简介
人体姿态估计(human pose estimation)是计算机视觉的一个重要任务,其目的是识别人体的动作和姿势,这对于很多应用(如运动分析、虚拟现实和人机交互等)都非常重要 。在虚拟现实中,人体姿态估计技术有助于跟踪用户的动作,使得虚拟现实体验更加逼真;在人机交互中,人体姿态估计技术有助于设备更好地识别用户的命令,从而使得人机交互更加流畅。一般来说,人体姿态估计分为二维姿态估计和三维姿态估计,它们之间有一些明显的差异。二维姿态估计用于检测人体在图像中的关节点坐标,输出为二维坐标。因此二维姿态估计类似于语义分割和目标检测这种视觉识别任务,所需技术包括图像特征提取和坐标回归等。三维姿态估计用于识别人体在三维空间中的关节点坐标,输出为三维坐标。因此三维姿态估计通常还需要场景重建技术,如立体视觉、运动估计等。在本章中,我们主要介绍二维姿态估计。
根据人体结构,可以把关节点连接起来,形成人体骨架(skeleton)的形式(如图14-1所示),图14-1人体姿态估计示意所以人体姿态估计也叫作人体骨架估计。
数据集
在人体姿态估计中,通常会选择以下几种常用的数据集进行模型的训练与测试。
(1)Leeds Sports Pose(LSP):共收录2000幅全身姿势图像,这些图像分为8类(田径羽毛球、棒球、体操、跑酷、足球、网球和排球),每幅人体图像都有14个关节点。
(2)Frames Labeled In Cinema(FLIC):共收录5003幅图像,这些图像来自30部著名好莱坞电影,每部电影每10帧进行一次人体检测,共获得约20000个人体候选区,这些候选区被发布到众包平台Amazon Mechanical Turk上做标注,每个候选区获得10个上半身关节的真实坐标,最后再由人工去除严重遮挡或非正视图的图像。
(3)Max Planck Institute for Informatics(MPII)Human Pose:包含约25000幅图像,其中包含40000多个标注了关节点的人,整个数据集涵盖410种人类的活动。数据集的图像来自YouTube,涵盖了室内外场景及各种成像条件,因此该数据集在外观变异性方面具有很高的多样性。研究人员对收集的图像提供了丰富的标注,包括身体关节的位置、头部和躯干的3D视角,以及眼睛和鼻子的位置,此外还对所有身体关节和部位的可见性进行了标注。
(4)Microsoft Common Objects in Context(MS COCO):MS COCO数据集不仅用于目标检测、分割、关节点检测等任务,也可以用于人体姿态估计。MS COCO对每个人体实例都标注了17个关节点,包括鼻子、两眼、两耳、肩部、手肘、手腕、髋部、膝盖和脚踝。相比于 MPIⅡ数据集,MS COCO在人脸结构的标注上更为丰富和多样。
人体姿态估计常用评测指标
PCK (Percentage of Correct Keypoints)
以关键点与真实位置的欧氏距离是否小于阈值(通常为头部尺寸的百分比)判断正确性。例如PCK@0.2表示误差小于头部尺寸20%的关键点比例。适用遮挡或复杂场景评估。
mAP|OKS (mean Average Precision)
基于目标检测的指标,又称目标关键点相识度,计算每个关键点的AP后取平均。常用OKS(Object Keypoint Similarity)作为IoU的替代,公式为:
其中为预测与真实点距离,s为尺度因子,
为关键点类型权重,
为可见性标签。
人体姿态估计模型
DeepPose早期的人体姿态估计方法都是基于图像块去预测关节点坐标,并根据人体学的知识加以约束)。但是仅根据图像的局部信息很难对关节点进行准确的预测。例如,从图14-2左边的两个图像块中很难判断出它们所表示的是人体的哪个部分,因此需要有一种可以将整幅图像作为输入直接预测所有关节点的方法。根据前面几章的内容可知,深度神经网络正好能够实现这个功能,于是就出现了基于深度神经网络的DeepPose。

接下来我们将详细介绍DeepPose的网络架构及训练过程。
基于神经网络的人体姿态估计
