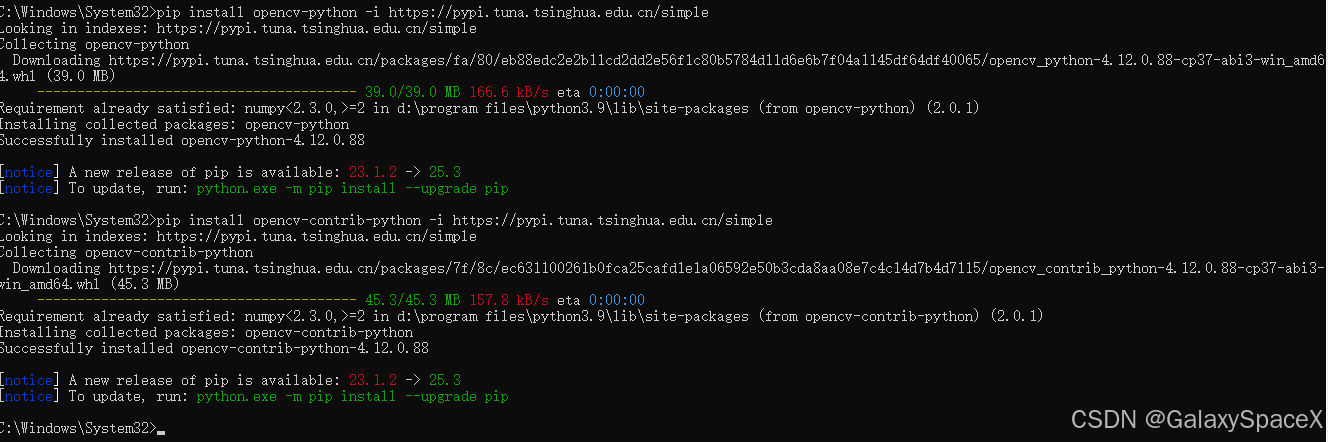
OpenCV安装:
pip install opencv-python -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install opencv-contrib-python -i https://pypi.tuna.tsinghua.edu.cn/simple执行安装对应的模块
判断是否安装成功:
import cv2
print(cv2.__version__)出现如下则证明安装成功

YOLOv11安装:
pip install ultralytics -i https://pypi.tuna.tsinghua.edu.cn/simple安装成功后去官网下载如下数据集:
python
https://github.com/ultralytics/ultralytics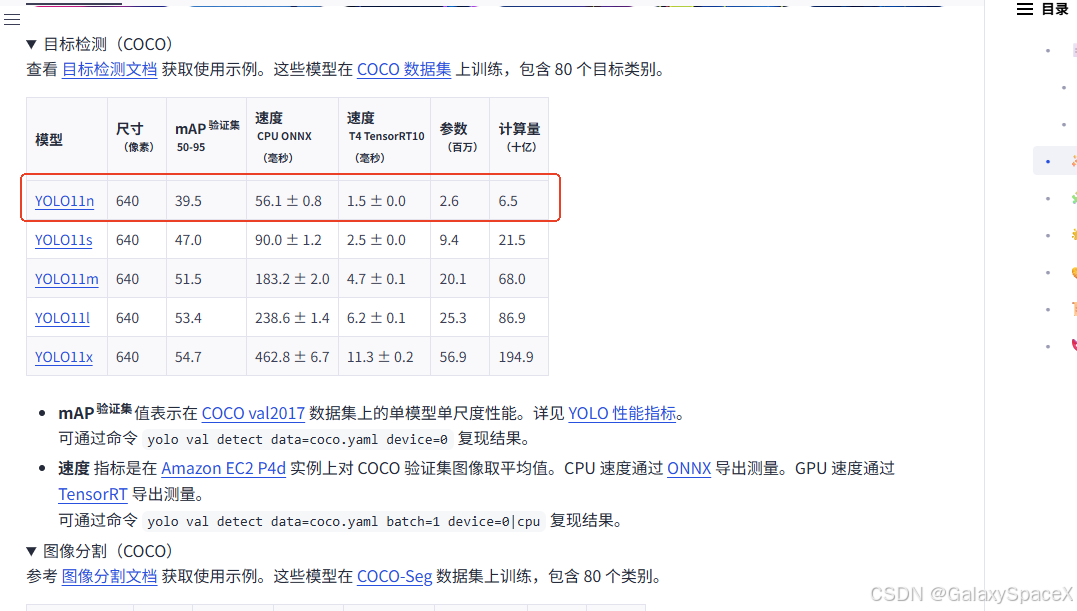
对应的数据集的区别,按照需求选择对应模型:
| Variant | 含义 / 规模 | 优缺点 / 适用场景 |
|---|---|---|
| YOLO11n ("nano" / 最轻量) | 最小模型 --- 参数量最少、计算量最小。 Ultralytics Docs+2mygit.top+2 | 推理最快、资源消耗最低,适合边缘设备、实时推理、计算资源受限的场景,但精度/检测能力相对较低。 wiki.walnutpi.com+1 |
| YOLO11s ("small" / 小型) | 比 nano 稍大,性能 + 精度都有所提升。 mygit.top+1 | 仍然保持较好速度,同时精度比 nano 高,在轻量级应用/嵌入式/资源受限环境中是性价比高的折中。 wiki.walnutpi.com+1 |
