编者按: 当你需要为 RAG 系统选择文档解析工具时,面对 GitHub 上数百个开源项目和各种商业解决方案,你是否感到无从下手?
本文基于作者在实际项目中的工具使用经验,系统梳理了处理不同类型文档的工具选择。从知识图谱处理的 GRAG、KG-RAG、GNN-RAG 等工具,到表格解析的 TableRAG、TA。从 HTML 处理的 BeautifulSoup、HtmlRAG,到 PDF 解析的 MinerU、GPTPDF、Marker,再到多模态处理的 CLIP、Wav2Vec 2.0 等。期待本文能够帮助你快速找到最适合自己项目需求的技术方案。
作者 | Florian June
编译 | 岳扬
对于 RAG 系统而言,从文档中提取信息是一个不可避免的情况。最终系统输出的质量很大程度上取决于从源内容中提取信息的效果。
过去,我曾从不同角度探讨过文档解析问题1。本文结合近期一篇 RAG 调查报告2的发现与我之前的部分研究,对 RAG 系统如何解析和整合结构化、半结构化、非结构化和多模态知识进行了简明概括。
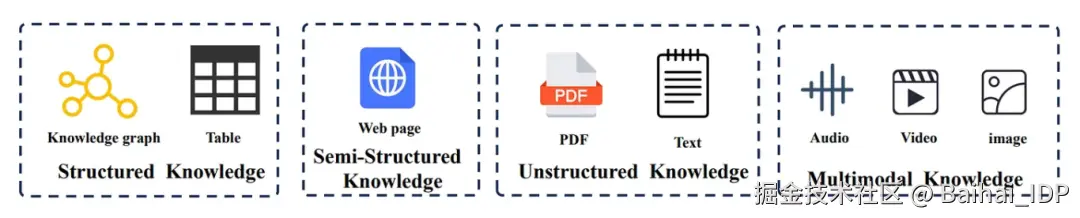
Figure 1: RAG 系统整合的多种知识类型,涵盖结构化、半结构化、非结构化和多模态知识。Source\[2]
01 结构化知识:数据按规则组织的范式
1.1 知识图谱:易于查询,便于使用,难以集成
知识图谱以一种清晰、互联的方式描述实体及其关系,使其成为机器系统的图谱遍历与查询的理想选择。
RAG 系统非常喜欢这样的结构化数据源 ------ 它们精确且语义丰富。但真正的挑战不在于查找数据,而在于如何有效地利用它。
- 如何从海量知识图谱中提取有意义的子图?
- 如何将结构化的图谱数据与自然语言对齐?
- 随着图谱规模的增长,系统是否仍能保持高效?
一些有前景的解决方案正逐步解决这些问题:
- GRAG 从多个文档中检索子图,来生成更聚焦的输入。
- KG-RAG 采用探索链算法(Chain of Explorations,CoE)来优化基于知识图谱的问答性能。
- GNN-RAG 采用图神经网络(GNN)检索和处理来自知识图谱(KG)的信息,在数据输入大语言模型(LLM)之前先进行一轮推理。
- SURGE 框架利用知识图谱生成更具相关性和知识感知(knowledge-aware)的对话,从而提升交互质量。
- 在特定领域,诸如 SMART-SLIC 、KARE 、ToG2.0 和 KAG3 等工具已充分证明,知识图谱作为外部知识源可以发挥多么强大的作用,可帮助 RAG 系统同时提升准确性和效率。
1.2 表格:结构紧凑、数据密集且解析困难
表格也是一种结构化数据 ------ 但它们与知识图谱截然不同。几行几列就可能蕴含着大量信息。但如何让机器理解这些信息?那完全是另一回事了。
表格中未明示的逻辑关系、格式不一致、专业领域内特有的知识...表格数据常游走于秩序与混沌之间。幸运的是,已有专门处理此类复杂情况的工具:
- TableRAG4 结合查询扩展(query expansion)、表结构与单元格检索(schema and cell retrieval),在将信息传递给语言模型前精准识别关键内容。
- TAG 和 Extreme-RAG 则更进一步整合了 Text-to-SQL 能力,使语言模型能够直接"操作数据库"。
核心结论?若能有效解析表格,它们就是价值极高的信息源。
02 半结构化数据:HTML、JSON 以及网络数据的杂乱中间态
半结构化数据就像数据世界的"家中老二(middle child)" ------ 既非完全结构化,也不完全是非结构化的。它比知识图谱更灵活,却比原始 PDF 文档更有条理。典型代表如 HTML 页面、JSON 文件、XML、电子邮件等格式,它们虽具备一定的结构特性,却常表现出结构规范不一致或结构要素不完备的特征。
尤其是 HTML,它无处不在,而每个网站都有其独特性。虽然存在 tags、attributes、elements(译者注:DOM 核心构件) 等结构化成分,但仍混杂着大量非结构化文本与图像。
为了有效解析 HTML,业界已开发出一系列工具和开源库,可将 HTML 内容转化为文档对象模型(DOM)树等结构化格式。值得关注的流行库包括:BeautifulSoup、htmlparser2、html5ever、MyHTML 以及 Fast HTML Parser。
此外,HtmlRAG5 等 RAG 框架在 RAG 系统中利用 HTML 格式替代纯文本,从而保留了语义与结构信息。
若希望 RAG 系统真正理解网页数据而非依靠胡编乱造 ------ HTML 解析便是这一切的起点。
03 非结构化知识:PDF、纯文本(既杂乱又有内在逻辑)
接下来叙述的内容才是真正的挑战。非结构化数据(自由格式的文本、PDF 文档、扫描报告)无处不在。
尤其是 PDF 文档,简直就是噩梦:不一致的布局、嵌入内部的图像、复杂的格式。但在学术、法律和金融等领域它们不可或缺。那么,我们该如何让它们符合 RAG 系统的要求呢?
