系列文章目录
机器视觉:智能车大赛视觉组技术文档------OpenArt结合OpenMV实现色块检测
机器视觉:智能车大赛视觉组技术文档------用 YOLO3 Nano 实现目标检测并部署到 OpenART
机器视觉:智能车大赛视觉组技术文档------用eIQ工具高效训练分类模型
机器视觉:智能车大赛视觉组技术文档------第20届智能车比赛视觉组视觉模块多种思路分析
文章目录
- 系列文章目录
- 前言
- 一、YOLO3算法简介
- [二、基于TensorFlow 2.x的轻量级YOLO3模型(YOLO3 Nano)简介](#二、基于TensorFlow 2.x的轻量级YOLO3模型(YOLO3 Nano)简介)
- 三、需要文件的下载安装
- 三、打标教程及技巧:为训练准备高质量数据
- 三、训练模型教程:从数据到可用模型
- 四、部署模型到OpenART
前言
上一篇博客 我们在讲色块检测的时候有提到,很多情况下我们也会选择yolo目标检测作为一种更加稳定的方案,他不需要现场调节阈值,可以很稳定的实现对选定目标的框取定位。
而在比赛之外,在嵌入式设备上实现高效的目标检测,一直是计算机视觉领域的热门需求。无论是智能小车避障、无人机巡检,还是便携式安防设备,都需要轻量级、低功耗且精度足够的模型。今天,我们就来聊聊如何利用YOLO3 Nano------一个基于TensorFlow 2.x的轻量级YOLO3实现,完成从数据打标、模型训练到部署到OpenART硬件的全流程。
本文适合对目标检测感兴趣的初学者,无需深厚的深度学习理论基础,跟着步骤操作就能上手。让我们一步步把"目标检测"搬进openart中吧
一、YOLO3算法简介
在聊YOLO3 Nano之前,我们先简单了解下它的"前辈"------YOLO3算法。
YOLO(You Only Look Once)是经典的单阶段目标检测算法,核心优势是"快"。与两阶段算法(如Faster R-CNN)相比,YOLO将目标检测视为一个端到端的回归问题,直接从图像中预测目标的边界框和类别,省去了复杂的区域提案(Region Proposal)步骤,因此推理速度极快,适合实时场景。
YOLO3在YOLOv1、v2的基础上做了多项改进:
- 多尺度检测:通过3个不同尺度的特征图(13×13、26×26、52×52),分别检测大、中、小目标,提升了对小目标的识别能力;
- 特征融合:使用跳跃连接(Skip Connection)融合不同层级的特征(浅层特征含细节,深层特征含语义),让检测更精准;
- 骨干网络升级:采用Darknet-53作为特征提取网络,兼顾精度和速度;
- 锚框机制:预设9种不同尺寸的锚框(Anchors),通过聚类数据集目标尺寸生成,提升边界框预测效率。
不过,YOLO3的Darknet-53网络仍有较多参数,在嵌入式设备上(比如说本次智能车大赛指定的openmv视觉模块或者是算力稍微好一点树莓派、Nano)运行时会面临算力和内存限制。因此,轻量级版本------YOLO3 Nano应运而生。