| YOLO11m ("medium" / 中型) | 中等规模 --- 参数量/计算量中等。 mygit.top+1 | 速度与精度比较平衡,适合通用目标检测场景。许多任务在速度/精度之间取得较好平衡。 interface.cqpub.co.jp+1 |
| YOLO11l ("large" / 大型) | 较大模型 --- 参数量和计算量都较高。 mygit.top+1 | 精度更好,适合对准确率要求较高、对资源/算力要求不严格的场景,比如服务器端推理、批量处理、高精度检测等。 wiki.walnutpi.com+1 |
| YOLO11x ("extra-large" / 超大型) | 最大模型 --- 参数量最多,计算量最大。 mygit.top+1 | 精度最高,但推理速度最慢、需要较大计算资源;适合对识别准确率要求极高的场景(例如工业检测、复杂图像分析、高精度任务)。 |
然后使用如下图进行识别:

对应的识别代码如下:
python
# cv_yolo11_draw.py
import cv2
from ultralytics import YOLO
# 1. 加载模型(任选其一)
model = YOLO("yolo11n.pt") # ① 官方 COCO 80 类
# model = YOLO("runs/train/exp/weights/best.pt") # ② 自己训练的权重
# 2. 读入照片
img = cv2.imread("road.jpg")
# 3. 推理 + 标注
results = model(img, conf=0.35) # conf 控制置信度阈值
annotated = results[0].plot() # 返回画好框的 ndarray(BGR)
# 4. 保存结果
cv2.imwrite("annotated.jpg", annotated)
print("已保存标注结果 -> annotated.jpg")执行完毕后对应的标注如下,可以正常的识别:

换一个图片不标注,仅判断是否出现对应的物体,这里判断是否存在汽车
python
