一. xxl-job路由策略有哪些?
XXL-JOB 在执行器集群 场景下,一共提供了 10 种路由策略 ,可分为**「单节点路由」「集群负载路由」「故障&忙碌转移」「并行分片」**四大类,配置时直接在调度中心任务编辑页 "路由策略" 下拉框选取即可。
实际开发建议
- 默认选择
ROUND(负载均衡-轮询**)或FAILOVER(** 故障转移**)** :
ROUND适合大多数无状态任务,实现简单且负载均衡。FAILOVER适合对高可用性要求高的任务(如支付、订单处理)。- 分片广播(
SHARDING_BROADCAST) :
- 用于需要全集群协作的场景(如数据同步、批量计算)。
- 一致性哈希(
CONSISTENT_HASH) :
- 适用于有状态任务(如用户分区、分库分表),避免频繁迁移。
- 故障转移(
FAILOVER) :
- 当任务依赖特定资源时,需优先配置此策略以提高容错能力。
| 类型 | 策略关键字 | 一句话说明 | 典型场景 |
|---|---|---|---|
| 单节点 | FIRST | 固定选第一个注册成功的机器 | 要求任务永远在同一台机器执行,如单机批账 |
| 单节点 | LAST | 固定选最后一个注册的机器 | 临时测试、灰度节点 |
| 负载均衡 | ROUND | 轮询各节点(24 h 计数缓存) | 最常用,简单均匀 |
| 负载均衡 | RANDOM | 随机挑一台 | 简单打散流量 |
| 负载均衡 | CONSISTENT_HASH | 按任务标识做一致性哈希,同一任务永远落到同一节点 | 用户级/订单级任务,避免分布式锁 |
| 负载均衡 | LEAST_FREQUENTLY_USED | 最少使用次数优先 | 节点性能不均时 |
| 负载均衡 | LEAST_RECENTLY_USED | 最近最久未用优先 | 节点冷启动均衡 |
| 故障转移 | FAILOVER | 顺序心跳探测,第一台存活即执行 | 高可用关键任务 |
| 忙碌转移 | BUSYOVER | 顺序空闲探测,第一台空闲即执行 | CPU/内存敏感任务 |
| 并行分片 | SHARDING_BROADCAST | 一次性广播 给所有节点,各节点按 shardIndex / shardTotal 并行处理 |
大数据批处理、全量对账 |
二. xxl-job任务执行失败怎么解决?
XXL-Job 内置了多种失败处理机制,可通过配置和界面化操作,快速应对临时故障:
- 第一:路由策略选择故障转移,优先使用健康的实例来执行任务
- 第二,如果还有失败的,我们在创建任务时,可以设置重试次数
- 第三,如果还有失败的,就可以查看日志或者配置邮件告警来通知相关负责人解决
XXL-Job 任务失败的处理流程可总结为:
- "任务一旦失败,我先在控制台 Rolling 日志 看堆栈;
- 若是偶发,直接 重试 3 次;
- 若是节点离线,切 FAILOVER(故障转移);
- 若是业务 BUG,本地修复后 灰度上线 ,并通过 邮件+钉钉 告警闭环。
- 最后把失败记录落到本地补偿表,凌晨补偿任务自动兜底,保证最终一致。"
先"快速止血"再"根治"。生产上我把它总结成 "三板斧 + 五步走",现场按这个顺序排查,基本 10 分钟就能定位。
1. 三板斧(分钟级止血)
| 招式 | 操作路径 | 作用 |
|---|---|---|
| 1. 立即重试 | 调度中心 → 任务列表 → "执行一次" | 排除偶发网络抖动 |
| 2. 调大重试次数 | 任务编辑 → "失败重试次数"改成 3~5 次 → 保存 | 减轻人工干预 |
| 3. 一键暂停 | 调度中心 → 任务 → "停止" / 调 API POST /jobinfo/stop |
防止失败任务雪崩 |
2. 五步走(根治流程)
① 看日志 ------ 秒级定位
-
调度中心 → "执行日志" → 点失败记录 → Rolling 实时日志 直接看堆栈 。
-
如果是 执行器节点 宕机,日志会报
connect timeout;如果是业务 NPE,能看到具体行号。
② 判断类型
| 现象 | 常见根因 | 快速验证 |
|---|---|---|
| 调度成功但执行失败 | 业务空指针 / 数据异常 | 手动触发一次,本地 Debug |
| 调度失败 | 执行器离线 / 时钟漂移 / IP 变化 | 执行器列表是否变灰 |
| 死循环/超时 | 任务逻辑 BUG | 任务编辑 → "超时时间"设 10 min,自动 kill |
③ 调整配置
-
超时保护:任务编辑 → "超时时间"= 业务最大耗时×2。
-
路由策略 :改为 FAILOVER 或 BUSYOVER,让健康节点接管 。
-
阻塞策略 :如果任务来不及处理,选择 "丢弃后续调度" 或 "覆盖之前调度" 避免堆积 。
④ 业务补偿
-
本地表补偿 :失败记录写入
xxl_job_fail_log,定时任务扫表重跑。 -
幂等兜底 :关键步骤加
ON DUPLICATE KEY UPDATE或 Redis 幂等 token,防止重试重复消费。
⑤ 告警闭环
-
调度中心 已支持 邮件、钉钉、企业微信 报警,配置在
application.properties里加:
xxl.job.mail.username=alert@xxx.com失败即 @值班群,人工二次介入 。
三. 关于xxl-job 如果有大数据量的任务同时都需要执行,怎么解决?
在 XXL-Job 中处理大数据量任务的并发执行,核心思路是 拆分任务、控制并发、扩容资源、优化执行,结合框架特性和分布式架构设计。
- 拆分任务:用分片广播将大数据量拆分为子任务,并行处理;
- 控制并发:通过错开触发时间、配置阻塞策略避免任务堆积;
- 扩容资源:增加执行器实例和硬件配置,提升集群处理能力;
- 优化执行:批量处理、异步化、缓存等手段缩短单任务耗时;
- 错峰调度:避开业务高峰,减少资源竞争。
1. 任务拆分:将 "大数据量单任务" 拆分为 "小数据量子任务"(核心手段)
大数据量任务(如全量数据同步、批量计算)的本质问题是 "单节点处理压力过大",通过分片广播(Sharding Broadcast) 策略拆分任务,实现分布式并行处理。
实现方式:
- 配置分片参数:在 XXL-Job Admin 中,将任务路由策略设置为 "分片广播",并指定 "分片总数"(如按数据量拆分为 10 片)。
- 执行器处理分片 :每个执行器实例通过
XxlJobHelper.getShardIndex()获取自身负责的分片序号(0~n-1),仅处理对应分片的数据。 - 分片规则设计 :
- 按 "ID 范围" 分片:如分片 0 处理 ID 1~10000,分片 1 处理 10001~20000(适合有序 ID)。
- 按 "哈希取模" 分片:如
user_id % 分片数,确保同用户数据由同一执行器处理(适合需状态一致性的场景)。
示例代码:
java
@XxlJob("bigDataSyncJob")
public void execute() {
// 获取分片信息(总片数、当前分片索引)
int shardTotal = XxlJobHelper.getShardTotal(); // 如10
int shardIndex = XxlJobHelper.getShardIndex(); // 如0~9
// 处理当前分片数据:仅查询属于当前分片的记录
List<Data> dataList = dataMapper.queryByShard(shardIndex, shardTotal);
for (Data data : dataList) {
// 处理单条数据(如同步到目标库)
syncData(data);
}
XxlJobHelper.handleSuccess("分片" + shardIndex + "处理完成");
}优势:将大数据量分散到多个执行器并行处理,单节点压力降低 N 倍(N 为分片数),执行效率线性提升。
2. 控制并发:避免任务集中触发导致资源耗尽
当大量任务同时触发时,需通过调度策略控制并发量,防止执行器线程池满、数据库连接耗尽等问题。
(1) 调度层面:错开任务触发时间
- 分散触发:对批量任务设置不同的 CRON 表达式(如每 10 分钟触发一批,而非同一时间全部触发)。
- 父子任务依赖:核心任务优先执行,非核心任务作为子任务依赖核心任务完成后再触发(通过 XXL-Job 的 "子任务 ID" 配置)。
(2)执行层面:限制单执行器并发数
- 配置任务阻塞策略 :在 XXL-Job Admin 中,对任务设置 "阻塞处理策略":
- 若任务执行时间长,选择 "丢弃后续调度"(避免同一任务重复触发);
- 若任务需及时执行,选择 "覆盖之前任务"(终止旧任务,执行新任务)。
- 调整执行器线程池 :在执行器配置中增大线程池参数(
xxl.job.executor.threadPool.coreSize),确保有足够线程处理并发任务(如从默认 20 调整为 50)。
3. 资源扩容:通过集群提升整体处理能力
当单执行器集群仍无法承载时,通过 "水平扩容执行器" 和 "优化资源配置" 提升处理能力。
(1) 执行器集群扩容
- 部署更多执行器实例(如从 3 台扩至 10 台),注册到同一执行器分组,调度中心会自动将任务分发到新实例。
- 结合 "轮询" 或 "一致性哈希" 路由策略,均衡分配任务到各实例,避免单实例负载过高。
(2) 提升单节点资源配置
- 增加执行器服务器的 CPU 核数、内存(如从 4 核 8G 升级为 8 核 16G),避免硬件瓶颈。
- 优化依赖资源(如数据库分库分表、Redis 集群),避免任务执行时因依赖资源卡顿(如查询慢 SQL 阻塞任务)。
4. 任务优化:减少单任务执行耗时
通过优化任务本身的执行逻辑,缩短单任务处理时间,间接提升并发能力。
(1)批量处理代替逐条处理
- 对数据库操作,采用 "批量插入 / 更新"(如 MyBatis 的
foreach批量 SQL),减少 IO 次数(如 1 次批量处理 1000 条,代替 1000 次单条处理)。
(2)异步化非核心步骤
- 将 "日志记录""通知推送" 等非核心操作异步化(如提交到本地线程池或消息队列),避免阻塞主任务流程。
(3)缓存热点数据
- 对任务中频繁访问的静态数据(如字典表、配置信息),提前加载到本地缓存(如 Caffeine),减少重复查询。
5. 错峰执行:避开业务高峰期
- 对非实时任务(如数据统计、报表生成),将执行时间调整到业务低峰期(如凌晨 2~6 点),避免与核心业务(如下单、支付)争夺 CPU、数据库等资源。
- 通过 XXL-Job 的 "任务触发时间" 配置,灵活调整执行时段
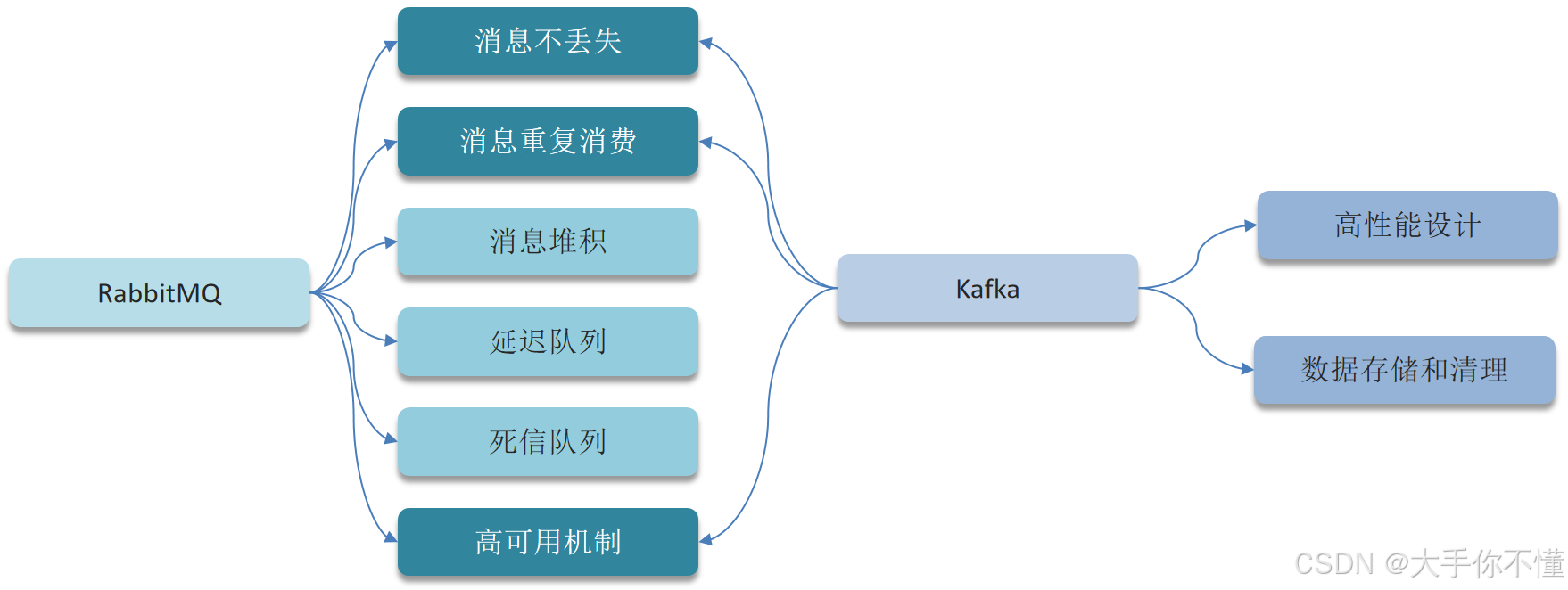
