视觉Transformer
Transformer 已成功应用于计算机视觉领域,并在许多任务中表现出色。在视觉领域判别任务最常见的选择是视觉 Transformer(Vision Transformer,简称 ViT)(Dosovitskiy et al., 2020)。在使用 Transformer 时,需要决定如何将输入图像转换为 token,最简单的选择是将每个像素作为一个 token 并按照线性投影进行转换。由于Transformer的复杂度随 token 数量平方增长,所以需要限制 token 数量。
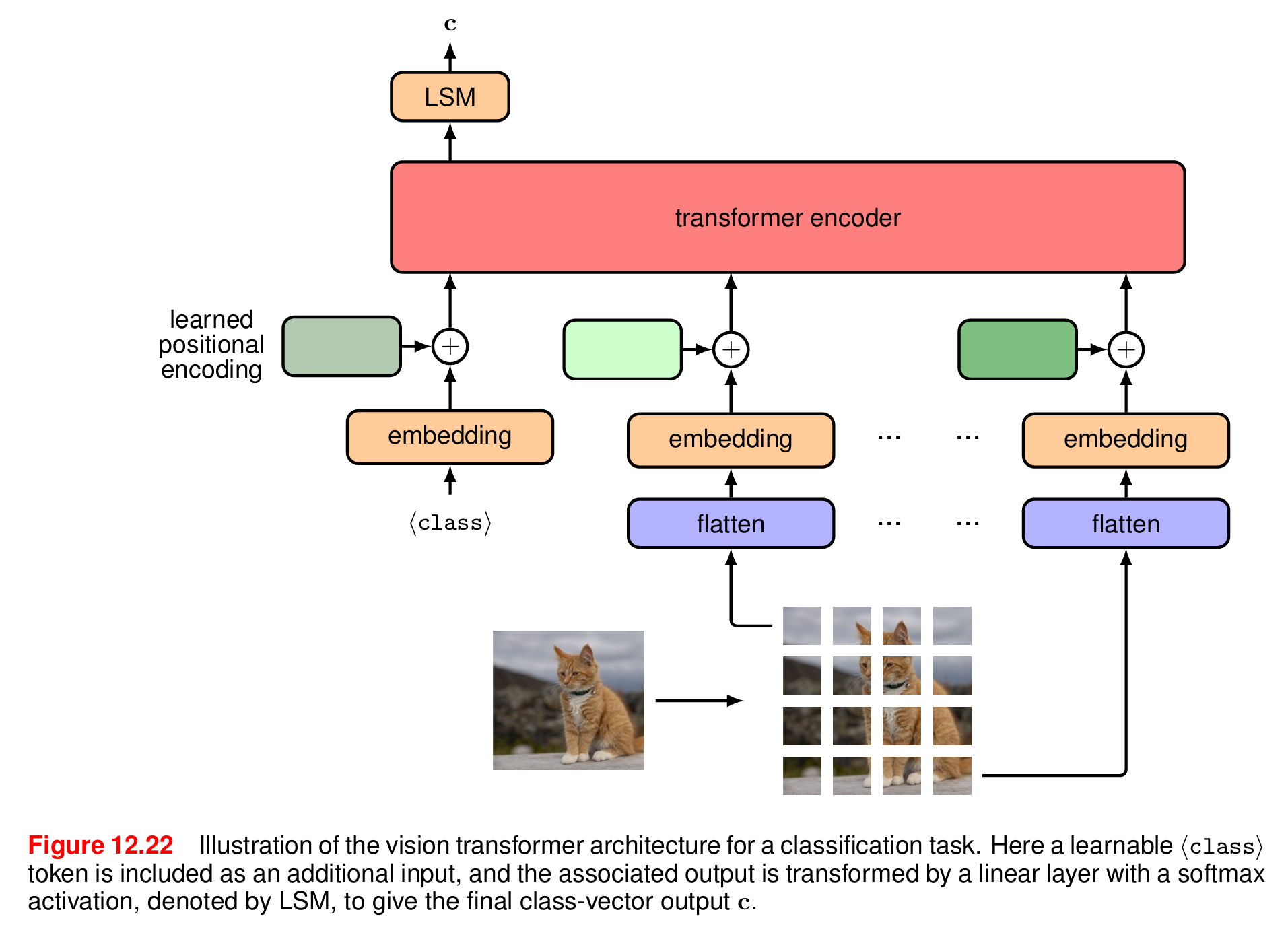
最常见的分词方法是将图像分割成一组大小相同的小块,然后通过线性变换映射为 token。假设图像的尺寸为 x ∈ R H × W × C \boldsymbol{x} \in \mathbb{R}^{H \times W \times C} x∈RH×W×C,其中 H H H和 W W W分别指的是图像的高度和宽度(以像素为单位), C C C是通道数(R、G、B 三种颜色的通道数通常为 3)。每幅图像被分割成大小为 P × P P \times P P×P的非重叠小块( P = 16 P = 16 P=16是常见的选择),然后"平铺"成一维向量,这样就得到了图像尺寸的另一种表示 x p ∈ R N × ( P 2 C ) \boldsymbol{x}_p \in \mathbb{R}^{N \times (P^2C)} xp∈RN×(P2C),其中 N = H W / P 2 N = HW / P^2 N=HW/P2是一幅图像的小块总数。用于分类任务的视觉 Transformer 的架构如图所示。
另一种分词方法是将图像输入一个小型卷积神经网络。这样就可以对图像进行采样,从而得到数量可控的 token,每个 token 由一个网络输出表示。例如,一个典型的 ResNet18 编码器将在高度和宽度两个维度对图像进行 8 倍的下采样,所得的 token 数量是像素数量的 1 / 64 1/64 1/64。
Transformer 模型本身不感知顺序或空间位置,因此需要额外添加位置信息。需要一种在 token 中编码位置信息的方法。可以使用固定的正弦/余弦位置编码,对图像小块的二维位置信息进行编码。但在实践中,这一般不会提高性能。在 ViT 中,通常为每个 patch 添加一个可学习的位置嵌入向量。与用于自然语言的 Transformer 不同,视觉 Transformer 通常将固定数量的 token 作为输入,从而避免了可学习的位置编码无法泛化到不同大小的输入的问题。
视觉 Transformer 的架构设计与卷积神经网络截然不同。虽然卷积神经网络中会产生强先验假设(如局部性、平移不变性),但视觉 Transformer 中唯一的二维归纳偏置是用于 token 化输入的小块造成的。因此,视觉 Transformer 通常比卷积神经网络需要更多的训练数据,来学习图像的空间结构。由于对输入的结构没有很强的假设,视觉 Transformer 通常能够达到更高的精度。这再次说明了归纳偏置与训练数据规模之间需要权衡(Sutton, 2019)。