择的是 DeepSeek 。
注册登录 DeepSeek 创建一个 API key 并把它放在 .env 文件中
env
DEEPSEEK_API_KEY=xxx安装 langChain DeepSeek 插件
sh
npm i @langchain/deepseek继续写代码
js
import { ChatDeepSeek } from '@langchain/deepseek'
import 'dotenv/config'
const llm = new ChatDeepSeek({
model: 'deepseek-chat',
temperature: 0,
})实现智能总结
定义 Prompt 然后初始化一个 chain ,最后调用 chain 并传入 doc ,即可实现。
js
import { createStuffDocumentsChain } from 'langchain/chains/combine_documents'
import { StringOutputParser } from '@langchain/core/output_parsers'
import { PromptTemplate } from '@langchain/core/prompts'
// Define prompt
const prompt = PromptTemplate.fromTemplate(
`简单总结这篇文章,200 字以内。
<article>
{context}
</article>
`
)
// Instantiate
const chain = await createStuffDocumentsChain({
llm: llm,
outputParser: new StringOutputParser(),
prompt,
})
// Invoke
const result = await chain.invoke({ context: doc })
console.log('result...', result)执行代码可打印结果,要点总结的非常到位。

另外,还可以使用 stream 形式输出内容,支持前端实现打字效果。
js
// streaming
const stream = await chain.stream({ context: docs })
for await (const token of stream) {
process.stdout.write(token + '|')
}方式2:Map Reduce
上述 方式1 比较简单,但只适用于内容简短的文档,大文档内容长度可能会超出 LLM token 限制,需要用 map reduce 方式解决。
所谓 map reduce 就是把一个主题拆分 为多个子主题,然后并行调用 LLM 得到多个结果,再对这些这些结果进行合并处处理。如果第一次合并完还不满足要求,那就再进一步拆分,可不断重复 map 和 reduce 这两个过程。

加载大文档
准备一个万字的博客 Markdown 文档,就是我之前写的博客《【万字总结】2025 前端+大前端+全栈 知识体系》上 下 两篇合并起来的。把这个 md 文档放在本地 data/blog2.md 目录下
使用上文的 loadMarkdownWithLoader 加载文档。执行代码,可输出文档内容长度,和文档的一部分内容。

拆分文档内容
由于文档比较大,不方便直接使用,需要用 langChain TextSpliter 把文档拆分为多个小模块,方便后续 map-reduce 操作。
js
import { RecursiveCharacterTextSplitter } from '@langchain/textsplitters'
// RecursiveCharacterTextSplitter 本地执行,不用网络请求,还可以智能区分段落句子
const textSplitter = new RecursiveCharacterTextSplitter({
chunkSize: 1000,
chunkOverlap: 100,
})
const splitDocs = await textSplitter.splitDocuments(doc)
console.log(`Generated ${splitDocs.length} documents.`)
// 查看拆分结果
splitDocs.forEach((doc, index) => {
console.log(`\n--- Chunk ${index + 1} ---`)