from ultralytics import YOLO
import cv2
# 加载官方权重(自带 COCO 80 类)
model = YOLO('yolo11n.pt')
img = cv2.imread("school.jpg")
# 推理图片
results = model(img, conf=0.35) # conf 控制置信度阈值
cls_list = results[0].boxes.cls.cpu().numpy().astype(int)
if 2 in cls_list: # 2 是 COCO 的 car
print('汽车')存在汽车则会输出,不存在则未识别到汽车,不输出

LabelStudio安装使用:
| 维度 | LabelImg | LabelStudio |
|---|---|---|
| 上手速度 | pip 安装即开,Qt 界面 0 配置 | 需 pip install label-studio 并启动 Web 服务,首次要建项目 |
| 数据类型 | 仅静态图像 | 图像、视频、文本、音频、时间序列多模态 |
| 标注形状 | 矩形框 | 矩形、多边形、关键点、语义分割、OCR 行等 20+ 类型 |
| 输出格式 | Pascal VOC、YOLO、CreateML | 20+ 格式+自定义模板,一键导出 COCO、YOLO、JSON |
| 协作&权限 | 无(单机) | 多用户、角色、任务分发、版本控制 |
| AI 辅助 | 无 | 内置模型预标注、主动学习、人工再修正 |
| 维护状态 | 2025 年起已停止独立维护,社区仅修 bug | 活跃开发,每月迭代,官方主推 |
| 体积&资源 | <30 MB,老爷机流畅 | 需本地起 Web 服务,大项目建议 Docker |
python
pip install label-studio -i https://pypi.tuna.tsinghua.edu.cn/simple启动Label Studio:
python
label-studio start运行后会打开网页
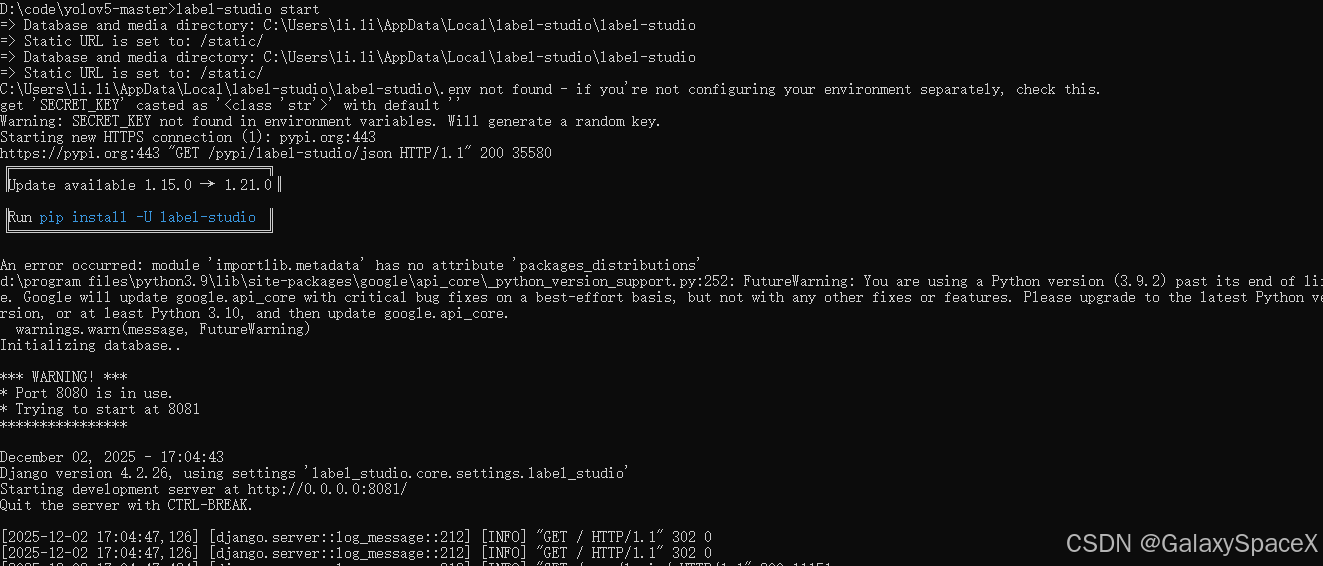
注册账号并输入登陆:
创建项目
创建成功后上传文件
然后点击Labeling Setup,这里选择关键点标注,可以根据实际情况选择
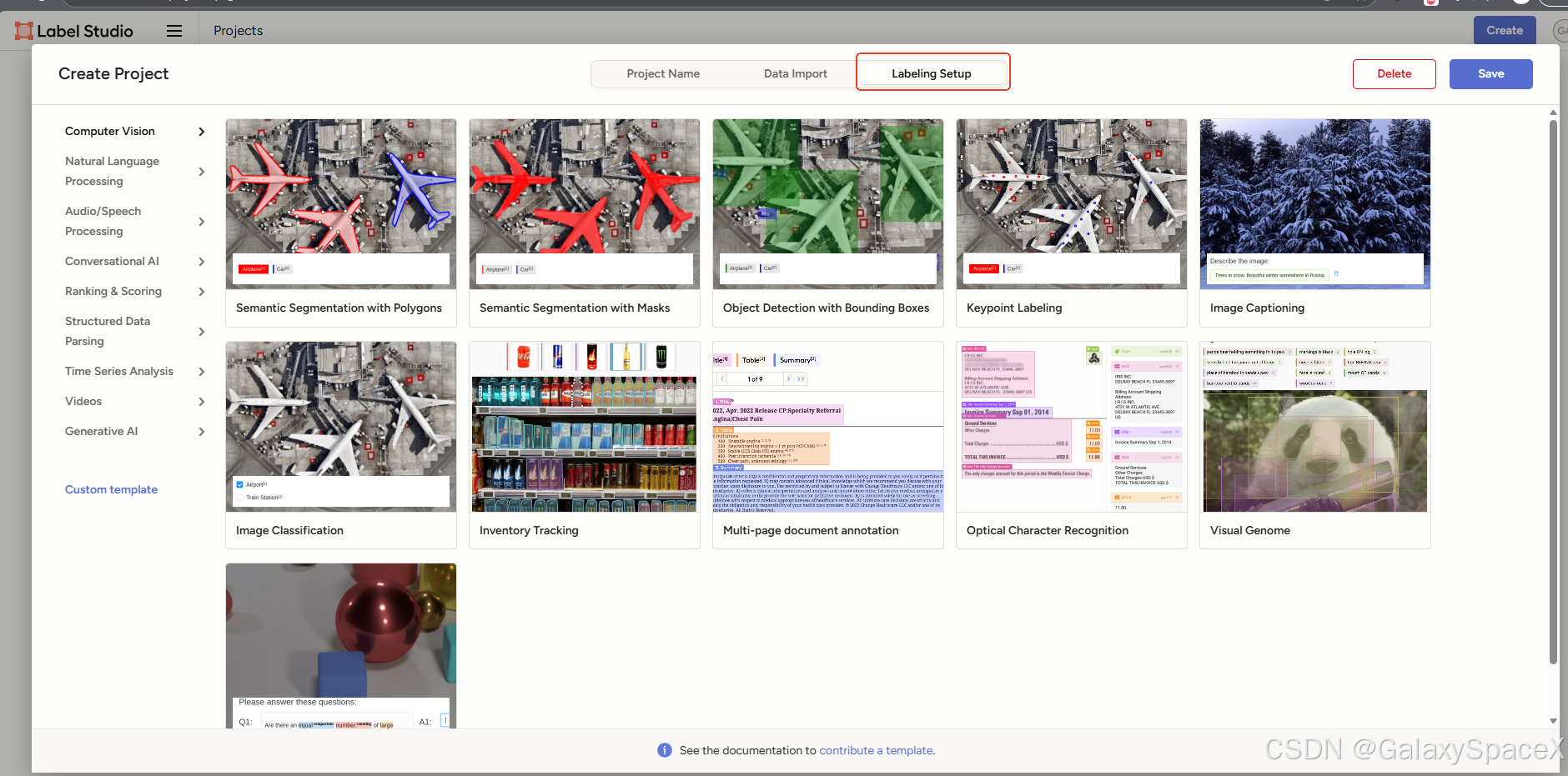
选择后删除之前的标签,新建标签:
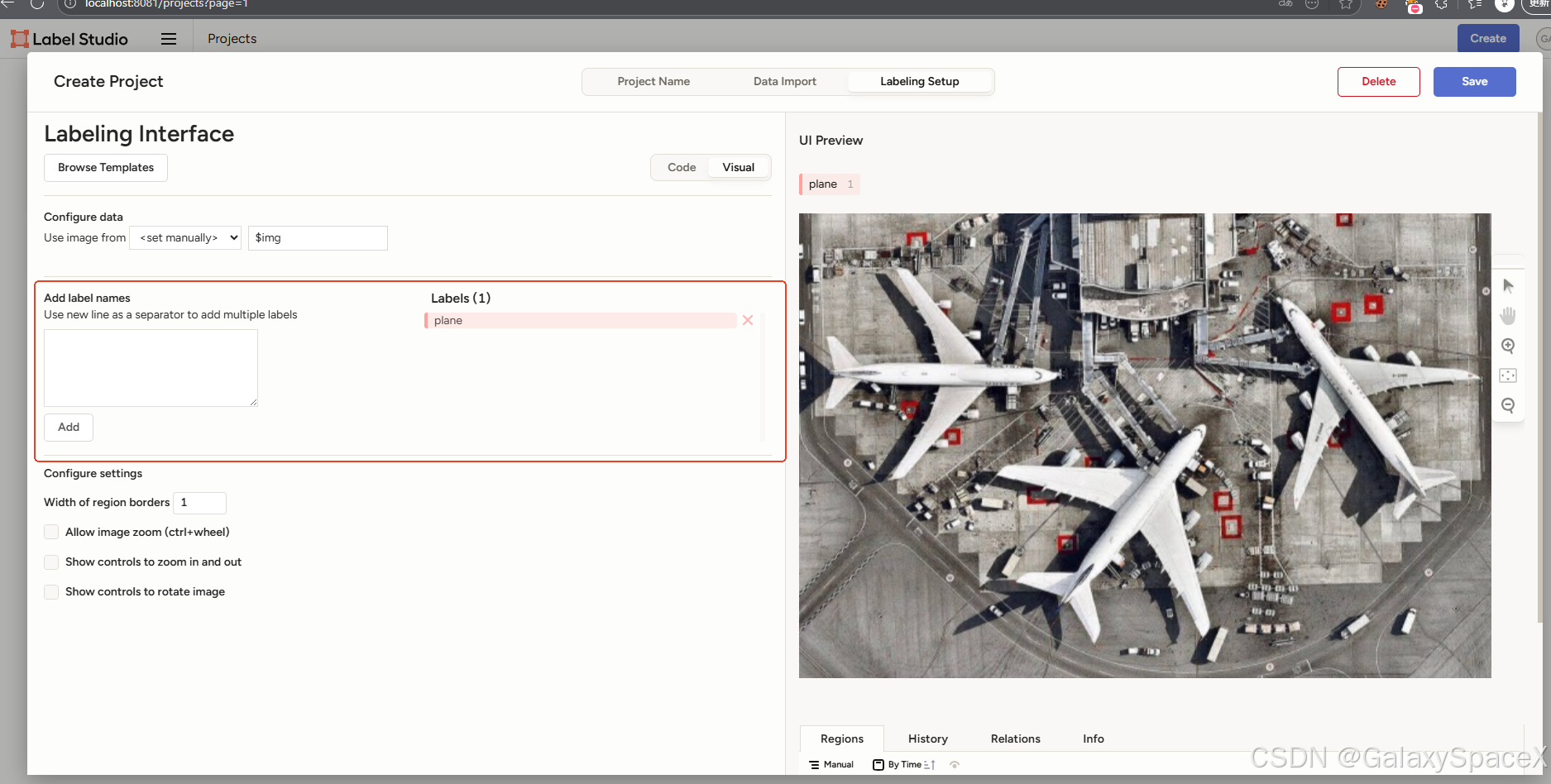
保存后可以进行标注,标注要先选择标签,然后再图中进行选择,右下角会出现标注的信息
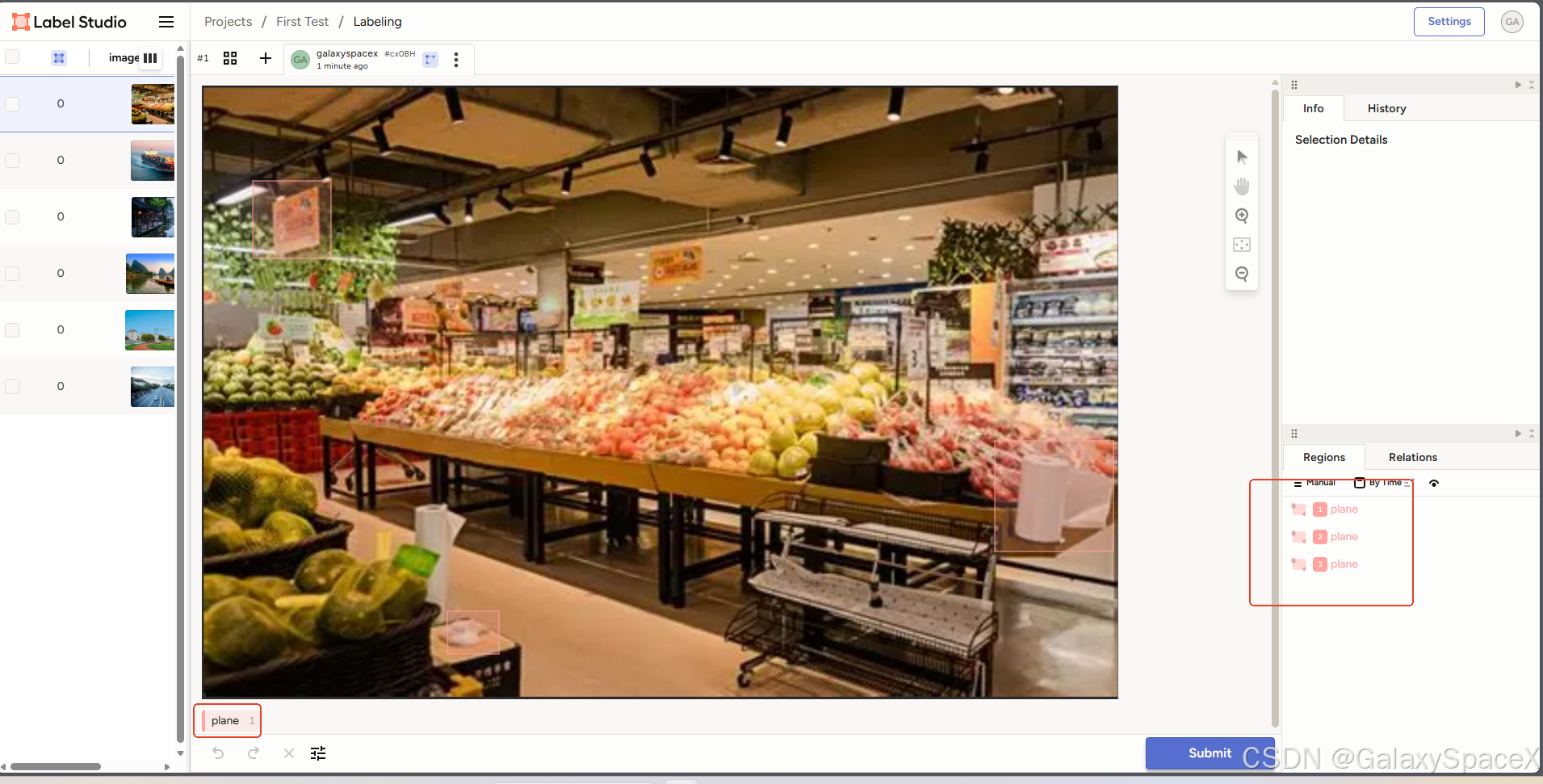
标记完成后使用导出功能进行导出
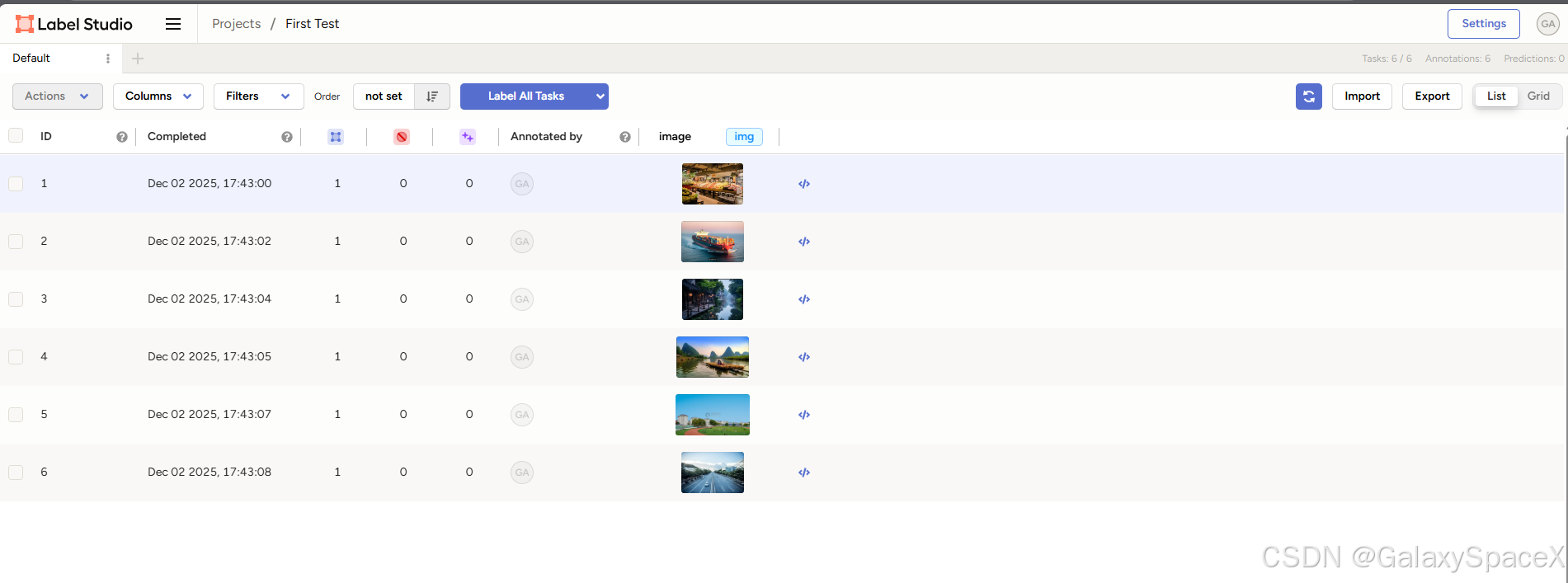
导出选择YOLO格式
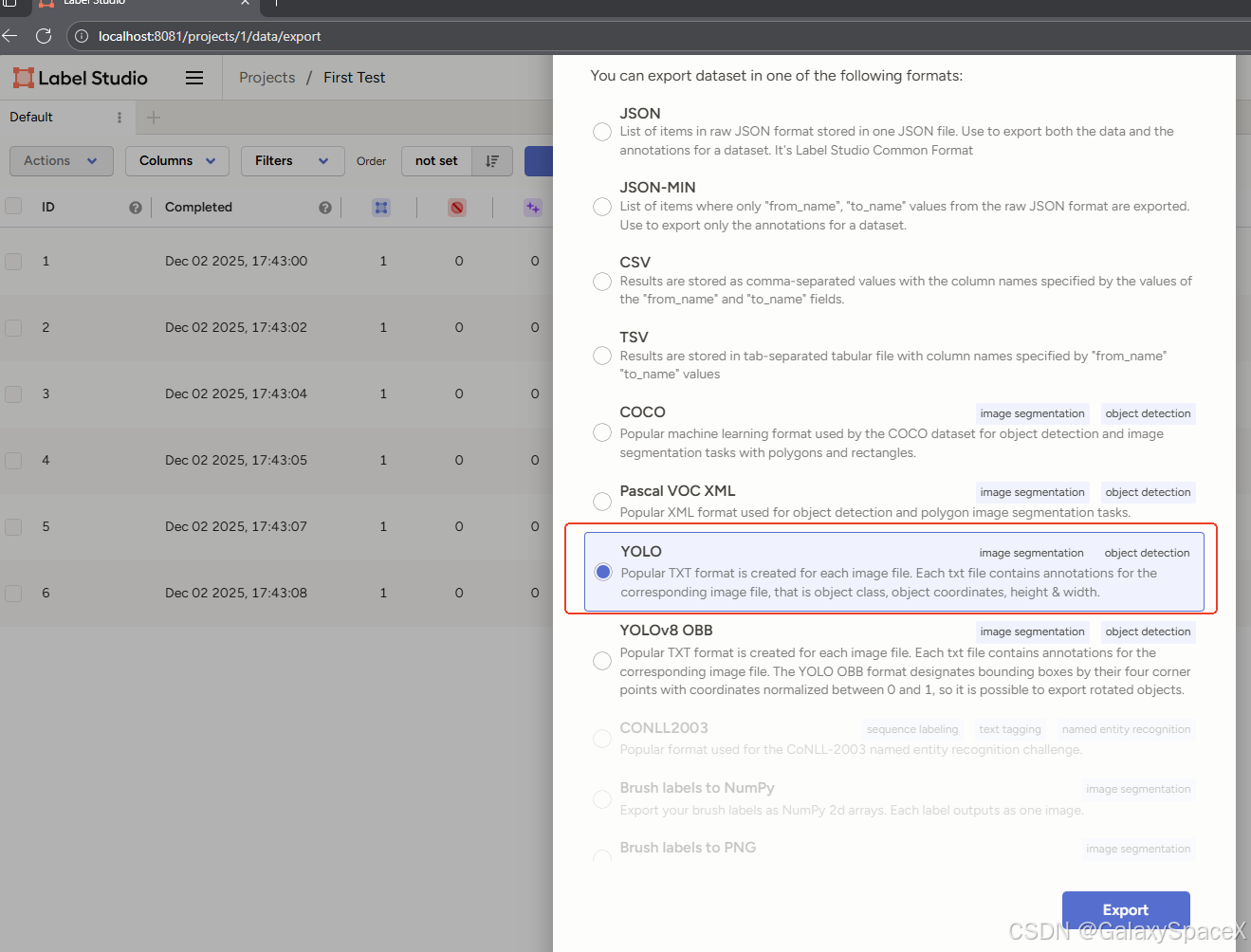
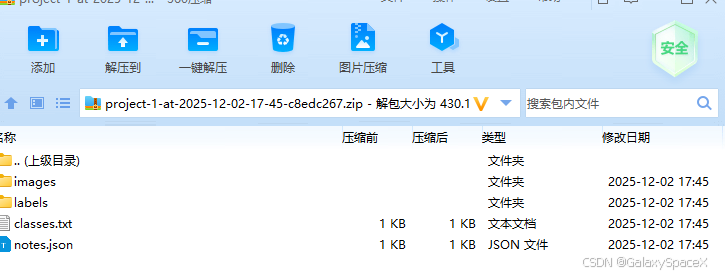
得到如下文件
训练:
首先必须按 YOLO 要求对文件进行划分
1.images 里所有图片分成 train / val(比例 8:2)
2.labels 里的 txt 按同样名字分到 train/val
即变成如下格式:
dataset/
│── images/
│ ├── train/
│ └── val/
│── labels/
│ ├── train/
│ └── val/
│── classes.txt
│── data.yaml
使用如下代码进行自动创建
python
import os
import random
import shutil
# 设置路径
images_dir = "dataset/images"
labels_dir = "dataset/labels"
# 输出目录
train_imgs = "dataset/images/train"
