在机器学习的世界里,面对复杂的任务,单个模型往往难以达到理想的效果。就像解决一个复杂问题时,多个专家的共同判断通常比单个专家更可靠一样,集成学习通过结合多个学习器的力量,显著提升了模型的性能。本文将带你全面了解集成学习的核心思想、三大主流方法(Bagging、Boosting、Stacking)以及实战案例,让你轻松入门集成学习。
一、集成学习:多个 "专家" 的智慧结晶
集成学习(ensemble learning)的核心思想非常直观:通过构建并结合多个个体学习器来完成学习任务。想象一下,当你面对一个难题时,询问多个领域专家的意见并综合他们的判断,往往能得到更准确的答案。集成学习正是借鉴了这一思路,将多个基础模型(个体学习器)的预测结果通过一定的策略结合起来,最终得到一个性能更优的强学习器。
1. 集成学习的 "决策规则":结合策略
常见的结合策略有以下几种:
简单平均法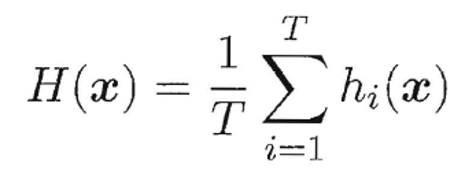
加权平均法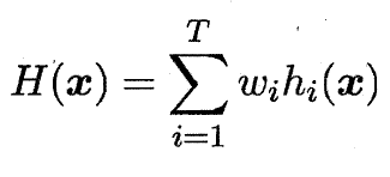
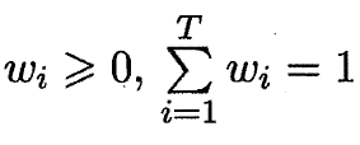
2. 集成学习的效果:提升、无效还是负作用?
集成学习并非总能提升性能,其效果取决于个体学习器的表现。如下图所示:
当个体学习器的错误率较低且误差相互独立时,集成结果能显著提升性能;
当个体学习器的错误高度相关时,集成可能不起作用;
当个体学习器的性能较差且误差方向一致时,集成甚至会起负作用。
因此,构建多样性高、性能较好的个体学习器是集成学习成功的关键。
二、集成算法的分类:并行与串行的对决
根据个体学习器的生成方式,集成学习方法可分为三大类:Bagging、Boosting 和 Stacking。
1. Bagging:并行训练的 "投票团"
Bagging 的全称是 bootstrap aggregation,它的核心思想是并行训练多个分类器,然后通过投票或平均来综合结果。
bootstrap 采样:从原始训练集中有放回地随机采样,生成多个不同的子训练集,每个子训练集用于训练一个个体学习器。
并行生成:个体学习器间不存在强依赖关系,可以同时训练,提高效率。
预测策略:分类任务采用简单投票法,回归任务采用简单平均法,公式为
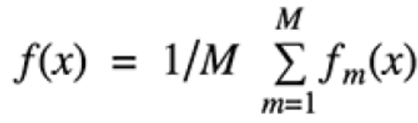 其中M是学习器数量,fm(x)是第m个学习器的预测结果。
其中M是学习器数量,fm(x)是第m个学习器的预测结果。
2. Boosting:串行优化的 "强化师"
Boosting 的核心思想是串行生成个体学习器,通过不断调整样本权重来强化弱学习器,最终组合成强学习器。
弱学习器强化:从弱学习器开始,根据前一个学习器的分类效果调整训练样本的权重 ------ 分错的样本权重提高,分对的样本权重降低,使后续学习器更关注难分样本。
串行生成:个体学习器间存在强依赖关系,必须依次训练,后一个学习器的生成依赖于前一个学习器的结果。
权重分配:每个弱学习器根据自身的准确性获得不同的权重,准确性高的学习器权重更大,最终结果是加权组合的结果。
3. Stacking:暴力融合的 "集成大师"
Stacking 的核心思想是分阶段聚合多个不同类型的模型,堪称集成学习中的 "暴力美学"。
多模型堆叠:可以融合各种类型的分类器或回归模型(如 KNN、SVM、随机森林等)。
分阶段训练:第一阶段让各个基础模型分别对训练数据进行预测,得到预测结果;第二阶段将这些预测结果作为新的特征,训练一个元模型(meta-model),最终由元模型输出最终预测结果。
三、Bagging 的典型代表:随机森林
随机森林(Random Forest)是 Bagging 方法中最著名的应用,它以决策树为个体学习器,通过双重随机性提升模型性能。
1. 随机森林的 "随机" 在哪里?
数据采样随机:采用 bootstrap 采样从原始数据中生成多个子训练集,每个子训练集用于训练一棵决策树。
特征选择随机:在构建决策树的每个节点时,从所有特征中随机选择一部分特征作为候选特征,然后从中选择最优特征进行分裂。
这种双重随机性保证了各个决策树的多样性,避免了单个决策树容易过拟合的问题。
2. 随机森林的优势:为什么它如此受欢迎?
高维数据处理能力:能够直接处理高维度(特征数量多)的数据,无需手动进行特征选择。
特征重要性评估:训练完成后,可以输出各特征的重要性得分,帮助理解数据和模型。
并行化高效:决策树的训练可以并行进行,速度快,适合大规模数据。
可视化友好:决策树结构直观,便于可视化展示和模型分析。
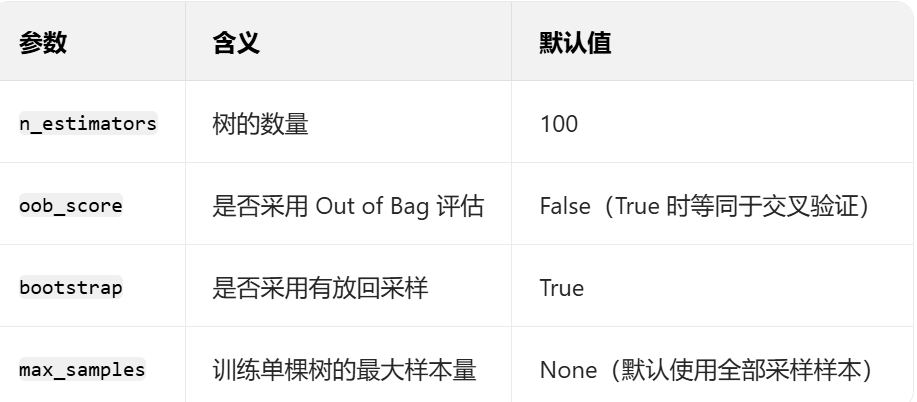
3. 随机森林的关键参数
在 Python 的 scikit-learn 库中,随机森林的分类算法为RandomForestClassifier,回归算法为RandomForestRegressor,常用关键参数如下:
四、Boosting 的经典算法:AdaBoost
AdaBoost(Adaptive Boosting)是 Boosting 方法中最具代表性的算法,它通过自适应地调整样本权重和学习器权重来构建强学习器。
Adaboost会根据前一次的分类效果调整数据权重 解释:如果某一个数据在这次分错了,那么在下一次我就会给它更大的权重 最终的结果:每个分类器根据自身的准确性来确定各自的权重,再合体
五、Stacking:集成学习的 "终极融合"
Stacking 是一种更灵活的集成方法,它不局限于单一类型的学习器,而是融合多种不同模型的优势。
1. Stacking 的分阶段流程
第一阶段(基础模型训练):使用原始训练数据训练多个不同的基础模型(如 KNN、SVM、随机森林等),得到每个模型对训练集和测试集的预测结果。
第二阶段(元模型训练):将第一阶段得到的训练集预测结果作为新的特征,与原始目标标签组成新的训练数据,训练一个元模型(通常是简单模型,如逻辑回归)。
最终预测:用元模型对第一阶段得到的测试集预测结果进行预测,得到最终结果。
2. Stacking 的优势
模型多样性:可以融合不同类型模型的优势,弥补单个模型的不足。
灵活性高:对基础模型的选择没有限制,可根据任务需求灵活搭配。
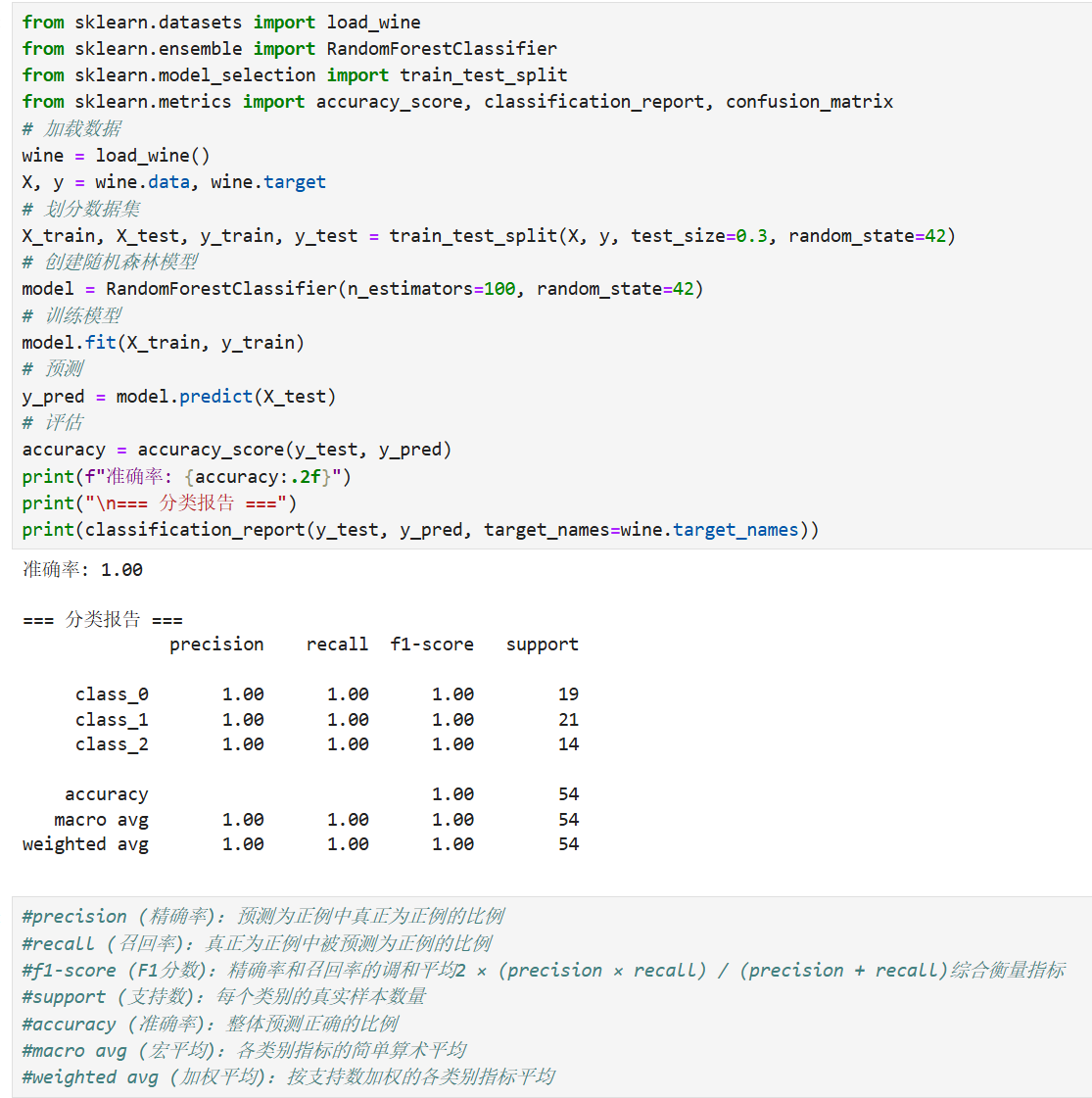
六,实战:用随机森林实现葡萄酒分类
下面我们以葡萄酒数据集为例,实战演示随机森林的分类应用。
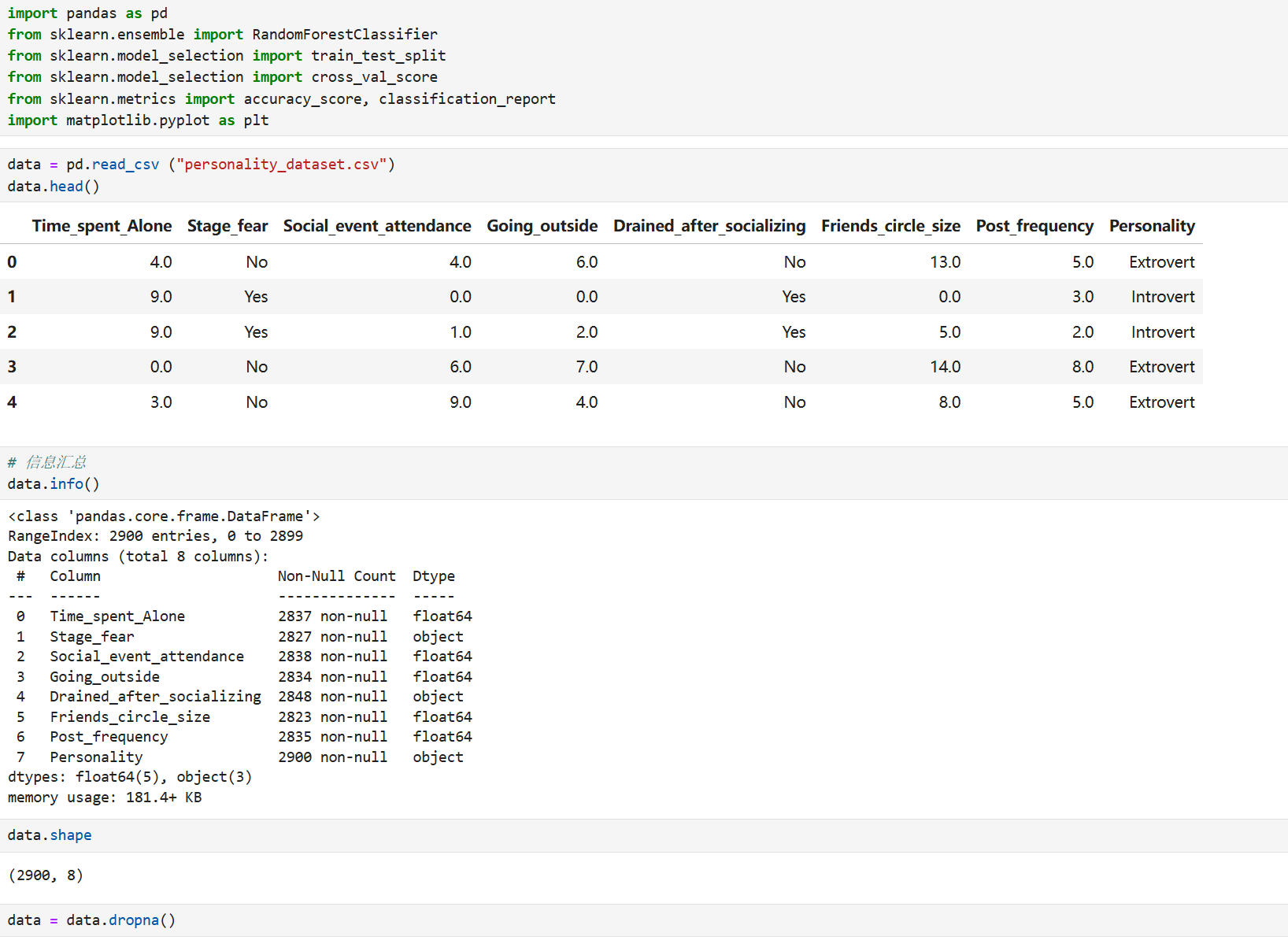
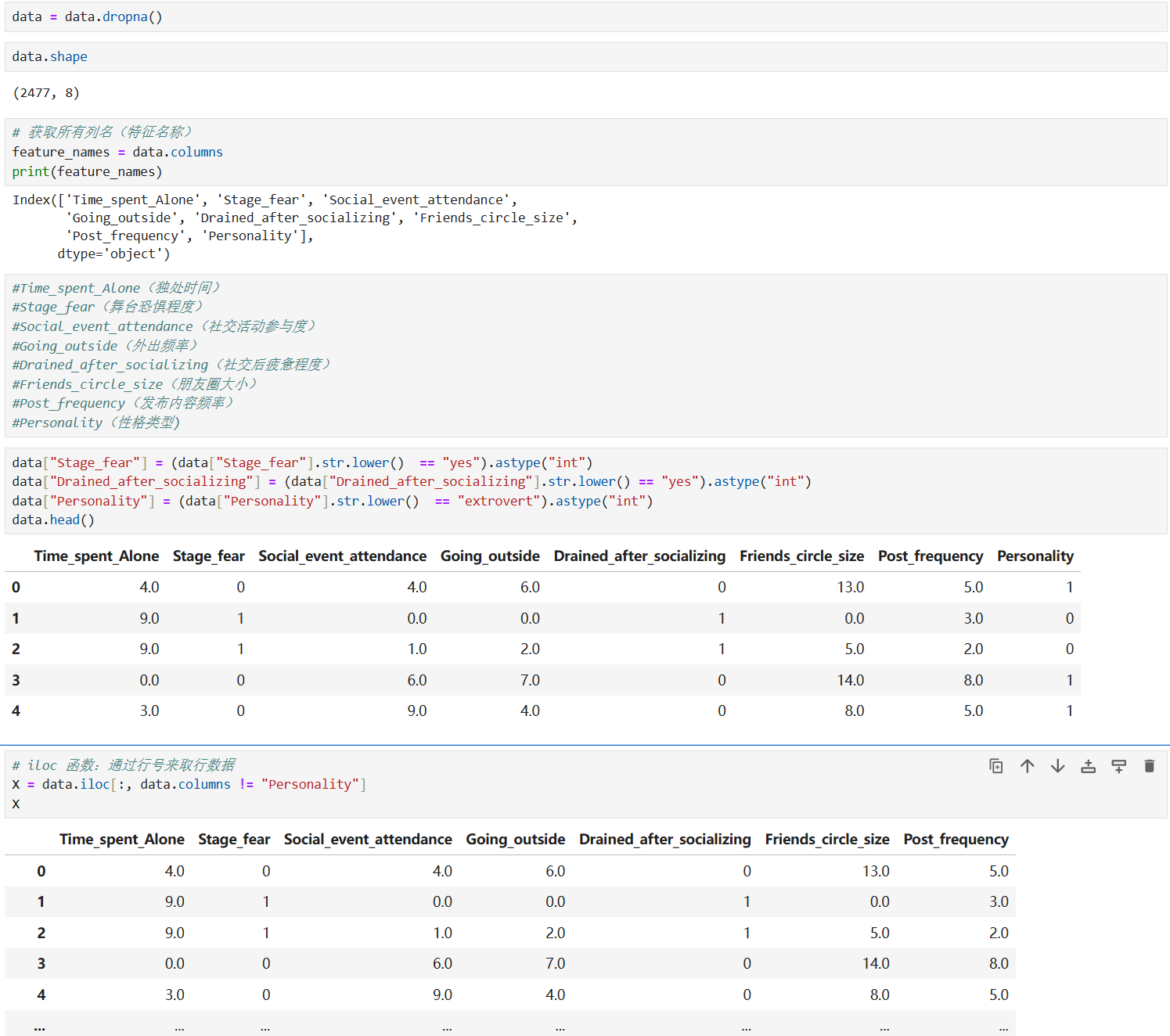
- 实战:用随机森林实现外向与内向的预测
