本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发学习视频及资料,尽在聚客AI学院。
人工智能大模型(如GPT、LLaMA等)已成为推动AI产业变革的核心引擎。其价值在于通过海量数据预训练提取通用知识,大幅提升模型泛化能力,降低微调成本。然而,大模型的开发涉及复杂的训练流程、高效的推理优化、激烈的市场竞争以及底层基础设施的严峻挑战。今天我将从大模型训练层、推理层、市场洞察及基础设施层四个维度,系统解析技术细节,希望对你们有所帮助,记得点个小红心支持一下。
第一部分:大模型训练层------构建模型能力的系统性工程
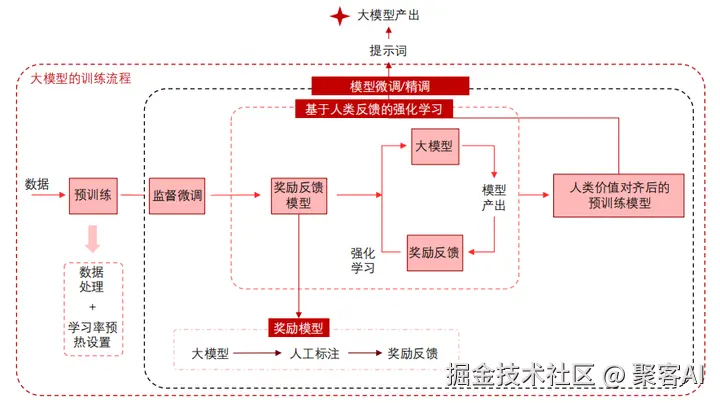
大模型训练是一个多阶段流程,核心目标是构建模型的基础能力并实现人类意图对齐。训练流程分为预训练、监督微调(SFT)、奖励模型训练和近端策略优化(PPO)强化学习。预训练阶段利用海量多样化语料(千亿至万亿级Token)提取深度语义表示,消耗总算力的90-99%,是资源最密集的阶段;后续微调阶段则通过少量标注数据优化模型,仅占1-10%算力,显著提升效率。
训练全流程框架:大模型训练始于预训练,处理原始语料以学习通用表示;接着进行监督微调,使模型适应特定任务;最后通过人类反馈强化学习(RLHF),包括奖励模型训练和PPO优化,确保生成内容的安全性、质量和人类偏好对齐。这一框架确保模型从基础能力到价值对齐的递进演进。
ps:由于文章篇幅有限,为了更好的帮大家理解大模型预训练微调,这里给粉丝朋友分享一个大模型微调实战项目思维导图,粉丝朋友自行领取:《大模型微调实战项目思维导图》
训练资源消耗与优化:预训练阶段是算力黑洞,需要数千至上万块GPU(如A100/H100)并行运算,处理TB级数据,耗时数周至数月。资源消耗主要包括:
- 算力:90-99%集中于预训练,因需处理高维参数和海量Token。
- 存储与数据:下载并处理数TB级文本语料,需高带宽存储系统。
- 时间成本:预训练周期长,微调阶段可缩短至几天。
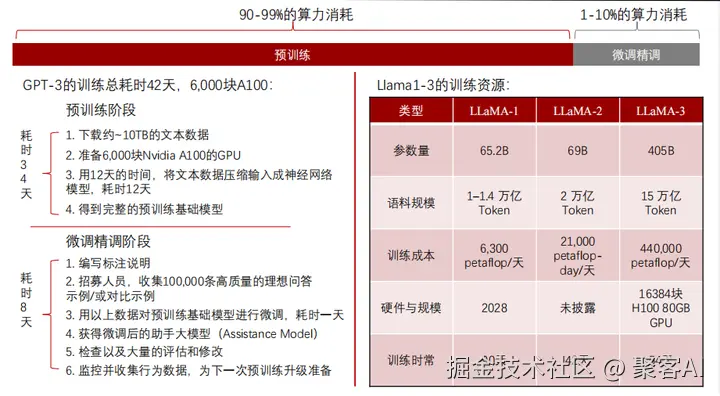
典型案例:
- GPT-3:在6,000块A100 GPU上耗时34天完成预训练,微调额外8天。
- LLaMA系列:LLaMA-1用2,028块GPU训练90天(1-1.4万亿Token);LLaMA-2在42天内处理2万亿Token;LLaMA-3动用16,384块H100 GPU,54天训练15万亿Token,凸显规模扩展趋势。
优化策略包括分布式训练(如模型并行、数据并行)、混合精度计算(FP16/FP8)以降低显存占用,以及高效数据管道减少I/O瓶颈。
强化学习对齐人类偏好:后训练阶段通过RLHF优化生成策略。监督微调使用高质量标注数据微调模型;奖励模型训练基于人工标注的偏好数据学习评分函数;PPO强化学习则迭代优化策略,使模型输出更安全、相关且符合人类价值观。这一流程显著提升对话质量和意图对齐,但需平衡多样性控制(如温度采样)与稳定性。
第二部分:大模型推理层------高效低延迟的生成引擎
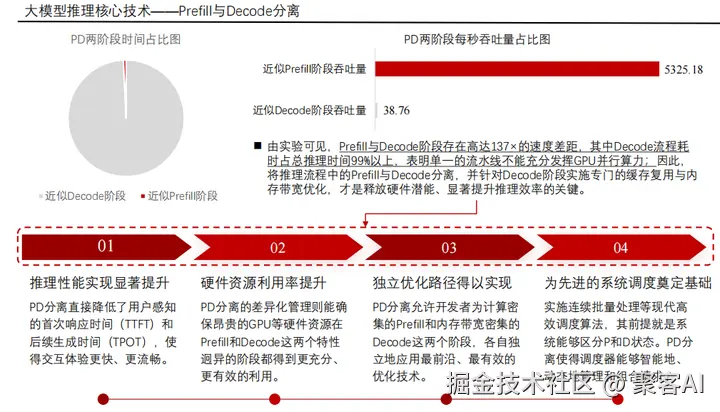
大模型推理是将训练好的模型应用于实时生成的关键阶段,核心挑战是降低延迟、提升吞吐率。推理流程分为输入处理、Transformer计算和后处理三部分,并依赖Prefill与Decode两阶段的解耦优化(PD分离技术)。
推理流程框架:输入文本先经分词和嵌入层转为向量,通过多层Transformer的自注意力机制计算。推理过程强调KV缓存技术,避免重复计算以加速生成。输出层生成词汇概率分布,后处理技术(如温度采样、Top-k/Top-p裁剪)调控多样性,确保语义连贯性。
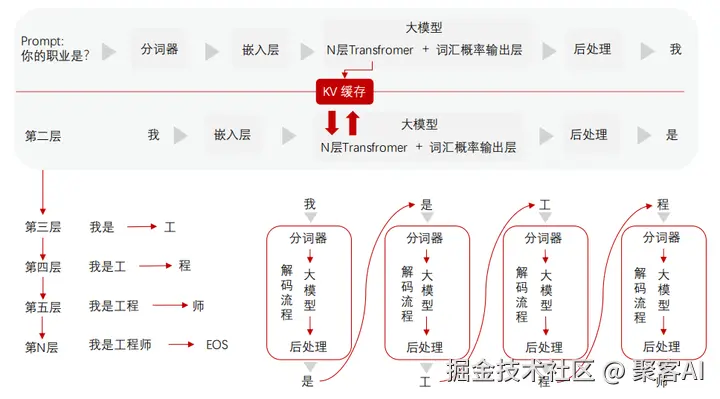
后处理技术:温度采样(Temperature Sampling)调节概率分布的平滑度,高温增加多样性,低温增强确定性;Top-k限制候选词数量,Top-p(Nucleus Sampling)动态选择概率累积超过阈值的词集,平衡生成质量与稳定性。参数典型设置:温度0.7-1.0,Top-p 0.9。

核心阶段:Prefill与Decode:
- Prefill阶段:一次性并行处理所有输入Token,构建完整的KV缓存,实现上下文"速读"。此阶段GPU计算密集,需最大化并行吞吐。
- Decode阶段:自回归逐Token生成输出,依赖KV缓存实现增量推理,类似"逐字成文"。此阶段内存带宽敏感,延迟占推理总时间99%以上。