二、基于TensorFlow 2.x的轻量级YOLO3模型(YOLO3 Nano)简介
YOLO3 Nano是针对资源受限设备设计的轻量化YOLO3实现,核心特点是"轻量"和"易用":
- 轻量级设计:简化了YOLO3的骨干网络,减少卷积层数量和通道数,大幅降低模型参数(通常只有原YOLO3的1/10左右),适合在嵌入式设备(如OpenART)上运行;
- TensorFlow 2.x支持:基于TensorFlow 2.x框架实现,兼容Keras高阶API,训练和部署更灵活,且支持导出为TFLite格式(轻量级推理格式);
- 完整工具链:配套提供了数据集转换、锚框生成、训练、评估、推理的全套脚本,无需从零搭建流程;
- OpenART适配:针对嵌入式硬件优化,可直接部署到OpenART设备(一种面向边缘计算的智能硬件),满足实时检测需求。
三、需要文件的下载安装
链接:https://pan.baidu.com/s/1EaHbtiiy0zJTN2bIdIjWpw
提取码:ciwu
下载解压之后是包含着四个文件或文件夹的,其具体作用在下面会详细介绍
三、打标教程及技巧:为训练准备高质量数据
模型训练的效果,很大程度上取决于数据集的质量。YOLO3 Nano支持VOC格式数据集,因此我们需要用工具标注图像,并生成VOC格式的标注文件。 打标的意思就是为数据添加标签,简单来说就是告诉模型这个图片里面的哪些区域是我要检测的东西,其属于哪个类别(不过在这边我们用的只有一个类别,因为我们暂时只需要进行目标检测)
工具准备:LabelImg
LabelImg是一款开源的图像标注工具,支持生成VOC格式(XML文件)的标注结果,操作简单,适合初学者。
安装命令(Windows/Mac/Linux通用):
bash
pip install labelimg安装完成后,在终端输入labelimg即可启动。
或者是这个压缩文件里面其实是提供了完整的打标工具的,进入label_img目录下直接运行mainUI.exe这个可执行文件既可进行打标
打标步骤
-
准备图像 :
收集需要检测的目标图像,建议至少收集500张以上(数量越多,模型泛化能力越强)注意不可以直接用比赛官方提供的数据集进行标注,一定要把数据集全部打印出来用摄像头一张一张的拍下在真实环境中的真实图片(不过去年逐飞官方有提到一个p图的方法,也可以参考参考),在目标检测的时候倒是不需要拍下所有类别的所有照片,大概拍一部分500张以上就可以了,实测数据集在5000张以上的时候定位效果是非常稳定的。这个数据集也可以按拍照图片的类别保存后,后期经过yolo模型处理之后可以作为训练分类模型的数据集,就可以少拍一些之后的分类模型数据集了(这个才是最折磨人的)
-
启动标注环境 导入图片 (以逐飞官方提供的labe_img为例):
