提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 前言
- [1. 我的竞赛列表](#1. 我的竞赛列表)
-
- [1.1 遗留问题](#1.1 遗留问题)
- [1.2 后端开发](#1.2 后端开发)
- [1.3 竞赛报名前端开发](#1.3 竞赛报名前端开发)
- [2. 题目列表功能](#2. 题目列表功能)
-
- [2.1 elasticSearch基本知识](#2.1 elasticSearch基本知识)
- [2.2 elasticSearch使用](#2.2 elasticSearch使用)
- [2.2 Kibana](#2.2 Kibana)
- [3. es命令](#3. es命令)
-
- [3.1 PUT增加](#3.1 PUT增加)
- [3.2 GET查询](#3.2 GET查询)
- [3.3 DELETE删除](#3.3 DELETE删除)
- [3.4 POST修改](#3.4 POST修改)
- [3.5 分词器](#3.5 分词器)
- [3.6 安装ik分词器](#3.6 安装ik分词器)
- [3.7 分词模式](#3.7 分词模式)
- [3.8 项目引入](#3.8 项目引入)
- 总结
前言
1. 我的竞赛列表
1.1 遗留问题
处理完用户请求之后,要清理ThreadLocal里面的数据
---》拦截器--》after可以完成这个功能--》清理所有的数据,因为这个线程已经没了,数据肯定也要清理掉了
java
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
ThreadLocalUtil.remove();
}这样就可以了
1.2 后端开发
java
@GetMapping("/list")
public TableDataInfo list(ExamQueryDTO examQueryDTO){
log.info("获取用户报名的竞赛信息,examQueryDTO:{}", examQueryDTO);
return userExamService.list(examQueryDTO);
}直接复制获取exam历史和已发布的竞赛的代码,然后改改
java
@AllArgsConstructor
@Getter
public enum ExamListType {
EXAM_UN_FINISH_LIST(0),
EXAM_HISTORY_LIST(1),
USER_EXAM_LIST(2);
private final Integer value;
}
java
private String getExamListKey(Integer examListType,Long userId) {
if (ExamListType.EXAM_UN_FINISH_LIST.getValue().equals(examListType)) {
return CacheConstants.EXAM_UNFINISHED_LIST;
} else if (ExamListType.EXAM_HISTORY_LIST.getValue().equals(examListType)) {
return CacheConstants.EXAM_HISTORY_LIST;
}else if(ExamListType.USER_EXAM_LIST.getValue().equals(examListType)){
return CacheConstants. +userId;
}
return null;
}尤其是改ExamCacheManager,主要就是增加了userid
java
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.ck.friend.mapper.user.UserExamMapper">
<select id="selectUserExamList" resultType="com.ck.friend.domain.exam.vo.ExamVO">
SELECT
e.exam_id,
e.title,
e.start_time,
e.end_time
FROM
tb_user_exam ue
JOIN
tb_exam e
ON
ue.exam_id = e.exam_id
WHERE
ue.user_id = #{userId}
ORDER BY
ue.create_time DESC
</select>
</mapper>
java
@Override
public TableDataInfo list(ExamQueryDTO examQueryDTO) {
examQueryDTO.setType(ExamListType.USER_EXAM_LIST.getValue());
Long userId= ThreadLocalUtil.get(Constants.USER_ID,Long.class);
