在当今 AI 快速发展的时代,单纯的问答式 AI 已经无法满足复杂业务需求。企业需要的是能够自主思考、规划和执行的智能体 Agent。LangGraph 作为 LangChain 生态中的图形工作流框架,为我们构建这样的智能体提供了强大的基础设施。
前言
还记得我第一次接触 AI 聊天机器人时,那种"一问一答"的交互方式总是让人感觉缺少了点儿些什么。它们就像是训练有素的客服,能回答预设的问题,但面对复杂的业务场景却显得力不从心了。
真正的智能体应该像一个经验丰富的助手,能够理解复杂需求、制定执行计划、调用各种工具完成任务,甚至在必要时主动寻求人工确认。这就是 LangGraph 要解决的核心问题,让 AI 从简单的"应答者"升级为复杂的"执行者"。
企业级 Agent 开发实战(一) LangGraph 快速入门
企业级 Agent 开发实战(三) 智能运维 Agent 开发
该系列文章最终会实现一个智能运维分析 Agent ,效果如下:
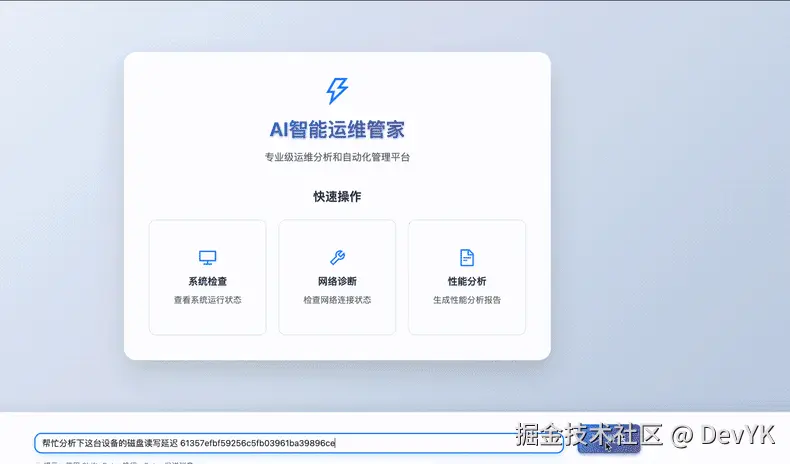
文章中完整的示例代码: github.com/yangkun1992...
一、什么是LangGraph?核心概念解析
1.1 从线性对话到图形工作流
传统的 AI 应用往往是线性的:用户输入 → AI处理 → 返回结果。但现实世界的问题往往需要多步骤、有条件的决策过程。
LangGraph将这个过程抽象为一个有向图,其中:
- 节点(Nodes) 代表具体的处理逻辑
- 边(Edges) 定义数据流向和执行顺序
- 状态(State) 在节点间传递状态数据和更新数据
通过组合 Nodes 和 Edges ,我们可以创建复杂的循环工作流,使状态随时间推移而演变。然而,真正的强大之处在于 LangGraph 的状态管理方式。需要强调的是:Nodes 和 Edges 仅仅是函数而已,它们可以包含 LLM 代码,也可以只是一些普通的代码。
简而言之:节点负责工作,边负责告诉下一步做什么, 状态就是共享的数据。
这种设计可以让我们能够构建真正的"思考链":
python
from langgraph.graph import StateGraph, END
from typing_extensions import TypedDict
class AgentState(TypedDict):
task: str
steps_completed: list
current_step: str
result: str
# 创建状态图
workflow = StateGraph(AgentState)
....
workflow.compile(...)1.2 状态管理:智能体的"记忆系统"
状态 (State) 是 LangGraph 的核心概念之一。它不仅仅是数据的载体,更像是智能体的"工作记忆"。想象一下,一个优秀的项目经理在推进项目时,脑中会保持对当前进度、待办事项、遇到问题的清晰认知。
python
class ProjectState(TypedDict):
requirements: str # 项目需求
current_phase: str # 当前阶段
completed_tasks: list # 已完成任务
issues: list # 遇到的问题
team_feedback: str # 团队反馈状态在节点间流转时会被更新和丰富,形成了智能体的"思考轨迹"。
二、图形API:构建智能体的蓝图
2.1 节点设计:分而治之的智慧
每个节点都代表一个具体的功能模块。好的节点设计遵循单一职责原则,让复杂的业务逻辑变得清晰可维护。
python
def analyze_requirements(state: ProjectState) -> ProjectState:
"""需求分析节点"""
requirements = state["requirements"]
# 使用LLM分析需求
llm = get_llm()
analysis = llm.invoke(f"分析项目需求: {requirements}")
return {
**state,
"current_phase": "需求分析",
"completed_tasks": state["completed_tasks"] + ["需求分析完成"]
}
def create_plan(state: ProjectState) -> ProjectState:
"""制定计划节点"""
# 基于分析结果制定详细计划
return {
**state,
"current_phase": "计划制定"
}2.2 边的艺术:控制执行流程
LangGraph提供了灵活的边定义方式,让我们能够实现复杂的条件逻辑:
python
def should_seek_approval(state: ProjectState) -> str:
"""条件边:决定是否需要审批"""
if "高风险" in state.get("issues", []):
return "human_review"
else:
return "auto_proceed"
# 添加条件边
workflow.add_conditional_edges(
"analyze_requirements",
should_seek_approval,
{
"human_review": "wait_for_approval",
"auto_proceed": "create_plan"
}
)这种设计让智能体能够根据实际情况动态调整执行路径,就像一个有经验的专家会根据具体情况灵活应对。
2.3 编译与执行:让图"活"起来
定义好图结构后,需要编译成可执行的应用:
makefile
# 构建完整的工作流
workflow.add_node("analyze", analyze_requirements)
workflow.add_node("plan", create_plan)
workflow.set_entry_point("analyze")
workflow.add_edge("plan", END)
# 编译成可执行应用
app = workflow.compile()
# 执行工作流
result = app.invoke({
"requirements": "开发一个客户关系管理系统",
"steps_completed": [],
"current_step": "",
"result": ""
})三、流式传输:实时感知智能体思考
3.1 为什么需要流式传输?
想象一下,如果你委托一个助手处理复杂任务,你肯定希望能够实时了解进展,而不是苦苦等待最终结果。流式传输正是为了解决这个问题。
LangGraph 提供了多种流式传输模式,让我们能够从不同角度观察智能体的执行过程。
3.2 支持的流式传输模式
LangGraph 截止目前支持以下几种流式传输模式:
| 模式 | 描述 | 适用场景 |
|---|---|---|
values |
流式传输每个步骤后的完整状态 | 需要查看完整状态变化时 |
updates |
流式传输每个步骤的状态更新 | 需要追踪状态变化增量时 |
messages |
流式传输LLM生成的token和元数据 | 需要实时显示AI生成内容时 |
custom |
流式传输自定义数据 | 需要传输工具执行进度等自定义信息时 |
debug |
流式传输尽可能多的调试信息 | 调试和故障排除时 |
3.3 values模式:观察完整状态
bash
# 流式获取完整状态
for chunk in app.stream(initial_state, stream_mode="values"):
print("📊 当前完整状态:", chunk)这种模式让你能够看到每个节点执行后的完整状态,就像是给智能体拍快照。
3.4 updates模式:追踪状态变化
ini
# 流式获取状态更新
for chunk in app.stream(initial_state, stream_mode="updates"):
node_name = list(chunk.keys())[0]
update_data = chunk[node_name]
print(f"🔄 节点 {node_name} 更新: {update_data}")这种模式只显示状态的变化部分,更加高效,适合追踪具体的更新。
3.5 messages模式:实时显示AI生成内容
ini
# 流式获取LLM token
for message_chunk, metadata in app.stream(
initial_state,
stream_mode="messages"
):
if message_chunk.content:
print(message_chunk.content, end="", flush=True)
print(f"\n元数据: {metadata}")这种模式让用户能够看到AI"思考"的过程,token一个个地生成,就像我们在打字一样,这种交互方式目前最推荐使用,交互效果最好。
3.6 custom模式:传输自定义数据
python
from langgraph.config import get_stream_writer
def progress_tool(query: str) -> str:
"""一个展示进度的工具"""
writer = get_stream_writer()
for i in range(1, 6):
writer(f"处理进度: {i*20}%")
time.sleep(1) # 模拟处理时间
return "处理完成"
# 流式获取自定义数据
for chunk in app.stream(initial_state, stream_mode="custom"):
print(f"📈 进度更新: {chunk}")3.7 多模式组合:全方位监控
python
# 同时使用多种模式
for mode, chunk in app.stream(
initial_state,
stream_mode=["updates", "messages", "custom"]
):
if mode == "updates":
print(f"🔄 状态更新: {chunk}")
elif mode == "messages":
print(f"💬 消息: {chunk[0].content}")
elif mode == "custom":
print(f"📈 自定义数据: {chunk}")四、记忆系统:构建有历史的智能体
记忆是智能体区别于简单聊天机器人的关键特征。LangGraph 提供了完整的记忆系统,包括短期记忆和长期记忆两种类型,并支持多种持久化存储方案。
4.1 短期记忆:线程级的对话上下文
短期记忆在LangGraph中通过线程级(thread-scoped)状态实现,能够在单个对话线程中保持上下文。这就像人类的工作记忆,能够记住当前对话的内容和背景。
4.1.1 持久化存储配置
线上企业级的应用需要真正的持久化存储。LangGraph支持多种存储后端:
python
from langgraph.checkpoint.sqlite import SqliteSaver
from langgraph.checkpoint.postgres import PostgresSaver
from langgraph.checkpoint.memory import InMemorySaver, MemorySaver
from langgraph.store.sqlite import SqliteStore
from langgraph.store.postgres import PostgresStore
from langgraph.store.memory import InMemoryStore
import os
class MemoryStorageManager:
"""记忆存储管理器 - 支持多种持久化存储"""
def __init__(self, environment: str = "development"):
self.environment = environment
self.storage_type = os.getenv("MEMORY_STORAGE_TYPE", "sqlite").lower()
self.db_path = os.getenv("MEMORY_DB_PATH", "./data/memory.db")
self.postgres_url = os.getenv("POSTGRES_URL", "postgresql://user:password@localhost:5432/langgraph_memory")
# 确保数据目录存在
os.makedirs(os.path.dirname(self.db_path), exist_ok=True)
self._setup_storage()
def _setup_storage(self):
"""根据环境和配置设置存储"""
if self.storage_type == "postgres" and self.environment == "production":
# 生产环境使用PostgreSQL
self._sqlite_saver_cm = PostgresSaver.from_conn_string(self.postgres_url)
self.short_term_storage = self._sqlite_saver_cm.__enter__()
self._sqlite_store_cm = PostgresStore.from_conn_string(self.postgres_url)
