四、机器学习基础
1、训练数据集
-
我们自己准备的,用来训练模型的数据集,模型就可以根据这些数据集来学习规律,从而能够用来做预测未知的数据
-
如果模型学习到的内容比较少且单一,那么使用模型的时候一定效果比较差,训练模型一定要准备丰富的数据集
2、分类
-
监督学习:目前基本上所有的模型都是基于监督学习完成的
- 在训练模型的时候,我们准备的数据集需要打标签
-
半监督学习:
- 训练模型的时候,一部分数据集打标签,一部分不打标签
-
无监督学习:
- 训练模型的时候,数据集不打标签,让模型自己去学习其中的规律
-
强化学习:
- 涉及到让智能体在与环境的交互中,不断的优化自身,得到有利的反馈
-
打标签:
- 训练模型的时候,需要告诉模型,他学习的数据集里面某个内容是什么
3、上游任务和下游任务
-
上游任务:可以理解为就是做模型
-
下游任务:把模型拿来做应用
4、计算机视觉的三大任务
-
图像分类任务:模型需要识别到图像中的物体的类别即可
-
目标检测任务:模型需要识别到图像中的物体的类别和位置
-
图像分割任务
5、数据集的分类【重点】
-
**训练数据集:**训练模型,训练模型中有一个概念叫做训练多少次模型,即让模型去学习多少次训练数据集里面的内容,这个过程叫做 epochs【数据集需要打标签】
-
**验证数据集:**一般情况下,每 epoch 之后,就会使用验证数据集去验证训练出来的模型,基于验证的结果,去调整训练模型的超参数信息,利于模型的训练【不参与训练】【数据集需要打标签】
-
测试数据集: 模型训练好了之后,在已知的数据集中做测试【数据集需要打标签,一般是可选项,可以没有】
-
**推理:**模型训练好了之后,在未知的数据集上做测试【不打标签】 --- 还可以理解为就是把训练好的模型拿来做应用
五、sklearn库
-
机器学习阶段,基本上所有的 API 都来自于这一个库
-
安装环境步骤:【重点】
-
第一步:激活虚拟环境 --- 需要把库装在哪个环境就激活哪个环境
-
第二步:查找安装库的命令,尽可能的跟上镜像地址
-
-
pycharm 中,可以打开 terminal,实现环境的安装,好处
-
默认就激活了选择的虚拟环境
-
默认的路径就是当前项目的根路径
-
1、数据集
-
sklearn 库中提供了大量的内置数据, 这些数据集就是我们本阶段使用的重点内容,此外,还可以通过 sklearn 库去下载网络数据集【开VPN下】
-
自带的数据集:可以直接通过 skearn 库的对应 API 加载出来,分为了几种类型的数据集:分类数据集、线性回归数据
-
分类数据集:基于一些描述信息,得出这个描述的哪一个类别,这个类别数是提前规定好了的,比如数字分类,0-9 一共 10 个类别,输入一个内容 0 1 2 3 4 5,这个内容就属于 0-9 中间的一类
-
线性回归数据集:基于一些描述信息,得到这些信息基于方程【y = x + 1】计算出来的值,得到的输出是一个具体的值
-
-
数据集加载步骤:
-
导入对应的数据集函数,在 skleran.datasets 里面
-
通过调用函数,得到数据集(字典)
-
data:特征信息
-
target:目标信息(标签)
-
feature_names:特征信息的名称
-
target_names:目标信息的名称
-
-
数据集中的具体的数据内容获取(字典操作)
-
1.1、内置数据集
-
sklearn 模块的 datasets 子模块提供了多种自带的数据集
-
datasets 子模块主要提供了一些导入、在线下载及本地生成数据集的方法,常用三种:
-
本地加载数据:
sklearn.datasets.load_<name>_ -
远程加载数据:
sklearn.datasets.fetch_<name>_ -
构造数据集:
sklearn.datasets.make_<name>
-
-
内置数据集数据量小,数据在 sklearn 库的本地,只要安装了 sklearn 就可以获取,使用的重点就是以下几个数据集
| 数据集 | 获得方法 | 适用模型 |
|---|---|---|
| 波士顿房价数据集 | load_boston | 回归模型 |
| 鸢尾花数据集 | load_iris | 分类模型 |
| 糖尿病数据集 | load_diabetes | 回归模型 |
| 手写数字识别数据集 | load_digits | 分类模型 |
| Linnerud 数据集 | load_linnerud | 多输出回归模型 |
| 红酒数据集 | load_wine | 分类模型 |
| 乳腺癌数据集 | load_breast_cancer | 分类模型 |
1.2、网络数据集
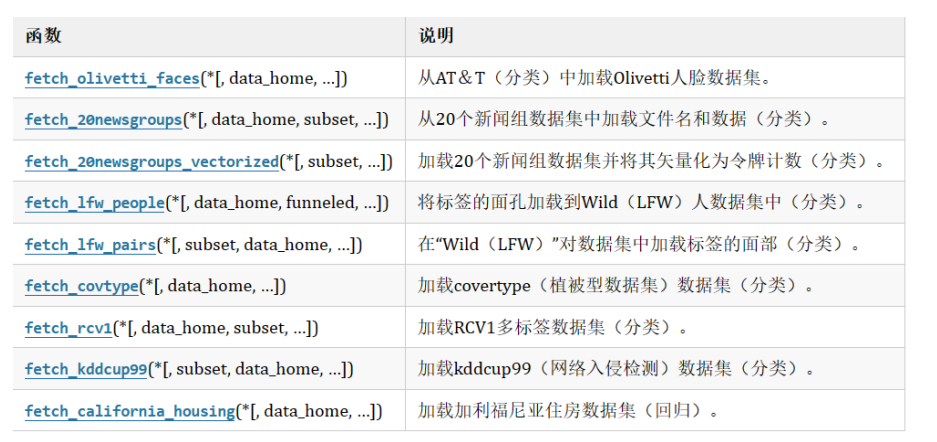
1.3、本地csv文件数据集
-
加载本地的 csv 文件数据集,可以使用 pandas 中的
read_csv函数 -
excel 文件同理
python
import pandas as pd
# 定义cvs文件的访问路径
path = "./guazi.csv"
