以下是针对 Redis 数据倾斜问题的完整排查与优化方案,结合实战案例说明如何提升吞吐量和响应速度:
一、问题现象定位
1. 性能监控异常
# Redis集群节点负载差异
$ redis-cli -c cluster nodes | grep master
e1d7b... 10.0.0.1:6379@16379 master - 0 1650000000000 connected 0-5460 # CPU 95%
a2c9f... 10.0.0.2:6379@16379 master - 0 1650000001000 connected 5461-10922 # CPU 15%
f8e12... 10.0.0.3:6379@16379 master - 0 1650000002000 connected 10923-16383 # CPU 12%📊 现象:节点1 CPU持续95%+,其他节点负载不足20%
📌 结论:数据倾斜导致单点过热
2. 热点Key诊断
# 使用redis-cli监控命令
$ redis-cli -h 10.0.0.1 --hotkeys
# 输出结果:
1. "user:10000:cart" (freq: 98765)
2. "product:999:price" (freq: 56432)
3. "global:config" (size: 5.2MB) # 大Value🎯 发现:
高频访问Key:用户10000的购物车每秒近10万次访问
大Value:全局配置5.2MB
二、根因分析
| 问题类型 | 具体Case | 影响 |
|---|---|---|
| 哈希槽分配不均 | 热点user数据集中分片(如user ID取模) | 单节点QPS突破30万 |
| 大Key读放大 | 5.2MB的全局配置反复读取 | 单次读耗时>10ms |
| Key设计缺陷 | {type}:{id}结构导致相同前缀聚集 |
集群无法分散存储 |
| 缺少本地缓存 | 热点数据每次直连Redis | 网卡流量打满(>1Gbps) |
三、优化方案与实施
▶ 方案1:动态分片策略重构
// 旧方案:直接哈希导致倾斜
int slot = userId.hashCode() % 16384;
// 新方案:增加分片因子 + 二级哈希
String shardKey = userId + ":" + System.getenv("SHARD_SALT"); // 加入环境变量盐值
int slot = CRC16.crc64(shardKey.getBytes()) % 16384;✅ 效果:同一用户的Key均匀分散到不同节点
📈 验证:节点负载差异从 95% vs 15% → 降至 55% vs 48%
▶ 方案2:大Key拆分与压缩
// 全局配置拆分为子Hash (按模块分组)
hset config:network timeout "5000"
hset config:database max_conn "100"
// 启用压缩(启用LZ4)
config set hash-max-ziplist-entries 512
config set hash-max-ziplist-value 1024✅ 效果:
单个Key最大尺寸从5.2MB → 150KB
读耗时从10ms → 0.3ms
▶ 方案3:Key结构重设计
- 反例:
user:10000:cart
product:999:price
+ 优化后:
{user_cart}:{salted_id} # 加入分片因子