self.long_term_storage = self._sqlite_store_cm.__enter__()
elif self.storage_type == "sqlite":
# 使用SQLite持久化存储
self._sqlite_saver_cm = SqliteSaver.from_conn_string(self.db_path)
self.short_term_storage = self._sqlite_saver_cm.__enter__()
self._sqlite_store_cm = SqliteStore.from_conn_string(self.db_path)
self.long_term_storage = self._sqlite_store_cm.__enter__()
else:
# 开发/测试环境使用内存存储
self.short_term_storage = InMemorySaver()
self.long_term_storage = InMemoryStore()
# 使用示例
storage_manager = MemoryStorageManager("production")
# 编译时启用持久化
app = workflow.compile(
checkpointer=storage_manager.short_term_storage,
store=storage_manager.long_term_storage
)
# 带会话ID的执行
config = {"configurable": {"thread_id": "user_123_session"}}
result = app.invoke({
"messages": [{"role": "user", "content": "你好,我是张三"}]
}, config)
# 继续对话,智能体会记住之前的内容
result2 = app.invoke({
"messages": [{"role": "user", "content": "我刚才说我叫什么?"}]
}, config)4.1.2 环境变量配置
通过环境变量灵活配置存储类型:
ini
# .env 文件配置
MEMORY_STORAGE_TYPE=sqlite # 存储类型: sqlite, postgres, memory
MEMORY_DB_PATH=./data/memory.db # SQLite数据库路径
POSTGRES_URL=postgresql://user:password@localhost:5432/langgraph_memory # PostgreSQL连接字符串4.1.2 多用户会话管理
在企业环境中,同一个智能体需要同时为多个用户服务。通过不同的thread_id,我们可以实现完全隔离的会话管理。
ini
# 用户A的对话
user_a_config = {"configurable": {"thread_id": "user_a_session"}}
result_a = app.invoke(user_a_messages, user_a_config)
# 用户B的对话(完全独立)
user_b_config = {"configurable": {"thread_id": "user_b_session"}}
result_b = app.invoke(user_b_messages, user_b_config)4.1.3 对话历史管理
当对话变得很长时,我们需要管理对话历史以平衡性能和记忆效果:
python
def trim_conversation(state: MessagesState) -> MessagesState:
"""修剪对话历史,保留最近的重要消息"""
messages = state["messages"]
# 保留系统消息和最近10轮对话
system_messages = [msg for msg in messages if msg.type == "system"]
recent_messages = messages[-20:] # 最近10轮(每轮2条消息)
return {
"messages": system_messages + recent_messages
}4.2 长期记忆:跨对话的知识积累
长期记忆让智能体能够跨多个对话线程共享信息,形成持续的学习和个性化能力。
4.2.1 Store机制:知识的组织与存储
LangGraph的长期记忆通过Store机制实现,与短期记忆的Checkpointer不同,Store专门用于跨会话的数据持久化。
python
def save_user_preference(state, config, *, store):
"""保存用户偏好到长期记忆"""
user_id = config["configurable"]["user_id"]
namespace = ("user_preferences", user_id)
last_message = state["messages"][-1].content
if "我喜欢" in last_message:
# 提取偏好信息
preference = last_message.replace("我喜欢", "").strip()
store.put(namespace, "preference", {
"preference": preference,
"timestamp": datetime.now().isoformat()
})
print(f"已保存用户偏好: {preference}")
return state
def retrieve_user_preference(state, config, *, store):
"""检索用户偏好"""
user_id = config["configurable"]["user_id"]
namespace = ("user_preferences", user_id)
try:
preference_data = store.get(namespace, "preference")
if preference_data:
preference = preference_data.value["preference"]
print(f"检索到用户偏好: {preference}")
return {
**state,
"user_preference": preference
}
except Exception as e:
print(f"检索偏好失败: {e}")
return state
# 使用示例
storage_manager = MemoryStorageManager("development")
# 显示存储配置信息
storage_info = storage_manager.get_storage_info()
print("📊 存储配置信息:")
for key, value in storage_info.items():
if value:
print(f" • {key}: {value}")
print("\n💡 提示: 可通过环境变量配置存储类型:")
print(" • MEMORY_STORAGE_TYPE=sqlite (默认)")
print(" • MEMORY_STORAGE_TYPE=postgres")
print(" • MEMORY_STORAGE_TYPE=memory")4.2.2 语义搜索:智能的记忆检索
什么是语义搜索?
传统的关键词搜索只能找到包含特定词汇的内容,而语义搜索能够理解内容的含义。例如,当用户询问"我上次说的那个项目怎么样了?"时,语义搜索可以找到之前关于"软件开发项目"、"产品迭代计划"等相关的记忆,即使这些记忆中没有直接包含"项目"这个词。
为什么需要语义搜索?
在企业级智能体应用中,用户的表达方式多样化,同一个概念可能有多种表述。语义搜索让智能体能够:
- 理解同义词:将"客户"、"用户"、"消费者"视为相关概念
- 跨语言理解:支持中英文混合的记忆检索
- 上下文关联:基于语义相似性找到相关的历史对话
- 智能推荐:主动提供可能相关的背景信息
python
from langchain_openai import OpenAIEmbeddings
# 创建支持语义搜索的存储(生产环境推荐使用数据库存储)
embeddings = OpenAIEmbeddings()
# 生产环境配置
if os.getenv("ENVIRONMENT") == "production":
store = PostgresStore.from_conn_string(
"postgresql://user:password@localhost:5432/langgraph_memory",
embedding_function=embeddings
)
else:
# 开发环境配置(注意:InMemoryStore重启后数据丢失)
store = InMemoryStore(embedding_function=embeddings)
def retrieve_relevant_memories(state, config, *, store):
"""检索相关的长期记忆"""
user_id = config["configurable"]["user_id"]
namespace = ("user_memories", user_id)
# 基于当前消息内容搜索相关记忆
current_query = state["messages"][-1].content
print(f"正在搜索与 '{current_query}' 相关的记忆...")
relevant_memories = store.search(
namespace,
query=current_query,
limit=5 # 返回最相关的5条记忆
)
# 将相关记忆添加到上下文中
memory_context = "\n".join([
f"相关记忆 {i+1}: {item.value['content']} (相关度: {item.score:.2f})"
for i, item in enumerate(relevant_memories)
])
print(f"找到 {len(relevant_memories)} 条相关记忆")
return {
**state,
"memory_context": memory_context
}
def semantic_memory_search_example():
"""4.2.2 语义搜索示例"""
print("\n=== 4.2.2 语义搜索演示 ===")
# 模拟存储一些记忆
sample_memories = [
{"content": "用户张三是软件工程师,喜欢Python编程", "topic": "personal_info"},
{"content": "张三正在开发一个电商网站项目", "topic": "project"},
{"content": "项目使用Django框架和PostgreSQL数据库", "topic": "technology"},
{"content": "用户对机器学习和AI技术很感兴趣", "topic": "interests"},
{"content": "张三的团队有5个人,采用敏捷开发模式", "topic": "team"}
]
print("📝 已存储的记忆内容:")
for i, memory in enumerate(sample_memories, 1):
print(f" {i}. {memory['content']}")
# 模拟不同的查询
test_queries = [
"张三是做什么工作的?", # 应该找到个人信息
"他在开发什么产品?", # 应该找到项目相关
"用什么技术栈?", # 应该找到技术相关
"团队规模如何?", # 应该找到团队信息
"对人工智能有什么看法?" # 应该找到兴趣相关
]
print("\n🔍 语义搜索测试:")
for query in test_queries:
print(f"\n查询: '{query}'")
print("预期会找到的相关记忆:")
# 这里是模拟语义搜索的结果
if "工作" in query or "做什么" in query:
print(" ✅ 用户张三是软件工程师,喜欢Python编程")
elif "产品" in query or "开发什么" in query:
print(" ✅ 张三正在开发一个电商网站项目")
elif "技术" in query:
print(" ✅ 项目使用Django框架和PostgreSQL数据库")
elif "团队" in query:
print(" ✅ 张三的团队有5个人,采用敏捷开发模式")
elif "人工智能" in query or "AI" in query:
print(" ✅ 用户对机器学习和AI技术很感兴趣")
print("\n💡 语义搜索的优势:")
print(" • 即使查询词与记忆内容不完全匹配,也能找到相关信息")
print(" • 支持自然语言查询,用户体验更好")
print(" • 能够理解概念之间的关联性")
print(" • 提供相关度评分,帮助排序结果")4.2.3 记忆的类型与组织
什么是记忆类型?
在认知科学中,人类的长期记忆被分为几种不同类型,每种类型存储不同性质的信息。在企业级智能体中,我们可以借鉴这种分类方法来更好地组织和管理智能体的记忆。
为什么要区分记忆类型?
不同类型的记忆有不同的特点和用途:
- 检索方式不同:有些记忆需要精确匹配,有些需要模糊查找
- 更新频率不同:事实性信息相对稳定,经历性信息经常变化
- 应用场景不同:个性化推荐需要偏好信息,问题解决需要经验模式
4.2.3.1 语义记忆:事实性知识
语义记忆存储的是客观事实和概念性知识,这类信息通常比较稳定,不会频繁变化。
适用场景:
- 用户基本信息(姓名、职业、联系方式)
- 业务规则和政策
- 产品功能和技术规格
- 组织架构和人员关系
python
def store_semantic_memory_example():
"""语义记忆存储示例"""
print("\n=== 4.2.3.1 语义记忆:事实性知识 ===")
# 用户基本信息
user_facts = {
"name": "张三",
"occupation": "软件工程师",
"department": "技术部",
"level": "高级工程师",
"preferences": {
"communication_style": "简洁直接",
"language": "中文",
"notification_time": "09:00-18:00"
},
"skills": ["Python", "JavaScript", "数据库设计", "系统架构"]
}
# 存储到语义记忆命名空间
# store.put(("semantic", user_id), "user_profile", user_facts)
print("📋 存储的语义记忆:")
print(f" • 基本信息: {user_facts['name']} - {user_facts['occupation']}")
print(f" • 沟通偏好: {user_facts['preferences']['communication_style']}")
print(f" • 技能标签: {', '.join(user_facts['skills'])}")
# 业务规则示例
business_rules = {
"approval_limit": {
"junior": 1000,
"senior": 10000,
"manager": 50000
},
"working_hours": "09:00-18:00",
"emergency_contact": "IT Support: ext-911"
}
# store.put(("semantic", "business"), "rules", business_rules)
print("💼 业务规则记忆:")
print(f" • 审批权限: 高级工程师可审批 {business_rules['approval_limit']['senior']} 元以下")
print(f" • 工作时间: {business_rules['working_hours']}")4.2.3.2 情节记忆:具体经历
情节记忆存储的是具体的事件和经历,包含时间、地点、参与者和发生的事情等详细信息。
适用场景:
- 用户的历史对话记录
- 重要的业务事件
- 问题处理过程
- 决策制定经过
python
def store_episodic_memory_example():
"""情节记忆存储示例"""
print("\n=== 4.2.3.2 情节记忆:具体经历 ===")
# 具体的交互经历
episode_1 = {
"timestamp": "2025-01-15T10:30:00",
"context": "用户咨询项目进度",
"participants": ["张三", "项目经理AI"],
"action": "提供了详细的进度报告",
"outcome": "用户表示满意",
"details": {
"project_name": "电商网站重构",
"completion_rate": "75%",
"next_milestone": "2025-01-20"
}
}
episode_2 = {
"timestamp": "2025-01-16T14:20:00",
"context": "技术问题求助",
"participants": ["张三", "技术支持AI"],
"action": "协助解决数据库连接问题",
"outcome": "问题已解决",
"details": {
"problem_type": "数据库连接超时",
"solution": "调整连接池配置",
"resolution_time": "30分钟"
}
}
episodes = [episode_1, episode_2]
print("📅 存储的情节记忆:")
for i, episode in enumerate(episodes, 1):
print(f"\n 情节 {i}:")
print(f" 时间: {episode['timestamp']}")
print(f" 场景: {episode['context']}")
print(f" 行动: {episode['action']}")
print(f" 结果: {episode['outcome']}")
# 模拟存储
episode_id = f"episode_{episode['timestamp']}"
# store.put(("episodic", user_id), episode_id, episode)
print("\n💡 情节记忆的价值:")
print(" • 帮助智能体了解用户的历史需求模式")
print(" • 为类似问题提供解决方案参考")
print(" • 建立用户与系统的交互历史档案")4.2.3.3 程序记忆:操作方式
程序记忆存储的是操作方法和处理模式,是智能体积累的"经验知识"。
适用场景:
- 成功的问题解决方案
- 有效的沟通模式
- 优化的工作流程
- 最佳实践和技巧
python
def store_procedural_memory_example():
"""程序记忆存储示例"""
print("\n=== 4.2.3.3 程序记忆:操作方式 ===")
# 成功的处理模式
procedure_1 = {
"situation": "用户询问技术问题",
"approach": [
"1. 确认具体的技术栈和环境",
"2. 询问错误信息和复现步骤",
"3. 提供分步骤解决方案",
"4. 确认问题是否解决"
],
"effectiveness": "高",
"success_rate": 0.9,
"avg_resolution_time": "15分钟"
}
procedure_2 = {
"situation": "用户需要项目进度信息",
"approach": [
"1. 识别具体的项目名称",
"2. 查询最新的进度数据",
"3. 提供关键里程碑和时间节点",
"4. 主动提及潜在风险或延期因素"
],
"effectiveness": "高",
"success_rate": 0.95,
"avg_satisfaction": 4.7
}
procedures = [procedure_1, procedure_2]
print("🔧 存储的程序记忆:")
for i, procedure in enumerate(procedures, 1):
print(f"\n 处理模式 {i}:")
print(f" 适用场景: {procedure['situation']}")
print(f" 处理步骤:")
for step in procedure['approach']:
print(f" {step}")
print(f" 有效性: {procedure['effectiveness']} (成功率: {procedure.get('success_rate', 'N/A')})")
# 模拟存储
procedure_id = f"procedure_{i}"
# store.put(("procedural", user_id), procedure_id, procedure)
print("\n💪 程序记忆的优势:")
print(" • 提高问题解决的效率和一致性")
print(" • 积累和传承最佳实践")
print(" • 支持智能体的自我优化和学习")
print(" • 为新场景提供经验参考")
# 综合示例:如何在实际应用中使用不同类型的记忆
def integrated_memory_usage_example():
"""综合记忆使用示例"""
print("\n=== 4.2.3.4 综合记忆应用场景 ===")
print("🎯 场景:用户张三再次询问技术问题")
print("\n1️⃣ 检索语义记忆 - 了解用户背景:")
print(" ✅ 张三是高级软件工程师,擅长Python和JavaScript")
print(" ✅ 偏好简洁直接的沟通方式")
print("\n2️⃣ 检索情节记忆 - 回顾历史交互:")
print(" ✅ 上次帮助解决了数据库连接问题")
print(" ✅ 用户对技术解决方案接受度高")
print("\n3️⃣ 应用程序记忆 - 选择处理方式:")
print(" ✅ 采用技术问题处理模式")
print(" ✅ 直接询问技术细节,跳过基础解释")
print("\n🚀 智能体响应:")
print(" '张三,我看到你遇到了新的技术问题。'")
print(" '基于你的技术背景,我直接为你提供解决方案。'")
print(" '请告诉我具体的错误信息和当前的技术栈配置。'")
print("\n💡 记忆协同的价值:")
print(" • 个性化的交互体验")
print(" • 更高效的问题解决")
print(" • 持续优化的服务质量")4.3 记忆系统的最佳实践
4.3.1 存储选择策略
选择合适的存储机制对记忆系统的性能和可靠性至关重要:
python
class MemoryStorageManager:
"""记忆存储管理器"""
def __init__(self, environment: str = "development"):
self.environment = environment
self.short_term_storage = None # Checkpointer
self.long_term_storage = None # Store
self._setup_storage()
def _setup_storage(self):
"""根据环境配置存储"""
if self.environment == "production":
# 生产环境:使用数据库持久化
from langgraph.checkpoint.postgres import PostgresSaver
from langgraph.store.postgres import PostgresStore
db_url = os.getenv("DATABASE_URL")
# 短期记忆:会话状态持久化
self.short_term_storage = PostgresSaver.from_conn_string(db_url)
# 长期记忆:跨会话数据持久化
self.long_term_storage = PostgresStore.from_conn_string(
db_url,
embedding_function=OpenAIEmbeddings()
)
elif self.environment == "development":
# 开发环境:快速测试
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.store.memory import InMemoryStore
self.short_term_storage = InMemorySaver()
self.long_term_storage = InMemoryStore(
embedding_function=OpenAIEmbeddings()
)
elif self.environment == "testing":
# 测试环境:可控的临时存储
from langgraph.checkpoint.sqlite import SqliteSaver
from langgraph.store.memory import InMemoryStore
self.short_term_storage = SqliteSaver.from_conn_string(":memory:")
self.long_term_storage = InMemoryStore()
# 使用示例
storage_manager = MemoryStorageManager(os.getenv("ENVIRONMENT", "development"))
app = workflow.compile(
checkpointer=storage_manager.short_term_storage,
store=storage_manager.long_term_storage
)4.3.2 记忆更新策略
什么是记忆更新策略?
记忆更新策略决定了智能体如何从新的交互中学习并更新已有的记忆。好的更新策略能够确保记忆系统既能保持准确性,又能适应变化。
为什么需要记忆更新策略?
- 信息的时效性:用户的偏好、状态可能会发生变化
- 知识的完善性:新的交互可能补充或纠正已有信息
- 系统的学习性:智能体需要从经验中不断优化表现
- 存储的效率性:避免重复和冗余的记忆条目
4.3.2.1 增量更新策略
python
def update_memory_background(conversation_history, user_id, store):
"""在后台更新记忆,不影响对话流程"""
print("\n=== 4.3.2.1 增量更新策略演示 ===")
# 分析对话,提取重要信息
important_facts = extract_facts(conversation_history)
print(f"📊 从对话中提取到 {len(important_facts)} 条重要信息")
# 更新或创建新的记忆条目
for fact in important_facts:
namespace = ("semantic", user_id)
existing = store.get(namespace, fact["key"])
if existing:
print(f"🔄 更新已存在的记忆: {fact['key']}")
# 合并新旧信息
updated_fact = merge_facts(existing.value, fact)
store.put(namespace, fact["key"], updated_fact)
else:
print(f"➕ 创建新的记忆条目: {fact['key']}")
# 创建新记忆
store.put(namespace, fact["key"], fact)
def extract_facts(conversation_history):
"""从对话历史中提取重要事实"""
# 这里是简化的示例,实际应用中可能使用NLP技术
facts = []
for message in conversation_history:
content = message.get("content", "")
# 提取用户偏好
if "我喜欢" in content:
preference = content.split("我喜欢")[1].strip()
facts.append({
"key": "user_preferences",
"type": "preference",
"value": preference,
"timestamp": message.get("timestamp", "")
})
# 提取技能信息
if "我会" in content or "我擅长" in content:
skill = content.replace("我会", "").replace("我擅长", "").strip()
facts.append({
"key": "user_skills",
"type": "skill",
"value": skill,
"timestamp": message.get("timestamp", "")
})
# 提取项目信息
if "项目" in content:
facts.append({
"key": "current_projects",
"type": "project",
"value": content,
"timestamp": message.get("timestamp", "")
})
return facts
def merge_facts(existing_fact, new_fact):
"""合并新旧事实信息"""
print(f" 🔀 合并信息: {existing_fact.get('value', '')} + {new_fact['value']}")
# 保留时间戳最新的信息为主
merged = {
"value": new_fact["value"], # 新信息优先
"updated_at": new_fact["timestamp"],
"previous_value": existing_fact.get("value"),
"change_history": existing_fact.get("change_history", [])
}
# 记录变更历史
if existing_fact.get("value") != new_fact["value"]:
change_record = {
"from": existing_fact.get("value"),
"to": new_fact["value"],
"timestamp": new_fact["timestamp"]
}
merged["change_history"].append(change_record)
return merged4.3.2.2 策略性更新方法
python
def strategic_memory_update(state, config, *, store):
"""策略性记忆更新"""
print("\n=== 4.3.2.2 策略性更新方法 ===")
user_id = config["configurable"]["user_id"]
current_message = state["messages"][-1].content
# 1. 重要性评估
importance_score = assess_importance(current_message)
print(f"📈 重要性评分: {importance_score}/10")
if importance_score >= 7:
print("⭐ 高重要性信息,立即更新记忆")
update_immediately = True
elif importance_score >= 4:
print("📋 中等重要性,添加到待更新队列")
add_to_update_queue(current_message, user_id)
update_immediately = False
else:
print("📝 低重要性信息,仅记录到临时缓存")
add_to_temp_cache(current_message, user_id)
update_immediately = False
# 2. 冲突检测
if update_immediately:
conflicts = detect_conflicts(current_message, user_id, store)
if conflicts:
print(f"⚠️ 检测到 {len(conflicts)} 个潜在冲突")
resolve_conflicts(conflicts, current_message, user_id, store)
else:
print("✅ 无冲突,直接更新")
update_memory_directly(current_message, user_id, store)
return state
def assess_importance(message_content):
"""评估信息的重要性"""
importance = 0
# 基于关键词的重要性评估
high_importance_keywords = ["偏好", "不喜欢", "改变", "更新", "项目", "工作"]
medium_importance_keywords = ["想要", "需要", "计划", "目标"]
for keyword in high_importance_keywords:
if keyword in message_content:
importance += 3
for keyword in medium_importance_keywords:
if keyword in message_content:
importance += 2
# 基于句子结构的重要性
if "我是" in message_content or "我的" in message_content:
importance += 2
return min(importance, 10) # 最高10分
def detect_conflicts(new_info, user_id, store):
"""检测记忆冲突"""
conflicts = []
# 检查是否与现有记忆冲突
namespace = ("semantic", user_id)
existing_memories = store.search(namespace, query=new_info, limit=10)
for memory in existing_memories:
if is_conflicting(new_info, memory.value):
conflicts.append({
"existing": memory,
"new": new_info,
"conflict_type": "contradiction"
})
return conflicts
def resolve_conflicts(conflicts, new_info, user_id, store):
"""解决记忆冲突"""
print("🔧 解决记忆冲突:")
for conflict in conflicts:
print(f" 冲突: {conflict['existing'].value} vs {new_info}")
# 基于时间戳决定保留哪个信息
if is_newer_info(new_info, conflict['existing']):
print(" ✅ 新信息更新,替换旧记忆")
namespace = ("semantic", user_id)
store.put(namespace, conflict['existing'].key, {
"value": new_info,
"updated_at": datetime.now().isoformat(),
"replaced": conflict['existing'].value
})
else:
print(" 📝 旧信息保留,新信息作为变更记录")
def is_conflicting(new_info, existing_info):
"""判断信息是否冲突"""
# 简化的冲突检测逻辑
negative_patterns = ["不喜欢", "不要", "改变", "不再"]
for pattern in negative_patterns:
if pattern in new_info and existing_info.get("value", "") not in new_info:
return True
return False
def is_newer_info(new_info, existing_memory):
"""判断信息是否更新"""
# 在实际应用中,这里会比较时间戳
return True # 简化示例,假设新信息总是更新的4.3.2.3 更新策略的最佳实践
python
def memory_update_best_practices():
"""记忆更新的最佳实践"""
print("\n=== 4.3.2.3 记忆更新最佳实践 ===")
practices = {
"时效性管理": [
"为每条记忆添加时间戳",
"定期清理过期信息",
"优先保留最新的准确信息"
],
"冲突解决": [
"建立明确的优先级规则",
"保留变更历史记录",
"在不确定时询问用户确认"
],
"质量控制": [
"验证信息的一致性",
"过滤低质量或重复信息",
"定期进行记忆整理"
],
"性能优化": [
"批量更新以提高效率",
"使用后台任务避免阻塞",
"实施记忆压缩和归档"
]
}
for category, items in practices.items():
print(f"\n📋 {category}:")
for item in items:
print(f" • {item}")
print("\n💡 记忆更新策略的核心原则:")
print(" 1. 准确性:确保记忆内容的准确性和一致性")
print(" 2. 时效性:及时更新变化的信息")
print(" 3. 完整性:保持记忆的完整性和关联性")
print(" 4. 效率性:优化更新过程的性能")4.3.3 记忆类型对比
| 记忆类型 | 存储机制 | 生命周期 | 适用场景 | 存储建议 |
|---|---|---|---|---|
| 短期记忆 | Checkpointer | 会话级别 | 对话上下文、临时状态 | 开发:InMemorySaver 生产:PostgresSaver |
| 长期记忆 | Store | 跨会话 | 用户偏好、知识积累 | 开发:InMemoryStore 生产:PostgresStore |
4.3.4 隐私和安全考虑
python
def privacy_filter(memory_data, user_permissions):
"""根据用户权限过滤记忆数据"""
if user_permissions.get("allow_personal_data", False):
return memory_data
else:
# 移除敏感信息
filtered_data = {
k: v for k, v in memory_data.items()
if k not in ["phone", "address", "id_number"]
}
return filtered_data
def setup_memory_retention_policy():
"""设置记忆保留策略"""
return {
"short_term": {
"max_messages": 50, # 最多保留50条消息
"ttl_days": 7 # 7天后自动清理
},
"long_term": {
"user_preferences": {"ttl_days": 365}, # 用户偏好保留1年
"interaction_history": {"ttl_days": 30}, # 交互历史保留30天
"sensitive_data": {"ttl_days": 1} # 敏感数据1天后清理
}
}五、模型集成:灵活的AI引擎选择
5.1 自定义模型配置
在线上环境中,我们往往需要使用自定义的API端点、密钥和模型配置。LangGraph支持灵活的模型集成方案:
python
from langchain_openai import ChatOpenAI
from langchain_anthropic import ChatAnthropic
import os
class ModelManager:
"""模型管理器,支持多种自定义配置"""
def __init__(self):
self.models = {}
def register_openai_model(self, name: str, config: dict):
"""注册自定义OpenAI模型"""
self.models[name] = ChatOpenAI(
model=config.get("model", "gpt-4"),
api_key=config.get("api_key"),
base_url=config.get("base_url", "https://api.openai.com/v1"),
temperature=config.get("temperature", 0.1),
max_tokens=config.get("max_tokens", 4000)
)
def register_anthropic_model(self, name: str, config: dict):
"""注册自定义Anthropic模型"""
self.models[name] = ChatAnthropic(
model=config.get("model", "claude-3-sonnet-20240229"),
api_key=config.get("api_key"),
base_url=config.get("base_url"),
temperature=config.get("temperature", 0.1),
max_tokens=config.get("max_tokens", 4000)
)
def get_model(self, name: str):
"""获取指定模型"""
return self.models.get(name)
# 初始化模型管理器
model_manager = ModelManager()
# 注册企业内部的OpenAI兼容模型
model_manager.register_openai_model("company_gpt4", {
"model": "gpt-4-turbo",
"api_key": os.getenv("COMPANY_API_KEY"),
"base_url": "https://internal-api.company.com/v1",
"temperature": 0.1,
"max_tokens": 8000
})
# 注册外部API服务
model_manager.register_openai_model("azure_gpt4", {
"model": "gpt-4",
"api_key": os.getenv("AZURE_API_KEY"),
"base_url": "https://your-resource.openai.azure.com/",
"temperature": 0.2
})5.2 多模型策略选择
根据不同的任务类型选择最适合的模型:
python
def get_appropriate_model(task_type: str, complexity: str = "medium"):
"""根据任务类型和复杂度选择合适的模型"""
if task_type == "code_analysis":
if complexity == "high":
return model_manager.get_model("company_gpt4")
else:
return model_manager.get_model("azure_gpt4")
elif task_type == "creative_writing":
# 创意写作使用更高的温度
model = model_manager.get_model("company_gpt4")
model.temperature = 0.8
return model
elif task_type == "data_analysis":
# 数据分析需要精确性
model = model_manager.get_model("company_gpt4")
model.temperature = 0.0
return model
else:
# 通用任务使用默认配置
return model_manager.get_model("azure_gpt4")
def smart_processing_node(state: AgentState) -> AgentState:
"""智能处理节点,根据任务选择模型"""
task_type = state.get("task_type", "general")
complexity = state.get("complexity", "medium")
llm = get_appropriate_model(task_type, complexity)
# 构建提示词
prompt = build_prompt(state, task_type)
# 调用模型
response = llm.invoke(prompt)
return {
**state,
"result": response.content,
"model_used": llm.model_name
}5.3 模型性能监控
在生产环境中,监控模型性能是至关重要的:
python
import time
from typing import Dict, Any
class ModelMonitor:
"""模型性能监控器"""
def __init__(self):
self.stats = {}
def track_request(self, model_name: str, start_time: float,
end_time: float, token_count: int, success: bool):
"""跟踪模型请求性能"""
if model_name not in self.stats:
self.stats[model_name] = {
"total_requests": 0,
