多标签分类领域中,传统对比学习模型常陷入标签混淆 困境,虽能通过样本间对比挖掘特征关联,但面对标签高度重叠的图像、文本数据时,不仅易混淆不同标签的特征边界,还难以捕捉标签间的依赖关系,导致分类结果漏标、错标频发。而近期CVPR等顶会的重磅研究,以多标签对比学习+标签注意力校准的融合方案打破瓶颈,该方向已成为多媒体分类领域的核心趋势。
**标签注意力校准模块可动态区分不同标签的特征贡献。**在电商商品多属性分类任务中,融合模型较纯对比学习准确率提升21%,标签识别完整性提高28%;在医学影像多病灶诊断场景下,它成功解决"病灶标签相互干扰"问题,多病灶检出准确率提升19%。
对于深耕该领域的论文er,跨模态标签对齐、轻量化对比架构、少样本多标签学习 等方向极具潜力。我已整理相关 顶会/顶刊 核心论文, 部分 还附带复现代码打包免费送 ,感兴趣的同学工种号 沃的顶会 扫码回复 "多标签对比" 领取。
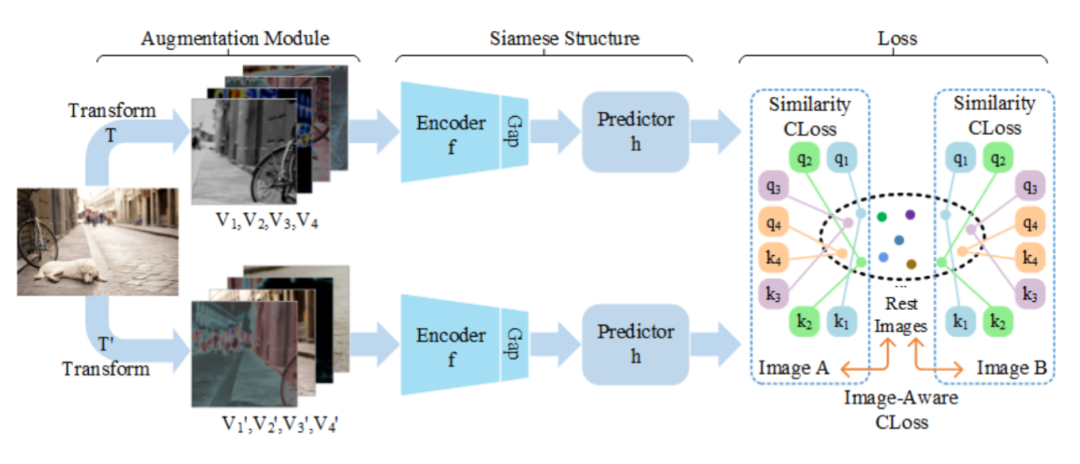
Self-Supervised Contrastive Learning for Multi-Label Images
文章解析
本文提出了一种针对多标签图像的自监督对比学习方法,旨在利用更少的数据量实现高质量的特征表示。传统自监督方法依赖大规模单标签数据(如ImageNet),计算开销大且难以适应多标签场景。为此,作者设计了分块增强模块和图像感知对比损失函数,以提升多标签图像中语义一致性的挖掘能力,并通过线性微调与迁移学习验证了该方法在挑战性样本下的有效性。
创新点
提出了分块增强模块(BAM),从多标签图像中生成更多潜在的正样本对。
设计了图像感知对比损失函数(IA-CLoss),增强视图间的语义关联。
改进了多标签场景下的线性微调验证方法,减少对单标签数据的依赖。
首次将SimSiam框架扩展至多标签图像领域,解决其被忽视的问题。
实现了在少量复杂多标签数据上的高效预训练和迁移学习性能。
研究方法
引入Block-wise Augmentation Module (BAM) 来增强多标签图像的正样本生成能力。
采用SimSiam架构作为基础SSL框架,适配多标签图像特性。