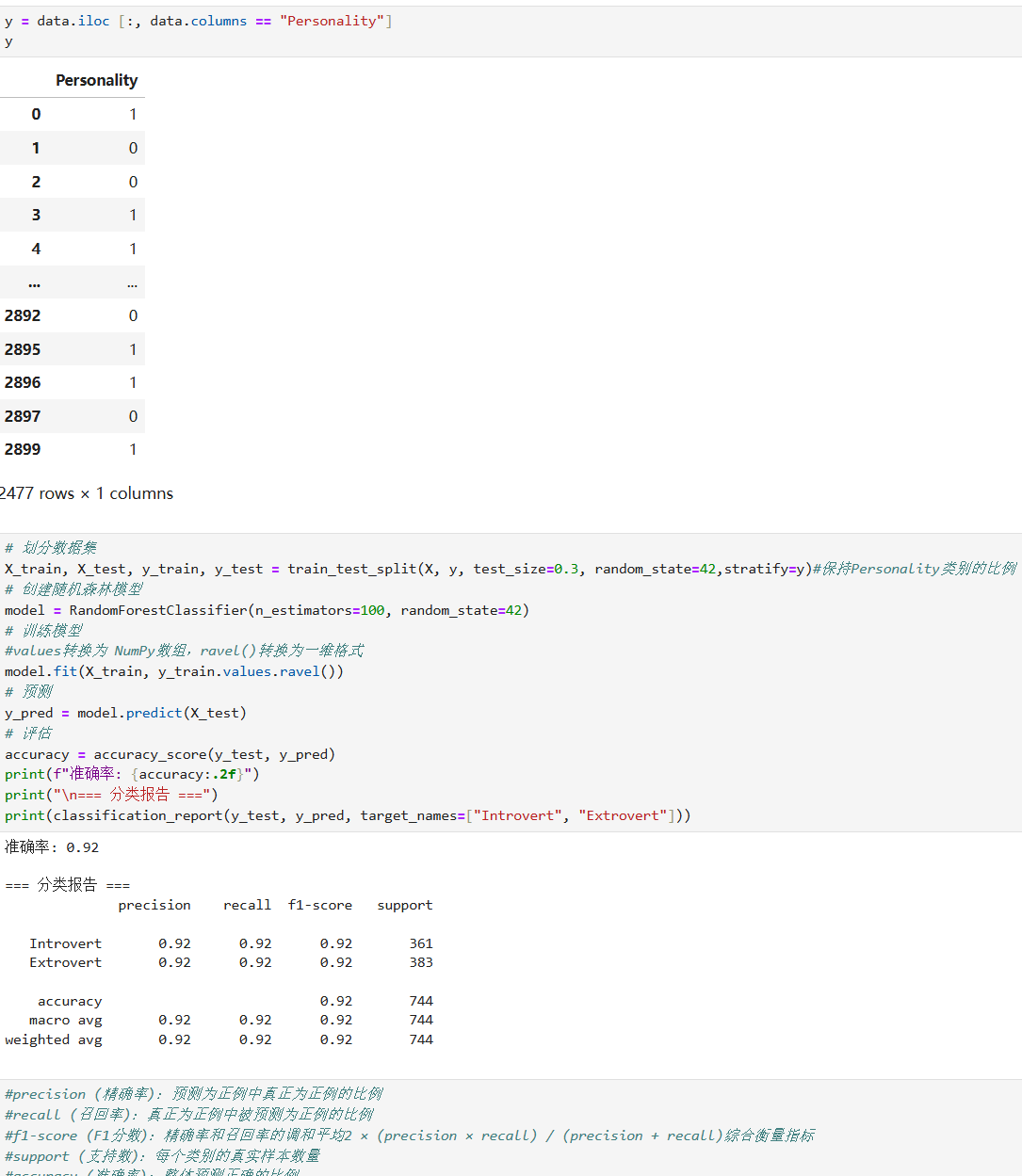
七、总结:如何选择适合的集成算法?
Bagging(随机森林):适用于高维数据、需要并行计算、关注特征重要性的场景,抗过拟合能力强。
Boosting(AdaBoost):适用于需要提升弱学习器性能、样本存在难易区分的场景,收敛速度快。
Stacking:适用于需要融合多种模型优势、追求更高预测精度的场景,灵活性高但实现相对复杂。
集成学习通过 "三个臭皮匠顶个诸葛亮" 的思想,让机器学习模型在复杂任务中表现更出色。希望本文能帮助你理解集成学习的核心原理,并在实际应用中选择合适的算法解决问题!