val_imgs = "dataset/images/val"
train_lbls = "dataset/labels/train"
val_lbls = "dataset/labels/val"
for d in [train_imgs, val_imgs, train_lbls, val_lbls]:
os.makedirs(d, exist_ok=True)
# 所有图像文件
files = [f for f in os.listdir(images_dir) if f.endswith((".jpg", ".png", ".jpeg"))]
# 按比例划分
random.shuffle(files)
val_ratio = 0.2
val_count = int(len(files) * val_ratio)
val_set = files[:val_count]
train_set = files[val_count:]
# 开始移动文件
def move_files(file_list, img_target, lbl_target):
for f in file_list:
shutil.copy(os.path.join(images_dir, f), os.path.join(img_target, f))
label_name = f.rsplit(".", 1)[0] + ".txt"
shutil.copy(os.path.join(labels_dir, label_name), os.path.join(lbl_target, label_name))
move_files(train_set, train_imgs, train_lbls)
move_files(val_set, val_imgs, val_lbls)
print("Done! Train:", len(train_set), " Val:", len(val_set))执行完成后可以看到目录下创建了train和val文件,并按照8:2的比例划分
然后创建data.yaml,这个值按照classes.txt来创建
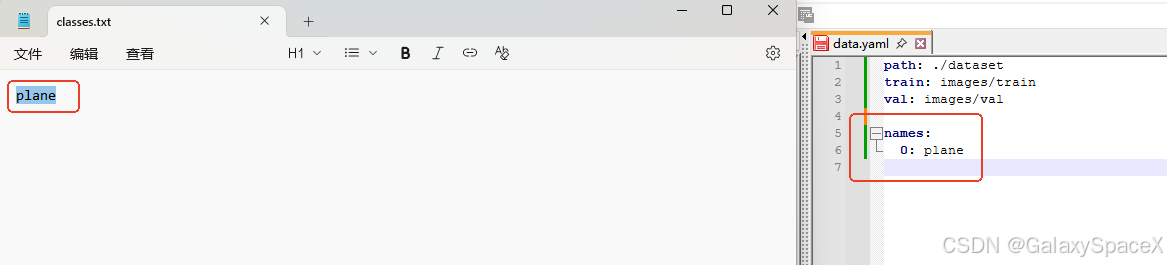
确定下按照的yolo版本

可以使用如下命令进行更新
python
pip install -U ultralytics -i https://pypi.tuna.tsinghua.edu.cn/simple如果使用的 ultralytics 库版本 >= 8.3.0,则 YOLOv8 命令实际上已经兼容 YOLO11
Ultralytics 从 8.3 开始内部统一框架,虽然命令还是 yolo,但支持 YOLO11 系列模型
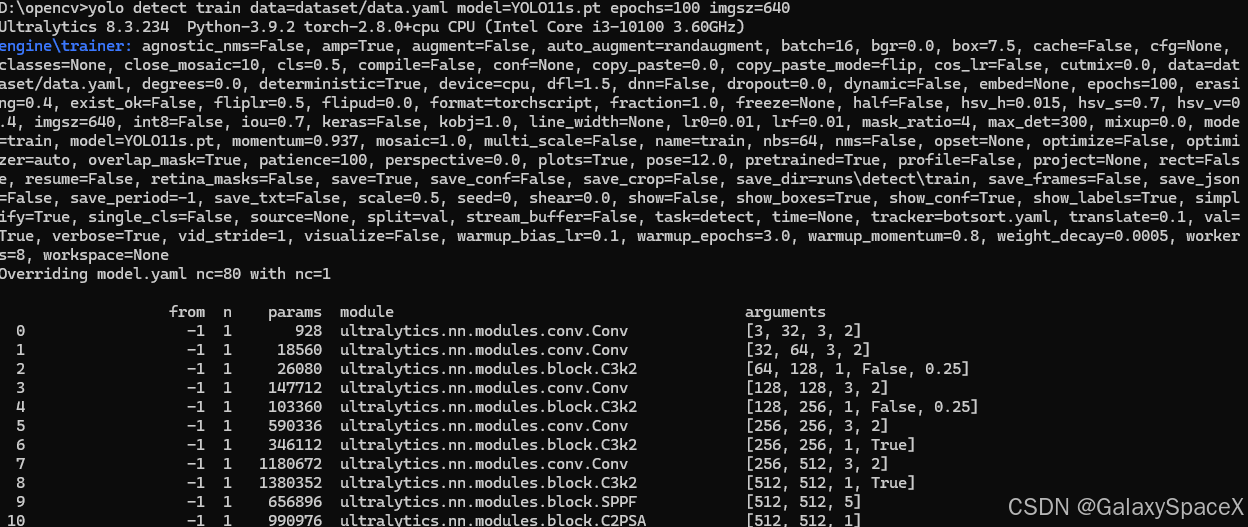
然后使用如下命令进行训练:
python
yolo detect train data=dataset/data.yaml model=YOLO11s.pt epochs=100 imgsz=640可以看到,开始训练:
训练完成后可以看到如下文件
runs/detect/train/
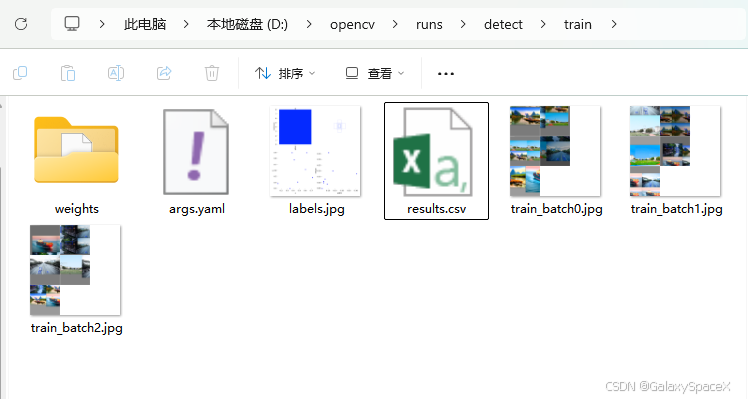
最终模型权重在weights中:

以后所有推理/部署,都用 best.pt 即可。
| 文件名 | 用途 |
|---|---|
| best.pt | 验证集表现最好的模型 → 部署用它 |
| last.pt | 最后一个 epoch 的模型 |
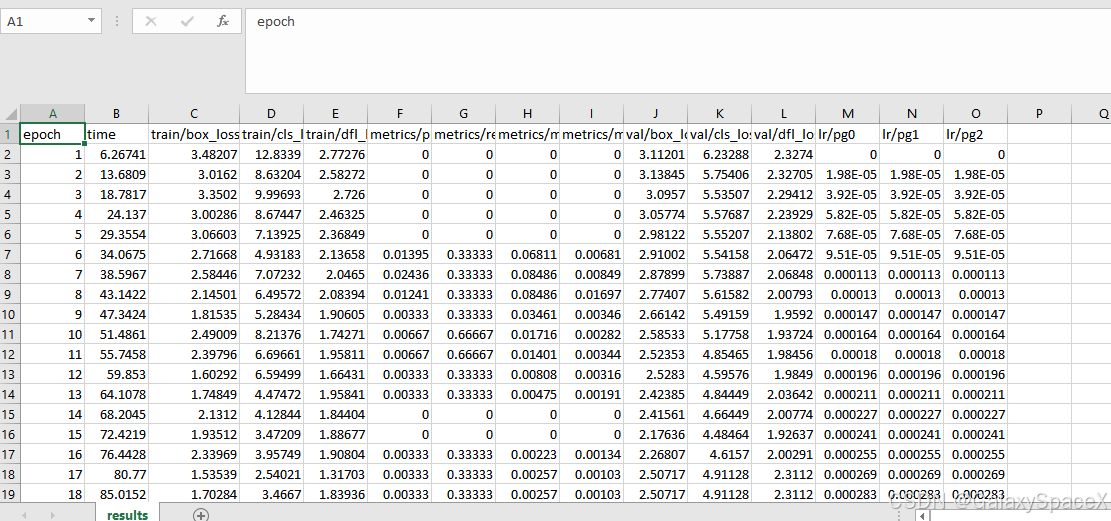
runs/detect/train/results.csv 训练日志
| 指标 | 描述 |
|---|---|
| loss_box | 边框损失 |
| loss_cls | 分类损失 |
| precision | 精确率 |
| recall | 召回率 |