在训练DeepPose之前,首先需要对数据进行预处理 。在数据集中,关节点坐标通常以图像的绝对坐标给出,但这种表示方式对于网络学习并不理想。因此,DeepPose将关节点坐标转换为相对坐标,即将关节点坐标相对于人体包围盒做归一化
DeepPose将姿态估计问题视作一个回归问题,可以训练一个姿态回归器来进行预测
级联回归
之前的方法存在一个问题,即网络的输入图像尺寸固定为220像素×220像素,这限制了网络对细节的捕捉能力。为了解决这个问题,DeepPose提出了级联回归的方法。在初始阶段,DeepPose会估计一个初始姿态。在随后的精化阶段中,对每个关节点训练一个额外的姿态回归器,以此来预测该关节点从上一阶段预测的位置到真实位置的位移。每个精化阶段使用上一阶段预测的关节点位置来集中关注关节点在图像的相关部分,也就是围绕上一阶段预测的关节点位置进行裁剪得到局部图像,并且应用姿态回归器在这个局部图像上预测关节点的精细化位置,如图14-3所示。这种级联回归的方法可以提高网络对细节的感知能力,通过监控各个人体关键点,从而提高姿态估计的精度。
DeepPose流程
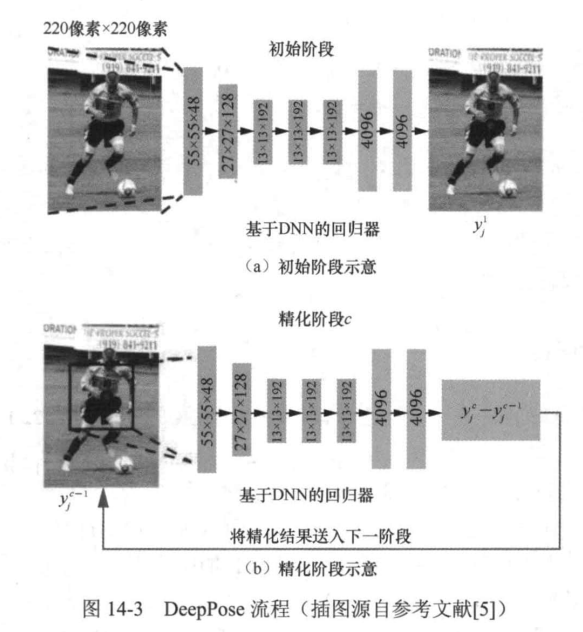
DeepPose相对于以往基于图像块的方法有如下创新点。
(1)对于如何使用全局观点获得关节点的坐标的问题,DeepPose提出了使用深度神经网络作为全局特征提取,将整幅图像作为输入的方法。
(2)人体关节点本身存在分布规律,而关节点的坐标在图像坐标系下并无特别的规律,因此DeepPose提出了在每个环节中,通过中心点、长和宽选择一个包围盒,然后计算节点在包围盒中的坐标,从而将绝对坐标转换为统一的坐标。
(3)为了实现更高精度的坐标计算,DeepPose提出了级联的深度神经网络,在获得初步的关节点坐标之后,再在原始图像中根据该坐标选择一定的局部区域,从而实现更高准确度的坐标计算。
通过这一系列的设计,DeepPose成功地成为当时的最高水平(state-of-the-art,SOTA),并引领了深度学习在人体姿态估计领域的潮流。接下来,我们来动手编写DeepPose并在MS COCO数据集上测试预测效果。
DeepPose代码实现
由于DeepPose的级联过程需要对每个关节点训练一个回归器,这一过程非常耗时。如 DeepPose的论文中所述,训练每个级联精化阶段需要花费7天时间。因此,我们这里采用一种高效的处理方式:在每个阶段,将上一阶段预测的关节点坐标和对图像提取得到的特征图进行拼接,并基于这一拼接的特征进行这一阶段关节点坐标的精化。与DeepPose的级联精化过程相比,我们采用的方式去除了裁剪操作,无须多次计算图像特征,因此高效得多;又因为拼接的特征图中包含了上一阶段预测的关节点位置信息,可以使网络更加关注该位置周围的局部图像区域,从而实现关节点坐标的精化。我们首先下载ms coco数据集
MSCOCO2017数据集
编写DeepPose的代码
python
import torch
import torch.nn as nn
import torchvision.models as models
class DeepPose(nn.Module):
# num_keypoints=17:默认预测17个关键点 pretain=True:默认使用预训练模型权重 num_stage=3:默认使用3 级联个阶段(stage)
def __init__(self,num_keypoints=17,pretain=True,num_stage=3):
# super调用父类 nn.Module.__init__(),确保 DeepPose 正确初始化
super(DeepPose,self).__init__()
self.num_keypoints=num_keypoints
self.num_stage=num_stage
# 加载预训练模型ResNet50
self.base_model=models.resnet50(pretrained=pretain)