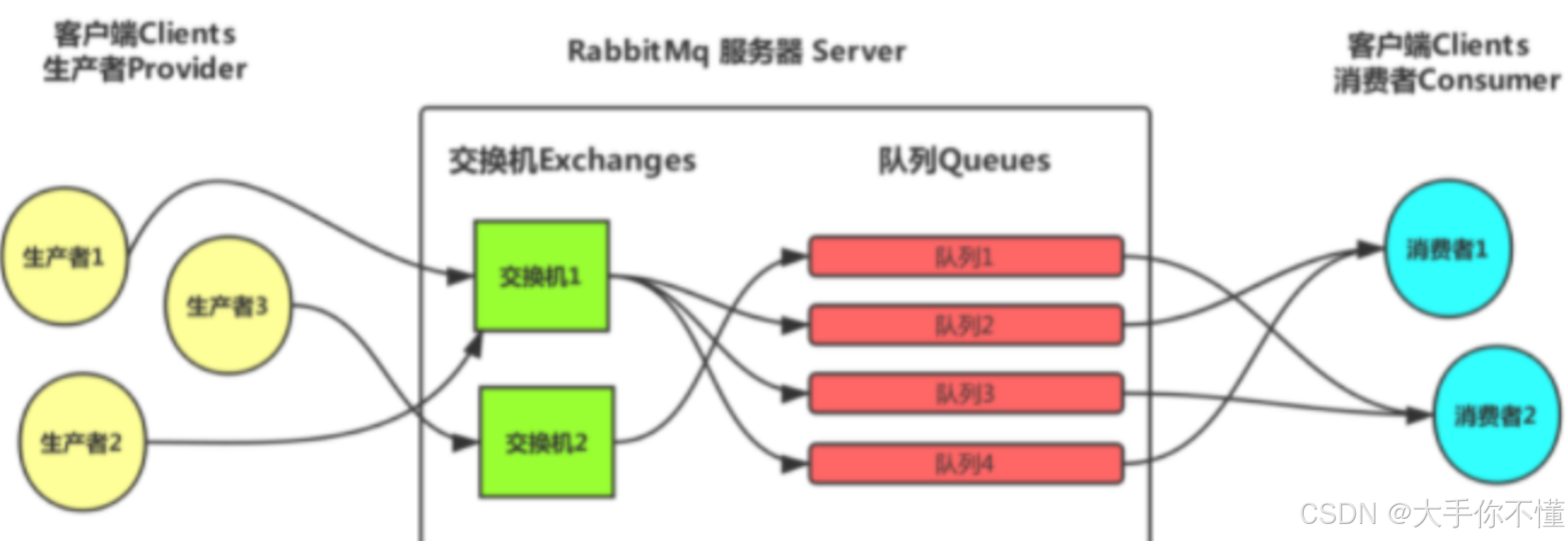
消息队列中间件相关(以RabbitMQ与Kafka为例):
四. RabbitMQ-如何保证消息不丢失
- 生产者 :
- 第一个是开启生产者确认机制,确保生产者的消息能到达队列
- RabbitMQ 会在消息成功到达交换机 / 队列后,向生产者返回确认通知(ACK);若失败则返回否定通知(NACK)。
- 如果报错可以先记录到日志中,再去修复数据
- RabbitMQ本身(Broker可以直接理解为 RabbitMQ 本身的一个实例) :
- 第二个是开启持久化功能,确保消息未消费前在队列中不会丢失,
- 其中的交换机、队列、和消息都要做持久化
- 消费者 :
- 第三个是关闭自动ACK,手动ACK确认(防止消费端崩溃,自动ACK导致消息未处理即被删除);设置死信队列处理异常;通过幂等性防止重复消费
(一)生产者端:确保消息成功发送到Broker
-
开启Publisher Confirm机制
- 作用 :生产者发送消息后,等待Broker的确认(
Basic.Ack),确保消息已到达Broker。 - 实现方式 :
-
同步确认 (适用于低并发场景):
javachannel.confirmSelect(); // 开启确认模式 channel.basicPublish("exchange", "routingKey", null, "消息内容".getBytes()); if (channel.waitForConfirms()) { System.out.println("消息已成功发送到Broker"); } else { System.out.println("消息发送失败,需重试"); } -
异步确认 (推荐,适用于高并发场景):
javachannel.confirmSelect(); channel.addConfirmListener((deliveryTag, multiple) -> { System.out.println("消息确认成功"); }, (deliveryTag, multiple) -> { System.out.println("消息确认失败,需重试"); }); channel.basicPublish("exchange", "routingKey", null, "消息内容".getBytes());
-
- 作用 :生产者发送消息后,等待Broker的确认(
-
开启Return Callback机制
-
作用 :如果消息无法路由到队列(如队列不存在或未绑定),RabbitMQ会通过
basic.return回调通知生产者。 -
实现方式 :
javachannel.addReturnListener((replyCode, replyText, exchange, routingKey, properties, body) -> { System.out.println("消息无法路由,需重试"); System.out.println("消息内容: " + new String(body)); }); channel.basicPublish("exchange", "invalidRoutingKey", true, false, properties, message.getBytes());
-
-
使用事务(性能较差,慎用)
-
作用:通过事务确保消息发送成功,否则回滚。
-
实现方式 :
javatry { channel.txSelect(); // 开启事务 channel.basicPublish("exchange", "routingKey", null, "消息内容".getBytes()); channel.txCommit(); // 提交事务 } catch (Exception e) { channel.txRollback(); // 回滚事务 System.out.println("事务异常,消息需重试"); }
-
(二)Broker端:确保消息持久化
-
队列持久化
-
作用 :声明队列时设置
durable=true,确保Broker重启后队列仍然存在。 -
代码示例 :
javachannel.queueDeclare("persistent_queue", true, false, false, null);
-
-
消息持久化
-
作用 :发送消息时设置
delivery_mode=2,确保消息写入磁盘。 -
代码示例 :
javaAMQP.BasicProperties props = new AMQP.BasicProperties.Builder() .deliveryMode(2) // 持久化消息 .build(); channel.basicPublish("exchange", "routingKey", props, "消息内容".getBytes());
-
-
交换机持久化 :声明交换机时设置
durable=true,确保 RabbitMQ 重启后交换机不丢失。javachannel.exchangeDeclare(exchangeName, "direct", true); -
镜像队列(HA模式)
-
作用:通过镜像队列将消息同步到多个节点,避免单点故障。
-
配置示例 :
java# 设置队列镜像策略(同步到所有节点) rabbitmqctl set_policy ha-all "^ha\." '{"ha-mode":"all","ha-sync-mode":"automatic"}'
-
(三)消费者端:确保消息被正确处理
-
手动ACK确认
-
作用:消费者处理完消息后,手动发送ACK,确保消息不会因消费者崩溃而丢失。
-
代码示例 :
javaDeliverCallback deliverCallback = (consumerTag, delivery) -> { String message = new String(delivery.getBody(), "UTF-8"); try { // 执行业务逻辑 channel.basicAck(delivery.getEnvelope().getDeliveryTag(), false); // 手动确认 } catch (Exception e) { channel.basicNack(delivery.getEnvelope().getDeliveryTag(), false, true); // 拒绝并重新入队 } }; channel.basicConsume("queue_name", false, deliverCallback, consumerTag -> {});
-
-
幂等性设计
- 作用:避免消息重复消费(如手动ACK失败后消息重投)。
- 实现方式 :
- 在消息中加入唯一标识符(如UUID),记录已处理的消息ID。
- 使用数据库唯一约束或Redis缓存校验是否已处理过该消息。
-
消息补偿机制
- 作用:在极端情况下(如Broker宕机且磁盘损坏),通过业务层补偿。
- 实现方式 :
- 生产者发送消息前,先将消息与业务数据一起入库(事务一致性)。
- 若消息丢失,通过定时任务扫描未处理的业务数据并补偿发送。
(四)总结:消息不丢失的关键点
| 环节 | 风险点 | 解决方案 |
|---|---|---|
| 生产者 | 网络异常导致消息未到达Broker | Publisher Confirm + Return Callback |
| Broker(RabbitMQ) | Broker宕机或消息未持久化 | 队列/消息持久化 + 镜像队列 |
| 消费者 | 自动ACK导致消息未处理即被删除 | 手动ACK + 幂等性设计 |
| 综合保障 | 极端场景下消息丢失 | 消息补偿机制(业务层冗余) |
(五)代码示例:完整消息发送与消费流程
java
// 生产者:发送持久化消息 + 确认机制
public class Producer {
public static void main(String[] args) throws Exception {
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("localhost");
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
// 声明持久化队列
channel.queueDeclare("persistent_queue", true, false, false, null);
// 开启确认机制
channel.confirmSelect();
channel.addConfirmListener((deliveryTag, multiple) -> {
System.out.println("消息确认成功");
}, (deliveryTag, multiple) -> {
System.out.println("消息确认失败,需重试");
});
// 发送持久化消息
AMQP.BasicProperties props = MessageProperties.PERSISTENT_TEXT_PLAIN;
channel.basicPublish("", "persistent_queue", props, "Hello RabbitMQ!".getBytes());
channel.close();
connection.close();
}
}
// 消费者:手动ACK + 幂等性处理
public class Consumer {
public static void main(String[] args) throws Exception {
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("localhost");
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
// 手动确认模式
DeliverCallback deliverCallback = (consumerTag, delivery) -> {
String message = new String(delivery.getBody(), "UTF-8");
try {
// 业务逻辑处理(例如写入数据库)
System.out.println("收到消息: " + message);
channel.basicAck(delivery.getEnvelope().getDeliveryTag(), false);
} catch (Exception e) {
