温馨提示:
本篇文章已同步至"AI专题精讲 " SEW-D:语音识别中无监督预训练的性能与效率权衡
摘要
本文研究了自动语音识别(ASR)中预训练模型的性能与效率权衡。我们聚焦于wav2vec 2.0,并形式化了几种影响模型性能和效率的架构设计。通过整合我们的所有观察,我们提出了SEW(Squeezed and Efficient Wav2vec),一种在性能和效率两个维度上均有显著改进的预训练模型架构,适用于多种训练设置。例如,在LibriSpeech的100小时-960小时半监督设置下,SEW与wav2vec 2.0相比,推理速度提升了1.9倍,并且词错误率(WER)相对降低了13.5%。在相似的推理时间下,SEW在不同模型大小下将词错误率降低了25%-50%。
1. 引言
最近,自监督预训练使用未标注的音频数据来学习多功能特征表示的研究受到了显著关注,随后这些表示会在特定任务的标注音频上进行微调(Zhang et al., 2020b;Wang et al., 2021b;Xu et al., 2020a;Pepino et al., 2021)。这一趋势与自然语言处理(NLP;Devlin et al., 2018;Liu et al., 2019;He et al., 2020)和计算机视觉(CV;He et al., 2019;Chen et al., 2020;Grill et al., 2020)中的发展类似。或许这一类模型中最具代表性的例子就是wav2vec 2.0(W2V2;Baevski et al., 2020b),该模型在仅使用10分钟的转录(标注)数据进行微调后,便能实现具有竞争力的词错误率(WER),而传统的监督方法通常需要近千小时的标注数据。如果最近在NLP和CV领域的进展能为我们提供任何启示,那么这种在专家任务上微调的预训练音频模型的重要性只会进一步增加。事实上,W2V2已经被广泛研究,重点关注了预训练数据的影响(Conneau et al., 2020;Hsu et al., 2021)、预训练任务(Hsu et al., 2020)或与伪标签相结合的效果(Xu et al., 2020a;Zhang et al., 2020b)。
在本文中,我们研究了W2V2模型的设计及其各个组成部分之间可能存在的权衡。我们的重点是提高实际应用中的效率,而不是扩展模型。随着W2V2类型模型的广泛应用,理解其效率的权衡对于将其从实验室应用到现实世界至关重要,因为在实际应用中,任何效率的提高都能显著减少推理成本和能源消耗。
我们研究了W2V2模型的多个方面。我们的研究重点是自动语音识别(ASR),同时保持标准的预训练和少量样本微调设置。首先,我们研究了网络的时间分辨率如何在性能和效率之间进行权衡,并展示了在计算预训练表示和ASR解码时使用不同分辨率可以显著减少推理时间,同时保持相似的性能。其次,我们提出了一种高效的波形特征提取器家族,该提取器在推理时间上为原始W2V2提取器的两倍的情况下,能够实现相似的性能。最后,我们研究了在网络的不同部分之间转移模型表达能力的影响。我们观察到,将更多参数分配给预训练网络的后期部分,比在输入波形附近增加容量更为有效。我们还发现,增加预训练预测头的表现能力能够提高性能,同时不会影响下游任务的计算,因为这些预测头在后续步骤中会被丢弃。
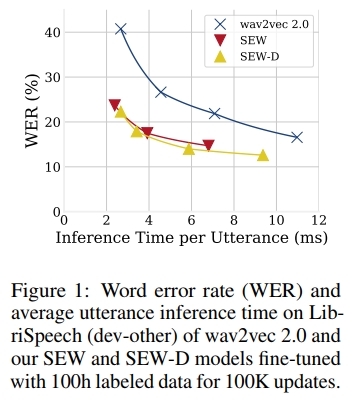
我们结合了这些观察,提出了两种模型:SEW(Squeezed and Efficient Wav2vec)和SEW-D(具有解耦注意力的SEW)。我们在LibriSpeech数据集(Panayotov et al., 2015)上的960小时未标注音频上预训练SEW和SEW-D,并在多个ASR任务上进行微调。SEW在性能效率权衡上显著优于原始的W2V2。例如,在100小时标注数据的情况下,相比于W2V2-tiny模型,SEW将LibriSpeech test-clean WER从22.8%降至10.6%,并且推理速度略快,甚至超越了一个更大的W2V2模型,其WER为12.8%。与官方W2V2-large发布版相比,我们的最佳SEW-D-base+在推理和预训练方面分别实现了2.7倍和3.2倍的速度提升,同时使用了一半的参数,且WER相当。与W2V2-base相比,我们的SEW-D-mid在推理速度上提升了1.9倍,WER相对减少了13.5%。图1展示了不同模型大小下的性能效率权衡。SEW-D在大多数预训练设置下超越了W2V2,我们在LibriSpeech(Panayotov et al., 2015)、Ted-lium 3(Hernandez et al., 2018)、VoxPopuli(Wang et al., 2021a)和Switchboard(Godfrey and Holliman, 1993)数据集上进行实验时,均得到了优异的结果。预训练模型和代码可在https://github.com/asappresearch/sew获取。