Long listSize = examCacheManager.getListSize(examQueryDTO.getType(),userId);
List<ExamVO> list ;
if(listSize==null||listSize==0){
//说明缓存中没有数据,所以要先从数据库中获取数据,然后存入redis
PageHelper.startPage(examQueryDTO.getPageNum(), examQueryDTO.getPageSize());
list = userExamMapper.selectUserExamList(userId);
examCacheManager.refreshCache(examQueryDTO.getType(),userId);
long total = new PageInfo<>(list).getTotal();
return TableDataInfo.success(list, total);
}else{
//直接从redis中获取数据
list = examCacheManager.getExamVOList(examQueryDTO,userId);
listSize = examCacheManager.getListSize(examQueryDTO.getType(),userId);
return TableDataInfo.success(list, listSize);
}
}这样就没有问题了
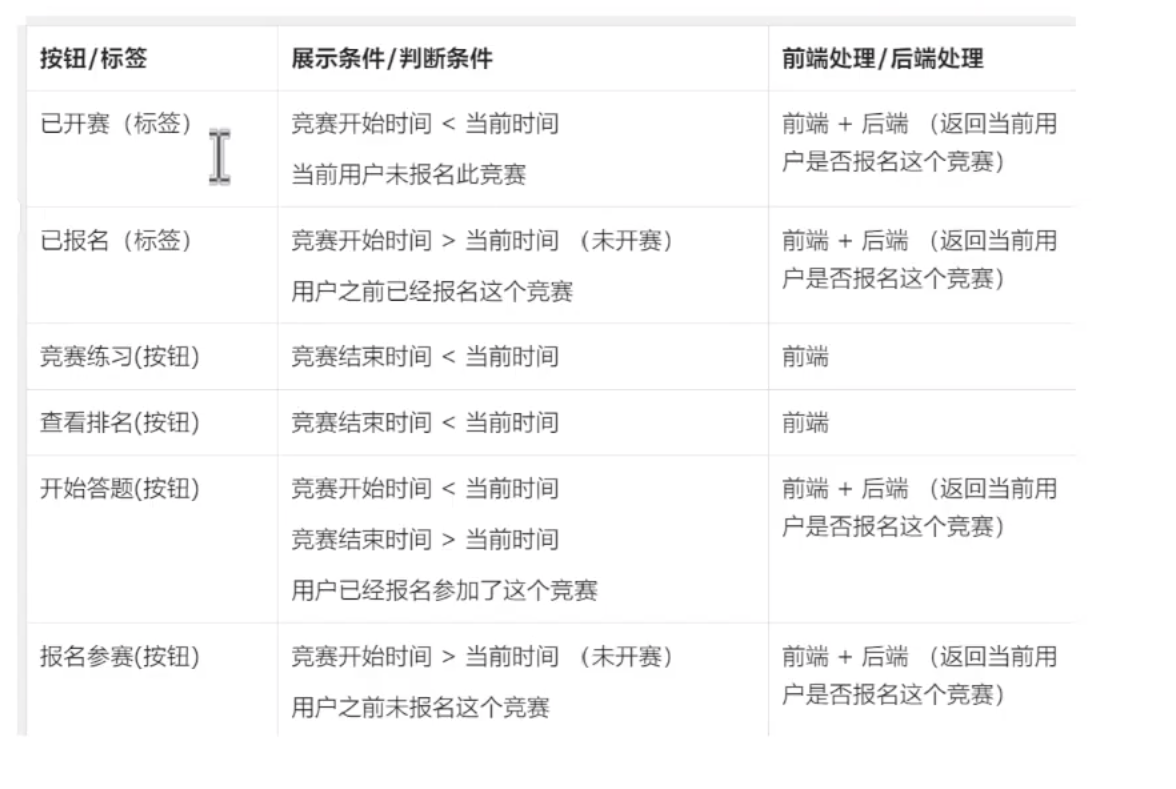
1.3 竞赛报名前端开发

竞赛开始前:没有报名显示未报名,已经报名显示已报名
竞赛开始后:没有报名显示已开赛,已经报名显示开始答题
所以我们要加上按钮
java
@Data
public class ExamVO {
@JsonSerialize(using = ToStringSerializer.class)
private Long examId;
private String title;
@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss")
private LocalDateTime startTime;
@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss")
private LocalDateTime endTime;
private boolean enter;//true表示已经报名,false表示没有报名
}开发之前我们要先完善后端,后端返回的examList要自带是否报名的字段
在ExamCacheManager中增加方法
java
public List<Long> getAllUserExam(Long userId) {
String detailKey = getDetailKey(userId);
List<Long> cacheListByRange = redisService.getCacheListByRange(detailKey, 0, -1, Long.class);
if(CollectionUtil.isNotEmpty(cacheListByRange)){
return cacheListByRange;
}
List<UserExam> userExams = userExamMapper.selectList(new LambdaQueryWrapper<UserExam>().eq(UserExam::getUserId, userId));
refreshCache(ExamListType.USER_EXAM_LIST.getValue(), userId);
if(CollectionUtil.isEmpty(userExams)){
return null;
}
return userExams.stream().map(UserExam::getExamId).toList();
}
java
@Override
public TableDataInfo redisList(ExamQueryDTO examQueryDTO) {
Long listSize = examCacheManager.getListSize(examQueryDTO.getType(),null);
List<ExamVO> list;
if(listSize==null||listSize==0){
//说明缓存中没有数据,所以要先从数据库中获取数据,然后存入redis
list = list(examQueryDTO);
examCacheManager.refreshCache(examQueryDTO.getType(),null);
listSize = new PageInfo<>(list).getTotal();
}else{
//直接从redis中获取数据
list = examCacheManager.getExamVOList(examQueryDTO,null);
listSize = examCacheManager.getListSize(examQueryDTO.getType(),null);
}
assembleEnterExamVoList(list);
return TableDataInfo.success(list, listSize);
}
private void assembleEnterExamVoList(List<ExamVO> list) {
Long userId = ThreadLocalUtil.get(Constants.USER_ID, Long.class);
List<Long> allUserExam = examCacheManager.getAllUserExam(userId);
if(CollectionUtil.isEmpty(allUserExam)){
return;
}
for(ExamVO examVO : list){
if(allUserExam.contains(examVO.getExamId())){
examVO.setEnter(true);
}
}
}这样就可以了
然后是前端开发
java
<div class="exam-button-container">
<span class="exam-hash-entry"
v-if="isOngoingAndUnregisteredCompetition(exam)">已开赛</span>
<span class="exam-hash-entry" v-if="isEntryAndNotStart(exam)">已报名</span>
<div v-if="isHistoryExam(exam)">
<el-button class="exam-practice-button" type="primary" plain
@click="goExam(exam)">竞赛练习</el-button>
<el-button class="exam-rank-button" type="primary" plain
@click="togglePopover(exam.examId)">查看排名</el-button>
</div>
<el-button class="exam-start-button" type="primary" plain v-if="isStartExam(exam)"
@click="goExam(exam)">开始答题</el-button>
<el-button class="exam-enter-button" type="primary" plain v-if="isCanEntry(exam)"
@click="enterExam(exam.examId)">报名参赛</el-button>
</div>给Exam.vue增加按钮
java
function isOngoingAndUnregisteredCompetition(exam) {
const now = new Date(); //当前时间
return new Date(exam.startTime) < now && new Date(exam.endTime) > now && !exam.enter
}
function isEntryAndNotStart(exam) {
const now = new Date();
return new Date(exam.startTime) > now && exam.enter
}
function isHistoryExam(exam) {
const now = new Date();
return new Date(exam.endTime) < now;
}
function isStartExam(exam) {
const now = new Date();
return new Date(exam.startTime) < now && new Date(exam.endTime) > now && exam.enter;
}
function isCanEntry(exam) {
const now = new Date();
return new Date(exam.startTime) > now && !exam.enter;
}
const isLogin = ref(false)
async function checkLogin() {
if (getToken()) {
await getUserInfoService()
isLogin.value = true
}
}然后是按钮是否显示的逻辑判断
然后是报名按钮
java
export function enterExamService(enterExamDTO) {
return service({
url: "/user/exam/enter",
method: "post",
data: enterExamDTO,
});
}
java
async function enterExam(examId) {
await checkLogin()
if (!isLogin.value) {
ElMessage.error('请先登录后报名参赛,谢谢')
return
}
const examDto = ref({
examId: examId
})
await enterExamService(examDto.value)
ElMessage.success('您已报名成功,请按时参赛',)
getExamList() //报名成功后刷新竞赛列表
}这样就成功了
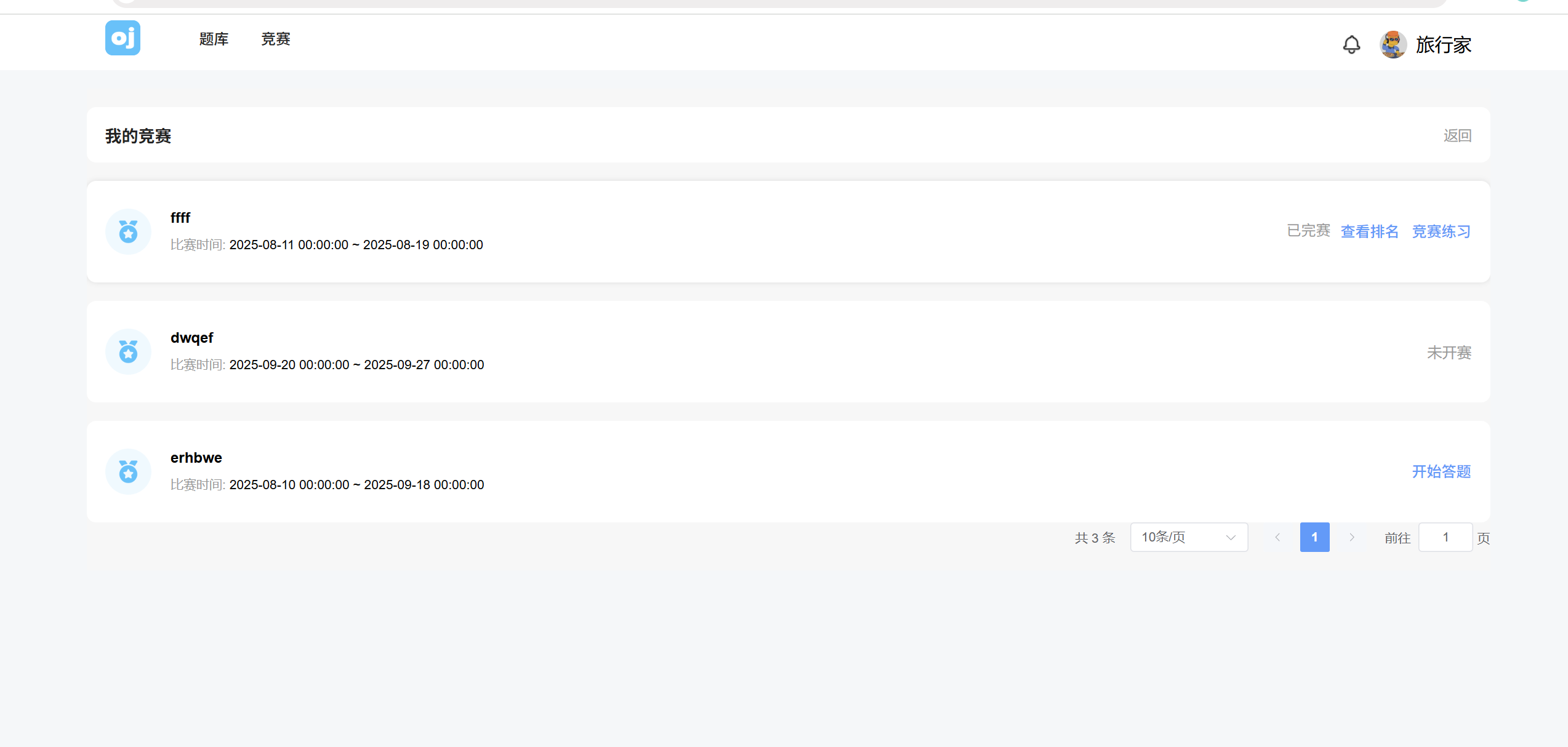
然后是我的竞赛列表页面
创建UserExam.vue
还有路由
java
function goMyExam(){
router.push("/c-oj/home/user/exam")
}然后是跳转按钮,这个跳转更新的是子页面
然后就是开发这个页面了
java
export function getMyExamListService(params) {
return service({
url: "/user/exam/list",
method: "get",
params,
});
}
java
<template>
<div class="my-exam-page">
<div class="exam-list-block">
<div class="exam-list-header">
<span class="ex-title">我的竞赛</span>
<span class="exam-list-back" @click="goBack">返回</span>
</div>
<div class="exam-list-content" v-for="(exam, index) in myExamList" :key="index">
<img src="@/assets/ide/jingsai.png" class="image" />
<div class="exam-content">
<div class="title">
{{ exam.title }}
</div>
<div class="date"><span>比赛时间:</span> {{ exam.startTime }} ~ {{ exam.endTime }}</div>
</div>
<div>
<div class="exam-end-lable-list" v-if="isHistoryExam(exam)">
<span class="exam-end-lable">已完赛</span>
<el-button class="exam-rank-lable" type="text" @click="togglePopover(exam.examId)">查看排名</el-button>
<el-button class="exam-rank-lable" type="text" @click="goHistoryExam(exam)">竞赛练习</el-button>
</div>
<div class="exam-status-lable exam-end-lable-list" v-else-if="isNotStart(exam)">未开赛</div>
<div class="exam-end-lable-list" v-else>
<el-button class="exam-rank-lable" type="text" plain @click="goExam(exam)">开始答题</el-button>
</div>
</div>
</div>
<div class="my-exam-pagination">
<!-- 增加分页展示器 -->
<el-pagination background layout="total, sizes, prev, pager, next, jumper" :total="total"
v-model:current-page="params.pageNum" v-model:page-size="params.pageSize" :page-sizes="[5, 10, 15, 20]"
@size-change="handleSizeChange" @current-change="handleCurrentChange" />
</div>
</div>
</div>
</template>
<script setup>
import { reactive, ref } from 'vue'
import {
getMyExamListService,
} from "@/apis/exam"
import router from '@/router'
const myExamList = ref([]) //消息列表
const total = ref(0)
const params = reactive({
pageNum: 1,
pageSize: 10,
})
// 分页
function handleSizeChange(newSize) {
params.pageNum = 1
getMyExamList()
}
function handleCurrentChange(newPage) {
getMyExamList()
}
//消息列表
async function getMyExamList() {
const ref = await getMyExamListService(params.value)
myExamList.value = ref.rows
total.value = ref.total
}
getMyExamList()
function isHistoryExam(exam) {
const now = new Date();
return new Date(exam.endTime) < now;
}
const isNotStart = (exam) => {
const now = new Date(); //当前时间
return new Date(exam.startTime) > now;
}
const goBack = () => {
router.go(-1)
}
</script>
<style lang="scss">
.my-exam-page {
max-width: 1520px;
margin: 0 auto;
background-color: rgba(247, 247, 247, 1);
position: relative;
overflow: hidden;
display: flex;
justify-content: center;
}
.exam-list-block {
width: 100%;
display: flex;
flex-wrap: wrap;
}
.exam-list-header {
background-color: rgba(255, 255, 255, 1);
border-radius: 10px;
width: 100%;
/* 设置宽度为100%以确保水平居中 */
height: 60px;
font-size: 25px;
text-indent: 20px;
display: flex;
align-items: center;
margin-top: 20px;
.ex-title {
font-family: PingFangSC, PingFang SC;
font-weight: 600;
font-size: 18px;
color: #222222;
}
.exam-list-back {
cursor: pointer;
color: #999999;
font-size: 15px;
margin-left: auto;
padding-right: 20px;
}
}
.exam-list-content {
height: 110px;
width: 100%;
background: #FFFFFF;
border-radius: 10px;
margin: 0 auto;
display: flex;
align-items: center;
margin-top: 20px;
justify-content: space-between;
cursor: pointer;
&:hover {
box-shadow: 0px 0px 6px 0px rgba(0, 0, 0, 0.1);
}
img {
width: 50px;
height: 50px;
margin: 0 20px;
}
}
.exam-list-content .exam-content {
max-width: calc(100% - 320px);
width: 100%;
}
.exam-list-content .title {
font-weight: bold;
font-size: 16px;
margin-bottom: 10px;
}
.exam-list-content .date {
font-weight: 400;
color: #000;
line-height: 20px;
margin-left: auto;
font-size: 14px;
span {
color: #999;
}
/* 将日期推至行尾 */
}
.exam-list-content .exam-status-lable {
color: #999999;
}
.exam-end-lable-list {
padding-right: 20px;
min-width: 228px;
text-align: right;
.exam-end-lable {
margin-right: 10px;
font-family: MicrosoftYaHei;
font-size: 16px;
color: #999999;
}
.exam-rank-lable {
font-size: 16px;
}
}
.my-exam-pagination {
width: 100%;
display: flex;
justify-content: flex-end;
padding-bottom: 20px;
}
</style>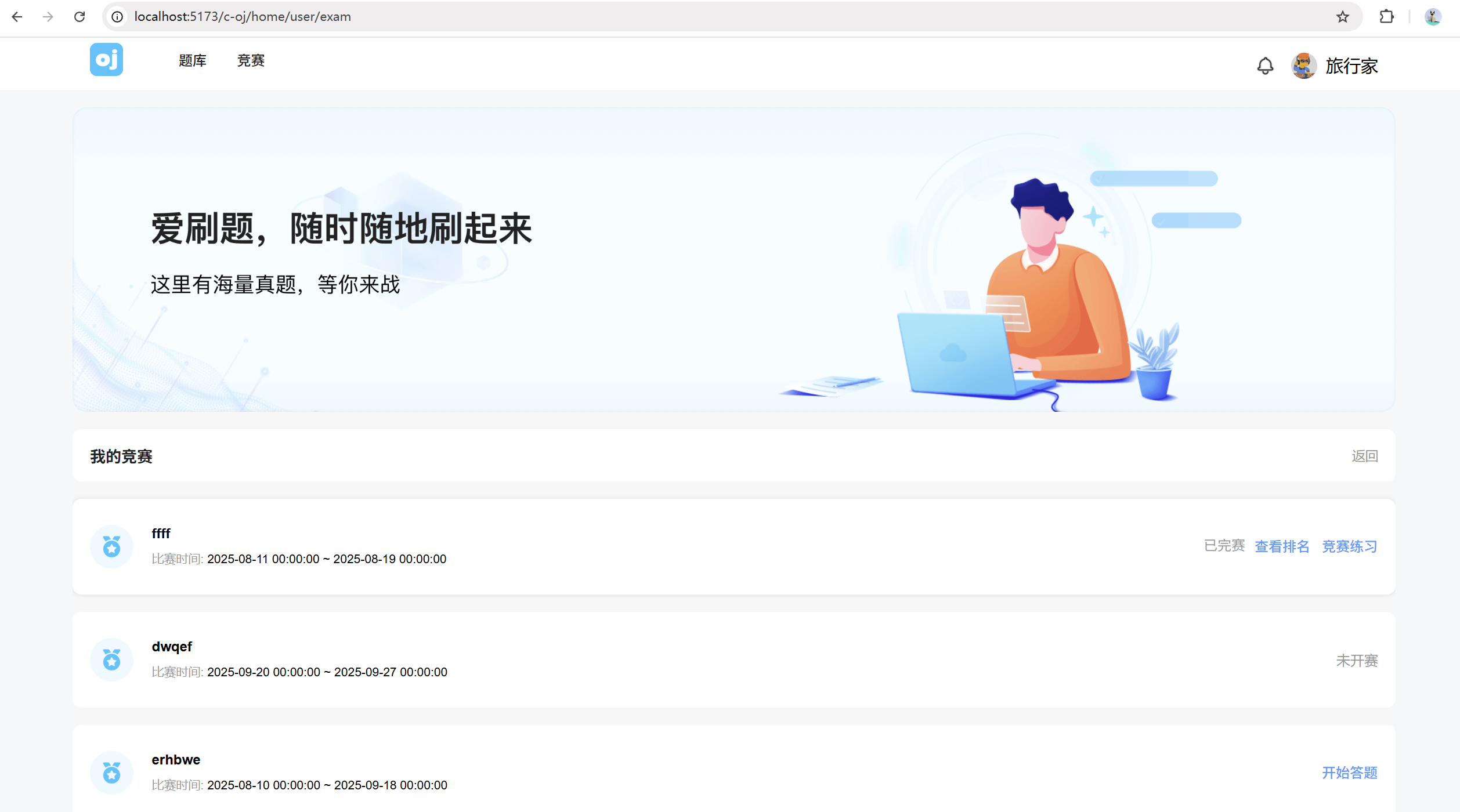
这样就可以了
但是我们这个我的竞赛页面不想显示页面的图片,该怎么做呢
可以给页面增加变量
java
{
path: '/c-oj/home',
name: 'home',
component: () => import('@/views/Home.vue'),
children: [
{
path: 'exam',
name: 'exam',
component: () => import('@/views/Exam.vue'),
meta: { showNavbar: true }
},
{
path: 'question',
name: 'question',
component: () => import('@/views/Question.vue'),
meta: { showNavbar: true }
},
{
path: 'user/exam',
name: 'userExam',
component: () => import('@/views/UserExam.vue'),
meta: { showNavbar: false}
}
]
},在Home页面中
java
<div v-if="$route.meta.showNavbar" >
<img src="@/assets/images/log-banner.png" class="banner-img">
</div>这样就可以了
2. 题目列表功能
先分析一下 redis
题目可以有一个list
key为question:list
value为questionId
然后是每个竞赛详细信息的redis存储
key为question:questionId
value为json详细信息
但是有一个问题,就是redis虽然支持分页搜索,但是不支持模糊搜索那种搜索
但是也可以拿出所有详细题目信息缓存,然后挨个进行模糊搜索--》拿出所有缓存就很性能差了,而且还有所有在遍历一次
第二个办法是把key改为要模糊搜索的字段,比如key含有标题这种要模糊查询的字段,但是中文做key吗,挺别扭的,而且这个办法也不好
业界的redis模糊查询我们用的是elasticSearch
2.1 elasticSearch基本知识
我们用的是8.5版本
ElasticSearch,简称ES(后⽂将直接使⽤这⼀简称),是⼀款卓越的开源分布式搜索引擎。其独特之处在于其近乎实时的数据检索能⼒,为⽤⼾提供了迅速、⾼效的信息查询体验。
ES解决什么问题
全⽂检索(全部字段)、模糊查询(搜索)、数据分析(提供分析语法,例如聚合)

倒排索引(Inverted Index)
倒排索引,也被称为反向索引或逆向索引,是⼀种索引数据的⽅法。与正排索引不同。倒排索引是按照⽂档中的词汇(关键词)来组织。也就是说在倒排索引中,索引的键是⽂档集合中出现过的每个独特词汇或关键词,索引的值是包含该关键词的所有⽂档的标识符(如⽂档ID),以及可选的额外信
息。
ES采取的是倒排索引
java
索引关键字 对应数据序号
⽩蛇 1,2,3,4
⼤战 2
告别 3,4
法海 2
⻘蛇 3
许仙 4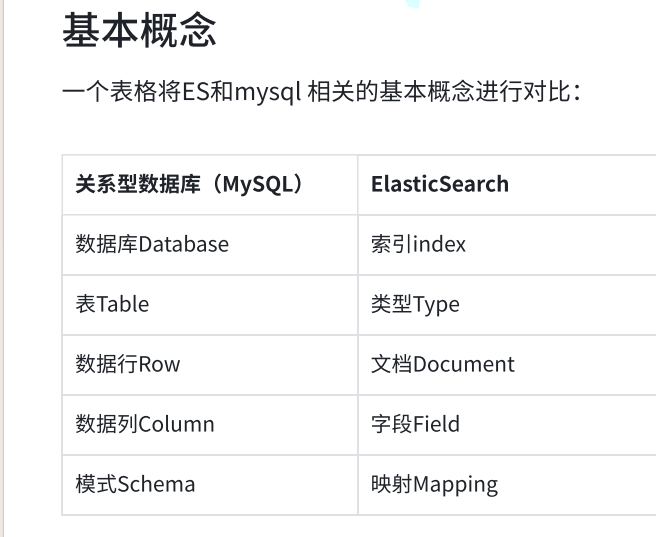
Index 索引
索引,具有相同结构的⽂档集合,类似于关系型数据库的数据库实例(6.0.0版本type废弃后,索引的概念下降到等同于数据库表的级别)。⼀个集群⾥可以定义多个索引,如客⼾信息索引、商品分类索引、商品索引、订单索引、评论索引等等,分别定义⾃⼰的数据结构。索引命名要求全部使⽤⼩写,建⽴索引、搜索、更新、删除操作都需要⽤到索引名称。
type 类型
类型,原本是在索引(Index)内进⾏的逻辑细分,但后来发现企业研发为了增强可阅读性和可维护性,制订的规范约束,同⼀个索引下很少还会再使⽤type进⾏逻辑拆分(如同⼀个索引下既有订单数据,⼜有评论数据),因⽽在6.0.0版本之后,此定义废弃
每个索引只有一中type类型,但是有很多个
Document ⽂档
⼀个⽂档是⼀个可被索引的基础信息单元,Document(⽂档)是JSON格式的,Document 就像是MySQL 中某个 Table ⾥⾯每⼀⾏的数据,Document中可以包含多个字段,每个字段可以是⽂本、数字、⽇期等类型
Field 字段:
字段是⽂档中的⼀个元素或属性,每个字段都有⼀个数据类型,如字符串、整数、⽇期等。
Mapping 映射
Mapping是ES中的⼀个很重要的内容,它类似于传统关系型数据中table的schema(定义了数据库中的数据如何组织,包括表的结构、字段的数据类型、键的设置(如主键、外键)等),⽤于定义⼀个索引的数据的结构(mapping中主要包括字段名、字段数据类型和字段索引类型。)。 在ES中,我们可以⼿动创建mapping,也可以采⽤默认创建⽅式。在默认配置下,ES可以根据插⼊的数据⾃动地创
建mapping。
2.2 elasticSearch使用
拉取es镜像:
java
docker pull elasticsearch:8.5.3创建⽹络
java
docker network create oj-network为什么要配置网络呢
因为Kibana要操作es,所以配置同一个网络的话,就可以链接了
输入docker network ls
就可以查看创建的网络oj-network了
启动es:
java
docker run -d --name oj-es-dev -e "ES_JAVA_OPTS=-Xms256m -Xmx256m" -e "discovery.type=single-node" -v D:\spring-project\ck-oj\deploy\dev\elasticSearch\es-plugins:/usr/share/elasticsearch/plugins -e "xpack.security.enabled=false" --privileged --network oj-network -p 9200:9200 -p 9300:9300 elasticsearch:8.5.3--network oj-network是配置的网络
-v D:\spring-project\ck-oj\deploy\dev\elasticSearch\es-plugins:/usr/share/elasticsearch/plugins是配置挂载卷,将容器映射到本地
----》这样在plugins新增插件就可以在本地操作了
-e "xpack.security.enabled=false"是关闭身份认证
-e "discovery.type=single-node"是单体模式
-e "ES_JAVA_OPTS=-Xms256m -Xmx256m"是配置最大和最小内存,防止es占完了
要先启动es,才能启动Kibana
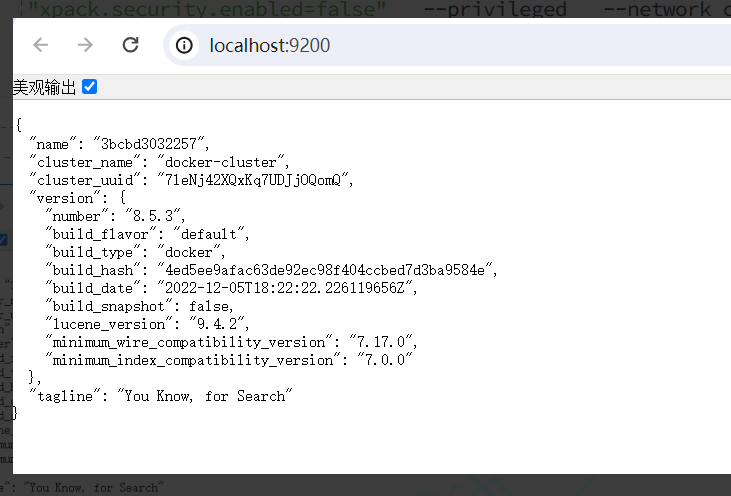
访问:http://localhost:9200/,验证启动成功。
2.2 Kibana
Kibana是ElasticSearch的数据可视化和实时分析的⼯具。通过Kibana,⽤⼾可以搜索、查看和与存储在Elasticsearch索引中的数据进⾏交互,执⾏⾼级数据分析,并通过各种图表、表格和地图将数据可视化。
就是ES的可视化工具
拉取kibana镜像
java
docker pull kibana:8.5.3与ES版本一样
启动kibana容器
java
docker run -d --name oj-kibana-dev -e "ELASTICSEARCH_HOSTS=http://oj-es-dev:9200" -e "I18N_LOCALE=zh-CN" -p15601:5601 --net=oj-network kibana:8.5.3-e "I18N_LOCALE=zh-CN"是配置中文页面
-e "ELASTICSEARCH_HOSTS=http://oj-esdev:9200"是配置es地址
访问:http://localhost:15601/,验证启动成功。
点击自己浏览
点击开发工具
左侧是命令,右侧是结果
3. es命令
3.1 PUT增加
java
PUT /employee/_doc/1
{
"first_name" : "John",
"last_name" : "Smith",
"age" : 25,
"about" : "I love to go rock climbing",
"interests": [ "sports", "music" ]
}
PUT /employee/_doc/2
{
"first_name" : "Jane",
"last_name" : "Smith",
"age" : 32,
"about" : "I like to collect rock albums",
"interests": [ "music" ]
}
PUT /employee/_doc/3
{
"first_name" : "Douglas",
"last_name" : "Fir",
"age" : 35,
"about": "I like to build cabinets",
"interests": [ "forestry" ]
}put就是增加的意思
PUT /employee/_doc/3的意思就是
先会增加一个employee索引,1表示新增第一条数据
employee:
表示索引名称(类似数据库中的 "表"),是存储文档的逻辑容器。