// 拒绝消息并重新入队
channel.basicNack(delivery.getEnvelope().getDeliveryTag(), false, true);
}
};
channel.basicConsume("persistent_queue", false, deliverCallback, consumerTag -> {});
}
}五. RabbitMQ消息的重复消费问题如何解决的
消息重复的根本原因(网络延迟、消费者宕机、手动确认机制不合理)
- 生产者重复推送(自动ack可能会导致消息丢失)
- 网络波动导致生产者未收到RabbitMQ的确认(ACK),误认为消息未发送成功,触发重试。
- 消费者失败重试(自动ack可能会导致消息丢失)
- 消费者处理消息失败但未及时发送ACK,RabbitMQ会重新投递消息。
- 集群脑裂
- RabbitMQ集群故障恢复时,可能因节点状态不一致导致消息重复投递。
解决方案 适用场景 优点 缺点 幂等性设计 所有业务场景 业务逻辑天然防重 需要业务支持,开发成本高 消息去重 高并发、分布式场景 实现简单,通用性强 依赖 Redis/DB,可能有性能瓶颈 手动 ACK 需要严格保证消息不丢失的场景 避免消息丢失,可靠性高 需要处理异常和重试逻辑 分布式锁 多消费者竞争场景 避免多线程/多节点重复处理 锁粒度控制复杂,可能阻塞
(一)解决方案
1. 保证消费者幂等性(核心)
核心原则 :无论消息被消费多少次,结果一致。
实现方式:
(1)数据库唯一约束
- 利用数据库主键或唯一索引防止重复写入(例如订单号唯一)。
- 示例:插入订单时,若订单号已存在,则直接返回成功。
java
@Transactional
public void consume(OrderMsg msg) {
try {
orderMapper.insert(msg); // 主键冲突直接回滚,天然幂等
} catch (DuplicateKeyException e) {
log.warn("重复消费,丢弃 msgId={}", msg.getMsgId());
}
}(2)幂等表(通用场景)
-
单独建一张
msg_log(id, msg_id, status, create_time),用msg_id做唯一索引。 -
流程:
-
消费前先
insert ignore into msg_log -
影响行数 = 0 → 已处理过,直接丢弃
-
影响行数 = 1 → 继续执行业务,成功后更新状态
-
-
优点:与业务表解耦,易复用。
(3)Redis SETNX(高并发场景)
-
利用
SETNX(或setIfAbsent)原子性写入。 -
代码:
javaString key = "mq:" + msgId; Boolean absent = redisTemplate.opsForValue() .setIfAbsent(key, "1", Duration.ofHours(1)); if (Boolean.FALSE.equals(absent)) { log.warn("重复消费,丢弃 msgId={}", msgId); return; } // 执行本地业务...
(4)Token机制
- 预生成唯一Token,处理时校验并删除。
- 示例:生成全局唯一ID(如UUID),处理时验证Token是否已使用。
java
@RestController
class IdempotentController {
@Autowired
private StringRedisTemplate rt;
// 1. 申请一次性 token
@GetMapping("/token")
String token() {
String t = UUID.randomUUID().toString();
rt.opsForValue().set(t, "1", Duration.ofMinutes(5));
return t;
}
// 2. 下单接口:校验并删除 token
@PostMapping("/order")
String order(@RequestParam String token) {
// 原子操作,Redis的 DEL命令天然 "检查存在即删除",一行搞定幂等。
Boolean del = rt.delete(token);
if (!Boolean.TRUE.equals(del)) return "重复请求";
// TODO: 真正的业务写库
return "success";
}
}(5)乐观锁(mysql锁机制)
乐观锁假设并发冲突较少,不直接锁定记录,而是在更新时检查 数据是否被其他事务修改过。通过版本号(
version)或时间戳(timestamp)检测数据是否被修改:
- 插入操作:结合唯一索引,确保唯一性。
- 更新操作:检查版本号,仅允许更新未被修改的数据。
-
场景1:防止重复插入
sql-- 添加唯一索引 ALTER TABLE orders ADD UNIQUE INDEX un_order_code (order_code); -- 插入订单(若 order_code 已存在,则抛出异常) INSERT INTO orders (order_code, amount) VALUES ('20250818001', 100);- 处理方式:捕获唯一约束异常,返回"已存在"的提示。
-
场景2:防止重复更新
sql-- 更新订单金额,检查版本号 UPDATE orders SET amount = amount + 100, version = version + 1 WHERE id = 1 AND version = 1;- 处理方式 :若
version不匹配(更新失败),则认为该操作已执行过,直接返回成功。
- 处理方式 :若
(6)悲观锁(mysql锁机制)
悲观锁假设并发冲突频繁,在操作数据时直接加锁 (如
SELECT ... FOR UPDATE)查询时锁定数据,确保事务独占数据。
- 插入操作:通过行锁防止重复插入。
- 更新操作:通过行锁确保数据一致性。
-
场景1:防止重复插入
START TRANSACTION; -- 锁定 order_code 对应的记录(若不存在,则加间隙锁) SELECT * FROM orders WHERE order_code = '20250818001' FOR UPDATE; -- 检查是否存在记录 IF NOT EXISTS THEN INSERT INTO orders (order_code, amount) VALUES ('20250818001', 100); END IF; COMMIT;- 处理方式:通过行锁或间隙锁确保同一事务内不会重复插入。
-
场景2:防止重复更新
START TRANSACTION; -- 锁定订单记录 SELECT * FROM orders WHERE id = 1 FOR UPDATE; -- 检查订单状态是否允许更新 IF status = '待支付' THEN UPDATE orders SET amount = amount + 100 WHERE id = 1; END IF; COMMIT;- 处理方式:通过行锁确保事务内数据状态不被其他事务修改。
2. 消息去重设计
- 消息唯一标识
- 生产者为每条消息生成唯一ID(如
业务主键+时间戳或 UUID)。
- 生产者为每条消息生成唯一ID(如
- 去重存储
-
Redis去重 :利用
SETNX命令记录已处理的消息ID,设置合理过期时间。javaString messageId = message.getHeaders().get("messageId"); if (redis.setnx(messageId, "1")) { // 处理消息 processMessage(message); redis.expire(messageId, 3600); // 设置过期时间 } else { // 已处理,直接 ACK channel.basicAck(deliveryTag, false); } -
数据库去重表:存储消息ID和状态,处理前先查询是否已存在。
-
3. 优化 RabbitMQ 配置
-
手动 ACK 模式
-
确保业务处理成功后再发送 ACK,避免自动 ACK 导致消息丢失。
javachannel.basicConsume(queueName, false, new DefaultConsumer(channel) { @Override public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties, byte[] body) { try { // 处理消息 processMessage(body); // 成功后发送 ACK channel.basicAck(envelope.getDeliveryTag(), false); } catch (Exception e) { // 失败则拒绝消息并重试 channel.basicNack(envelope.getDeliveryTag(), false, true); } } });
-
-
设置消息 TTL
- 为消息设置过期时间,避免长期滞留引发重复问题。
-
死信队列(DLX)
- 将消费失败的消息转入死信队列,限制重试次数,超过阈值后人工处理。
4. 分布式锁控制
- 全局锁
-
使用 Redis 分布式锁,确保同一消息在同一时刻只被一个消费者处理。
javaString lockKey = "lock:" + orderId; if (redisClient.set(lockKey, "locked", nx = true, ex = 30)) { try { // 处理消息 processMessage(message); } finally { redisClient.del(lockKey); // 释放锁 } } else { // 已被其他消费者处理,跳过 }
-
(二)实际场景中的实践
1. 消息去重的 Java 实现
- 单消费者场景:将消息ID存入 Redis String,每次覆盖旧值(适合单消费者)。
- 多消费者场景:将消息ID存入 Redis List,避免多消费者竞争问题(需定期清理数据)。
- 增量存储:以消息ID为 Key 存入 Redis Hash,并设置过期时间(适合高吞吐场景)。
2. 手动 ACK 的注意事项
- ACK 时机:确保消息处理完全成功后再发送 ACK,否则消息会重新投递。
- NACK 重试 :处理失败时,通过
basicNack返回消息到队列,触发重试机制。
3. 结合幂等性与去重的综合方案
java