# pandas读取csv文件
data = pd.read_csv(path)
print(type(data))
print(data[:5])2、加载内置数据集
以鸢尾花数据集为例:
-
鸢尾草数据集重要属性包含以下几个:
data:二维数组,每一行代表一个样本,每一列表示一个特征。这是实际用来训练和测试模型的数据部分
-
target:一维数组,包含了每个样本的目标值(即鸢尾花的类别标签)。对于鸢尾花数据集来说,标签是整数编码的,0 表示 Setosa,1 表示 Versicolour,2 表示 Virginicafeature_names:列表,包含了数据集中所有特征的名字
-
target_names:列表,包含了所有目标类别的名字。在这个数据集中,就是鸢尾花的三个种类DESCR:字符串,包含了关于数据集的详细描述,包括数据来源、特性、实验设计等信息
-
filename:字符串(可选),指向数据文件的位置
python
# 导入函数 --- load_iris:加载鸢尾花数据集的函数
from sklearn.datasets import load_iris
import numpy as np
import pandas as pd
# 获取数据集 --- 执行 load_iris 函数
iris = load_iris()
# print("数据集:\n", iris)
"""
数据集打印的内容中,是一个字典数据,key 介绍如下:
data:
对应了一个 array 二维数组数据
每一个元素是一个列表,列表中有四个元素,这四个元素就是鸢尾花的特征描述信息
对于我们来说,data 里面的内容就是:数据集
target:
对应了一个 array 一维数组数据
里面的元素由 0 1 2 组成,这个内容就是鸢尾花的标签
对于我们来说,target 里面的内容就是:结果、类别信息、目标
frame:None
target_names:
target 的实际名称,即 0 -- setosa 1 -- versicolor 2 -- virginica
DESCR:
数据集的描述
feature_names:
特征名称,四个值
'sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)'
分别对应 data 属性中的元素
"""
# 获取data属性
# data = iris['data']
data = iris.data
print("data:\n", data[:5])
print(data.shape)
# 获取target属性
target = iris.target
print("target:\n", target[:5])
print(target.shape)
# 获取target_names属性
target_names = iris.target_names
print("target_names:\n", target_names)
# 获取feature_names属性
feature_names = iris.feature_names
print("feature_names:\n", feature_names)
print("====================")
# 先把target的形状进行改变
target.shape = (len(target), 1)
print(target[:5])
# 把target的内容拼接在data后面,四个特征值决定了一个目标值
result = np.hstack((data, target))
print(result[:5])
# 把target列名加入到feature_names中
feature_names.append('target')
print(feature_names)
df = pd.DataFrame(result, columns=feature_names)
# 设置显示内容的格式
# 设置显示所有列
pd.set_option('display.max_columns', None)
# 设置控制台宽度,以容纳所有列名
pd.set_option('display.width', 200)
print(df.head())3、加载网络数据集
-
现实世界数据,需要通过网络才能下载后,保存到本地目录,可以通过
datasets.get_data_home()获取到存储的目录 -
下载时,有可能回为网络问题而出题
-
如果硬盘中已经下载了这个数据集,直接加载,否则会下载到磁盘中
以newsgroups为例:
sklearn.datasets.fetch_20newsgroups 是一个用于加载 20 Newsgroups 数据集的函数。这个数据集包含大约 2 万篇新闻组文章,分别来自 20 个不同的新闻组。它是文本分类任务的一个标准数据集,常用于文本挖掘、自然语言处理(NLP)等领域的研究
python
from sklearn.datasets import fetch_20newsgroups
"""
fetch_20newsgroups 函数参数:
1、data_home:数据集下载之后存储的路径