按上述步骤进入mainUI.exe之后界面如下,需要按图片步骤导入拍摄的图片路径:
点开导入之后有一个打开图片文件夹的选项,选中你存放拍摄的图片的路径下就可以了,效果如下:
-
新建工程
点击左上角的文件------然后选择新建工程------在弹出的界面中选择User Define Objects------在Input Types里面输入object(注意一定要是object 不可以是别的否则在训练的时候会报错,除非你的代码基础比较好可以直接尝试修改备注文件或者标注工程文件)
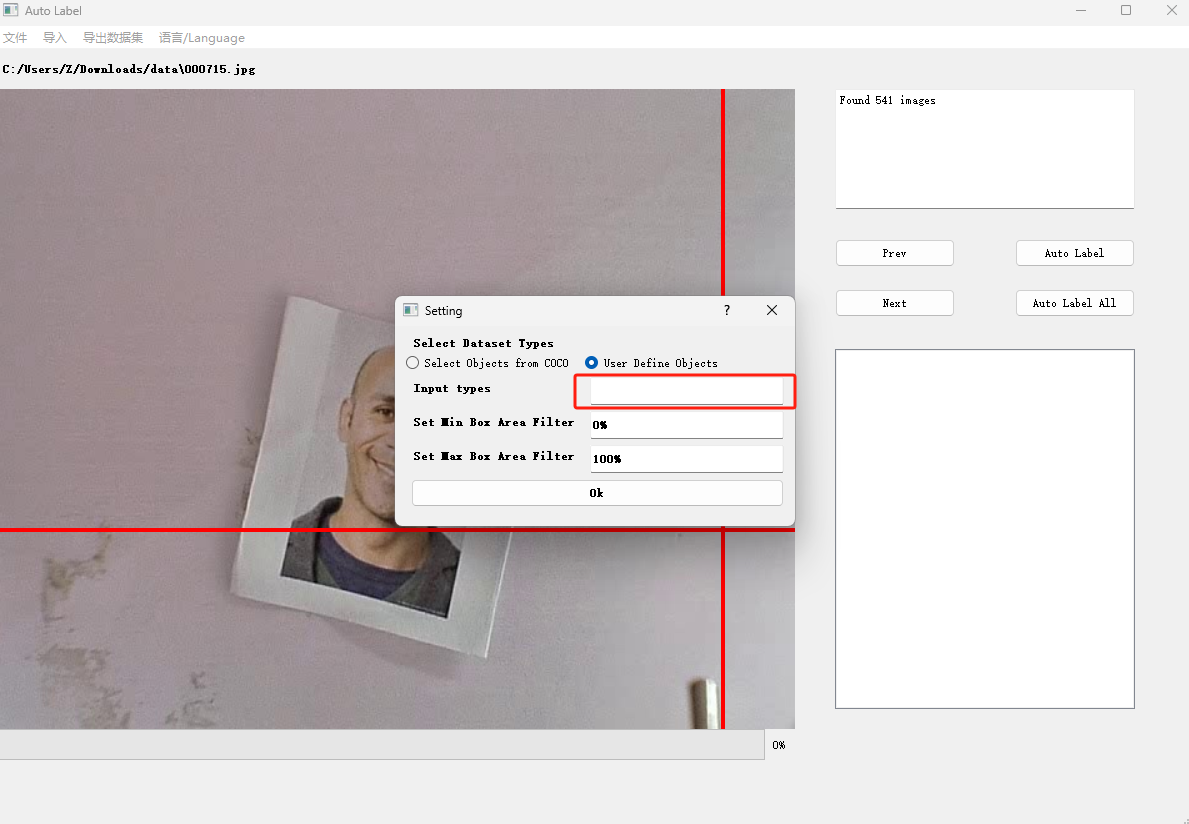
-
标注目标 :
这里面的标注框选工具是默认唤醒的,直接进行框选就好,框选之后会出现类别的选择项,由于这边使用的是单目标检测,所以直接选择object_0就可以了

打完这张图的标记之后可以按Next进入下一张的标注
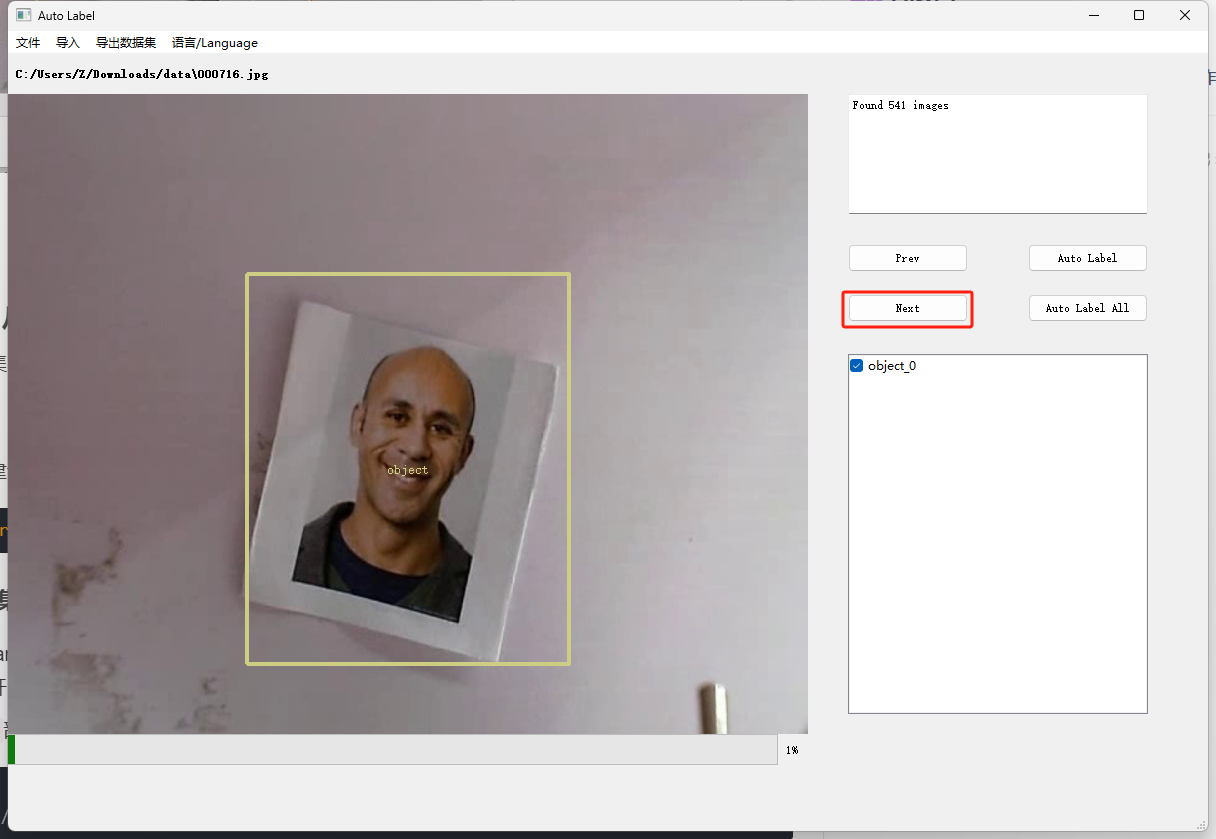
-
导出数据集 :
按导出数据集------保存voc文件既可进行打标结果的保存,这个保存的数据集是直接适配于文件中的yolo3Nano的训练代码的,不需要再进行格式调整什么的。
保存之后的是一个tar压缩包,解压之后数据集格式如下:

JPEGImage就是原始的图片数据

Annotations文件夹是与图片一一对应的打标数据(文件名相同,猴嘴不同为xml文件)

文件打开之后格式如下:
<annotation> <folder>data</folder> <filename>000716.jpg</filename> <path>C:\Users\Z\Downloads\data\000716.jpg</path> <source> <database>Unknown</database> </source> <size> <width>640</width> <height>480</height> <depth>3</depth> </size> <segmented>0</segmented> <object> <name>object</name> <pose>Unspecified</pose> <truncated>0</truncated> <difficult>0</difficult> <bndbox> <xmin>191</xmin> <ymin>135</ymin> <xmax>449</xmax> <ymax>428</ymax> </bndbox> </object> </annotation>标注文件为 Pascal VOC 格式(常用于 YOLO 等模型训练),主要信息如下:
标注图像:位于 "data" 文件夹,文件名为 "000716.jpg",路径为 "C:\Users\Z\Downloads\data\000716.jpg";
图像尺寸:宽 640、高 480、深度 3(RGB 格式),无分割标注(segmented=0);
标注物体:1 个类别为 "object" 的物体,姿态未指定,未截断(truncated=0),不难识别(difficult=0),边界框坐标为 xmin=191、ymin=135、xmax=449、ymax=428。
打标技巧
1、进入下一张的时候可以直接按空格复刻上一次的按钮操作(Prev 或者 Next) 就不需要数据在框选和Next那边来回点击了
2、建议打一部分就按一次导出数据集------保存voc文件,不然万一这个程序抽风崩溃或者卡死前面的标就全部白打了
三、训练模型教程:从数据到可用模型
有了标注好的数据集,接下来我们用YOLO3 Nano的工具链训练模型。
环境准备
首先安装依赖库(建议用虚拟环境隔离):
bash
pip install tensorflow==2.11.0 numpy==1.23.4 pillow opencv-python configparser argparse matplotlib步骤1:配置数据集路径
-
打开刚才下载的文件夹里面yolo3_smartcar路径,找到项目根目录下的
config.cfg文件,用记事本或VS Code打开。 -
找到
[dataset]部分的voc_folder参数,填写VOC格式数据集的根目录路径:
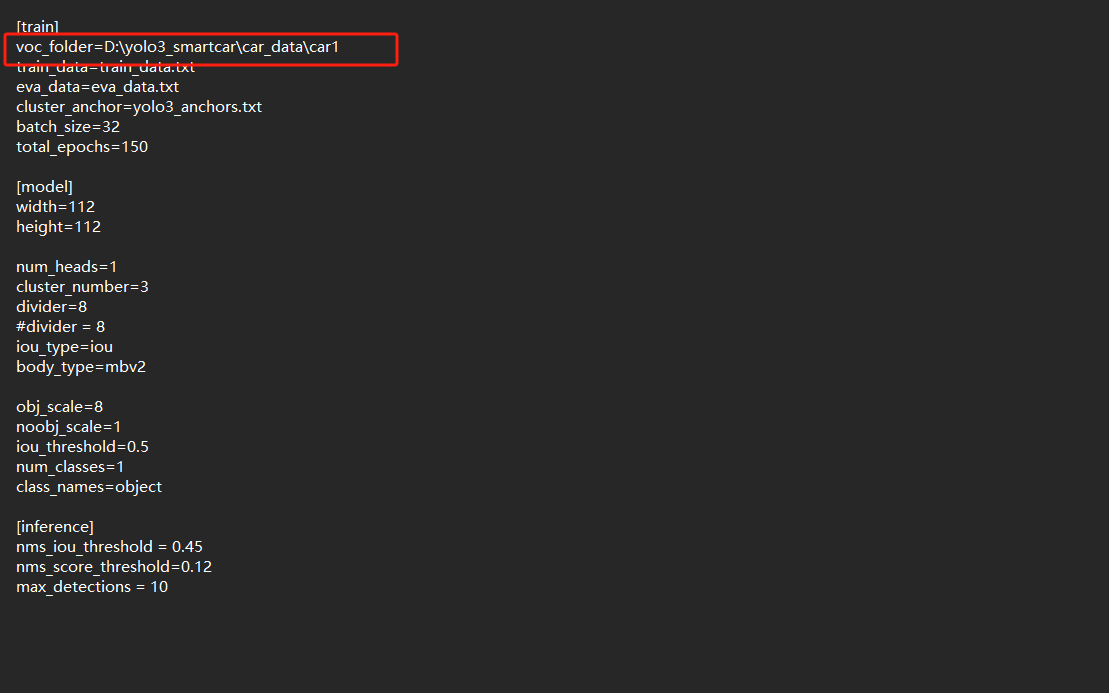
修改为刚才标注导出的tar文件的解压之后的路径
数据集目录结构需符合VOC格式(如下),其中JPEGImages放图像,Annotations放XML标注文件,ImageSets/Main下放train.txt和val.txt(记录训练/验证图像的文件名):VOC2007/ ├─ JPEGImages/ # 图像文件(.jpg) ├─ Annotations/ # 标注文件(.xml) └─ ImageSets/ └─ Main/ ├─ train.txt # 训练集图像文件名(无后缀) └─ val.txt # 验证集图像文件名(无后缀)
步骤2:转换数据集
YOLO3 Nano需要将VOC格式的XML文件转换为模型可直接读取的TFRecord格式(高效存储数据)。运行以下命令:
bash
python voc_convertor.py脚本会自动读取config.cfg中的数据集路径,生成train.tfrecord和val.tfrecord文件(保存在项目根目录)。

步骤3:生成锚框(Anchors)
锚框(Anchor Box) 是一种预先设定的、具有固定宽高比例的边界框,用于辅助模型更高效地预测图像中目标的位置和大小。它的核心作用是 "降低预测难度"------ 通过预设的 "模板框",让模型只需学习 "如何调整模板",而不是从零开始预测目标的边界框。
YOLO算法依赖锚框预测目标边界框,锚框的尺寸需要根据数据集的目标尺寸通过K-means聚类生成(更贴合数据分布)。运行:
bash
python kmeans.py脚本会输出9个锚框的尺寸(如[[10,13], [16,30], ...]),并自动更新到config.cfg的anchors参数中。
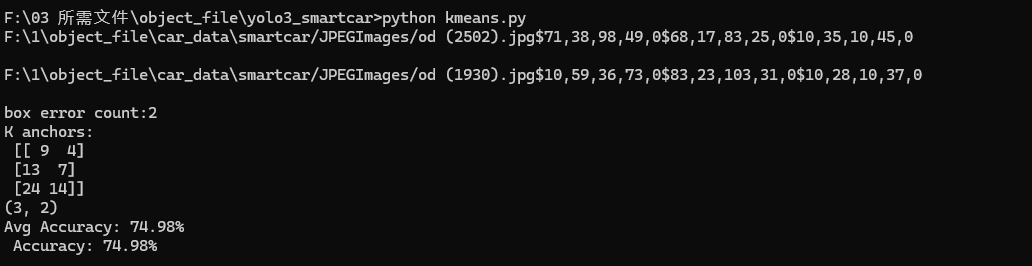
输出结果解析:
1、发现了 2 个无效标注框(需检查并修正,避免影响模型训练);
2、聚类得到 3 个锚框(9×4、13×7、24×14),这些锚框会被用于 YOLO3 Nano 模型的边界框预测;
3、锚框与真实目标的平均匹配度为 74.98%,聚类效果合格,可用于后续训练
步骤4:训练模型
运行训练脚本,开始模型训练:
bash
python train.py训练过程中,脚本会自动加载数据集、初始化模型、计算损失并更新参数。关键参数可在config.cfg中调整:
batch_size:批次大小(根据显卡显存调整,建议8-32);epochs:训练轮数(建议100-300轮,根据验证集精度调整);learning_rate:学习率(初始建议0.001,后期可衰减)。
训练过程中,模型会定期保存到checkpoints目录,同时在logs目录生成TensorBoard日志(可通过tensorboard --logdir=logs查看损失和精度曲线)。
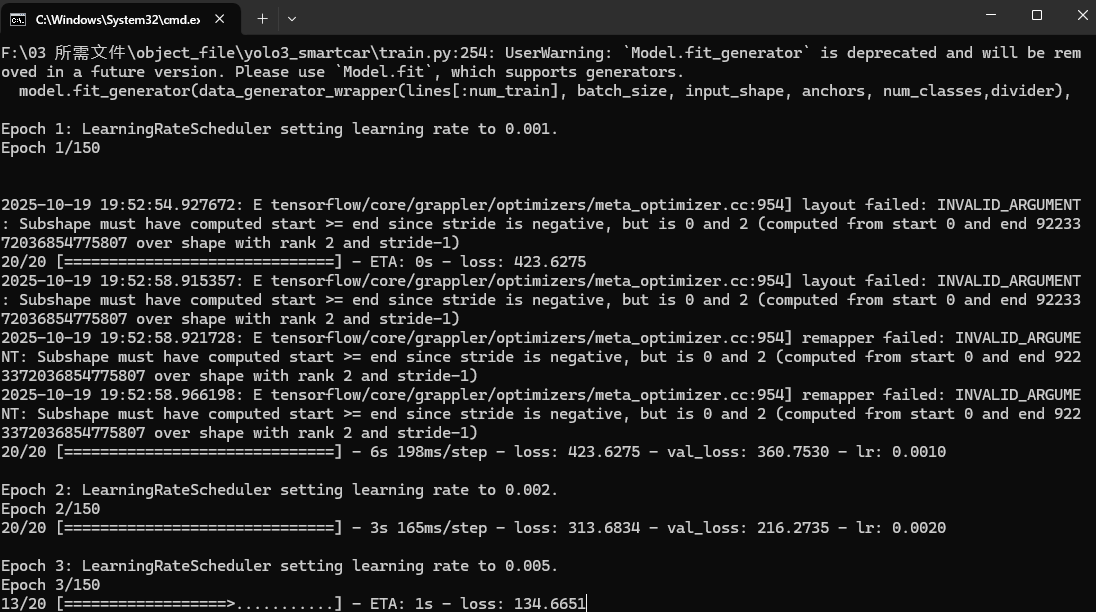
这样就是正确开始训练了,耗时不会很长,具体根据你的batch_size和epochs等决定
步骤5:评估模型
训练完成后,用验证集评估模型性能(主要看mAP:平均精度均值):
bash
python evaluate.py输出结果中,mAP值越高(接近1),模型性能越好。如果精度较低,可增加数据集数量、调整训练参数或优化标注质量。
四、部署模型到OpenART
训练好的模型需要转换为嵌入式设备支持的格式,才能部署到OpenART。YOLO3 Nano已支持导出TFLite格式(轻量级推理格式),并附带后处理逻辑(简化部署流程)。
步骤1:导出TFLite模型
训练完成后,项目会自动生成包含后处理的TFLite模型(yolo3_iou_smartcar_final_with_post_processing.tflite),无需额外转换。
步骤2:部署到OpenART
OpenART是一款支持TFLite推理的嵌入式硬件,部署步骤超简单:
- 将
yolo3_iou_smartcar_final_with_post_processing.tflite复制到SD卡中; - 将SD卡插入OpenART硬件的SD卡槽;
- 启动OpenART,运行以下官方提供的代码(我已加上详细注释很好理解)。硬件会自动加载TFLite模型并运行目标检测:
python
# 导入必要的库
# seekfree/pyb:OpenART硬件专用库,用于控制底层硬件(如摄像头、IO口)
# sensor:摄像头传感器控制库,负责图像采集
# image:图像处理库,用于绘制检测框、图像预处理等
# time:时间工具库,用于计时和帧率计算
# tf:TensorFlow Lite推理库,用于加载模型并执行目标检测
# gc:垃圾回收库,嵌入式设备内存有限,用于主动释放内存避免溢出
import seekfree, pyb
import sensor, image, time, tf, gc
# ----------------------------
# 1. 摄像头传感器初始化配置
# ----------------------------
# 重置摄像头传感器(类似重启,确保初始状态正确)
sensor.reset()
# 设置像素格式:RGB565(每个像素占2字节,兼顾色彩显示和内存占用)
# 可选格式:GRAYSCALE(灰度图,1字节/像素,更省内存但无色彩)
sensor.set_pixformat(sensor.RGB565)
# 设置图像分辨率:QVGA(320x240)
# 选择原因:嵌入式设备算力有限,低分辨率可提升帧率(实时性更优);若需更高精度,可尝试VGA(640x480)但帧率会下降
sensor.set_framesize(sensor.QVGA)
# 跳过初始2000ms的图像帧
# 原因:摄像头刚启动时,曝光、白平衡等参数未稳定,前几帧图像可能偏暗/偏色,跳过可保证后续检测稳定性
sensor.skip_frames(time=2000)
# 创建时钟对象,用于计算实时帧率(FPS)
clock = time.clock()
# ----------------------------
# 2. 加载YOLO3 Nano模型
# ----------------------------
# 模型路径:TFLite模型存储在SD卡中(OpenART通常通过SD卡读取外部文件)
# 此处路径对应之前部署的"带后处理的模型"(已集成NMS等后处理逻辑,直接输出最终检测结果)
model_path = '/sd/yolo3_iou_smartcar_final_with_post_processing.tflite'
# 加载模型:通过tf.load()方法将模型从SD卡加载到内存
# 注意:若模型加载失败,可能是路径错误或模型文件损坏,需检查SD卡中的文件
net = tf.load(model_path)
# 主动触发一次垃圾回收,释放模型加载过程中可能产生的临时内存占用
gc.collect()
# ----------------------------
# 3. 实时目标检测主循环
# ----------------------------
while True:
# 记录当前时间(用于后续计算帧率)
clock.tick()
# 从摄像头获取一帧图像(snapshot()返回image对象,可直接用于检测和绘制)
img = sensor.snapshot()