public void handleMessage(Message message) {
String messageId = message.getMessageProperties().getMessageId();
String orderId = extractOrderId(message); // 从消息中提取业务主键
// 1. 使用 Redis 分布式锁
String lockKey = "lock:" + orderId;
if (!redis.setnx(lockKey, "locked")) {
return; // 已被其他消费者处理
}
try {
// 2. 校验消息是否已处理
if (redis.exists("processed:" + messageId)) {
return; // 已处理过
}
// 3. 业务处理
processOrder(orderId);
// 4. 记录已处理消息
redis.set("processed:" + messageId, "1");
redis.expire("processed:" + messageId, 3600); // 设置过期时间
} finally {
redis.del(lockKey); // 释放锁
}
}六. 介绍一下RabbitMQ中死信交换机 ? (RabbitMQ延迟队列有了解过嘛)
- 死信交换机:用于处理成为死信的消息,是消息可靠性保障的重要组件。
- 延迟队列 :基于 "TTL+DLX" 实现,核心是利用消息过期后自动进入死信队列的特性,实现延迟任务。
- 发送消息到一个 延迟队列 (实际是普通队列,但不设置消费者,并绑定死信交换机)。
- 为消息设置 TTL(过期时间) ,或为队列设置统一 TTL(
x-message-ttl)。- 当消息过期后,自动成为死信 ,被转发到死信交换机 ,最终进入死信队列。
- 死信队列配置消费者 ,实现延迟 后的消息处理。
总结:
- "死信交换机 是 RabbitMQ 提供的 兜底机制,把失败/超时消息集中处理。
- 延迟队列 就是它的 经典应用 :给消息或队列加 TTL,到期后自动进入 DLX,再路由到真正的消费端,实现 精准延时投递,常用于 30 分钟关单、延时短信等场景。"
注意:
- 单队列多延迟问题 :如果一个延迟队列中存在不同 TTL 的消息,可能导致 "先过期的消息被后过期的消息阻塞 "(因为 RabbitMQ 只会检查队列头部消息是否过期)
- 解决方案:为不同延迟时间创建单独的延迟队列。
(一)死信交换机(Dead Letter Exchange, DLX)
1. 什么是死信交换机?
- 死信( Dead Letter**)** :
- 在 RabbitMQ 中,无法被正常消费 的消息称为 死信(Dead Letter)。
- 例如,消息被消费者拒绝 (
basic.reject或basic.nack)、消息过期 (TTL 到期)、**队列达到最大长度(队列满)**等情况。
- 死信交换机(DLX) :
- 是一个普通的交换机 (如
direct、topic),但被指定为接收死信的"中转站" 。当消息成为死信 时,RabbitMQ 会将其转发到 DLX ,再由 DLX 根据绑定规则路由到死信队列(DLQ)。
- 是一个普通的交换机 (如
2. 死信产生的条件
- 消息被拒绝(Rejected) :消费者调用
basic.reject或basic.nack且requeue=false。 - 消息过期(TTL 过期):消息在队列中的存活时间(TTL)到期。
- 队列满 :队列达到最大长度(
x-max-length或x-max-size)。
3. 死信交换机的配置方式:
通过声明队列时指定参数,将队列与死信交换机绑定:
java
// 1. 声明死信交换机(普通交换机,类型任意,如direct)
channel.exchangeDeclare("dlx.exchange", "direct", true);
// 2. 声明死信队列
channel.queueDeclare("dlx.queue", true, false, false, null);
// 3. 绑定死信交换机和死信队列
channel.queueBind("dlx.queue", "dlx.exchange", "dlx.routing.key");
// 4. 声明普通队列,并指定死信交换机相关参数
Map<String, Object> args = new HashMap<>();
// 指定死信交换机
args.put("x-dead-letter-exchange", "dlx.exchange");
// 指定死信路由键(可选,默认使用原消息的路由键)
args.put("x-dead-letter-routing-key", "dlx.routing.key");
// 声明普通队列,关联死信配置
channel.queueDeclare("normal.queue", true, false, false, args);4. 应用场景:
- 处理消费失败的消息(如订单支付超时未支付)。
- 清理过期数据(如临时优惠券过期)。
- 实现延迟队列(结合消息 TTL)。
- 消息重试:通过 DLX + 延迟队列实现失败消息的延迟重试。
- 监控告警:将死信队列中的消息用于系统监控或告警。
(二)延迟队列(Delayed Queue (基于 DLX+TTL 实现))
1. 什么是延迟队列?
- 延迟队列 :消息在发送到队列后,不会立即被消费,而是延迟一段时间后才被消费者处理。典型场景包括订单超时未支付自动取消、定时任务调度等。
2. 实现方式
RabbitMQ 本身不原生支持延迟队列,但可以通过以下两种方式实现:
| 实现方式 | DLX + TTL | 延迟消息插件 |
|---|---|---|
| 是否需要插件 | 否 | 是 |
| 延迟精度 | 低(依赖队列头部消息) | 高(直接延迟) |
| 复杂度 | 高(需配置 DLX 和 TTL) | 低(直接发送延迟消息) |
| 适用场景 | 简单延迟需求 | 高精度延迟需求(如金融系统) |
方式 1:通过 DLX + TTL 模拟延迟队列
- 设置消息或队列的 TTL :
- 消息级别 TTL :在发送消息时设置
expiration属性(单位:毫秒)。 - 队列级别 TTL :在声明队列时设置
x-message-ttl参数。
- 消息级别 TTL :在发送消息时设置
- 配置死信交换机:将过期的消息转发到 DLX,再由 DLX 路由到延迟队列。
示例代码:
java
// 1. 声明死信交换机(用于接收过期消息)
channel.exchangeDeclare("delay.dlx.exchange", "direct", true);
// 2. 声明死信队列(实际处理延迟消息的队列)
channel.queueDeclare("delay.dlx.queue", true, false, false, null);
channel.queueBind("delay.dlx.queue", "delay.dlx.exchange", "delay.routing.key");
// 3. 声明延迟队列(无消费者,仅用于存储消息直至过期)
Map<String, Object> delayQueueArgs = new HashMap<>();
// 绑定死信交换机
delayQueueArgs.put("x-dead-letter-exchange", "delay.dlx.exchange");
// 绑定死信路由键
delayQueueArgs.put("x-dead-letter-routing-key", "delay.routing.key");
// 队列统一TTL(所有消息过期时间为10秒,可选)
delayQueueArgs.put("x-message-ttl", 10000);
channel.queueDeclare("delay.queue", true, false, false, delayQueueArgs);
// 4. 发送消息(可单独设置消息TTL,覆盖队列TTL)
AMQP.BasicProperties props = new AMQP.BasicProperties.Builder()
.deliveryMode(2) // 持久化
.expiration("15000") // 消息单独设置15秒过期(单位:毫秒)
.build();
// 发送到延迟队列(无消费者,等待过期)
channel.basicPublish("", "delay.queue", props, "订单123超时取消".getBytes());方式 2:使用 RabbitMQ 延迟消息插件
- 插件名称 :
rabbitmq_delayed_message_exchange - 优势 :
- 直接支持延迟消息,无需依赖 DLX 和 TTL。
- 解决了"队列头部阻塞"问题(即队首消息未过期时,后续已过期消息无法被消费)。
配置步骤:
- 下载并启用插件:
bash
# 下载插件(以 3.8.9 版本为例)
wget https://github.com/rabbitmq/rabbitmq-delayed-message-exchange/releases/download/3.8.9/rabbitmq_delayed_message_exchange-3.8.9-0199d11c.ez
# 启用插件
rabbitmq-plugins enable rabbitmq_delayed_message_exchange-
创建延迟交换机(类型为
x-delayed-message):java@Bean public CustomExchange delayedExchange() { return new CustomExchange("delayed.exchange", "x-delayed-message", true, false); } -
发送延迟消息:
java// 设置延迟时间(单位:毫秒) Map<String, Object> headers = new HashMap<>(); headers.put("x-delay", 5000); // 延迟 5 秒 AMQP.BasicProperties props = new AMQP.BasicProperties.Builder() .headers(headers) .build(); channel.basicPublish("delayed.exchange", "delayed.key", props, "延迟消息".getBytes());
七. 如果有100万消息堆积在MQ , 如何解决 ?