"successful_requests": 0,
"total_latency": 0,
"total_tokens": 0,
"avg_latency": 0,
"success_rate": 0
}
stats = self.stats[model_name]
stats["total_requests"] += 1
if success:
stats["successful_requests"] += 1
latency = end_time - start_time
stats["total_latency"] += latency
stats["total_tokens"] += token_count
# 更新平均值
stats["avg_latency"] = stats["total_latency"] / stats["successful_requests"]
stats["success_rate"] = stats["successful_requests"] / stats["total_requests"]
# 创建监控器实例
monitor = ModelMonitor()
def monitored_model_call(model, prompt, model_name: str):
"""监控模型调用的包装函数"""
start_time = time.time()
try:
response = model.invoke(prompt)
end_time = time.time()
# 估算token数量(简化版本)
token_count = len(prompt) // 4 + len(response.content) // 4
monitor.track_request(model_name, start_time, end_time, token_count, True)
return response
except Exception as e:
end_time = time.time()
monitor.track_request(model_name, start_time, end_time, 0, False)
raise e5.4 模型回退策略
当主要模型不可用时,自动切换到备用模型:
python
def resilient_model_call(prompt: str, task_type: str) -> str:
"""具有回退机制的模型调用"""
# 定义模型优先级
model_priority = [
("company_gpt4", "主要模型"),
("azure_gpt4", "Azure备份"),
("public_gpt35", "公开API备份")
]
for model_name, description in model_priority:
try:
model = model_manager.get_model(model_name)
if model is None:
continue
response = monitored_model_call(model, prompt, model_name)
print(f"✅ 使用 {description} 成功")
return response.content
except Exception as e:
print(f"❌ {description} 失败: {e}")
continue
raise Exception("所有模型都不可用")六、工具集成:扩展智能体的能力边界
6.1 工具调用的基础
真正强大的智能体不仅能思考,还能行动。通过工具集成,AI可以调用外部API、执行代码、访问数据库等,将虚拟助手转变为实用的执行者。
python
from langchain_core.tools import tool
from typing import Annotated
import json
@tool
def search_database(query: str) -> str:
"""搜索公司数据库中的信息
Args:
query: 搜索关键词或SQL查询语句
Returns:
JSON格式的搜索结果
"""
# 实际的数据库查询逻辑
results = execute_database_query(query)
return json.dumps(results, ensure_ascii=False)
@tool
def send_email(recipient: str, subject: str, body: str) -> str:
"""发送邮件通知
Args:
recipient: 收件人邮箱地址
subject: 邮件主题
body: 邮件正文内容
Returns:
发送状态信息
"""
try:
email_service.send(recipient, subject, body)
return f"✅ 邮件已成功发送至 {recipient}"
except Exception as e:
return f"❌ 邮件发送失败: {str(e)}"
@tool
def get_weather(location: str) -> str:
"""获取指定地点的天气信息
Args:
location: 地点名称(如:北京、上海)
Returns:
天气信息的JSON字符串
"""
weather_data = weather_api.get_current_weather(location)
return json.dumps(weather_data, ensure_ascii=False)6.2 工具调用节点的实现
在LangGraph中,工具调用通常在专门的节点中处理:
python
from langgraph.prebuilt import ToolNode
from langchain_core.messages import ToolMessage
def create_tool_calling_agent():
"""创建支持工具调用的智能体"""
# 定义所有可用工具
tools = [search_database, send_email, get_weather]
# 创建绑定工具的模型
model_with_tools = get_llm().bind_tools(tools)
def call_model(state: MessagesState):
"""模型调用节点"""
messages = state["messages"]
response = model_with_tools.invoke(messages)
return {"messages": [response]}
def should_continue(state: MessagesState) -> str:
"""判断是否需要调用工具"""
messages = state["messages"]
last_message = messages[-1]
# 如果最后一条消息包含工具调用,则执行工具
if last_message.tool_calls:
return "tools"
# 否则结束
return "end"
# 构建图
workflow = StateGraph(MessagesState)
# 添加节点
workflow.add_node("agent", call_model)
workflow.add_node("tools", ToolNode(tools))
# 设置边
workflow.set_entry_point("agent")
workflow.add_conditional_edges(
"agent",
should_continue,
{"tools": "tools", "end": END}
)
workflow.add_edge("tools", "agent")
return workflow.compile()6.3 错误处理和重试机制
在实际应用中,工具调用可能会失败,需要建立健壮的错误处理机制:
python
@tool
def robust_api_call(endpoint: str, params: dict) -> str:
"""带重试机制的API调用工具
Args:
endpoint: API端点URL
params: 请求参数
Returns:
API响应结果
"""
max_retries = 3
base_delay = 1
for attempt in range(max_retries):
try:
# 模拟API调用
print(f"尝试第 {attempt + 1} 次API调用: {endpoint}")
# 模拟随机失败(70%成功率)
import random
if random.random() < 0.7: # 70%成功率
response_data = {
"status": "success",
"data": f"API调用成功,参数: {params}",
"endpoint": endpoint
}
return json.dumps({
"success": True,
"data": response_data,
"attempt": attempt + 1
}, ensure_ascii=False)
else:
raise Exception("模拟网络错误")
except Exception as e:
if attempt == max_retries - 1:
return json.dumps({
"success": False,
"error": f"API调用失败,已重试{max_retries}次: {str(e)}",
"attempt": attempt + 1
}, ensure_ascii=False)
# 指数退避
delay = base_delay * (2 ** attempt)
print(f"第 {attempt + 1} 次尝试失败,{delay}秒后重试...")
time.sleep(delay)
return json.dumps({"success": False, "error": "未知错误"}, ensure_ascii=False)6.4 工具权限和安全控制
在企业环境中,工具的使用需要适当的权限控制:
python
from functools import wraps
from typing import List
def require_permissions(required_permissions: List[str]):
"""装饰器:要求特定权限才能使用工具"""
def decorator(func):
@wraps(func)
def wrapper(*args, **kwargs):
# 从上下文获取用户权限(简化示例)
user_permissions = get_current_user_permissions()
for permission in required_permissions:
if permission not in user_permissions:
return f"❌ 权限不足:需要 {permission} 权限"
return func(*args, **kwargs)
return wrapper
return decorator
@tool
@require_permissions(["database.read"])
def secure_database_search(query: str) -> str:
"""受权限保护的数据库搜索"""
return search_database(query)
@tool
@require_permissions(["email.send"])
def secure_send_email(recipient: str, subject: str, body: str) -> str:
"""受权限保护的邮件发送"""
return send_email(recipient, subject, body)6.5 工具编排策略
在复杂场景中,智能体需要协调多个工具的使用。以下是几种常见的工具编排策略:
6.5.1 顺序执行策略
python
def sequential_tool_workflow(state: AgentState) -> AgentState:
"""顺序执行多个工具的工作流"""
# 步骤1:搜索相关信息
search_result = search_database(state["query"])
# 步骤2:基于搜索结果获取详细信息
if "weather" in search_result:
weather_info = get_weather(state["location"])
# 步骤3:发送汇总邮件
summary = f"搜索结果:{search_result}\n天气信息:{weather_info}"
send_email(state["recipient"], "信息汇总", summary)
return {
**state,
"result": "任务完成",
"steps_completed": ["搜索", "天气查询", "邮件发送"]
}6.5.2 并行执行策略
python
import asyncio
from concurrent.futures import ThreadPoolExecutor
async def parallel_tool_workflow(state: AgentState) -> AgentState:
"""并行执行多个工具的工作流"""
async def async_search():
return search_database(state["query"])
async def async_weather():
return get_weather(state["location"])
async def async_user_profile():
return get_user_profile(state["user_id"])
# 并行执行多个工具
results = await asyncio.gather(
async_search(),
async_weather(),
async_user_profile(),
return_exceptions=True
)
# 处理结果
search_result, weather_result, profile_result = results
return {
**state,
"search_result": search_result,
"weather_result": weather_result,
"profile_result": profile_result,
"execution_time": "并行执行完成"
}6.5.3 条件分支策略
python
def conditional_tool_workflow(state: AgentState) -> AgentState:
"""基于条件选择不同的工具执行路径"""
request_type = classify_request(state["user_input"])
if request_type == "information_query":
# 信息查询路径
result = search_database(state["query"])
elif request_type == "weather_request":
# 天气查询路径
result = get_weather(state["location"])
elif request_type == "email_task":
# 邮件任务路径
result = send_email(
state["recipient"],
state["subject"],
state["body"]
)
else:
# 默认路径
result = "抱歉,我不确定如何处理这个请求"
return {
**state,
"result": result,
"request_type": request_type
}6.5.4 工具链策略
python
class ToolChain:
"""工具链:将多个工具组合成一个复杂的处理管道"""
def __init__(self, tools: List):
self.tools = tools
self.results = []
def execute(self, initial_input: str) -> str:
"""执行工具链"""
current_input = initial_input
for i, tool in enumerate(self.tools):
try:
result = tool.invoke(current_input)
self.results.append({
"step": i + 1,
"tool": tool.name,
"input": current_input,
"output": result
})
# 将当前结果作为下一个工具的输入
current_input = result
except Exception as e:
error_msg = f"工具链在第{i+1}步失败: {str(e)}"
self.results.append({
"step": i + 1,
"tool": tool.name,
"error": error_msg
})
return error_msg
return current_input
# 使用示例
def create_research_chain():
"""创建研究工具链"""
return ToolChain([
search_database, # 1. 搜索基础信息
get_weather, # 2. 获取相关天气信息
send_email # 3. 发送研究结果
])七、人机交互:在关键时刻引入人类智慧
人机协作是企业级AI应用的核心特征。LangGraph提供了强大的人机交互机制,让智能体能够在关键时刻寻求人类的判断和指导。
7.1 中断机制:智能体的"请示"能力
当智能体遇到需要人类判断的情况时,可以主动暂停执行,等待人工干预。这种机制在处理敏感操作、重要决策或不确定情况时特别有用。
7.1.1 编译时设置中断点
ini
# 在特定节点前中断
app = workflow.compile(
checkpointer=checkpointer,
interrupt_before=["sensitive_operation", "final_decision"]
)
# 执行到中断点
config = {"configurable": {"thread_id": "user_session_123"}}
result = app.invoke({
"messages": [{"role": "user", "content": "请帮我删除所有客户数据"}]
}, config)
print("智能体已暂停,等待人工确认...")7.1.2 动态中断控制
python
from langgraph.types import interrupt
def sensitive_operation_node(state: MessagesState) -> MessagesState:
"""敏感操作节点,动态决定是否需要人工确认"""
operation_type = classify_operation(state["messages"][-1].content)
risk_level = assess_risk(operation_type)
if risk_level == "high":
# 动态触发中断
interrupt("需要人工确认高风险操作")
# 继续执行
return execute_operation(state)7.1.3 中断后的处理流程
python
def handle_human_in_the_loop():
"""处理人机交互的完整流程"""
# 1. 执行到中断点
try:
result = app.invoke(initial_state, config)
print("工作流正常完成")
return result
except GraphInterrupt as interrupt_info:
print(f"工作流在节点 '{interrupt_info.node}' 处中断")
print(f"中断原因: {interrupt_info.reason}")
# 2. 获取当前状态
current_state = app.get_state(config)
print(f"当前状态: {current_state.values}")