2 相关工作
无监督音频表示学习
对比预测编码(CPC)是一种通用的无监督学习方法,适用于语音、视觉、文本和强化学习(van den Oord et al., 2018)。在语音领域应用时,它利用过去的音频来预测未来的音频,类似于语言建模(Mikolov et al., 2010; Dauphin et al., 2017; Kaplan et al., 2020),但采用对比损失。Wav2vec(Schneider et al., 2019)进一步改进了CPC模型架构设计,重点研究了用于端到端自动语音识别(ASR)的无监督预训练。大致来说,wav2vec包含一个特征提取器,它从原始波形音频中生成一系列向量,以及一个上下文网络,它通过编码近期的特征来预测即将到来的特征。这个上下文网络仅用于学习有用的特征表示,通常在预训练后被丢弃。最近,Baevski et al.(2020a)引入了vq-wav2vec,并将vq-wav2vec与一个类似BERT的离散模型(Devlin et al., 2019; Baevski et al., 2019)结合。W2V2(Baevski et al., 2020b)将vq-wav2vec与BERT-like模型结合,形成一个端到端的设置,其中BERT部分作为上下文网络,但不会被丢弃。更近期,Hsu et al.(2020)提出了HuBERT,并展示了W2V2可以使用聚类目标而不是对比目标进行预训练。除了专注于ASR的研究外,其他语音任务(Synnaeve and Dupoux, 2016; Chung et al., 2018; Chuang et al., 2019; Song et al., 2019)、音乐(Yang et al., 2021; Zhao and Guo, 2021)和通用音频(Saeed et al., 2021; Gong et al., 2021; Niizumi et al., 2021; Wang et al., 2021c)等领域也有着广泛的兴趣。
端到端自动语音识别(ASR)
随着大规模数据集和高速计算的出现,端到端ASR模型(Amodei et al., 2016; Zhang et al., 2020b)逐渐实现了最先进的结果,超越了HMM-DNN混合系统(Abdel-Hamid et al., 2012; Hinton et al., 2012)。端到端ASR模型大致可以分为三种主要类型:连接时序分类(CTC;Graves et al., 2013)、RNN变换器(RNN-T;Graves, 2012; Han et al., 2020; Gulati et al., 2020)和序列到序列(即Listen, Attend and Spell模型)(Seq2seq;Chan et al., 2016; Dong et al., 2018; Watanabe et al., 2018)。CTC模型在批量解码时非常快速;RNN-T变种常用于实时系统;Seq2seq模型则更常见于离线设置。最近,随着NLP任务上的成功,语音处理逐渐转向Transformer架构(Vaswani et al., 2017; Dong et al., 2018)及其变种(Zhang et al., 2020a; Baevski et al., 2020b; Gulati et al., 2020; Zhang et al., 2020b; Yeh et al., 2019)。
3 技术背景:Wav2vec 2.0(W2V2)
W2V2由一个波形特征提取器和一个上下文网络组成。波形特征提取器生成一系列连续的特征向量,每个特征向量编码音频的一个小片段,而上下文网络则将这些特征向量映射为上下文依赖的表示。在预训练过程中,部分特征会被遮蔽(masked),这些被遮蔽的特征不会被上下文网络看到。与此同时,未遮蔽的特征会被离散化,并作为预测目标。上下文网络的目标是通过InfoNCE损失函数(van den Oord et al., 2018)在负样本池中区分出被遮蔽位置的离散化特征版本。