问题定位:消息堆积的根本原因
消息堆积的本质是 生产速率 > 消费速率,导致消息在 MQ 中累积。常见的原因包括:
- 消费者处理能力不足 (80% 情况):
- 消费者代码逻辑复杂(慢 SQL、外部接口调用、高耗时计算)。
- 单条消息处理时间过长(>100ms)。
- 消费者实例数量不足或配置不合理(如
QoS/Prefetch参数设置过小)。- 生产端突发流量冲击 (10% 情况):
- 大促、秒杀等业务高峰导致瞬时流量激增。
- MQ Broker 性能瓶颈 (10% 情况):
- 磁盘 I/O 瓶颈(如 PageCache 刷盘慢)、主从同步延迟等。
参考回答1:
"100 万消息堆积时,先用 临时扩容+批量消费 把水位迅速打下去,同时把 无关键业务降级 ,并配合 惰性/惰性队列+磁盘 防止内存被打爆,最后通过 死信队列 对残留消息做补偿。"
参考回答2:
"面对 100 万消息堆积,我的思路是 三板斧:
先保护 Broker :把队列改成 惰性队列 或调大内存阈值,防止节点 OOM;
再提速消费 :水平扩容消费者 + 多线程批量拉取 + 批量 ACK,让单机 QPS 提升 5~10 倍;
最后兜底 :给队列加 最大长度 + DLX(死信交换机) ,超限消息进死信队列 ,离线补偿即可。
这样能在分钟级 把水位降下来,同时保证零丢失。"
参考回答3:
第一:提高消费者的消费能力 ,可以使用多线程并行消费任务
第二:增加更多消费者,提高消费速度。使用工作队列模式, 设置多个消费者消费消费同一个队列中的消息
第三:扩大队列容积,提高堆积上限 ,可以使用RabbitMQ惰性队列,惰性队列的好处主要是:
①接收到消息后直接存入磁盘而非内存
②消费者要消费消息时才会从磁盘中读取并加载到内存
③支持数百万条的消息存储
八. RabbitMQ的高可用机制有了解过嘛?
RabbitMQ 高可用的核心目标
- 避免单点故障:确保任意节点故障时,系统仍能正常运行。
- 数据不丢失:通过冗余和持久化机制保障消息可靠性。
- 服务持续可用:在节点宕机或网络分区时,自动恢复并提供无缝切换
总结:
- "RabbitMQ 的 HA 主要靠 集群 + 队列复制(避免单点故障)。
- 老版本用 镜像队列 ,新版本推荐 仲裁队列(Raft) ,结合 持久化机制(数据不丢失) ,客户端配合 多节点地址 + 自动重连(服务持续可用);
- 这样即使单个节点宕机,数据依旧可用,业务零中断。"
ps:为什么推荐使用仲裁队列?
问题场景 镜像队列 仲裁队列 主节点故障未同步消息 可能丢失(异步同步机制) 不会丢失(需多数节点确认后才算成功) 网络分区数据一致性 可能分裂为多个集群,导致数据冲突 遵循 Raft 协议,仅多数派分区能处理写操作 性能与节点数量的关系 节点越多,性能下降越明显(全量复制) 性能衰减平缓(优化的复制逻辑) 运维复杂度 需要配置 Policy、手动同步等 零配置,自动管理节点组和数据复制
1. RabbitMQ 高可用的核心机制
(1)集群部署
-
普通集群(标准集群):
- 特点:
- 元数据同步:所有节点都保存(共享)了集群的元数据,比如交换机、队列、绑定关系等的定义。
- 消息不复制 :只有创建队列的那个节点才真正存储队列中的消息和状态(消息仅存储在创建队列的节点),其他节点只是"知道"这个队列的存在。
- 消费者连接任意节点:消费者可以连接到任意集群节点来消费某个队列,但如果该节点不是队列所在节点,RabbitMQ 会通过内部通信将消息从"队列所在节点"转发给消费者。
- 如果**队列所在(主节点)**的节点宕机,队列和消息将不可用。
- 适用场景:对队列高可用要求不高,但希望通过集群提升吞吐量。
- 缺点:主节点故障可能导致消息丢失。
- 举例:
-
假设你有一个 3 节点的 RabbitMQ 集群:
Node A、Node B、Node C。 -
你在
Node A上声明了一个队列order.queue。 -
此时:
-
Node A是order.queue的"拥有者"。 -
所有消息都会被存储在
Node A上。 -
Node B和Node C只知道这个队列存在,但不保存消息。
-
-
✅ 消费者连接
Node B并消费order.queue?没问题!- RabbitMQ 内部会从
Node A把消息拉取过来,再投递给消费者
- RabbitMQ 内部会从
-
- 特点:
-
镜像集群(Mirrored Queue):
- 核心原理 :
- 将队列和消息同步到多个节点(主节点 + 从节点)。
- 主节点负责读写,从节点实时同步数据。
- 主节点宕机时,从节点自动选举为新的主节点,实现故障转移。
- 配置方式 :
-
通过策略(Policy)定义镜像规则,例如:
javarabbitmqctl set_policy ha-all "^ha\." '{"ha-mode":"all"}'表示所有以
ha.开头的队列会在集群中所有节点镜像。
-
- 优点 :
- 消息跨节点冗余,防止单节点数据丢失。
- 故障转移无感知,保障服务连续性。
- 缺点 :
- 同步机制带来性能开销(副本数量越多,吞吐量越低)。
- 无法解决网络分区导致的数据不一致问题。
- 主节点故障未来得及同步消息,可能会导致消息丢失
- 核心原理 :
-
Quorum (仲裁)队列(3.8+ 新特性):
- 核心原理 :
- Raft = 半数以上投票选主 + 日志多副本同步提交 ;强一致地复制数据。
- 基于 Raft 协议实现分布式一致性,取代镜像队列。
- 队列数据在多个节点之间通过投票机制达成一致。
- 优点 :
- 更强的数据一致性保障。
- 支持动态调整副本数量。
- 适用场景:生产环境推荐使用,替代传统镜像队列。
- 核心原理 :
(2)持久化机制
-
Exchange(交换机) 持久化 :
- 声明 Exchange 时设置
durable=true,防止 Exchange 在节点重启后丢失。
- 声明 Exchange 时设置
-
Queue(队列)持久化 :
- 声明 Queue 时设置
durable=true,确保队列元数据写入磁盘。
- 声明 Queue 时设置
-
消息持久化 :
- 发送消息时设置
deliveryMode=2(持久化),消息会被写入磁盘。
- 发送消息时设置
-
代码示例(Java) :
java// 声明持久化 Exchange 和 Queue channel.exchangeDeclare("my_exchange", "direct", true); channel.queueDeclare("my_queue", true, false, false, null); // 发送持久化消息 AMQP.BasicProperties props = new AMQP.BasicProperties.Builder() .deliveryMode(2) // 持久化消息 .build(); channel.basicPublish("my_exchange", "routing_key", props, "Hello, World!".getBytes());
(3)客户端自动恢复
-
自动重连 :
- 客户端配置
automaticRecoveryEnabled=true,连接断开后自动重连。
- 客户端配置
-
代码示例(Spring Boot) :
javaConnectionFactory factory = new ConnectionFactory(); factory.setAutomaticRecoveryEnabled(true);
2. 高可用的典型场景与解决方案
场景 1:节点宕机
- 镜像队列:主节点宕机后,从节点自动接管,消息不丢失。
- Quorum 队列:通过 Raft 协议选举新主节点,保障一致性。
场景 2:网络分区
- 镜像队列:可能出现脑裂问题,需手动干预。
- Quorum 队列:通过 Raft 协议的法定多数(quorum)机制自动处理分区。
场景 3:数据恢复
- 镜像队列 :若主节点数据损坏,需通过
forget_cluster_node命令剔除故障节点并重建镜像。 - Quorum 队列:支持动态修复数据一致性。
3. 高可用的配置与优化建议
- 镜像队列策略 :
- 合理设置
ha-mode(如exactly=3,复制到 3 个节点)。 - 避免过度镜像,平衡性能与可靠性。
- 合理设置
- Quorum 队列配置 :
- 使用
quorum类型队列替代镜像队列。 - 设置合理的副本数(如 3 个节点)。
- 使用
- 监控与告警 :
- 通过 Prometheus + Grafana 监控集群状态(如节点健康、队列长度)。
- 配置自动扩缩容(Kubernetes HPA)应对流量突增。
4. 高可用机制的优缺点对比
| 机制 | 优点 | 缺点 |
|---|---|---|
| 普通集群 | 简单易部署,提升吞吐量 | 单节点故障导致消息丢失 |
| 镜像队列 | 消息冗余,故障自动转移 | 性能开销大,无法解决网络分区问题 |
| Quorum 队列 | 数据一致性高,支持动态修复 | 配置复杂,依赖 Raft 协议 |
| 持久化 | 防止节点重启导致数据丢失 | 磁盘 I/O 开销较大 |
九. 介绍一下镜像队列丢失数据的情况,以及怎么解决?