我们可以使用更智能的 OCR 技术、版面分析技术和视觉内容 - 语言融合技术:
- Levenshtein OCR 和 GTR 结合视觉和语言线索来提高识别准确率。
- OmniParser 和 Doc-GCN 专注于保留文档的结构。
- ABINet 采用双向处理机制提升 OCR 系统的表现。
与此同时,一大波开源工具的出现使得将 PDF 转换为 Markdown(一种对 LLM 更友好的格式)的过程变得更加容易。有哪些工具?我基本都已经介绍过了!
- GPTPDF6 利用视觉模型解析表格、公式等复杂版面结构,并快速转换为 Markdown 格式 ------ 该工具运行高效且成本低廉,适合大规模部署。
- Marker7 专注于清除噪声元素,同时还保留原始格式,因而成为处理研究论文和实验报告的首选工具。
- PDF-Extract-Kit(MinerU 采用的 PDF-Extract-Kit 模型库8)支持高质量内容提取,包括公式识别与版面检测。
- Zerox OCR9 对每页文档进行快照处理,通过 GPT 模型生成 Markdown,从而高效管理复杂文档结构。
- MinerU10 是一种综合解决方案,可保留标题/表格等原始文档结构,并支持受损 PDF 的 OCR 处理。
- MarkItDown11 是一种多功能转换工具,支持将 PDF、媒体文件、网页数据和归档文件转为 Markdown。
04 多模态知识:图像、音频与视频数据一同入场
传统 RAG 系统专为文本数据而设计,因此在处理图像、音频或视频等多模态信息时往往力不从心。这就导致其回应常显得肤浅或不完整 ------ 尤其当核心信息蕴含于非文本内容中时。
为应对这些挑战,多模态 RAG 系统引入了整合和检索不同模态的基本方法。其核心思想是将文本、图像、音频、视频等模态对齐到共享嵌入空间(shared embedding space),实现统一处理和检索。 例如:
- CLIP 在共享嵌入空间中对齐视觉与语言模态。
- Wav2Vec 2.0 和 CLAP 专注于建立音频与文本的关联。
- 在视频领域,ViViT 等模型专为捕捉时空特征而设计。
这些技术都是基础模块。随着系统的不断演进迭代,我们将看到能够一次性从文档、幻灯片及语音内容中提取洞见的 RAG 应用。
05 结语
在实践中,我发现 MinerU 是解析 PDF 的最佳开源工具。
当然,若你想自建文档解析器,自然需处理诸多复杂细节。但这样做的回报是值得的:更自主的源代码控制、更强的文档安全性,以及更可靠的结果。
后续若有契机,我将分享更多工程实践洞见。
我们正在超越纯文本语言模型的时代。倘若能教会机器理解人类传递知识的各种格式,或许它们也能协助我们更透彻地理解这个世界。
END
本期互动内容 🍻
❓未来 3 年,你认为文档解析技术会出现什么颠覆性突破?比如:LLM 原生解析 PDF?欢迎天马行空!
文中链接
1aiexpjourney.substack.com/t/pdf-parsi...
3aiexpjourney.substack.com/p/ai-innova...
4aiexpjourney.substack.com/p/ai-innova...
5aiexpjourney.substack.com/p/ai-innova...
6aiexpjourney.substack.com/p/ai-innova...
7aiexpjourney.substack.com/p/demystify...
9aiexpjourney.substack.com/p/ai-innova...
10aiexpjourney.substack.com/p/ai-innova...
11aiexpjourney.substack.com/p/ai-innova...
原文链接: