本文较长,建议点赞收藏,以免遗失。文中我也会放一些实战项目,帮助各位更好的学习。
检索增强智能体技术正在重塑AI应用的开发范式,它巧妙地将大语言模型的推理能力与结构化知识检索相结合,解决了传统智能体在处理动态信息时的局限性。今天我将根据实际开发中的痛点:如何设计高效、灵活的智能体系统?深入探讨三大集成模式(工具模式、预检索模式和混合模式)的实战选择,解析RAG(检索增强生成)组件链的构建细节,并分享高级技术如上下文压缩和混合检索的优化技巧。
一、三大核心集成模式对比

| 模式 | 适用场景 | 技术实现 | 优势 |
|---|---|---|---|
| 检索工具模式 | 动态决策场景 | 封装检索系统为Agent工具 | 灵活调用、多工具协同 |
| 预检索增强模式 | 知识密集型任务 | 先检索后注入上下文 | 减少API调用、信息可控 |
| 混合模式 | 复杂推理任务 | 基础上下文+动态检索 | 平衡效率与灵活性 |
二、RAG与智能体融合架构
ini
# RAG基础组件链
from langchain.document_loaders import WebBaseLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
# 1. 文档加载与处理
loader = WebBaseLoader("https://example.com")
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000)
documents = text_splitter.split_documents(docs)
# 2. 向量化存储
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(documents, embeddings)
# 3. 智能体集成
retriever = vectorstore.as_retriever(search_kwargs={"k": 5})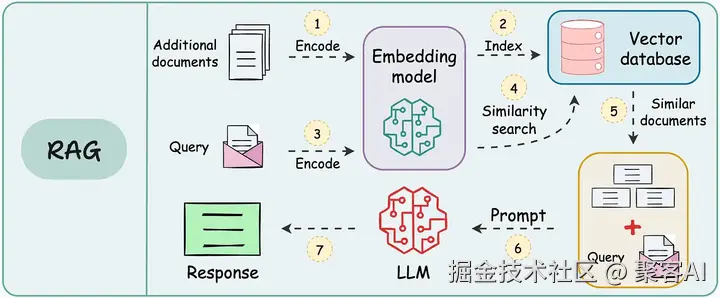
三、高级检索优化技术
1. 上下文压缩技术
ini
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import LLMChainExtractor
compressor = LLMChainExtractor.from_llm(ChatOpenAI(temperature=0))
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor,
base_retriever=vectorstore.as_retriever()
)
# 压缩后文档体积减少40%-60%2. 混合检索策略
ini
# 结合语义与关键词检索
from langchain.retrievers import BM25Retriever, EnsembleRetriever
bm25_retriever = BM25Retriever.from_documents(documents)
ensemble_retriever = EnsembleRetriever(
retrievers=[
vectorstore.as_retriever(search_type="mmr"),
bm25_retriever
],
weights=[0.6, 0.4]
)四、实战设计模式
1. 多步检索智能体工作流
ini
def iterative_retrieval(query, max_depth=3):
context = ""
for i in range(max_depth):
docs = retriever.get_relevant_documents(query)
context += "\n".join(d.page_content for d in docs)
if sufficient_information(context, query):
break
# 生成深化问题
prompt = f"""基于当前信息:{context[:2000]}...
生成更精准的子问题(需满足:{query})"""
query = llm.predict(prompt)
return generate_final_answer(context, query)2. 知识库自更新机制
ini
def knowledge_update_agent(new_data):
# 信息价值评估
evaluation_prompt = f"""评估信息价值(1-10分):
{new_data}
评估维度:新颖性、准确性、完整性"""
score = int(llm.predict(evaluation_prompt))
if score >= 8:
# 知识结构化处理
structuring_prompt = f"""将信息转化为知识条目:
- 保留核心事实
- 删除冗余描述
- 标准化术语
原始信息:{new_data}"""
structured_knowledge = llm.predict(structuring_prompt)
vectorstore.add_documents([Document(structured_knowledge)])五、性能优化关键点
提示工程三原则
- 明确检索触发条件:当遇到以下情况时使用文档搜索:①需要实时数据 ②上下文缺失
- 强制引用机制:每个结论需标注来源编号doc1
- 探索平衡策略:首轮使用预检索,后续动态调用工具
检索效率提升
python
# 查询重写技术
def query_rewriter(original_query):
return llm.predict(f"将用户查询优化为检索友好格式:{original_query}")
# 结果过滤管道
from langchain.retrievers import TFIDFFilter
filtered_retriever = TFIDFFilter(retriever, threshold=0.7)六、行业应用及实践
客户支持系统架构
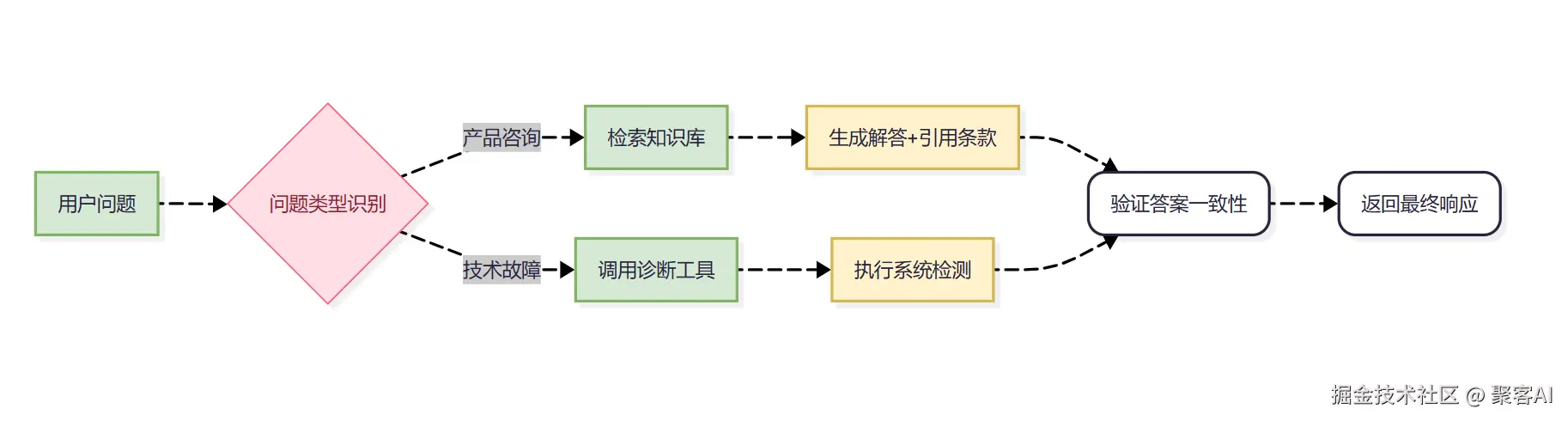
实践资源
这里再给大家分享一个基于 ChatGLM 等大语言模型与 Langchain 等应用框架实现,开源、可离线部署的检索增强生成(RAG)大模型知识库项目。建议各位最好实践一下,能更好的帮助大家学习和理解,粉丝朋友自行领取:《Langchain-chatchat V0.2.10》
检索增强智能体的核心价值在于平衡知识利用与动态探索:它让AI不再依赖静态训练数据,而是能主动查询、整合实时信息。最后,记住优化黄金法则:明确检索触发条件、强制引用来源、优先预检索提速。未来,随着多模态检索的演进,这项技术将更深度赋能行业。动手试试分享的实战代码吧,从简单预检索开始,逐步扩展至混合架构------您的智能体应用已经呼之欲出。好了,今天的分享就到这里,点个小红心,我们下期见。