- 镜像队列丢失数据的核心原因是异步同步机制和网络分区 ,
- 镜像队列默认 异步复制 ,主节点挂了,尚未同步给镜像的那几条消息就丢了。
- 只丢"最后 N 条",不是全丢。
- 解决思路是:
- 基础保障 :持久化消息与队列 ,结合生产者确认机制。
- 配置优化 :自动同步 、合理节点数量 、分区策略。
- 升级方案 :用仲裁队列替代镜像队列,通过 Raft 协议实现强一致性
| 数据丢失的原因 | 具体场景描述 | 解决方案 |
|---|---|---|
| 主节点故障时消息未同步 | 主节点接收消息后,未完成向从节点的同步就宕机,导致消息仅存在于主节点内存中丢失 | 1. 启用生产者确认机制 (Publisher Confirm),确保消息被主节点和至少一个从节点确认后再视为成功 2. 对核心消息设置持久化 (deliveryMode=2),强制写入磁盘 3. 改用仲裁队列(基于 Raft 协议,需多数节点确认后才算投递成功) |
| 网络分区导致数据冲突 | 集群网络分裂为多个分区,各分区独立处理消息,恢复后因数据不一致丢弃部分消息 | 1. 配置集群分区策略 为pause_minority,少数派分区自动暂停服务 ,避免数据分裂 2. 限制镜像队列节点在同一机房 ,减少跨机房网络分区风险 3. 改用仲裁队列(遵循 Raft 协议,仅多数派分区可处理写操作,天然避免冲突) |
| 非持久化消息全副本丢失 | 消息未持久化(仅存于内存),所有镜像节点同时宕机(如集群断电),导致消息丢失 | 1. 所有核心消息 强制设置持久化 (deliveryMode=2),确保写入磁盘 2. 避免在镜像队列中使用非持久化消息(除非业务可容忍丢失) |
| 手动同步模式下历史消息丢失 | 镜像队列配置为ha-sync-mode=manual,从节点未手动同步历史消息,主节点故障后从节点缺失数据 |
1. 核心队列 配置ha-sync-mode=automatic,从节点加入后自动同步全量消息 2. 从节点启动后,通过rabbitmqctl sync_queue <queue_name>手动触发同步(适用于手动模式) 3. 改用仲裁队列(自动管理数据同步,无需手动干预) |
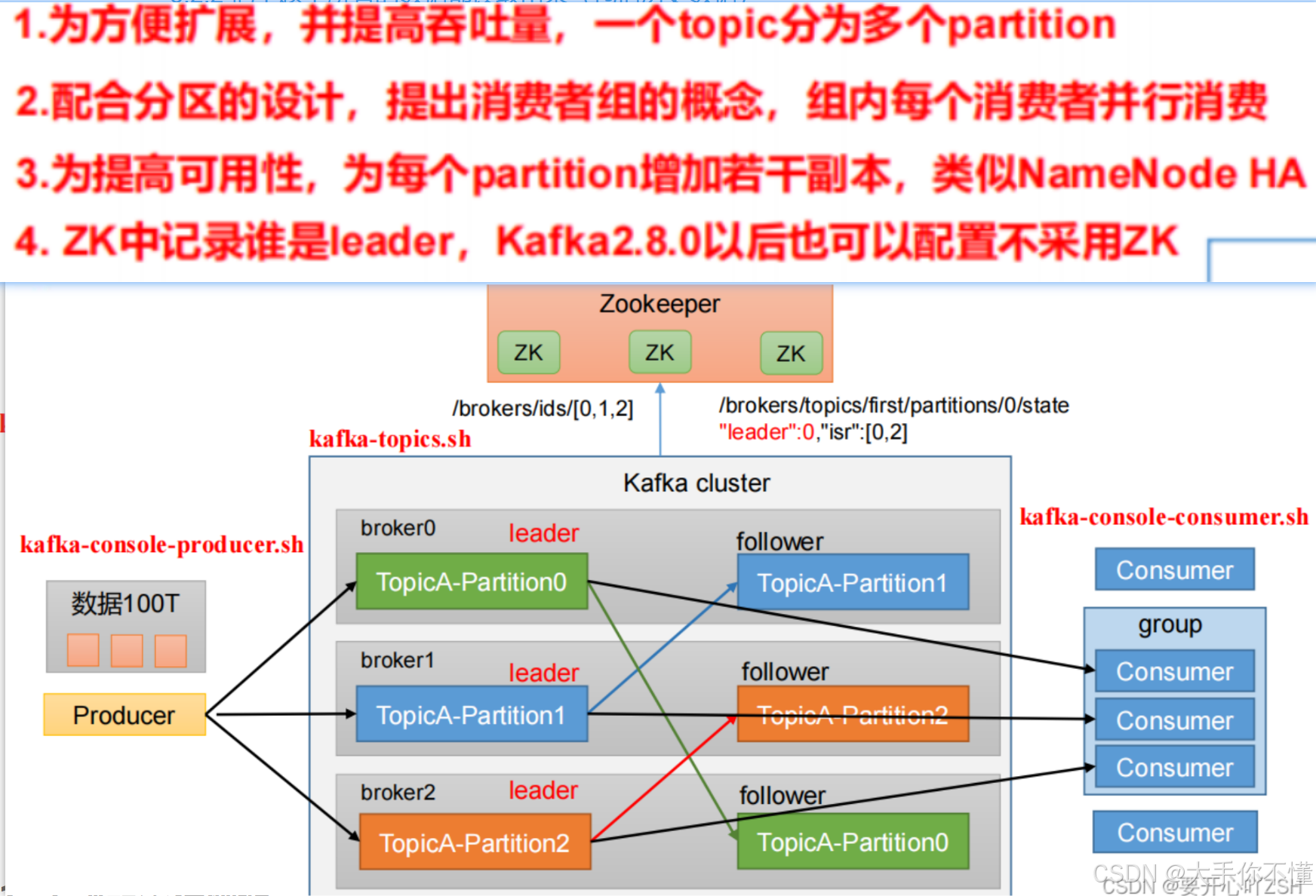
十. Kafka是如何保证消息不丢失
Kafka 保证消息不丢失的核心逻辑是:
- 生产者 :通过
acks=all+ 重试机制,确保消息成功写入足够多的副本;- Broker:通过多副本 + ISR 机制,确保集群故障时数据不丢失;
- 消费者:通过手动提交偏移量,确保消息被正确处理后再标记完成。
组件 关键配置 作用 生产者 acks=all确保消息写入所有 ISR 副本 retries=Integer.MAX_VALUE自动重试发送失败的消息 enable.idempotence=true避免因重试导致的重复消息(幂等(去重、保序)) Broker(服务端) replication.factor=3每个分区有 3 个副本**(至少 1 个首领副本 + 2 个 follower 副本)** min.insync.replicas=2(要求至少 2 个副本同步消息,避免单副本故障丢失) unclean.leader.election=false禁止非 ISR 副本成为 Leader,避免数据回滚 消费者 enable.auto.commit=false禁用自动提交 ,手动控制 Offset提交时机 auto.offset.reset=earliest从最早的消息开始消费 sendOffsetsToTransaction将 Offset 提交与事务绑定,实现 Exactly-Once 语义
- 自动提交 offset 导致的问题:
- 消息丢失 :【业务未处理,offset 已提交 】
- 一旦在 业务还没真正处理完 就触发,就会导致 消息已标记『已消费』,
- 但业务实际没成功 ,重启后 Kafka 继续从 已提交的 offset 往后拉,于是 漏消费;
- 重复消费:【业务已处理,offset 未提交 】
- 相反,如果 业务已处理完但还没提交 offset,Broker 就认为消息没消费
- ,重启后 Kafka 继续从 已提交的 offset 往后拉,于是 重复消费。"
1️⃣ Producer(生产者) 端
-
acks=all (或 -1)
Leader 要等 所有 ISR 副本 都落盘才回 ACK ⇒ 即使 Leader 挂了,数据仍在 follower。
-
retries > 0 + enable.idempotence=true
自动重试 + 幂等(去重、保序) ⇒ 不会因为网络抖动丢或重。
TypeScript
# 生产端必配
acks=all
retries=Integer.MAX_VALUE
enable.idempotence=true
acks参数控制确认级别
acks=0:生产者发送消息后不等待任何确认(可靠性最低,性能最高)。
acks=1:仅等待 Leader 副本确认消息写入本地日志(若 Leader 未同步 Follower 就宕机,消息可能丢失)。
acks=all(推荐) :等待所有 ISR(In-Sync Replicas)副本确认写入(可靠性最高,但延迟较高)。
2️⃣ Broker(服务) 端
-
replication.factor ≥ 3
多副本,任何一台机器挂数据仍在。(至少 1 个首领副本 + 2 个 follower 副本)
-
min.insync.replicas ≥ 2
控制"最少同步副本数" ,低于此值生产端会抛异常,主动拒写,防止"只剩 Leader 一个"时强行写丢数据。(要求至少 2 个副本同步消息,避免单副本故障丢失) -
flush.messages / flush.ms (可选)
强制刷盘频率;默认 OS page cache 即可,极端场景可调低。
-
启用 unclean.leader.election.enable=false:禁止非 ISR 副本成为首领(避免数据不一致)
3️⃣ Consumer(消费者) 端
-
手动提交 offset
-
业务逻辑处理完再
commitSync(),Broker 重启也不会重复丢。 -
避免自动提交(避免消息没消费完就提交了offset导致消息丢失 )
-
-
幂等消费
每条消息带业务主键,消费端用 Redis/DB 去重。
十一. Kafka中消息的重复消费问题如何解决的
重复消费的原因:(业务已完成+offset未提交)
序号 触发场景 产生重复消费的根因 结果表现 1 自动提交 (enable.auto.commit=true) poll() 后立即提交 offset,若业务处理慢/异常崩溃,offset 提前提交 ,重启后 Kafka 认为已消费,但业务实际未完成;当重试逻辑或重平衡发生时又会 重新拉取 同批消息 重复消费 2 手动提交前崩溃 业务已处理成功,但 commitSync()没来得及执行,offset 未更新;重启后 Kafka 仍按旧 offset 拉取重复消费 3 Rebalance(分区重分配) 消费者组发生 Rebalance 时,旧消费者还没来得及提交 offset;新消费者接手分区后从 旧 offset 开始 重复消费 4 业务超时/处理失败重试 业务逻辑内部失败后自行重试,未对消息做幂等控制 重复消费 Kafka 只保证"至少一次"投递;以上四种情况都会导致 同一消息被多次投递 。解决 Kafka 消息重复消费的核心是消费者手动提交+幂等性设计,具体方案选择:
- 消费者端 :关闭自动提交 + 手动提交偏移量。
- 业务逻辑 :实现幂等性
- 通用方案:消息唯一 ID + Redis(加锁、分布式锁) / 数据库去重(适用于大多数场景)。
- 数据库场景:唯一约束或乐观锁(强一致性要求)。
- 配置优化 :减少因偏移量提交问题导致的重复消费概率。
- 非核心业务 :可使用自动提交 (
enable.auto.commit=true),但需设置较短的auto.commit.interval.ms(如 100ms),减少未提交范围。- 核心业务 :必须手动提交 (
enable.auto.commit=false),且在业务处理完成后再调用commitSync(),避免提前提交。
1. 手动提交偏移量(Offset)
核心思路:
- 关闭自动提交 (
enable.auto.commit=false),确保消息处理完成后再提交偏移量。 - 通过
commitSync()或commitAsync()显式控制偏移量提交时机。
优点:
- 精确控制偏移量提交时机,避免消息未处理完成就被标记为已消费。
- 防止消费者崩溃后重复消费未提交的消息。
注意事项:
- 同步提交 (
commitSync):保证可靠性,但可能降低性能。 - 异步提交 (
commitAsync):提高性能,但需处理回调中的异常。
2. 幂等性消费(Idempotent Consumer)
核心思路:
- 业务逻辑设计为幂等:即使消息重复消费,最终结果也一致。
- 唯一标识符判重:通过消息的唯一键(如业务ID)检查是否已处理过该消息。
实现方式:
- 通用场景:消息唯一 ID + Redis(加锁、分布式锁) / 数据库去重(适用于大多数场景)。记录已处理的消息ID,避免重复处理。
- 数据库场景:唯一约束或乐观锁(强一致性要求)。
优点:
- 无需依赖 Kafka 的机制,完全由业务逻辑保证幂等性。
- 适用于所有场景,尤其是无法使用事务的系统。
缺点:
- 需要额外的存储(如 Redis 或数据库),增加复杂性。
- 可能存在缓存击穿或性能瓶颈。
3. Kafka 配置优化:减少重复消费概率
通过优化消费者配置,降低因偏移量提交问题导致的重复消费:
-
合理设置偏移量提交方式
- 非核心业务:可使用自动提交(
enable.auto.commit=true),但需设置较短的auto.commit.interval.ms(如 100ms),减少未提交范围。 - 核心业务:必须手动提交(
enable.auto.commit=false),且在业务处理完成后再调用commitSync(),避免提前提交。
- 非核心业务:可使用自动提交(
-
控制消费批次与重试
- 减少单次拉取消息量(
max.poll.records,如设为 100),降低因处理超时导致的重平衡(rebalance)。 - 避免无限重试:设置
max.poll.records和max.poll.interval.ms,超过次数后将消息放入死信队列人工处理。
- 减少单次拉取消息量(
十二. Kafka是如何保证消费的顺序性
"Kafka 的顺序性靠三板斧:① 全局单分区;② 业务 key 指定分区;③ 单线程消费 + 手动提交。只要 同一个分区由 同一个消费者线程顺序拉取,就能保证消息顺序。"
- 生产端 :通过相同 key 将相关消息路由到同一分区,确保分区内写入顺序。
- Broker(服务端) :分区内部天然 追加日志,顺序写入磁盘 【分区内有序】
- 消费端 :一个分区仅被一个线程消费,串行处理消息并正确提交偏移量。
(一)Kafka 顺序性的基础:分区内有序
Kafka 的消息顺序性是 "分区级别的有序",即:
- 同一个分区(Partition)内的消息,按生产者发送顺序存储(偏移量 offset 递增),消费者也按此顺序消费。
- 不同分区之间的消息顺序不做保证(因分区数据分散在不同 Broker,消费时并行处理)。
这是因为 Kafka 的分区本质是一个 追加日志文件(Append-Only Log) ,消息一旦写入分区就不可修改,只能按顺序追加,天然保证分区内有序。
(二)保证消费顺序性的关键措施
1. 生产端:确保消息按顺序写入同一分区
-
指定分区键(Key) :生产者发送消息时,通过相同的
key路由到同一分区(Kafka 默认按key的哈希值分配分区)。
例:订单消息按orderId作为 key,确保同一订单的创建、支付、发货等消息进入同一分区。java// 相同orderId的消息会进入同一分区 producer.send(new ProducerRecord<>("order-topic", orderId, message)); -
禁用分区再平衡(避免数据迁移) :若分区副本迁移,可能导致短暂的顺序混乱,需确保集群稳定(如合理配置
unclean.leader.election.enable=false)。 -
单分区设计 :将主题配置为 单分区,所有消息强制进入同一个分区,天然保证全局顺序。
2. 消费端:单线程处理同一分区消息
-
一个分区仅被一个消费者线程消费:Kafka 消费者组中,一个分区只能分配给组内一个消费者实例,确保该分区的消息不会被多线程并行处理。
-
关闭多线程并行消费 :即使消费者实例内部使用多线程,也需保证同一分区的消息被单线程串行处理(如通过分区号映射到固定线程)。
java// 伪代码:按分区分配线程处理 Map<Integer, ExecutorService> partitionThreads = new HashMap<>(); for (ConsumerRecord<String, String> record : records) { int partition = record.partition(); // 为每个分区获取专属线程池(单线程) ExecutorService thread = partitionThreads.computeIfAbsent(partition, k -> Executors.newSingleThreadExecutor()); thread.submit(() -> process(record)); // 串行处理该分区消息 } -
禁止自动提交偏移量,确保处理顺序:手动提交偏移量时,需等分区内所有消息处理完成后再提交,避免因部分消息未处理导致的顺序混乱。
3. 避免消息重试导致的顺序颠倒
- 若消息消费失败需要重试 ,直接重试会导致 "失败消息" 被滞后处理,破坏顺序(如消息 1 处理失败,消息 2 先处理完成)
- 解决方案:将失败消息放入 延迟重试队列 (单独的主题),延迟一段时间后重新消费,且重试队列也按原分区键路由,保证重试消息与原消息顺序一致。
(三)局限性与权衡
- 顺序性与吞吐量的矛盾 :
- 严格的顺序性依赖 "单分区 + 单线程消费",会降低吞吐量(无法并行处理)。
- 平衡方案:根据业务场景拆分主题(如将非顺序依赖的消息拆分到不同主题),或通过多分区 + 按 key 路由实现 "局部有序"。
- 跨分区顺序无法保证 :若业务需要全局顺序 (如全量日志的严格时序),只能使用 单分区主题(但会牺牲吞吐量)。
十三. Kafka的高可用机制有了解过嘛
"Kafka 的高可用靠 多副本 + ISR + Controller 秒级切主 ,Producer 端
acks=all重试,Consumer 端重平衡,故障切换对业务透明;再配 跨机架/跨 AZ 部署,做到机柜级甚至机房级容灾。"
分区多副本机制(核心基础):解决数据单点故障问题;
ISR 同步机制(确保数据一致性):确保副本数据一致性;
首领自动选举(故障转移):自动选举实现故障无缝转移;
集群控制器(Controller):控制器统筹集群状态管理。
生产者端 HA :acks=all + 重试+幂等
消费者端 HA :Broker 挂掉导致分区重新分配,Kafka 在组内 自动重平衡,消费者线程无感知继续消费。
(1)多副本机制(Replication)
- 原理 :每个 Kafka 主题(Topic)的分区(Partition)可以配置多个副本(Replica),副本分布在不同的 Broker 上。
- Leader 副本:负责处理所有客户端(生产者/消费者)的读写请求。
- Follower 副本:被动同步 Leader 的数据,不处理客户端请求。
- 目的:当 Leader 宕机时,Follower 可以快速接管成为新的 Leader,避免服务中断
(2)ISR 机制(In-Sync Replicas)
- 原理 :ISR 是与 Leader 保持同步 的 Follower 副本集合。只有在ISR 中的副本才有资格被选举为新的 Leader。
- 动态管理 :
- 移出 ISR :当 Follower 与 Leader 的滞后时间或消息数超过阈值(如
replica.lag.time.max.ms,默认 30 秒),会被移出 ISR。 - 加入 ISR:当 Follower 追上 Leader 后,重新加入 ISR。
- 移出 ISR :当 Follower 与 Leader 的滞后时间或消息数超过阈值(如
- 关键参数 :
replication.factor:副本总数(通常设为 3)。min.insync.replicas:最小同步副本数(通常设为 2)。
(3)领导者选举(Leader Election)
当首领副本所在的 Broker 宕机或与集群失联时,Kafka 会自动从 ISR 中选举新的首领副本,流程如下:
- 故障检测 :集群控制器 (见下文)通过心跳机制监控 Broker状态,发现首领所在节点故障后,触发选举。
- 选举规则 :
- 优先从ISR 中选举(确保数据最新)。
- 禁止非 ISR 副本成为首领 (通过
unclean.leader.election.enable=false配置,默认关闭,避免数据不一致)。
- 无缝切换 :选举完成后,控制器通知所有 Broker 更新分区首领信息,客户端通过元数据请求自动感知新首领,无需人工干预。
(4)集群控制器(Controller)
- 角色:每个 Kafka 集群中有一个 Controller,负责管理分区和副本的元数据,协调 Leader 选举、副本同步等操作。
- 容错性:Controller 本身是单点,但 Kafka 会定期在 ZooKeeper 中选举新的 Controller,避免单点故障。
(5)生产者端 HA
-
acks=all + 重试
消息必须写到所有 ISR 才返回 ACK;Leader 挂而未同步时,生产者收到异常可 自动重试 (
retries=Integer.MAX_VALUE)。 -
幂等 Producer
开启
enable.idempotence=true,重试也不会重复写。
(6)消费者端 HA
-
消费者组重平衡
Broker 挂掉导致分区重新分配,Kafka 在组内 自动重平衡,消费者线程无感知继续消费。
-
手动提交 offset
业务处理完再
commitSync(),避免节点重启后重复/漏消费。
十四. 解释一下复制机制中的ISR?