# 为每个级联定于回归层
self.regression_layers=nn.ModuleList(
self._make_regression_layers() for _ in range(num_stage)
)
# 每个级联阶段的最终全连接层,用于关节点预测
self.final_layers=nn.ModuleList(
nn.Linear(2048,num_keypoints*2) for _ in range(num_stage)
)
# 定义每个级联阶段的回归层
def _make_regression_layers(self):
# 定义回归层,由几个卷积层组成
return nn.Sequential(
nn.Conv2d(2048,512,kernel_size=3,padding=1),
nn.BatchNorm1d(512),
nn.ReLU(inplace=True),
nn.Conv2d(512,512,kernel_size=3,padding=1),
nn.BatchNorm1d(512),
nn.ReLU(inplace=True),
nn.Conv2d(512,2048,kernel_size=1),
)
def forward(self,x):
# 使用骨干网络提取特征
features=self.backbone(x)
keypoint_preds=torch.zeros(x.size(0),self.num_keypoints*2).to(x.device)
# 循环每个级联阶段的回归层
for i in range(self.num_stage):
#将关节点预测结果与特征图拼接
keypoint_map=keypoint_preds.view(x.size(0),self.num_keypoints,2, 1,1)
keypoint_map=keypoint_map.expand(-1,-1,-1,features.size(2), features.size(3))
features_with_keypoints=torch.cat([features, keypoint_map.view(x.size(0),-1,features.size(2), features.size(3))],dim=1)
# 通过回归层进行精化
regression_output=self.regression_layers[i](features_with_keypoints)
#将回归输出展平并通过全连接层
regression_output=regression_output.view(x.size(0),-1)
keypoint_preds +=self.fc_layers[i](regression_output)
#返回关节点的最终位置
return keypoint_preds.view(x.size(0),self.num_keypoints,2)接着,我们在MS COC0上对其进行训练。我们先导入必要的仓库以及库函数。
python
!git clone https://github.com/Naman-ntc/Pytorch-Human-Pose-Estimation.git
!pip install -r requirements.txt设置好模型设置和MS COCO数据集的路径,开始对模型进行训练。
bash
!python main.py -DataConfig conf/datasets/coco.defconf -ModelConfig / conf/models/DeepPose.defconf
小结
本章介绍了使用深度学习进行人体姿态估计的开山之作一DeepPose,并在MS COCO数据集上进行了训练与测试。人体姿态估计是计算机视觉领域的一个基础问题,只有准确地估计了图像中人体的姿态,才能赋能后续的操作,如电影动作捕捉、动画制作、轨迹跟踪、人机交互及运动分析等。接下来我们将继续介绍如何从视频中识别运动。