console.log(`Content length: ${doc.pageContent.length}`)
console.log(`Metadata:`, doc.metadata)
console.log(`Preview: ${doc.pageContent.substring(0, 50)}...`)
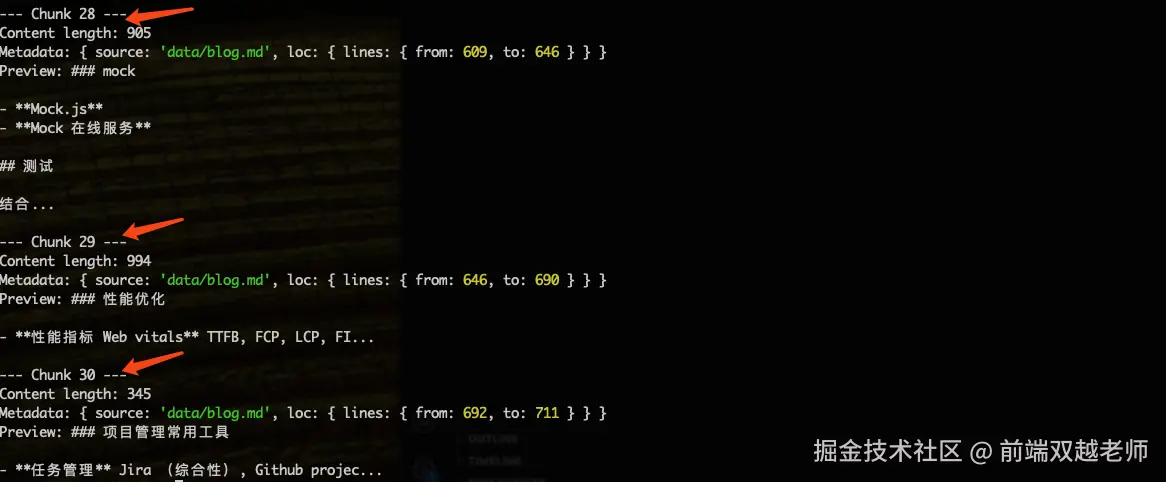
})执行代码,可看到一共拆分出 30 chunks ,每个内容长度在 1000 左右(除了最后一个)
Map 拆分
代码执行会在最后演示,因为需要定义很多函数最后再一起调用。这里我们先模拟代码执行过程。
首先会执行 mapSummaries 函数,通过 state.contents 可获得拆分后的文档内容,然后使用 map 把每一个 content 传递给 generateSummary 函数
js
import { Send } from '@langchain/langgraph'
// map 遍历生成 summaries
const mapSummaries = (state) => {
// state.contents 是分割出来的文档内容数组
return state.contents.map(
(content) => new Send('generateSummary', { content }) // 每个文档内容都调用 generateSummary
)
}在 generateSummary 函数中通过 LLM 生成总结,最终返回为一个 summaries 数组。
js
import { ChatPromptTemplate } from '@langchain/core/prompts'
const mapPrompt = ChatPromptTemplate.fromMessages([
['user', '根据如下内容写一个简单的总结: \n\n{context}'],
])
// 根据文档,生成总结
const generateSummary = async (state) => {
// state.content 是分割出来的一段文档内容
const prompt = await mapPrompt.invoke({ context: state.content })
const response = await llm.invoke(prompt)
return { summaries: [String(response.content)] }
}即,原来是 contents 数组 ['内容1', '内容2', '内容3'],拆分处理之后就变成了 summaries 数组 ['总结1','总结2','总结3'],每一个 content 都变成了相应的 summary 总结。
Reduce 缩减
同样,代码执行会在最后演示,因为需要定义很多函数最后再一起调用。这里我们先模拟代码执行过程。
会先调用 collectSummaries 函数,它会把上文生成的 summaries 转换为 Document 数组,方便后续操作。
js
import { Document } from '@langchain/core/documents'
const collectSummaries = async (state) => {
return {
collapsedSummaries: state.summaries.map(
(summary) => new Document({ pageContent: summary })
),
}
}然后再调用 shouldCollapse 函数,检查当前 collapsedSummaries 所有的 token 长度,是否超出了 LLM token 限制。
js
let tokenMax = 1500 // 设置最大 token 限制
// 计算文档的 token 数量
async function lengthFunction(documents) {
const tokenCounts = await Promise.all(
documents.map(async (doc) => {
return llm.getNumTokens(doc.pageContent)
})
)
return tokenCounts.reduce((sum, count) => sum + count, 0)
}
// 继续合并,还是生成最终总结?