2、subset:选择下载的数据集的类型,train:训练数据集、test:测试数据集、all:训练+测试
3、return_X_y:bool, default=False
"""
news = fetch_20newsgroups(data_home="./", subset="all", return_X_y=False)
print(news)六、数据集划分
数据集的划分,主要就是把我们的总数据划分为训练数据和测试数据两个部分
6.1、可变参数
在 Python 中,可变参数(也称为不定长参数)是指函数可以接受任意数量的参数。Python 支持两种类型的不定长参数:
-
位置不定长参数 :使用星号
*前缀来收集额外的位置参数,并将它们打包成一个元组(tuple) -
关键字不定长参数 :使用双星号
**前缀来收集额外的关键字参数,并将它们打包成一个字典(dictionary)
python
def a(*k, **p):
print(k) # (1, 2, 3)
print(p) # {'username': 'chenlei', 'password': '111'}
if __name__ == '__main__':
a(1, 2, 3, username="chenlei", password="111")
"""
python 中的语法可变参数:
*k:给函数传递参数的时候,无论的写入多少个非key=value格式的数据都给到*k里面,输出元组
**p:给函数传递参数的时候,传入的key=value格式数据就给到**p,输出字典
"""6.2 train_test_split 函数
-
train_test_split是sklearn.model_selection库中的一个非常实用的函数,用于将数据集划分为训练集和测试集。这种划分是机器学习流程中的重要步骤之一,它有助于评估模型在未见过的数据上的性能,从而避免过拟合 -
函数描述如下:
- 主要参数及其作用:
参数名 类型 默认值 可选值/说明 *arrayslist, numpy array, pandas DataFrame 等 - 传入一个或多个数组(如特征 X和标签y)test_sizefloat 或 int 0.25测试集大小:若为浮点数表示比例(如 0.2),若为整数表示样本数量train_sizefloat 或 int 自动计算 训练集大小,若未指定则根据 test_size推导random_stateint 或 RandomState实例 或NoneNone控制随机种子,确保每次划分一致(可复现) shufflebool True是否在划分前打乱数据,默认开启;关闭后按顺序划分 stratifyarray-like 或 None None用于分类任务中保持类别分布一致性(常用于不平衡数据 -
返回值:
-
train_test_split函数返回一个元组,包含分割后的数据集。具体返回值的数量取决于传入的数组数量。如果传入两个数组(如X和y),则返回四个数组;如果传入三个数组,则返回六个数组,依此类推。返回值的数据类型和传入函数进行分割的数据类型一致 -
对于两个数组的情况,返回值如下:
返回值 类型 描述 X_trainarray-like 划分后的训练集特征数据 X_testarray-like 划分后的测试集特征数据 y_trainarray-like 划分后的训练集目标变量(标签) y_testarray-like 划分后的测试集目标变量(标签) -
python
"""
假设我们要训练一个鸢尾花分类的模型,那么我们就需要把鸢尾花数据集拿来做训练
不可以把训练了的数据集再用来做测试,因为数据集已经被学习过,那么模型肯定知道它是什么类型的,我们应该使用为参数训练的数据集来测试
所以:我们需要把鸢尾花数据集拿来做划分,一般训练:测试 = 8:2 7:3 --- 训练数据 >>> 测试数据集
训练数据集、测试数据集中的数据,不可以出现训练的时候没有某一个种而测试的时候有
划分数据集使用的是 sklearn 库中的 model_selection 下的 train_test_split 函数,这个函数有几个参数需要掌握:
1、*arrays:传入的1-多个数组,就是需要被划分的数据集
1 个数组被划分成 2 份
2 个数组被划分成 4 份【一般选择,一个是特征信息、一个是标签】
2、test_size:测试集划分的比例 --- 一般是0.0-1.0之间,默认0.25
3、train_size:训练集划分的比例
test_size 和 train_size 参数之间会相互计算
4、random_state:随机数种子,不设置,每一次划分出来的数据集不一致,设置了,每一次划分出来的内容一致
5、shuffle:是否打乱数据集在划分,需要打乱
总结:
1、数据集划分前后的数据类型是一致的
2、二维数组划分的时候,是基于行划分的,列是没有改变的
"""
# 导入划分数据集的函数
from sklearn.model_selection import train_test_split