两阶段特性对比:
- Prefill:批量请求合并,模型并行切分Transformer层至多GPU。
- Decode:Flash Attention优化注意力计算,多查询注意力(MQA)降低显存占用。
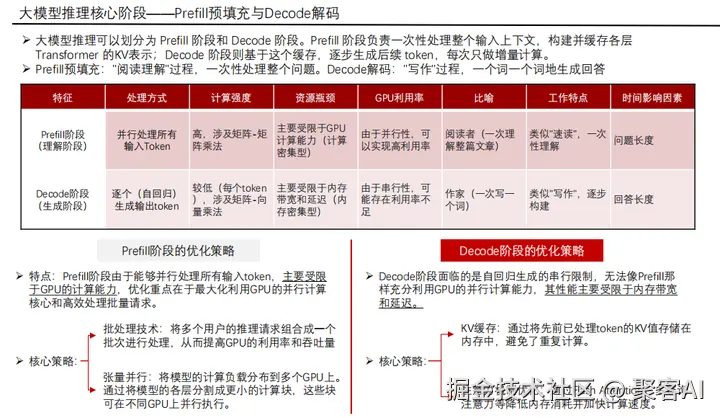
PD分离技术:传统一体化流程导致Decode阶段GPU利用率低下。PD分离将Prefill与Decode解耦:
- Prefill优化:批量调度请求,利用GPU并行能力缩短首次响应时间(TTFT)。
- Decode优化:专用流水线结合KV缓存,提升后续Token生成速率(TPOT)。
该技术显著降低延迟,提升吞吐率50%以上,并为智能资源调度奠定基础。
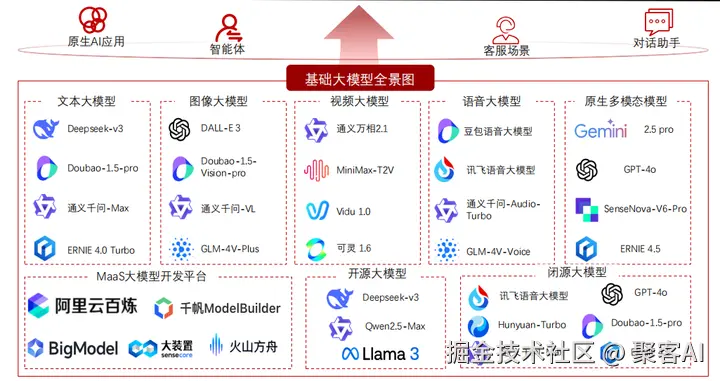
第三部分:基础大模型市场洞察------技术趋同与路径分化
全球大模型产业呈现"技术终局趋同,商业路径分化"的格局。所有头部厂商(如OpenAI、Google、Meta、中国厂商)均以原生多模态为演进目标,但商业化路径分裂为闭源与开源两大阵营。
全景图谱:技术终局指向统一处理文本、视觉、听觉的多模态模型,如GPT-4o和Gemini,这些模型通过跨模态融合提升理解与生成能力。市场分化表现为:
- 闭源平台路径:构建高价值商业闭环,如OpenAI的API服务和Google Cloud集成,强调安全性和企业级支持。
- 开源普惠路径:Llama、Qwen、Deepseek等通过开放模型权重,构建开发者社区,降低入门门槛。
市场集中度加剧,调用量向具备云基础设施(如AWS、Azure)和海量应用场景(如搜索引擎、智能助理)的头部厂商归拢。
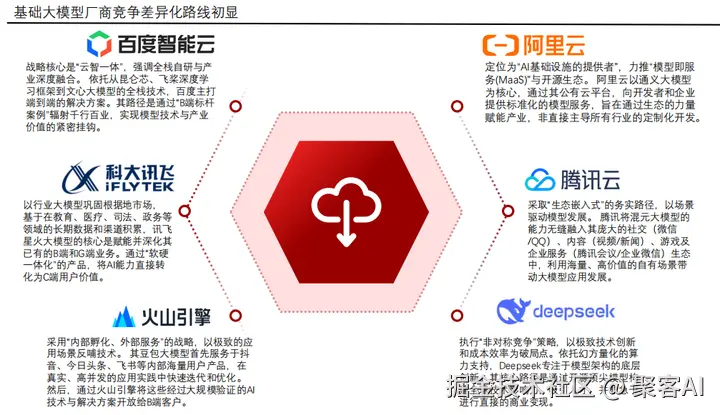
厂商差异化竞争:告别同质化内卷,厂商基于核心禀赋展开战略竞争:
- 闭源阵营:聚焦高精度API服务、垂直行业解决方案。
- 开源阵营:通过社区生态和定制化微调工具链吸引长尾开发者。
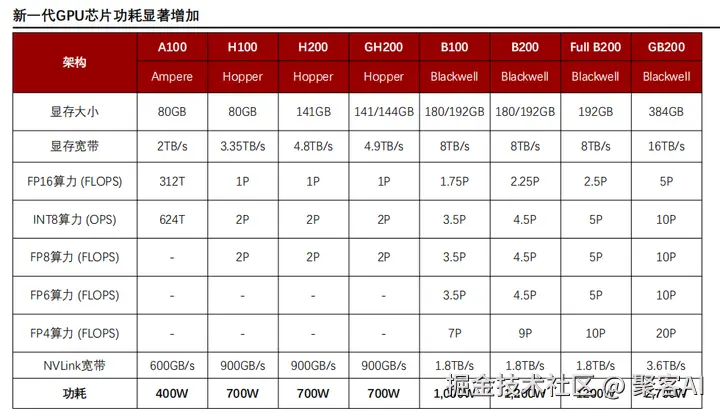
第四部分:大模型基础设施层------算力硬件的演进与挑战
大模型依赖的智算中心(AI数据中心)是一个多系统协同的复杂体系,核心是支撑高密度GPU集群的运行。新一代GPU和服务器以极限功耗和互联带宽为特征,推动基础设施重构。
智算中心基础构成:包括供配电(双路冗余UPS)、制冷(液冷系统为主)、机柜(高密度部署)、防雷防火等子系统,确保99.99%可用性。核心设计原则是高能效比和可扩展性。

GPU芯片演进与功耗挑战:NVIDIA架构从Ampere(A100)到Hopper(H100/H200)再到Blackwell(B100/B200/GB200),标志AI算力向精度可变和带宽扩展跃迁:
- 算力指标:FP8/FP6低精度性能指数级增长(如Blackwell FP4算力达10 PetaFLOPS),优化推理效率。
- 互联带宽:显存带宽从A100的2TB/s提升至GB200的16TB/s,NVLink达3.6TB/s,缓解分布式训练瓶颈。
- 功耗激增:单芯片功耗从A100的400W增至GB200的2700W,对散热和供电提出极限要求。
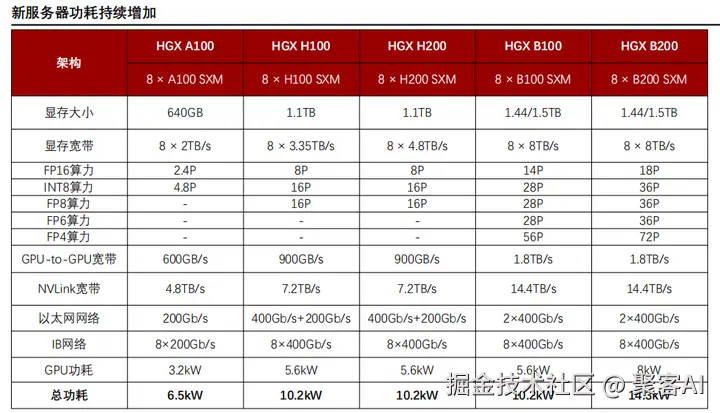
AI服务器功耗与重构:HGX服务器从A100到B100/B200的迭代,体现"高精度异构算力+极限互联"趋势:
- 性能提升:低精度算力(FP8/FP6)主导设计,NVLink带宽翻倍。
- 功耗跃升:单节点总功耗从6.5kW增至14.3kW,推动液冷散热和48V直流供电系统普及。
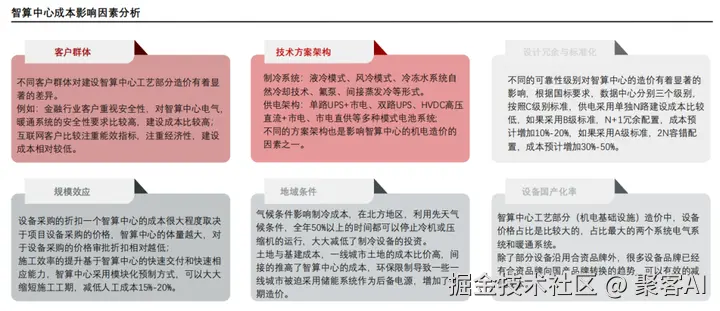
成本影响因素包括客户需求(如冗余等级)、技术方案(液冷vs.风冷)、规模效应和区位(电价差异),智算中心造价高度定制化。
作者结语
大模型技术已进入系统化成熟期:训练层通过预训练与RLHF实现能力对齐;推理层依托PD分离和缓存优化实现高效生成;市场层在技术趋同下分化出闭源与开源双轨;基础设施层则面临GPU功耗与服务器密度的严峻挑战,驱动液冷和智能调度创新。未来,大模型开发将更注重端到端能效优化,开发者需平衡算力成本、延迟要求及生态适配性。持续关注低精度计算、分布式训练框架(如Megatron-DeepSpeed)和开源社区工具链,将是提升竞争力的关键。好了,今天的分享就到这里,点个小红心,我们下期见。