async function shouldCollapse(state) {
let numTokens = await lengthFunction(state.collapsedSummaries)
if (numTokens > tokenMax) {
return 'collapseSummaries'
} else {
return 'generateFinalSummary'
}
}如果没有超出 token 限制,那就执行 generateFinalSummary 生成最后的总结,即根据 collapsedSummaries 再写一个最终总结。
js
const reducePrompt = ChatPromptTemplate.fromMessages([
[
'user',
`下面是一组总结:
{docs}
将这些内容提炼成一个最终的、综合性的总结。`,
],
])
async function _reduce(input) {
const prompt = await reducePrompt.invoke({ docs: input })
const response = await llm.invoke(prompt)
return String(response.content)
}
// 生成最后的总结
const generateFinalSummary = async (state) => {
const response = await _reduce(state.collapsedSummaries)
return { finalSummary: response }
}如果依然超出 token 限制,则调用 collapseSummaries 函数,根据当前 token 数量和 token 限制进行拆分,调用 _reduce 函数进行总结合并。即把内容进一步总结、压缩 reduce ,让它内容变短。
js
import { collapseDocs, splitListOfDocs } from 'langchain/chains/combine_documents/reduce'
const collapseSummaries = async (state) => {
const docLists = splitListOfDocs(
state.collapsedSummaries,
lengthFunction,
tokenMax
)
const results = []
for (const docList of docLists) {
results.push(
await collapseDocs(docList, _reduce) // 把 docList 中的文档合并为一个文档
)
}
return { collapsedSummaries: results }
}定义 Graph 工作流
使用 StateGraph 定义 Agent 工作流。对此不熟悉的同学可看我之前的博客 30 行代码 langChain.js 开发你的第一个 Agent
js
import { StateGraph, Annotation } from '@langchain/langgraph'
const OverallState = Annotation.Root({
contents: Annotation,
// Notice here we pass a reducer function.
// This is because we want combine all the summaries we generate
// from individual nodes back into one list. - this is essentially
// the "reduce" part
summaries: Annotation({
reducer: (state, update) => state.concat(update),
}),
collapsedSummaries: Annotation,
finalSummary: Annotation,
})
const graph = new StateGraph(OverallState)
.addNode('generateSummary', generateSummary)
.addNode('collectSummaries', collectSummaries)