# ----------------------------
# 3.1 执行目标检测
# ----------------------------
# 使用加载的模型检测图像中的目标
# tf.detect(net, img)返回检测结果列表:每个元素是一个目标的信息(坐标、类别、置信度)
# 注:模型输出的坐标是"归一化坐标"(范围0~1),需后续转换为实际像素坐标
detect_results = tf.detect(net, img)
# ----------------------------
# 3.2 处理检测结果
# ----------------------------
for obj in detect_results:
# 解析单个目标的信息:
# x1, y1:目标左上角坐标(归一化,0~1)
# x2, y2:目标右下角坐标(归一化,0~1)
# label:目标类别ID(对应训练时的类别,如0代表"车")
# scores:目标置信度(0~1,值越高,模型对该目标的判断越可靠)
x1, y1, x2, y2, label, scores = obj
# 过滤低置信度目标:只保留置信度>70%的结果
# 目的:减少误检(模型可能把背景误判为目标),提升检测可靠性
if scores > 0.7:
# 打印目标信息(调试用,可查看检测到的目标细节)
print(f"检测到目标:类别={label},置信度={scores:.2f},坐标=({x1:.2f},{y1:.2f})-({x2:.2f},{y2:.2f})")
# ----------------------------
# 3.3 坐标转换:归一化坐标 → 实际像素坐标
# ----------------------------
# 模型输出的x1,y1,x2,y2是相对于图像宽高的比例(0~1),需转换为实际像素值
# 图像实际宽高:img.width()=320,img.height()=240(对应QVGA分辨率)
img_width = img.width() # 图像宽度(像素)
img_height = img.height() # 图像高度(像素)
# 计算目标宽度和高度(归一化)
w_norm = x2 - x1 # 归一化宽度
h_norm = y2 - y1 # 归一化高度
# 转换为实际像素坐标(x1_offset是可选的校准参数,若检测框整体偏右,可减偏移量)
x1_pixel = int((x1 - 0.05) * img_width) # 左上角x像素(-0.05为示例校准值,可根据实际偏移调整)
y1_pixel = int(y1 * img_height) # 左上角y像素
w_pixel = int(w_norm * img_width) # 宽度像素
h_pixel = int(h_norm * img_height) # 高度像素