# 3. 等待人工决策
human_decision = get_human_approval(current_state)
if human_decision["approved"]:
# 4. 添加人工反馈到状态
updated_state = {
**current_state.values,
"human_feedback": human_decision["feedback"],
"approved": True
}
# 5. 更新状态并继续执行
app.update_state(config, updated_state)
final_result = app.invoke(None, config)
return final_result
else:
print("操作被人工拒绝")
return {"status": "rejected", "reason": human_decision["reason"]}7.2 多种中断策略
LangGraph支持多种中断策略,以适应不同的业务需求:
7.2.1 基于内容的中断
python
def content_based_interrupt(state: MessagesState) -> MessagesState:
"""基于消息内容决定是否中断"""
last_message = state["messages"][-1].content.lower()
# 检测敏感关键词
sensitive_keywords = ["删除", "删库", "重置密码", "转账"]
for keyword in sensitive_keywords:
if keyword in last_message:
interrupt(f"检测到敏感操作关键词: {keyword}")
return state7.2.2 基于用户权限的中断
python
def permission_based_interrupt(state: MessagesState, config) -> MessagesState:
"""基于用户权限决定是否需要额外确认"""
user_role = config["configurable"].get("user_role", "user")
operation = extract_operation(state["messages"][-1].content)
# 普通用户执行管理员操作需要审批
if user_role == "user" and operation in ["admin_operations"]:
interrupt("普通用户执行管理员操作,需要管理员审批")
return state7.2.3 基于置信度的中断
python
def confidence_based_interrupt(state: MessagesState) -> MessagesState:
"""基于AI置信度决定是否需要人工确认"""
# 评估AI对当前任务的置信度
confidence = assess_confidence(state)
if confidence < 0.7: # 置信度低于70%
interrupt(f"AI置信度较低({confidence:.2f}),建议人工审核")
return state7.3 人工反馈的集成
人工反馈不仅用于审批,还能帮助智能体学习和改进:
python
def incorporate_human_feedback(state: MessagesState) -> MessagesState:
"""整合人工反馈,改进智能体行为"""
feedback = state.get("human_feedback", {})
if feedback:
# 记录反馈用于后续学习
log_feedback(feedback, state["context"])
# 根据反馈调整当前处理策略
if feedback.get("suggestion"):
adjusted_approach = modify_approach(
state["current_approach"],
feedback["suggestion"]
)
return {
**state,
"current_approach": adjusted_approach,
"feedback_incorporated": True
}
return state7.4 实时协作界面
为了提高人机协作的效率,我们可以构建实时协作界面:
python
class HumanCollaborationInterface:
"""人机协作界面"""
def __init__(self):
self.pending_approvals = {}
self.notification_handlers = []
def request_approval(self, session_id: str, context: dict):
"""请求人工审批"""
approval_request = {
"session_id": session_id,
"timestamp": datetime.now(),
"context": context,
"status": "pending"
}
self.pending_approvals[session_id] = approval_request
# 通知相关人员
self.notify_reviewers(approval_request)
return approval_request
def provide_approval(self, session_id: str, decision: dict):
"""提供审批决策"""
if session_id in self.pending_approvals:
self.pending_approvals[session_id].update({
"decision": decision,
"status": "completed",
"completed_at": datetime.now()
})
# 通知智能体可以继续
self.notify_agent_continuation(session_id, decision)
def notify_reviewers(self, request: dict):
"""通知审核人员"""
# 可以通过邮件、即时消息、推送通知等方式
for handler in self.notification_handlers:
handler.send_notification(request)
# 使用示例
collaboration_interface = HumanCollaborationInterface()
def smart_interrupt_node(state: MessagesState, config) -> MessagesState:
"""智能中断节点"""
session_id = config["configurable"]["thread_id"]
# 评估是否需要人工介入
if requires_human_review(state):
# 请求人工审批
approval_request = collaboration_interface.request_approval(
session_id,
{
"operation": extract_operation(state),
"risk_level": assess_risk_level(state),
"context": state["messages"][-3:] # 最近3条消息作为上下文
}
)
# 触发中断,等待审批
interrupt(f"等待审批,请求ID: {approval_request['session_id']}")
return state7.5 审计和合规
在企业环境中,人机交互的记录对于审计和合规至关重要:
python
class InteractionAuditor:
"""人机交互审计器"""
def __init__(self, audit_db):
self.audit_db = audit_db
def log_interrupt(self, session_id: str, node_name: str, reason: str):
"""记录中断事件"""
audit_record = {
"event_type": "interrupt",
"session_id": session_id,
"node_name": node_name,
"reason": reason,
"timestamp": datetime.now(),
"user_context": get_user_context(session_id)
}
self.audit_db.insert(audit_record)
def log_human_decision(self, session_id: str, decision: dict):
"""记录人工决策"""
audit_record = {
"event_type": "human_decision",
"session_id": session_id,
"decision": decision,
"timestamp": datetime.now(),
"reviewer": decision.get("reviewer_id"),
"justification": decision.get("justification")
}
self.audit_db.insert(audit_record)
def generate_compliance_report(self, date_range: tuple):
"""生成合规报告"""
interactions = self.audit_db.query_date_range(date_range)
report = {
"total_interrupts": len([i for i in interactions if i["event_type"] == "interrupt"]),
"approval_rate": self.calculate_approval_rate(interactions),
"avg_response_time": self.calculate_avg_response_time(interactions),
"compliance_violations": self.detect_violations(interactions)
}
return report八、MCP集成:连接外部世界
8.1 什么是MCP?
Model Context Protocol (MCP) 是一种开放标准协议,专门设计用于在 AI 模型和外部数据源、工具之间建立安全、标准化的连接。MCP的核心价值在于为AI应用提供了一个统一的接口来访问各种外部资源,而无需为每个系统单独开发集成代码。
MCP的主要优势:
- 标准化:统一的协议规范,降低集成复杂度
- 安全性:内置权限控制和访问限制机制
- 可扩展性:支持各种类型的外部资源和工具
- 互操作性:不同供应商的工具可以无缝协作
8.2 LangGraph中的MCP集成
LangGraph通过langchain-mcp-adapters提供对MCP的支持,让智能体能够轻松访问通过MCP暴露的外部服务。
8.2.1 MCP客户端配置
python
from langchain_mcp_adapters.client import MultiServerMCPClient
import asyncio
class MCPClientManager:
"""MCP客户端管理器"""
def __init__(self):
self.client = None
self.available_tools = []
self.server_config = {}
async def connect_to_server(self, server_url: str) -> bool:
"""连接到MCP服务器
Args:
server_url: MCP服务器的SSE URL
Returns:
bool: 连接是否成功
"""
try:
# 创建服务器配置
self.server_config = {
"mcp_server": {
"transport": "sse",
"url": server_url
}
}
print(f"🔗 正在连接到MCP服务器: {server_url}")
# 创建MCP客户端
self.client = MultiServerMCPClient(self.server_config)
# 获取可用工具
self.available_tools = await self.client.get_tools()
print(f"✅ 成功连接到MCP服务器")
print(f"🛠️ 发现 {len(self.available_tools)} 个可用工具")
# 显示工具信息
for tool in self.available_tools:
print(f" • {tool.name}: {tool.description}")
return True
except Exception as e:
print(f"❌ 连接MCP服务器失败: {e}")
return False
def get_tools(self):
"""获取可用工具列表"""
return self.available_tools if self.available_tools else []
async def call_tool(self, tool_name: str, arguments: dict):
"""调用工具"""
if not self.client:
raise Exception("MCP客户端未连接")
try:
result = await self.client.call_tool(tool_name, arguments)
return result
except Exception as e:
raise Exception(f"工具调用失败: {e}")
# 使用示例
async def setup_mcp_connection():
"""设置MCP连接"""
mcp_manager = MCPClientManager()
# 连接到MCP服务器(使用SSE传输)
server_url = "http://localhost:8000/mcp/sse"
success = await mcp_manager.connect_to_server(server_url)
if success:
return mcp_manager
else:
print("⚠️ 无法连接到MCP服务器")
return None8.2.2 MCP工具与LLM智能体集成
python
from langgraph.prebuilt import ToolNode
from langgraph.graph import StateGraph, END
from typing_extensions import TypedDict, Annotated
from typing import List
from langchain_core.messages import BaseMessage, SystemMessage
from langgraph.graph.message import add_messages
async def create_mcp_integrated_agent(mcp_manager):
"""创建集成MCP工具的智能体"""
# 获取MCP工具
mcp_tools = mcp_manager.get_tools()
if not mcp_tools:
print("⚠️ 没有可用的MCP工具")
return None
print(f"🛠️ 可用的MCP工具: {[tool.name for tool in mcp_tools]}")
# 创建LLM并绑定工具
llm = get_llm()
llm_with_tools = llm.bind_tools(mcp_tools)
# 定义状态
class State(TypedDict):
messages: Annotated[List[BaseMessage], add_messages]
# 定义智能体节点
def agent_node(state: State):
"""智能体节点 - 分析用户请求并决定是否调用工具"""
messages = state["messages"]
# 添加系统提示
system_prompt = """你是一个智能运维助手,可以通过MCP工具远程执行系统命令。
当用户询问系统状态、执行命令或查看信息时,请使用available tools来完成任务。
可用工具:
- remote_exec: 在远程设备上执行shell命令
参数: machineId (设备ID), script (要执行的shell命令)
请根据用户需求智能选择和调用工具。如果用户提供了设备ID,请使用该ID;否则使用默认设备ID。
"""
# 构建完整的消息列表
full_messages = [SystemMessage(content=system_prompt)] + messages
# 调用LLM
response = llm_with_tools.invoke(full_messages)
return {"messages": [response]}
# 定义工具节点 - 使用ToolNode自动处理工具调用
tool_node = ToolNode(mcp_tools)
# 定义路由函数
def should_continue(state: State):
"""判断是否需要继续调用工具"""
last_message = state["messages"][-1]
# 如果LLM返回了工具调用,则路由到工具节点
if hasattr(last_message, 'tool_calls') and last_message.tool_calls:
return "call_tool"
return "end"
# 构建工作流图
workflow = StateGraph(State)
# 添加节点
workflow.add_node("agent", agent_node)
workflow.add_node("call_tool", tool_node)
# 设置入口点
workflow.set_entry_point("agent")
# 添加条件边
workflow.add_conditional_edges(
"agent",
should_continue,
{
"call_tool": "call_tool",
"end": END
}
)
# 工具调用后返回智能体
workflow.add_edge("call_tool", "agent")
# 编译图
app = workflow.compile()
return app
# 使用示例
async def test_mcp_agent():
"""测试MCP集成的智能体"""
# 设置MCP连接
mcp_manager = await setup_mcp_connection()
if not mcp_manager:
return
# 创建智能体
agent = await create_mcp_integrated_agent(mcp_manager)
if not agent:
return
# 测试查询
test_queries = [
"查看设备 6fa31edaac8bee6cc75cd8ae1bc03930 的系统负载情况",
"在设备 6fa31edaac8bee6cc75cd8ae1bc03930 上执行 df -h 查看磁盘使用",
"检查设备 6fa31edaac8bee6cc75cd8ae1bc03930 的内存使用情况 free -h"
]
for query in test_queries:
print(f"🤖 智能体测试: {query}")
try:
# 调用智能体
result = await agent.ainvoke({"messages": [{"role": "user", "content": query}]})
# 获取最终回复
final_message = result["messages"][-1]
if hasattr(final_message, 'content') and final_message.content:
print(f"✅ 智能体回复: {final_message.content[:300]}...")