ISR(In-Sync Replicas)就是 "当前与 Leader 保持同步的副本集合" ;只有 ISR 里的 Follower 才有资格在 Leader 宕机时被选为新 Leader,从而保证 已提交的数据绝不丢失。
判定标准 :Follower 在
replica.lag.time.max.ms(默认 30 s)内 追上 Leader 的就留在 ISR,否则被踢出。写入规则 :Producer 的
acks=all要求消息 写入 ISR 中所有副本 才返回 ACK,因此即使 Leader 挂,数据仍在 ISR 的某个副本里。高可用核心 :Leader 宕机 → Controller 只在 ISR 中选新 Leader,不会选落后太多的副本,避免丢数据。
(一)ISR 的定义
ISR 是指所有与首领副本保持同步状态的副本的集合,包括首领副本自身。
- 每个分区的副本(包含 Leader 和 Follower)中,只有满足 "同步条件" 的副本才能进入 ISR。
- "同步条件":Follower 副本的消息偏移量(Offset)与 Leader 的差距在配置的阈值内(由
replica.lag.time.max.ms控制,默认 30 秒)。
(二)ISR 的核心作用
-
确保数据可靠性
生产者发送消息时,若配置
acks=all,Kafka 会等待 ISR 中所有副本都确认写入消息后,才向生产者返回成功。这保证了消息至少被多个同步副本保存,避免单副本故障导致数据丢失。 -
限制首领选举范围
当 Leader 副本所在 Broker 宕机时,新的 Leader 只会从 ISR 中选举(通过
unclean.leader.election.enable=false配置),确保新 Leader 拥有最新的数据,避免数据不一致。
(三)ISR 的动态维护机制
ISR 不是固定不变的,会根据副本同步状态动态调整:
-
加入 ISR:
- Follower 启动后,会从 Leader 同步全量消息,当追上 Leader 的偏移量并满足同步条件时,加入 ISR。
-
移出 ISR:
- 若 Follower 因网络延迟、Broker 负载过高等原因,超过
replica.lag.time.max.ms未与 Leader 同步(偏移量差距过大),会被移出 ISR。
- 若 Follower 因网络延迟、Broker 负载过高等原因,超过
-
重新加入 ISR:
- 被移出的 Follower 恢复同步能力后,若再次满足同步条件,会重新加入 ISR。
(四)关键配置参数
replica.lag.time.max.ms:判断 Follower 是否同步的超时阈值(默认 30 秒)。超过该时间未同步的 Follower 会被移出 ISR。min.insync.replicas:ISR 中最小副本数量(默认 1)。若 ISR 副本数低于该值,生产者会收到异常(NotEnoughReplicasException),避免在副本不足时写入数据导致风险。
十五. Kafka数据清理机制了解过嘛
Kafka 通过 "分段日志 + 基于时间与大小的保留策略 + 后台异步清理线程" 自动删除或压缩旧数据,磁盘永远可控。
"Kafka 默认 7 天或超过阈值就整段删 ,也可改为 压缩模式 保留最新 key,日志文件再大也不会把磁盘打爆。"
Kafka 数据清理机制的核心是 "基于日志分段的策略化清理":
- 删除策略:按时间 (默认7天)/ 大小自动删除过期数据,适用于时序数据(如日志)。
- 压缩策略:按 Key 保留最新版本,适用于状态数据(如配置信息)。
Kafka 的数据清理机制用于管理磁盘上的消息日志,避免存储无限限制膨胀,同时根据业务需求保留必要的历史数据。其核心是通过 日志分段(Log Segments) 和可配置的清理策略,实现对过期或无用数据的自动清理。主要机制如下:
(一)数据存储结构:日志分段(Log Segments)
Kafka 的每个分区(Partition)数据以 日志文件(Log) 形式存储在磁盘,而日志又被分割为多个 日志分段(Log Segments):
- 每个分段 是一个独立的文件 (如
00000000000000000000.log表示从 offset=0 开始的分段)。 - 新消息 会追加到当前活跃分段(Active Segment),当分段大小或时间达到阈值时,会创建新的分段。
- 分段文件还包含索引文件(
.index)和时间戳索引(.timeindex),用于快速定位消息。
这种结构使得数据清理 可以按分段粒度进行,而非整个日志,提高效率。
(二)两种核心清理策略
Kafka 提供两种主要的日志清理策略,通过 log.cleanup.policy 配置(默认 delete):
1. 时间或大小阈值的删除策略(Delete Policy)
按 时间或大小阈值 自动删除过期的日志分段,适用于需要保留一定时间历史数据的场景(如日志收集)。
- 触发条件 :
- 时间阈值 :
log.retention.hours(默认 168 小时 / 7 天)、log.retention.minutes、log.retention.ms(优先级最高),超过该时间的分段会被删除。 - 大小阈值 :
log.retention.bytes(默认 -1,即不限制),当分区总大小超过该值,从最旧的分段开始删除。
- 时间阈值 :
- 执行机制 :Kafka 后台有专门的清理线程(
log.cleaner.threads),定期检查并删除满足条件的分段。
2. 压缩策略(Compact Policy)
按 消息键(Key) 保留最新版本,旧版本消息被压缩(删除),适用于需要保留最新状态的场景(如用户配置、字典数据)。
- 核心逻辑:对相同 Key 的消息,只保留最后一条(最新 offset),之前的旧版本会被清理。
- 执行机制 :
- 清理线程扫描分段,构建 Key 到最新 offset 的映射。
- 生成新的 "压缩分段",仅包含每个 Key 的最新消息,替换旧分段。
- 配置参数 :
log.cleaner.enable=true(默认开启)、log.cleanup.policy=compact。
(四)其他辅助清理机制
-
日志分段滚动 :
当活跃分段达到
log.segment.bytes(默认 1GB)或log.roll.hours(默认 24 小时)时,会关闭当前分段并创建新分段,确保单个文件不会过大,便于清理和管理。 -
删除已消费的消息?
Kafka 不会仅因消息被消费就删除(与 RabbitMQ 不同),而是严格按上述时间 / 大小 / 压缩策略清理,确保消费者可重复消费历史数据(如重新消费、消费者故障恢复)。
-
手动删除 :
可通过命令手动删除指定主题的过期数据:
TypeScript# 强制清理 test 主题的过期数据 bin/kafka-delete-records.sh --bootstrap-server broker:9092 --offset-json-file delete.json
十六. Kafka中实现高性能的设计有了解过嘛?
- 消息分区:不受单台服务器的限制,可以不受限的处理更多的数据
- 顺序读写:磁盘顺序读写,提升读写效率
- 页缓存:把磁盘中的数据缓存到内存中,把对磁盘的访问变为对内存的访问
- 零拷贝:减少上下文切换及数据拷贝
- 消息压缩:Producer 把多条消息按批次 gzip/lz4/snappy 压缩再发送,减少磁盘IO和网络IO
- 分批发送:将消息打包批量发送,减少网络开销
1. 分布式架构与分区(Partitioning)
- 水平扩展
Kafka 是一个分布式系统,主题(Topic)被划分为多个分区(Partition),这些分区可以分布在不同的 Broker 上。这种设计允许 Kafka 通过增加 Broker 轻松地进行水平扩展,从而处理巨大的数据量和并发请求。 - 并行处理
生产者和消费者都可以并行地处理不同分区的数据。生产者可以将消息发送到不同的分区,消费者组中的不同消费者可以同时消费不同分区的消息,极大地提高了系统的整体吞吐量。
2. 顺序写入
- 顺序I/O
每个分区的消息日志是 仅追加(Append-Only) 的文件,新消息永远写入文件末尾,避免了磁盘随机 IO(随机 IO 性能比顺序 IO 低 100 倍以上)。 - 这种顺序写入方式充分利用了磁盘的物理特性,其性能远高于随机写入。现代硬盘和 SSD 对顺序写入的优化使得 Kafka 能够实现非常高的写入吞吐量。
- 即使需要删除旧数据,也只按 "日志分段(Log Segment)" 批量删除(而非单条删除),进一步减少磁盘操作。
3. 零拷贝(Zero-Copy)技术
Kafka 在 Broker 向消费者传输消息时,使用操作系统的 零拷贝技术 (如 Linux 的 sendfile() 系统调用):
- 传统方式:磁盘 → 内核缓存 → 用户缓存 → socket 缓存 → 网络,需 4 次数据拷贝和 2 次用户态 / 内核态切换。
- 零拷贝 :
- 直接从内核缓存 将数据传输到socket 缓存(无需用户态参与),减少 2 次拷贝和切换,尤其对大消息传输效率提升显著。
- 磁盘 → 内核缓存 → socket 缓存 → 网络
4. 批量处理(Batching)
- 生产者批量发送
Kafka 生产者通过 批量发送 优化网络和 I/O 请求的开销:batch.size:定义批量发送消息的最大大小(默认 16KB)。linger.ms:生产者在尝试发送消息前等待的最长时间(默认 0ms,建议设置为 200ms 以启用批量发送)。buffer.memory:指定生产者可以用来缓冲待发送消息的总内存空间(默认 32MB)。
这种方式减少了网络请求的次数,提高了吞吐量。
- 消费者批量拉取
Kafka 消费者可以一次性拉取多条消息,减少客户端的处理开销,提高效率。
5. 页缓存(Page Cache)优化
- 定义 :页缓存是操作系统内核维护 的一块内存区域,用于缓存从磁盘读取的数据页(通常以 4KB 为单位),或暂存即将写入磁盘的数据。
- 核心作用 :作为磁盘 和应用程序 之间的缓冲层,让频繁访问的数据常驻内存,避免每次读写都操作物理磁盘(磁盘 IO 速度比内存慢 10 万倍以上)。
-
读写操作均通过页缓存
- 读操作:消费者读取消息时,先检查页缓存中是否存在所需数据页。若命中(缓存中有),直接从内存返回,避免磁盘 IO;若未命中,操作系统从磁盘加载数据到页缓存,再返回给应用。
- 写操作:生产者发送的消息先写入页缓存(通过内存映射文件 MMAP),操作系统会异步将页缓存中的数据刷入磁盘(由内核的 pdflush 线程按策略执行),而非同步等待磁盘写入完成,减少写操作延迟。
-
顺序读写放大页缓存优势
Kafka 的消息日志是 仅追加(Append-Only) 的顺序写入模式,且消费者通常按顺序读取消息(从旧到新):
- 顺序写入时,页缓存可高效预加载后续数据页,减少 "缓存未命中" 的概率。
- 顺序读取时,操作系统的 预读机制(Read-Ahead) 会自动将相邻的数据页提前加载到页缓存(例如读取 offset=100 的消息时,预加载 offset=101~200 的数据),进一步提升读取效率。
6.压缩(Compression)
- Kafka 支持消息压缩(如 GZIP、Snappy、LZ4),减少网络传输和磁盘存储开销。
- Producer 把多条消息按批次 gzip/lz4/snappy压缩再发送