# 确保坐标在图像范围内(避免超出图像边界导致绘制错误)
x1_pixel = max(0, min(x1_pixel, img_width))
y1_pixel = max(0, min(y1_pixel, img_height))
w_pixel = max(1, min(w_pixel, img_width - x1_pixel)) # 宽度至少为1,避免无效框
h_pixel = max(1, min(h_pixel, img_height - y1_pixel))
# ----------------------------
# 3.4 绘制检测框
# ----------------------------
# 在图像上绘制矩形框标记目标,线宽为2像素,颜色默认红色(RGB565格式下可自定义)
img.draw_rectangle((x1_pixel, y1_pixel, w_pixel, h_pixel), thickness=2)
# 可选:在框上方绘制类别和置信度文本(增强可视化效果)
# 文本内容:类别ID + 置信度(保留2位小数)
text = f"cls{label}: {scores:.2f}"
# 绘制文本:位置在框左上角上方,字体大小1(最小),颜色红色
img.draw_string(x1_pixel, y1_pixel - 10, text, color=(255, 0, 0), scale=1)
# ----------------------------
# 3.5 输出实时帧率
# ----------------------------
# 计算并打印当前帧率(FPS = 每秒处理的图像帧数)
# 嵌入式设备中,FPS越高说明实时性越好(通常需≥10FPS才流畅)
print(f"帧率:{clock.fps():.1f} FPS")
# 定期触发垃圾回收,释放循环中产生的临时内存(避免内存泄漏)
gc.collect()步骤3:验证部署效果
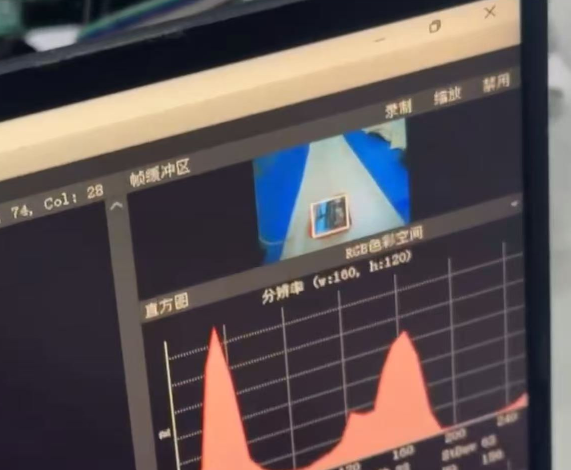
如果需要在PC上提前验证TFLite模型的效果,可运行项目提供的检测脚本:
脚本会读取图像并输出检测结果(目标位置和类别),效果如下(由于openart都给下一届学弟拿去学习了,现在手上没有openart 这还是从以前视频截的照片):
总结
通过本文,我们完成了从数据打标、模型训练到部署到OpenART的全流程。YOLO3 Nano的轻量级设计让它在openart设备上"跑得动",而TensorFlow 2.x的生态则简化了训练和部署流程。
回顾整个过程,高质量的数据集 是模型效果的基础,合理的锚框和训练参数 是模型精度的保障,而TFLite格式则是连接训练与部署的桥梁。如果想进一步提升性能,可以尝试:
- 增加数据增强(如旋转、裁剪、亮度调整);
- 微调模型结构(如增加注意力机制);
- 量化模型(TFLite支持INT8量化,进一步降低推理耗时)。