# 导入数据集函数
from sklearn.datasets import load_iris
import numpy as np
# 加载鸢尾花数据集
iris = load_iris()
# 特征信息
data = iris.data
print("data:", type(data))
# 标签信息[目标值]
target = iris.target
print("target:", type(target))
# 调用划分数据集函数,实现数据集的划分
X_train, X_test, y_train, y_test = train_test_split(data,
target,
test_size=0.2,
random_state=42)
print("X_train:", type(X_train))
print("X_test:", type(X_test))
print("y_train:", type(y_train))
print("y_test:", type(y_test))
# print(len(X_train))
# print(len(X_test))
# print(len(y_train))
# print(len(y_test))
# print(X_train[:2])
# print(X_test[:2])
# print(y_train[:2])
# print(y_test[:2])
"""
np.arange 函数:创建一个从哪里开始到那里结束的数组 [start,end),最后一个参数是步长
"""
# 随机生成一个数组
data1 = np.arange(1, 16, 1)
# 把数组改变形状,改成 5 行 3 列
data1 = data1.reshape(5, 3)
print(data1)
# target数据
target1 = np.array([0, 1, 1, 2, 0])
X_train1, X_test1, y_train1, y_test1 = train_test_split(data1,
target1,
test_size=0.2,
random_state=42)
print("X_train1:\n", X_train1)
print("X_test1:\n", X_test1)6.2.1、字典数据集划分
需要使用到一个 API,DictVectorizer
python
"""
字典数据集的意思就是,多个特征,特征有的是中文和英文描述,并非全部类似于鸢尾花数据集,都是数字
我们计算机只能够识别 0 1,那么我们就需要把中文和英文特征转换为数字,从而训练模型
需要使用到一个 API,字典特征提取的 API【from sklearn.feature_extraction import DictVectorizer】
"""
# 定义一个数据集
data = [
{"name": "张三", "address": "成都", "age": "18"},
{"name": "lisi", "address": "重庆", "age": "20"},
{"name": "王五", "address": "贵州", "age": "30"},
]
# 如果想要把 data 数据集用来做模型的训练,第一个步骤就是进行数据集的转换,这里需要使用字典特征提取的api
# 导入字典特征的提取的类
from sklearn.feature_extraction import DictVectorizer
# 通过DictVectorizer类来创建一个对象,字典特征提取对象
"""
sparse:可以选择 True、False,用来控制输出的类型是什么
True:默认值,
False:
"""
dict_vec = DictVectorizer(sparse=False)
# 执行特征提取操作
result = dict_vec.fit_transform(data)
print(result)
print(type(result))
"""
在n维中,如果进行特征提取之后,进行特征信息表达,选择的是 one-hot 编码【独热编码】
那么就会类似于这样存储[0 1 0 0 ... 0] 即只有一个位置上是1,其余都是0
这样的存储方式不好,因为他占内存空间,有用的信息又少,这样存储的结果叫做高维稀疏
[[ 0. 0. 1. 18. 0. 0. 1.]
[ 1. 0. 0. 30. 1. 0. 0.]
[ 0. 1. 0. 40. 0. 1. 0.]]
这就是一个字典特征提取的结果,是一个 one-hot 编码的结果
one-hot 编码,只有一个位置为1,其余位置都是 0
七个特征 name=张三、name=lisi、name=王五、address.....
['address=成都', 'address=贵州', 'address=重庆', 'age', 'name=lisi', 'name=张三', 'name=王五']
第1列:
第2列:
第3列:
第4列:年龄
第5列:
第6列:
第7列:
"""
# 获取每一列的名称
print(dict_vec.get_feature_names())