这里表示要操作的是名为 employee 的索引,如果该索引不存在,Elasticsearch 会自动创建它(基于默认配置)。
_doc:
表示文档类型(在 Elasticsearch 7.x 及以上版本中,这是默认且唯一的文档类型)。
历史上,一个索引可以有多个文档类型(类似表中的不同 "子表"),但 7.x 后已废弃多类型,统一使用 _doc 作为类型名。
它仅作为路径中的固定标识,无实际业务含义。
3:
表示文档 ID(类似数据库中的 "主键"),是当前文档的唯一标识。
通过这个 ID 可以精确操作该文档(如查询、修改、删除)。
如果省略 ID(如 PUT /employee/_doc),Elasticsearch 会自动生成一个随机字符串作为 ID。
向 employee 索引中,添加或更新 ID 为 3 的文档(如果 ID 为 3 的文档已存在,则会覆盖更新;不存在则创建)。
3.2 GET查询
java
GET /employee/_search该请求默认会查询 employee 索引下的所有文档(类似 SQL 的 SELECT * FROM employee),返回的结果会包含匹配的文档列表、总命中数、排序结果等元数据。
_search:Elasticsearch 的搜索专用端点,表示对前面指定的 employee 索引执行 "搜索 / 查询" 操作。
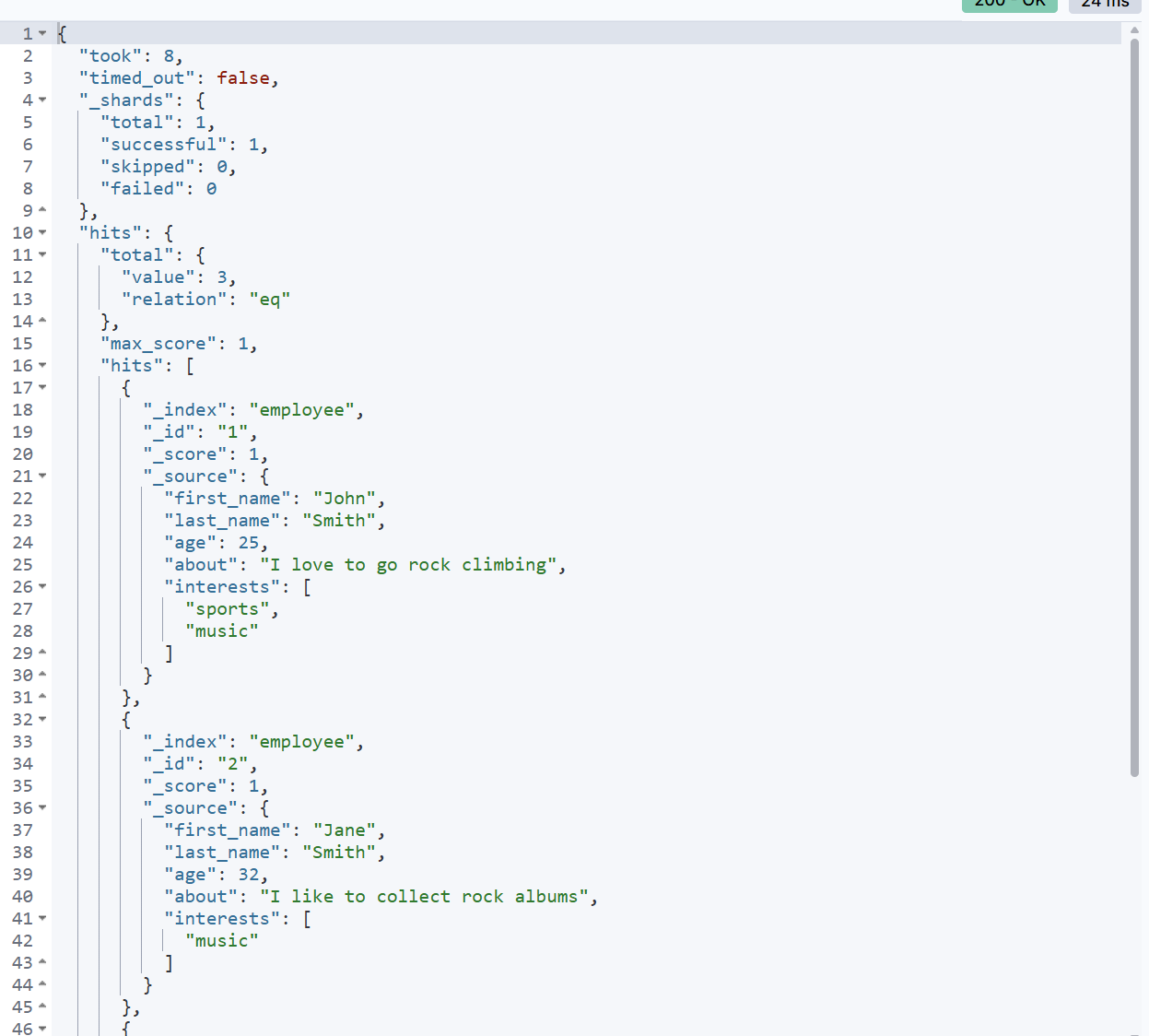
这样就成功了
java
GET /employee/_doc/3这个表示查询id为3的文档
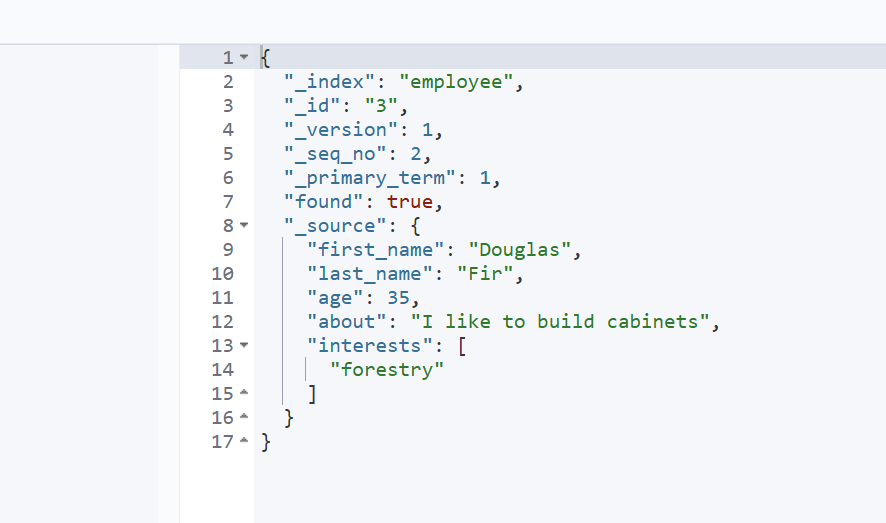
3.3 DELETE删除
java
DELETE /employee/_doc/3删除指定数据
java
DELETE /employee直接删除索引
3.4 POST修改
java
POST /employee/_update/3
{
"doc" : {
"last_name" : "mark"
}
}这个就是修改第三条数据的last_name字段
3.5 分词器
根据前⾯学习的倒排索引的概念。倒排索引是按照⽂档中的词汇(关键词)来组织的,索引的键是⽂档集合中出现过的每个独特词汇或关键词。那es是怎么将这些关键词提取出来的呢?这其实就是es中的分词器在起着作⽤,它负责将⽂本切分成⼀个个有意义的词语,以建⽴索引或进⾏搜索和分析。
我们的业务中通常使⽤的是中⽂分词,es的中⽂分词默认会将中⽂词每个字看成⼀个词⽐如:"我想吃⾁夹馍"会被分为"我","想","吃","⾁" ,"夹","馍" 这显然是不太符
合⽤⼾的使⽤习惯,所以我们需要安装中⽂分词器ik,来讲中⽂内容分解成更加符合⽤⼾使⽤的关键
字。
java
GET _analyze
{
"text": "我想吃⾁夹馍"
}这个代码的意思就是对我想吃⾁夹馍进分词
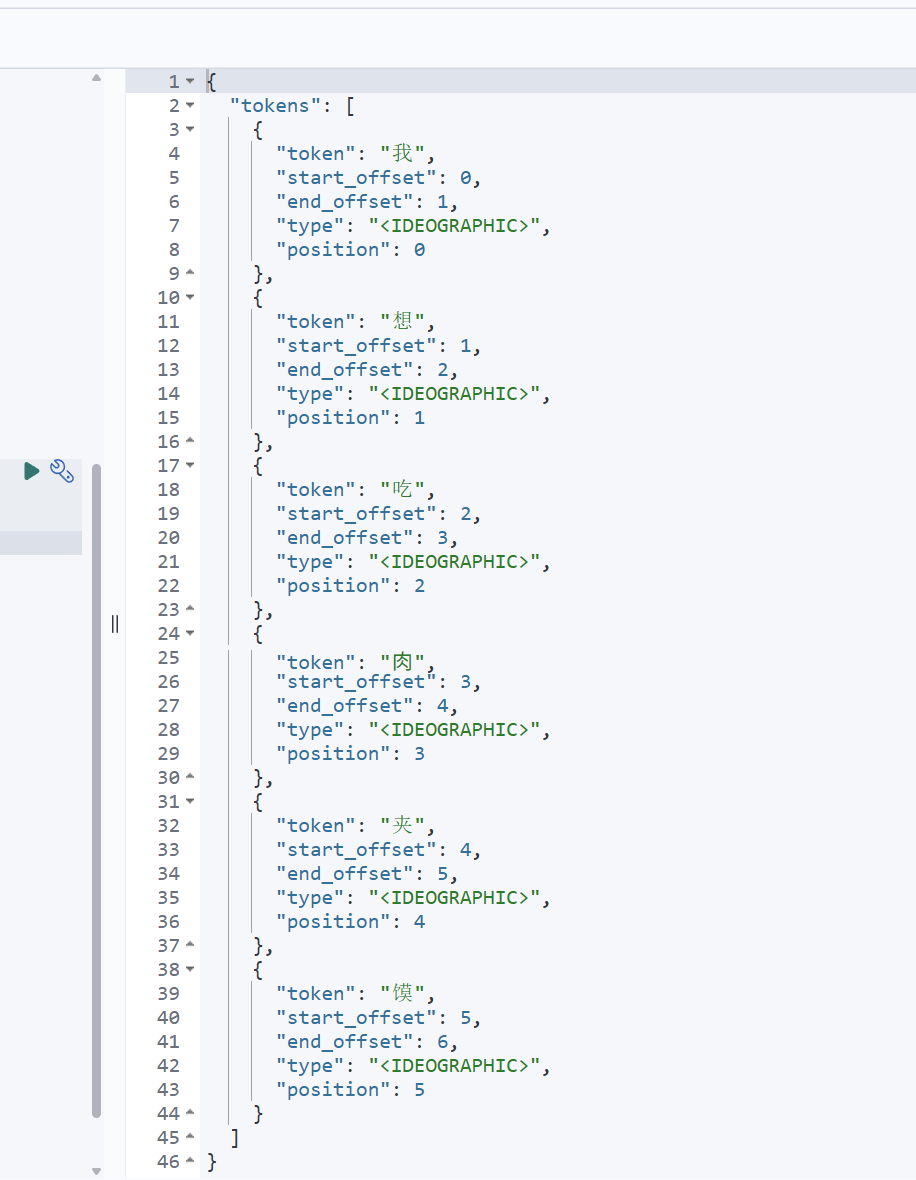
我们发现确实对中文就只能一个一个分词
3.6 安装ik分词器
下载到D:\spring-project\ck-oj\deploy\dev\elasticSearch\es-plugins这个目录
就是绑定卷的目录,就是映射的那个目录
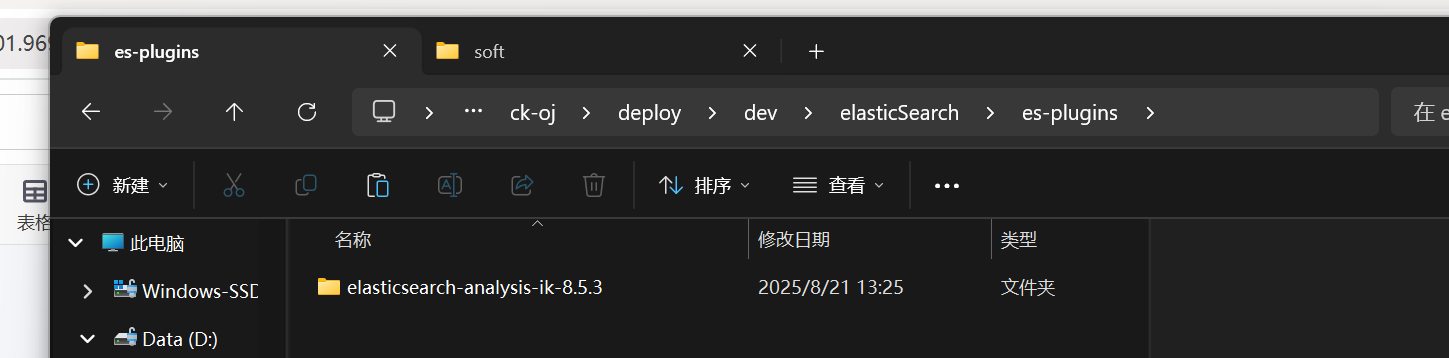
这样就可以了
如果版本不是8.5.3,那么就要改文件名为8.5.3
然后是plugin-descriptor.properties里面要改版本为8.5.3
java
version=8.5.3
elasticsearch.version=8.5.3然后是重启es容器
java
GET _cat/plugins这个命令就可以知道我们安装的插件了
3.7 分词模式
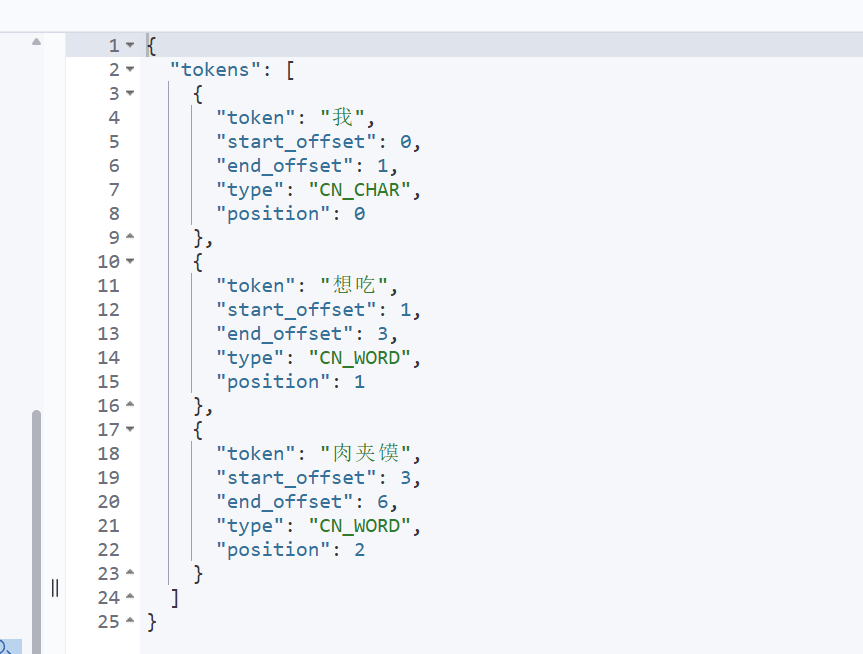
ik分词器提供了两种分词模式:ik_smart 和 ik_max_word,其中 ik_smart 模式会尽量保持⻓词,尽可能地保留词语的完整性,提⾼搜索的准确性,⽽ ik_max_word 模式则会尽可能多地切分出词汇。
java
GET _analyze
{
"text": "我想吃肉夹馍",
"analyzer": "ik_smart"
}这个就是指定ik分词器的什么分词模式了
java
GET _analyze
{
"text": "我想吃⾁夹馍",
"analyzer": "ik_max_word"
}
3.8 项目引入
先创建一个公共包oj-common-elasticSearch
java
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>这个包是空的,什么代码都没写,万一后面会写代码呢,而且这是一个组件,所以我们要低耦合
然后是es配置
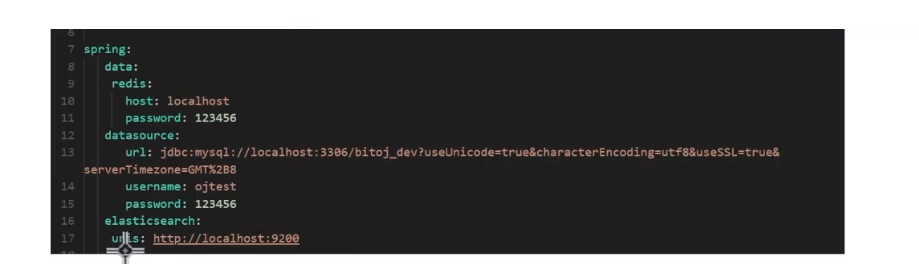
直接在friend下引入oj-common-elasticSearch,然后配置