提出Multi-block Image-Aware Contrastive Loss (IA-CLoss) 来建模视图间的语义关系。
在COCO2017等多标签数据集上进行线性分类和迁移学习实验验证方法效果。
分析了传统随机裁剪在多标签图像中的局限性并提出针对性解决方案。
研究结论
所提方法在少量多标签图像上仍能获得竞争力强的表示学习能力。
分块增强和图像感知对比损失有效提升了多标签图像的语义一致性建模。
改进后的验证策略减少了对大规模单标签数据的依赖,拓展了SSL的应用范围。
实验证明该方法在挑战性多标签数据下具有良好的迁移学习表现。
为未来多标签图像的自监督学习研究提供了新的思路和基准。
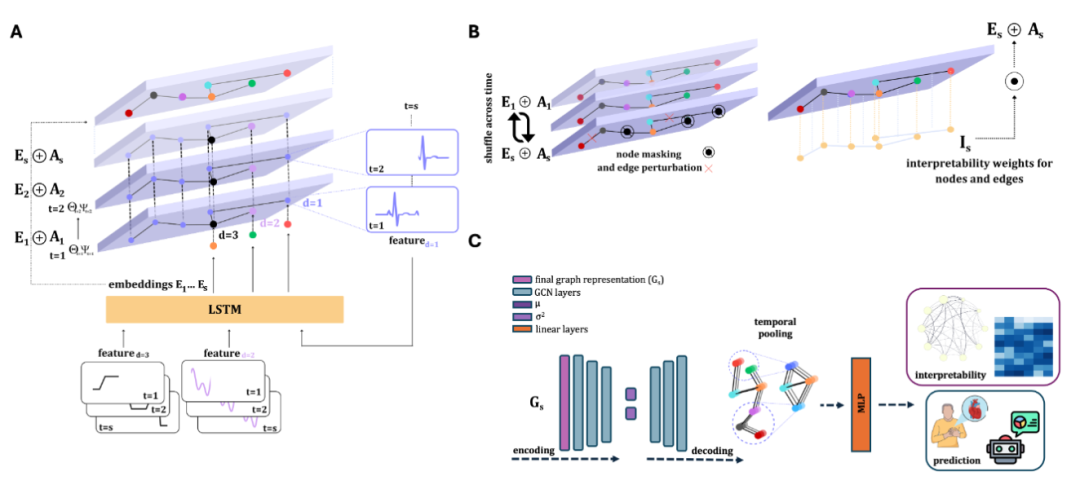
DynaGraph:Dynamic Graph Learning for EHRs
文章解析
本文提出了DynaGraph,这是一种端到端可解释的对比图模型,用于处理多变量电子健康记录(EHRs)的时间序列数据。通过动态图结构建模,该方法能够捕捉临床状态随时间变化的隐藏依赖关系,并在多个真实世界医疗数据集上验证了其优越性能。此外,DynaGraph引入了一种伪注意力机制,提高了模型的可解释性,使得临床医生可以追踪协变量的重要性。
创新点
提出了一种新的时空图方法,结合顺序嵌入、信息传播和伪注意力机制。
首次将动态图学习、时间递归与变分图学习整合到一个统一的框架中。
引入直观的可解释机制,支持时间分辨特征重要性分析。
采用新颖的图增强策略结合对比损失以提升预测性能。
结合焦点损失和结构损失以稳定不平衡多标签时间序列中的动态图学习。
研究方法
构建动态图结构,无需预定义图或静态约束。
通过聚合时序模块的嵌入和可学习的图矩阵来捕捉特征相关性。
使用伪注意力机制聚焦于重要的时间模式。
设计对比学习目标以增强图表示的一致性和判别能力。
结合多种损失函数优化模型在不平衡任务上的表现。
研究结论
DynaGraph在多个ICU和初级护理数据集中显著提升了平衡准确率和敏感度。
模型提供了良好的可解释性,有助于临床验证与信任建立。
所提出的动态图方法优于现有的时间序列和图模型。
实验表明DynaGraph在处理不平衡、多标签任务方面具有鲁棒性。
为基于EHRs的临床预测提供了一个高效且具可解释性的解决方案。