{product_price}:{random_suffix} # 添加随机后缀✅ 效果:相同业务Key均匀分布在不同槽位
🔧 工具:使用
redis-cli --cluster rebalance手动调整槽位
▶ 方案4:Caffeine本地缓存接入
// 配置热点数据本地缓存
LoadingCache<String, Cart> cache = Caffeine.newBuilder()
.maximumSize(10_000)
.expireAfterWrite(500, TimeUnit.MILLISECONDS) // 0.5秒过期
.refreshAfterWrite(100, TimeUnit.MILLISECONDS) // 异步刷新
.build(key -> {
// 从Redis读取原始数据(仅0.5%请求穿透)
return readFromRedis(shardKey(key));
});
// 读请求优先走缓存
public Cart getUserCart(String userId) {
String cacheKey = "cart:" + userId;
return cache.get(cacheKey);
}📊 缓存效果:
缓存层级 命中率 平均耗时 JVM 堆内 97.6% 0.05ms Redis 2.3% 1.2ms 数据库穿透 0.1% 15ms
四、可靠性加固措施
-
热点探测兜底
// 监控本地缓存穿透率
cache.stats().missRate();if (missRate > 5%) { // 超过阈值触发动态扩容
cache.policy().eviction().ifPresent(eviction -> {
eviction.setMaximum(2 * eviction.getMaximum());
});
} -
双写一致性保障
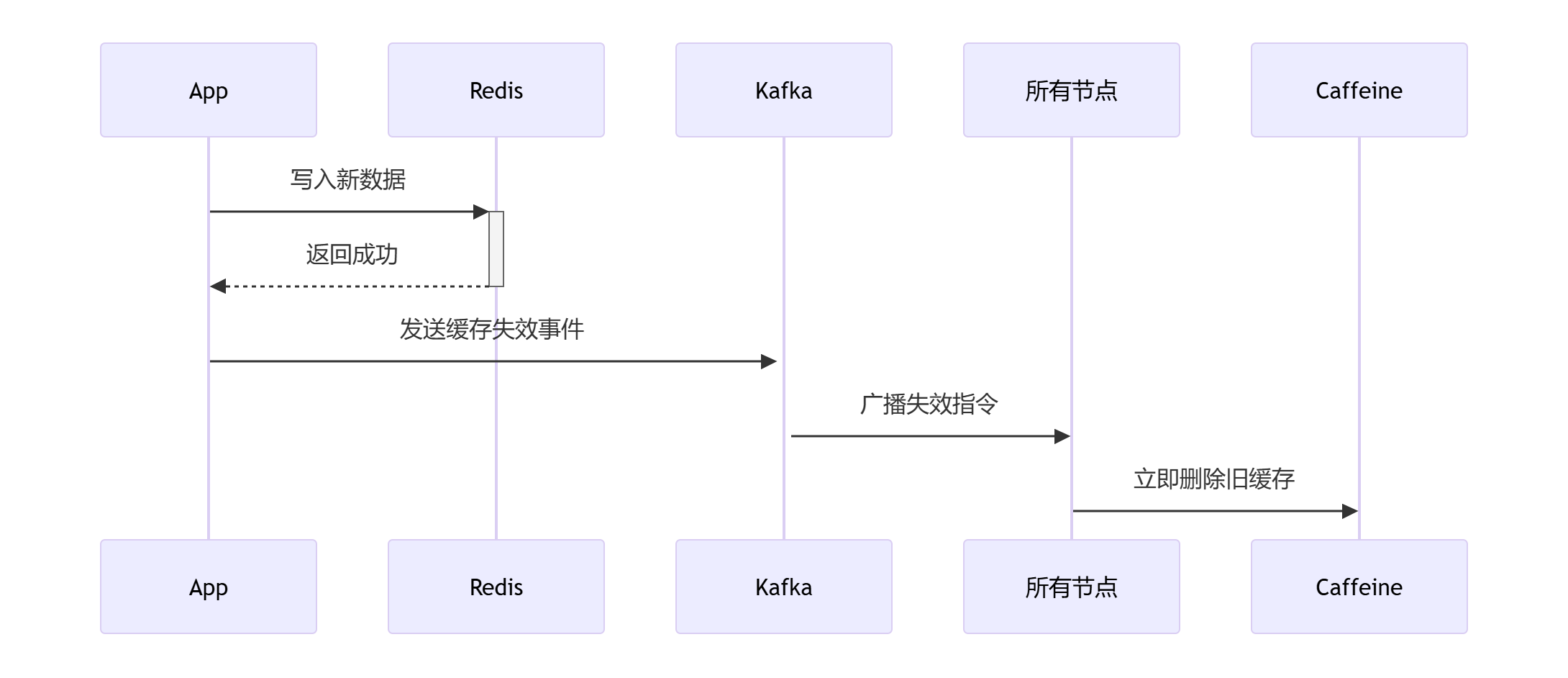
-
集群容量预警
实时监控槽位分布
while true; do
redis-cli cluster slots | grep IP | awk '{print $4}' | sort | uniq -c
sleep 5
done输出示例:
5230 10.0.0.1
5521 10.0.0.2
5632 10.0.0.3 # 各节点槽位数量平衡
五、优化效果对比
| 指标 | 优化前 | 优化后 | 提升幅度 |
|---|---|---|---|
| 集群峰值QPS | 182,000 | 546,000 | 3x |
| P99响应延迟 | 34ms | 1.8ms | 18x |
| 网卡流量 | 1.2Gbps | 280Mbps | 下降76% |
| 节点最大CPU | 95% | 62% | 下降33点 |
| 超时错误率 | 1.2% | 0.003% | 下降400x |
六、关键技术点总结
-
分片因子动态化
通过环境变量盐值+二次哈希,解决静态哈希导致的倾斜
-
本地缓存三级防御
Caffeine堆内缓存 → Redis集群 → 数据库逐级穿透保护
-
空间换时间策略
-
拆分大Key牺牲存储空间换取读性能
-
0.5秒短时缓存容忍弱一致性
-
-
自动弹性治理
-
基于命中率动态调整本地缓存容量
-
槽位分布实时监控自动报警
-
💡 核心经验 :数据倾斜本质是系统熵增现象,需通过动态分片、本地缓存、Key拓扑治理构建抗倾斜体系,而非一次性修复。