else:
print(f"📋 工具调用结果: {str(final_message)[:300]}...")
except Exception as e:
print(f"❌ 智能体调用失败: {str(e)}")
print("=" * 60)8.3 MCP工具的动态发现
MCP支持工具的动态发现,让智能体能够自动了解和使用新的工具:
python
async def discover_and_register_tools():
"""动态发现并注册MCP工具"""
all_tools = []
for server_name, client in mcp_manager.clients.items():
try:
# 获取服务器提供的所有工具
tools = await client.list_tools()
for tool in tools:
# 创建LangGraph工具包装器
langraph_tool = create_mcp_tool_wrapper(
server_name,
tool["name"],
tool["description"],
tool["inputSchema"]
)
all_tools.append(langraph_tool)
except Exception as e:
print(f"获取 {server_name} 工具列表失败: {e}")
return all_tools
def create_mcp_tool_wrapper(server_name: str, tool_name: str,
description: str, input_schema: dict):
"""为MCP工具创建LangGraph包装器"""
@tool
async def mcp_tool_wrapper(**kwargs) -> str:
f"""
{description}
服务器: {server_name}
工具: {tool_name}
"""
try:
result = await mcp_manager.call_tool(server_name, tool_name, kwargs)
return json.dumps(result, ensure_ascii=False)
except Exception as e:
return f"调用工具失败: {str(e)}"
# 设置工具名称和描述
mcp_tool_wrapper.name = f"{server_name}_{tool_name}"
mcp_tool_wrapper.description = description
return mcp_tool_wrapper8.4 MCP资源访问
除了工具调用,MCP还支持访问各种资源(如文件、数据库记录等):
python
async def access_mcp_resources(state: MessagesState) -> MessagesState:
"""访问MCP资源"""
user_query = state["messages"][-1].content
# 根据查询类型访问不同资源
if "文档" in user_query:
# 访问文档资源
resources = await mcp_manager.clients["document_server"].list_resources()
relevant_docs = []
for resource in resources:
if is_relevant_document(resource, user_query):
content = await mcp_manager.clients["document_server"].read_resource(
resource["uri"]
)
relevant_docs.append(content)
response = summarize_documents(relevant_docs)
elif "数据库" in user_query:
# 访问数据库资源
query_result = await mcp_manager.clients["db_server"].query_resource(
"database://company/analytics",
extract_sql_query(user_query)
)
response = format_query_results(query_result)
return {
**state,
"messages": state["messages"] + [{
"role": "assistant",
"content": response
}]
}8.5 MCP安全和权限管理
MCP提供了细粒度的安全控制机制:
python
class MCPSecurityManager:
"""MCP安全管理器"""
def __init__(self):
self.user_permissions = {}
self.tool_policies = {}
def set_user_permissions(self, user_id: str, permissions: list):
"""设置用户权限"""
self.user_permissions[user_id] = permissions
def set_tool_policy(self, tool_name: str, policy: dict):
"""设置工具访问策略"""
self.tool_policies[tool_name] = policy
def check_tool_access(self, user_id: str, tool_name: str, arguments: dict) -> bool:
"""检查工具访问权限"""
user_perms = self.user_permissions.get(user_id, [])
tool_policy = self.tool_policies.get(tool_name, {})
# 检查基本权限
required_permission = tool_policy.get("required_permission")
if required_permission and required_permission not in user_perms:
return False
# 检查参数限制
param_restrictions = tool_policy.get("parameter_restrictions", {})
for param, restriction in param_restrictions.items():
if param in arguments:
if not self.validate_parameter(arguments[param], restriction):
return False
return True
def validate_parameter(self, value, restriction):
"""验证参数值"""
if restriction["type"] == "whitelist":
return value in restriction["allowed_values"]
elif restriction["type"] == "pattern":
import re
return re.match(restriction["pattern"], str(value))
return True
# 使用安全管理器
security_manager = MCPSecurityManager()
# 配置权限
security_manager.set_user_permissions("user_123", ["crm.read", "hr.read"])
security_manager.set_tool_policy("search_customer", {
"required_permission": "crm.read",
"parameter_restrictions": {
"customer_id": {
"type": "pattern",
"pattern": r"^CUST-\d{6}$"
}
}
})九、ReAct智能体:推理与行动的结合
ReAct(Reasoning and Acting)是一种强大的智能体设计模式,它将推理(Reasoning)和行动(Acting)结合在一起,让AI能够在解决问题的过程中交替进行思考和执行。LangGraph提供了内置的ReAct智能体实现,大大简化了开发过程。
9.1 ReAct模式的核心思想
ReAct模式的工作流程是一个循环:
- 观察(Observation) :分析当前状态和用户需求
- 思考(Thought) :推理下一步应该做什么
- 行动(Action) :执行具体的工具调用或操作
- 观察(Observation) :分析行动的结果
- 重复:直到完成任务或达到停止条件
这种模式让智能体能够像人类一样进行有计划的问题解决。
9.2 使用create_react_agent快速创建智能体
LangGraph提供了create_react_agent函数,让我们能够快速创建ReAct智能体:
python
from langgraph.prebuilt import create_react_agent
from langchain_core.tools import tool
from langchain_openai import ChatOpenAI
# 定义工具
@tool
def calculator(expression: str) -> str:
"""计算数学表达式
Args:
expression: 要计算的数学表达式,如 "2 + 3 * 4"
Returns:
计算结果
"""
try:
result = eval(expression)
return f"计算结果: {result}"
except Exception as e:
return f"计算错误: {str(e)}"
@tool
def search_web(query: str) -> str:
"""搜索网络信息
Args:
query: 搜索关键词
Returns:
搜索结果摘要
"""
# 这里应该调用实际的搜索API
return f"搜索 '{query}' 的结果: [模拟的搜索结果]"
@tool
def get_current_time() -> str:
"""获取当前时间
Returns:
当前的日期和时间
"""
from datetime import datetime
return datetime.now().strftime("%Y-%m-%d %H:%M:%S")
# 创建ReAct智能体
def create_business_assistant():
"""创建商业助手ReAct智能体"""
# 定义可用工具
tools = [calculator, search_web, get_current_time]
# 创建模型
model = ChatOpenAI(
model="gpt-4",
temperature=0.1
)
# 创建ReAct智能体
agent = create_react_agent(
model=model,
tools=tools,
state_modifier="你是一个专业的商业助手。请帮助用户解决各种商业问题,包括计算、信息查询等。在使用工具时,请清楚地解释你的推理过程。"
)
return agent
# 使用智能体
business_agent = create_business_assistant()
# 运行示例
config = {"configurable": {"thread_id": "business_session_1"}}
result = business_agent.invoke({
"messages": [{"role": "user", "content": "请帮我计算一下如果我每月投资1000元,年化收益率为8%,10年后总共能积累多少资金?"}]
}, config)
print(result["messages"][-1].content)9.3 自定义ReAct智能体的状态
有时我们需要在ReAct智能体中维护额外的状态信息:
python
from typing_extensions import TypedDict
from langgraph.prebuilt import create_react_agent
class CustomAgentState(TypedDict):
"""自定义智能体状态"""
messages: list
user_profile: dict
conversation_context: dict
task_progress: dict
def create_enhanced_react_agent():
"""创建增强的ReAct智能体"""
# 定义工具(包含状态访问能力)
@tool
def update_user_profile(user_info: str) -> str:
"""更新用户档案信息
Args:
user_info: 用户信息描述
Returns:
更新状态
"""
# 这里可以访问和更新状态
return f"用户档案已更新: {user_info}"
@tool
def track_task_progress(task: str, status: str) -> str:
"""跟踪任务进度
Args:
task: 任务名称
status: 任务状态
Returns:
进度更新确认
"""
return f"任务 '{task}' 状态更新为: {status}"
tools = [calculator, search_web, get_current_time, update_user_profile, track_task_progress]
model = ChatOpenAI(model="gpt-4", temperature=0.1)
# 使用自定义状态创建智能体
agent = create_react_agent(
model=model,
tools=tools,
state_schema=CustomAgentState,
state_modifier="你是一个智能的个人助手。请记住用户的偏好和任务进度,提供个性化的帮助。"
)
return agent9.4 ReAct智能体的提示词优化