图2展示了W2V2的框架,包括: (a) 特征提取器, (b) 上下文网络, © 可选的量化模块, (d) 两个投影头。
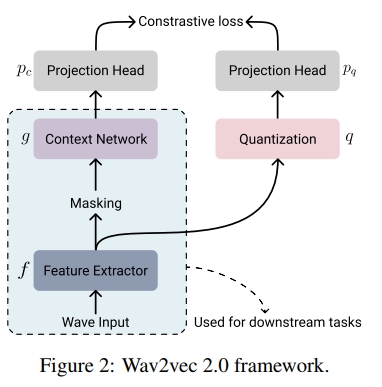
波形特征提取器 (WFE)
波形特征提取器 f ( ⋅ ) f(\cdot) f(⋅) 将原始波形音频输入 X = ( x 1 , . . . , x T input ) ∈ R T input × d input X = (x_1, ..., x_{T_{\text{input}}}) \in \mathbb{R}^{T_{\text{input}} \times d_{\text{input}}} X=(x1,...,xTinput)∈RTinput×dinput (其中 d input = 1 d_{\text{input}} = 1 dinput=1 对于单通道音频)编码并降采样为一组特征向量 Z = f ( X ) = ( z 1 , . . . , z T ) ∈ R T × d feat Z = f(X) = (z_1, ..., z_T) \in \mathbb{R}^{T \times d_{\text{feat}}} Z=f(X)=(z1,...,zT)∈RT×dfeat。
例如,W2V2将16kHz的音频序列映射到50Hz的帧,通过使用一个卷积波形特征提取器(WFE),该提取器的感受野大小为400,步幅为320。每个特征向量编码的是25ms( 1000 16000 × 400 \frac{1000}{16000} \times 400 160001000×400)窗口内的原始信号,步幅大小为20ms( 1000 16000 × 320 \frac{1000}{16000} \times 320 160001000×320)。因此,减少后的序列长度为 T = T input − 400 320 + 1 = T input − 80 320 T = \frac{T_{\text{input}} - 400}{320} + 1 = \frac{T_{\text{input}} - 80}{320} T=320Tinput−400+1=320Tinput−80。
上下文网络
上下文网络 g ( ⋅ ) g(\cdot) g(⋅) 遵循与自然语言处理中的掩码语言模型(如BERT(Devlin et al., 2018)或RoBERTa(Liu et al., 2019))类似的原理。在预训练期间,每个 z t z_t zt 被掩码并以可训练的掩码向量 m m m 替代,替代的概率为预定义的 p p p。例如, Z = ( z 1 , z 2 , z 3 , z 4 , z 5 , z 6 , ... , z T ) \mathbf{Z} = (z_1, z_2, z_3, z_4, z_5, z_6, \dots, z_T) Z=(z1,z2,z3,z4,z5,z6,...,zT) 可以变为 Z ′ = ( z 1 , m , m , z 4 , m , z 6 , ... , z T ) \mathbf{Z'} = (z_1, m, m, z_4, m, z_6, \dots, z_T) Z′=(z1,m,m,z4,m,z6,...,zT)。上下文网络将这个掩码序列映射到一系列上下文表示 C = g ( Z ′ ) = ( c 1 , ... , c T ) ∈ R T × d feat \mathbf{C} = g(\mathbf{Z'}) = ( \mathbf{c}_1, \dots, \mathbf{c}T ) \in \mathbb{R}^{T \times d{\text{feat}}} C=g(Z′)=(c1,...,cT)∈RT×dfeat,以融入上下文信息。即使 z_t 被掩码并替换为 m m m,我们也预期 c t \mathbf{c}_t ct 能够恢复 z t z_t zt 中的信息,因为它包含了周围未被掩码的输入向量的信息。上下文网络通常使用Transformer架构来实现(Vaswani et al., 2017; Gulati et al., 2020)。
量化模块
量化模块 q ( ⋅ ) q(\cdot) q(⋅) 将每个未被掩码的向量 z t z_t zt 映射为量化形式 q t = q ( z t ) ∈ R d feat \mathbf{q}t = q(\mathbf{z}t) \in \mathbb{R}^{d{\text{feat}}} qt=q(zt)∈Rdfeat,针对每个掩码位置 t t t 进行处理。量化后的 q t tiny s \mathbf{q}t^{\text{~tiny~s}} qt tiny s 作为预测目标。量化模块基于Gumbel Softmax与直通估计器(Gumbel Softmax, Jang et al., 2016; Maddison et al., 2014)。有 G G G 个字典,每个字典有 V 个条目,总共有 G × V G \times V G×V 个向量 e g , v ∈ R d feat G \mathbf{e}{g,v} \in \mathbb{R}^{\frac{d{\text{feat}}}{G}} eg,v∈RGdfeat,其中 g ∈ { 1 , ... , G } g \in \{1, \dots, G\} g∈{1,...,G}, v ∈ { 1 , ... , V } v \in \{1, \dots, V\} v∈{1,...,V}。对于每个组 g g g,将 z t z_t zt 分配给第 v v v-th 条目的概率为:
p g , v = exp ( W v g ⋅ z t / τ Q ) ∑ v ′ = 1 V exp ( W v ′ g ⋅ z t / τ Q ) p_{g,v} = \frac{\exp(W_v^g \cdot z_t / \tau_Q)}{\sum_{v' = 1}^{V} \exp(W_{v'}^g \cdot z_t / \tau_Q)} pg,v=∑v′=1Vexp(Wv′g⋅zt/τQ)exp(Wvg⋅zt/τQ)
其中 W\^g \\in \\mathbb{R}\^{V \\times d_{\\text{feat}}} 是可训练的矩阵, τ Q \tau_Q τQ 是量化温度。对于每个组 g g g,将 z t z_t zt 分配给 v g ∗ v_{g}^{*} vg∗-th 条目,其中:
v g ∗ = arg max v p g , v v_g^{*} = \arg \max_v p_{g,v} vg∗=argvmaxpg,v
相应的嵌入向量 ( e 1 , v 1 ∗ , ... , e G , v G ∗ ) (\mathbf{e}{1, v_1^*}, \dots, \mathbf{e}{G, v_G^*}) (e1,v1∗,...,eG,vG∗) 被连接成一个向量 q t ∈ R d feat \mathbf{q}t \in \mathbb{R}^{d{\text{feat}}} qt∈Rdfeat,并构成一个量化特征序列 Q = ( q 1 , ... , q T ) ∈ R T × d feat \mathbf{Q} = (\mathbf{q}_1, \dots, \mathbf{q}T) \in \mathbb{R}^{T \times d{\text{feat}}} Q=(q1,...,qT)∈RT×dfeat。
投影头
两个线性投影头 p c ( ⋅ ) p_c(\cdot) pc(⋅) 和 p q ( ⋅ ) p_q(\cdot) pq(⋅) 用于降低 C \mathbf{C} C 和 Q \mathbf{Q} Q 的维度。对于一个掩码并替换为 m m m 的 c t \mathbf{c}_t ct,我们希望 p c ( c t ) ∈ R d proj p_c(\mathbf{c}t) \in \mathbb{R}^{d{\text{proj}}} pc(ct)∈Rdproj 和 p q ( q t ) ∈ R d proj p_q(\mathbf{q}t) \in \mathbb{R}^{d{\text{proj}}} pq(qt)∈Rdproj 相似。Baevski et al.(2020b)在其原始符号中并未区分 p c p_c pc 和 g g g 或 p_q 和 q q q,但我们保持这些区分,因为它们在不同的作用下工作,并且在下游微调之前被丢弃。
预训练目标
W2V2在预训练损失中结合了对比损失和多样性损失:
L = L m + α L d ( 1 ) \mathcal { L } = \mathcal { L } _ { m } + \alpha \mathcal { L } _ { d }\quad(1) L=Lm+αLd(1)
温馨提示:
阅读全文请访问"AI深语解构 " SEW-D:语音识别中无监督预训练的性能与效率权衡