.addNode('collapseSummaries', collapseSummaries)
.addNode('generateFinalSummary', generateFinalSummary)
.addConditionalEdges('__start__', mapSummaries, ['generateSummary'])
.addEdge('generateSummary', 'collectSummaries')
.addConditionalEdges('collectSummaries', shouldCollapse, [
'collapseSummaries',
'generateFinalSummary',
])
.addConditionalEdges('collapseSummaries', shouldCollapse, [
'collapseSummaries',
'generateFinalSummary',
])
.addEdge('generateFinalSummary', '__end__')
const app = graph.compile()这个工作流的调度流程和上文描述的是一样的
- map 拆分文档内容,分别生成总结
- reduce 针对一系列总结,生成一个总结
- 生成最终总结
js
/**
* workflow:
┌────────────┐
│ __start__ │
└─────┬──────┘
↓
┌─────────────────┐
│ generateSummary │◄───┐ (Map: 对每段文档 summarization)
└────┬────────────┘ │
↓ │ mapSummaries
┌──────────────────────┐ │
│ collectSummaries │─────┘
└────┬─────────────────┘
↓
shouldCollapse ?
┌──────────────────┐
│ 是 │
▼ ▼
collapseSummaries generateFinalSummary
│ │
└──shouldCollapse───┘
↓
__end__
*/调用 Agent
使用 stream 方式调用 Agent
js
let finalSummary = null
for await (const step of await app.stream(
{ contents: splitDocs.map((doc) => doc.pageContent) },
{ recursionLimit: 10 }
)) {
console.log(Object.keys(step))
if (step.hasOwnProperty('generateFinalSummary')) {
finalSummary = step.generateFinalSummary
}
}
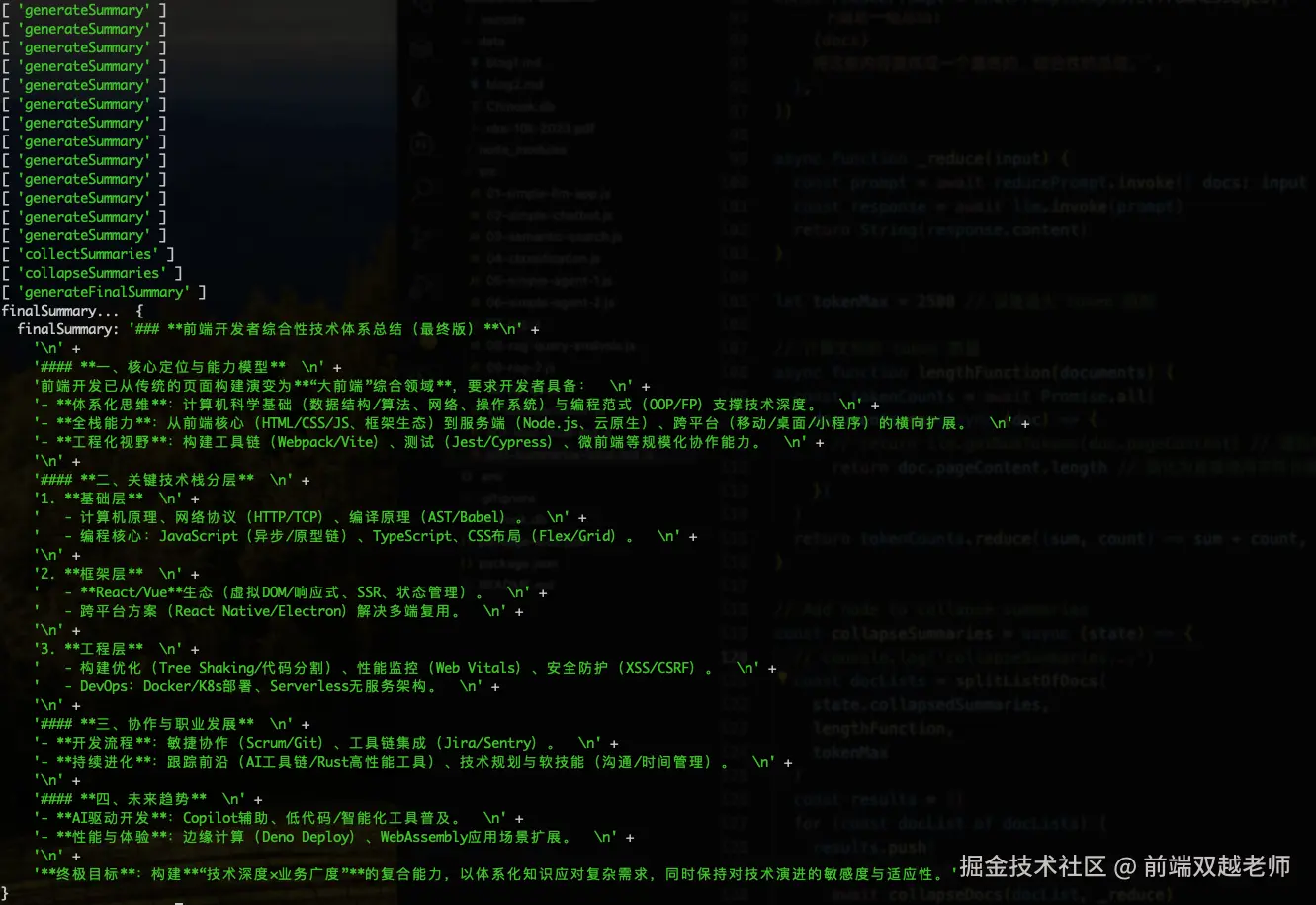
console.log('finalSummary... ', finalSummary)执行代码遇到一个报错 Failed to calculate number of tokens, falling back to approximate count Error: Unknown model

看报错位置是在 lengthFunction 函数内,计算 token 数量时。这里先直接使用字符串 length 作为 token 吧。
js
// 计算文档的 token 数量
async function lengthFunction(documents) {
const tokenCounts = await Promise.all(
documents.map(async (doc) => {
// return llm.getNumTokens(doc.pageContent)
return doc.pageContent.length // 简化为直接使用字符长度
})
)
return tokenCounts.reduce((sum, count) => sum + count, 0)
}再次执行代码,打印结果如下:
最后
这个例子体现了 LangChain 在 AI 领域强大的开发能力,如有类似需求,可以直接拿来用于项目中。
最后有对 AI Agent 开发感兴趣的同学,欢迎加入分享和讨论~