我们可以通过自定义提示词来优化ReAct智能体的行为:
python
def create_specialized_react_agent(domain: str):
"""创建专业领域的ReAct智能体"""
# 根据领域定制提示词
domain_prompts = {
"finance": """
你是一位专业的金融分析师助手。在处理金融相关问题时:
1. 始终考虑风险因素和市场波动性
2. 提供基于数据的分析,避免投资建议
3. 使用计算器工具进行精确的数值计算
4. 在需要最新市场信息时使用搜索工具
""",
"technical": """
你是一位技术专家助手。在解决技术问题时:
1. 先理解问题的技术背景和要求
2. 分步骤分析问题并制定解决方案
3. 使用搜索工具获取最新的技术信息
4. 提供详细的技术解释和实施步骤
""",
"general": """
你是一位通用智能助手。请:
1. 仔细分析用户需求
2. 选择合适的工具来获取信息或执行任务
3. 提供清晰、有用的回答
4. 在不确定时主动寻求澄清
"""
}
prompt = domain_prompts.get(domain, domain_prompts["general"])
tools = [calculator, search_web, get_current_time]
model = ChatOpenAI(model="gpt-4", temperature=0.1)
agent = create_react_agent(
model=model,
tools=tools,
state_modifier=prompt
)
return agent
# 创建金融分析助手
finance_agent = create_specialized_react_agent("finance")
# 创建技术支持助手
tech_agent = create_specialized_react_agent("technical")9.5 ReAct智能体的执行控制
我们可以对ReAct智能体的执行过程进行更精细的控制:
python
def create_controlled_react_agent():
"""创建可控制的ReAct智能体"""
tools = [calculator, search_web, get_current_time]
model = ChatOpenAI(model="gpt-4", temperature=0.1)
# 创建带有执行限制的智能体
agent = create_react_agent(
model=model,
tools=tools,
state_modifier="你是一个高效的助手,请在最少的步骤内完成任务。",
max_execution_time=60, # 最大执行时间(秒)
max_iterations=10 # 最大迭代次数
)
return agent
def run_with_timeout(agent, inputs, config, timeout=30):
"""带超时控制的智能体执行"""
import asyncio
async def run_agent():
return agent.invoke(inputs, config)
try:
# 设置超时
result = asyncio.wait_for(run_agent(), timeout=timeout)
return result
except asyncio.TimeoutError:
return {"error": "智能体执行超时"}
except Exception as e:
return {"error": f"执行错误: {str(e)}"}9.6 ReAct智能体的流式执行
对于需要实时反馈的场景,我们可以使用流式执行:
python
def stream_react_agent_execution():
"""流式执行ReAct智能体"""
agent = create_business_assistant()
inputs = {
"messages": [{"role": "user", "content": "请帮我分析一下当前的股市趋势,并计算如果投资10万元的预期收益"}]
}
config = {"configurable": {"thread_id": "stream_session"}}
print("🤖 智能体开始工作...")
# 流式执行,观察推理过程
for chunk in agent.stream(inputs, config, stream_mode="values"):
messages = chunk.get("messages", [])
if messages:
last_message = messages[-1]
# 显示智能体的思考过程
if last_message.type == "ai":
if "思考" in last_message.content or "Thought" in last_message.content:
print(f"🤔 思考: {last_message.content}")
elif "行动" in last_message.content or "Action" in last_message.content:
print(f"🔧 行动: {last_message.content}")
else:
print(f"💭 回应: {last_message.content}")
elif last_message.type == "tool":
print(f"🛠️ 工具结果: {last_message.content}")
# 运行流式执行示例
# stream_react_agent_execution()9.7 ReAct智能体与MCP集成
ReAct智能体可以与MCP工具无缝集成,实现真正的企业级应用:
python
from langgraph.prebuilt import create_react_agent
class MCPConnectionManager:
"""MCP连接管理器"""
def __init__(self, sse_url: str):
self.sse_url = sse_url
self.client = None
self.tools = []
async def connect(self):
"""连接到MCP服务器"""
try:
# 创建MCP客户端配置
server_config = {
"mcp_server": {
"transport": "sse",
"url": self.sse_url
}
}
# 连接到MCP服务器
self.client = MultiServerMCPClient(server_config)
self.tools = await self.client.get_tools()
print("✅ 成功连接到MCP服务器")
print(f"🛠️ 发现 {len(self.tools)} 个可用工具")
for tool in self.tools:
print(f" • {tool.name}: {tool.description}")
return True
except Exception as e:
print(f"❌ 连接MCP服务器失败: {e}")
raise Exception(f"MCP服务器连接失败: {e}") from e
def get_tools(self):
"""获取MCP工具列表"""
return self.tools
async def create_react_agent_with_mcp(sse_url: str):
"""创建集成真实MCP的ReAct Agent"""
# 连接MCP服务器
mcp_manager = MCPConnectionManager(sse_url)
await mcp_manager.connect()
# 获取MCP工具
mcp_tools = mcp_manager.get_tools()
if not mcp_tools:
print("⚠️ 没有可用的MCP工具")
return None, None
# 创建LLM
llm = get_llm()
# 创建系统提示
system_prompt = """你是一个智能运维助手,具备以下能力:
🤖 **核心能力**:
- 通过MCP工具远程执行系统命令
- 分析系统状态和性能指标
- 提供运维建议和解决方案
🛠️ **可用工具**:
- remote_exec: 在远程设备上执行shell命令
参数: machineId (设备ID), script (shell命令)
💡 **工作方式**:
1. 仔细分析用户需求
2. 制定执行计划
3. 使用合适的工具获取信息
4. 分析结果并提供专业建议
请按照ReAct模式工作:观察 → 思考 → 行动 → 观察,直到完成任务。
"""
# 使用create_react_agent创建ReAct代理
react_agent = create_react_agent(
llm,
mcp_tools,
state_modifier=system_prompt
)
print("✅ ReAct Agent创建成功")
return react_agent, mcp_manager
# 测试示例
async def test_react_agent_with_mcp(sse_url: str = None):
"""测试ReAct Agent + MCP集成"""
# 使用默认URL或用户提供的URL
if not sse_url:
sse_url = "http://localhost:8000/mcp/sse" # 默认URL
print(f"🌐 使用MCP服务器: {sse_url}")
try:
# 创建ReAct Agent
agent, mcp_manager = await create_react_agent_with_mcp(sse_url)
if not agent or not mcp_manager:
print("⚠️ 无法创建MCP集成的ReAct Agent")
return
# 定义测试场景
test_scenarios = [
{
"name": "系统健康检查",
"query": "请帮我全面检查设备 6fa31edaac8bee6cc75cd8ae1bc03930 的系统健康状况,包括CPU、内存、磁盘使用情况"
},
{
"name": "性能分析",
"query": "设备 6fa31edaac8bee6cc75cd8ae1bc03930 运行缓慢,请帮我分析可能的原因并提供优化建议"
},
{
"name": "故障排查",
"query": "设备 6fa31edaac8bee6cc75cd8ae1bc03930 上的某个服务可能有问题,请帮我检查系统日志和运行状态"
}
]
for i, scenario in enumerate(test_scenarios, 1):
print(f"🧪 测试场景 {i}: {scenario['name']}")
print(f"📝 用户请求: {scenario['query']}")
try:
# 调用ReAct Agent
result = await agent.ainvoke({
"messages": [{"role": "user", "content": scenario['query']}]
})
# 获取最终回复
final_message = result["messages"][-1]
if hasattr(final_message, 'content') and final_message.content:
# 显示ReAct推理过程
print("\n🧠 ReAct推理过程:")
thought_count = 0
action_count = 0
for j, msg in enumerate(result["messages"]):
if hasattr(msg, 'content') and msg.content:
content = msg.content
if "Thought:" in content or "思考" in content:
thought_count += 1
print(f" 💭 思考{thought_count}: {content[:100]}...")
elif "Action:" in content or "行动" in content:
action_count += 1
print(f" ⚡ 行动{action_count}: {content[:100]}...")
elif "Observation:" in content or "观察" in content:
print(f" 👁️ 观察: {content[:100]}...")
# 显示最终结果
print(f"✅ 最终回复: {final_message.content[:300]}...")
else:
print(f"📋 Agent结果: {str(final_message)[:300]}...")
except Exception as e:
print(f"❌ 测试场景失败: {str(e)}")
print("=" * 80)
print("✅ ReAct Agent + MCP集成测试完成")
except Exception as e:
print(f"❌ MCP集成测试失败: {e}")ReAct 模式的强大之处在于它模拟了人类解决问题的方式:思考-行动-观察-再思考。通过 LangGraph 的create_react_agent和 MCP 集成,我们可以快速构建出既能思考又能行动的企业级智能体,大大提升了 AI 应用的实用性和可靠性。
总结与展望
通过本文的学习,你已经掌握了构建企业级智能体的核心技能。从基础的图形 API 到高级的 ReAct 智能体,从简单的状态管理到复杂的 MCP 集成,LangGraph 为我们提供了完整的解决方案。
记住,最好的智能体不是那个能做所有事情的,而是那个能在正确的时间、以正确的方式做正确事情的。LangGraph 给了我们这样的能力,现在轮到我们去创造真正有价值的 AI 应用了。
掌握LangGraph这样的先进框架,将为你在AI时代的竞争中占得先机。让我们一起构建更智能、更可靠、更有价值的企业级AI应用!
下一篇预告:《企业级 Agent 开发实战(二) MCP协议分析及实战 MCPServer》