| mAP50 | IoU=0.5 的平均精度 |
| mAP50-95 | 综合精度 |
可以查看对应的训练日志
总结如下:
| 文件 | 用途 |
|---|---|
| best.pt | 你真正要用于部署和推理的模型 |
| results.png | 判断模型是否收敛 |
| results.csv | 训练数据曲线 |
| val_batch*.jpg | 验证集效果 |
| hyp.yaml / args.yaml | 参数备份 |
利用我们训练好的数据可以进行图像识别,命令如下:
python
yolo detect predict model=runs/detect/train/weights/best.pt source=your_image.jpg
yolo detect predict model=best.pt source=dataset/images/test
输出预测图片到:runs/detect/predict/同样我们可以使用代码调用:
图片识别:
python
from ultralytics import YOLO
model = YOLO("best.pt")
results = model("image.jpg")
results[0].show()视频流(摄像头):
python
from ultralytics import YOLO
model = YOLO("best.pt")
model.predict(source=0, show=True)另外可以使用YOLO导出模型到不同的平台,可以进行对应的二次开发
python
yolo export model=best.pt format=onnx
yolo export model=best.pt format=torchscript
yolo export model=best.pt format=engine # TensorRT
yolo export model=best.pt format=coreml # iPhone
yolo export model=best.pt format=pb # TF SavedModel
yolo export model=best.pt format=tflite # Android| 格式 | 可用于 |
|---|---|
| ONNX | C++, C#, Java, Go,或 Nvidia AI 框架 |
| TensorRT (.engine) | Jetson Nano / Orin / CUDA GPU 加速部署 |
| CoreML (.mlpackage) | iOS App |
| TFLite (.tflite) | Android 手机 / Edge TPU |
| TorchScript | 纯 PyTorch 部署 |
视觉系统:
OpenCV = 视觉处理基础能力
YOLOv11 = AI识别能力
两者结合 = 完整的智能视觉系统
摄像头实时检测代码:
python
from ultralytics import YOLO
import cv2
# ① 加载YOLOv11模型(替换成你的best.pt)
model = YOLO("best.pt") # 官方模型可改成 'yolo11n.pt' 或 'yolo11s.pt'
# ② 打开摄像头(0 = 默认摄像头)
cap = cv2.VideoCapture(0)
# 设置摄像头分辨率(可选)
cap.set(3, 1280) # width
cap.set(4, 720) # height
while True:
ret, frame = cap.read()
if not ret:
print("无法读取摄像头")
break
# ③ YOLO 推理
results = model(frame, imgsz=640, conf=0.5)
# ④ 将检测结果绘制到画面上
annotated_frame = results[0].plot() # YOLO 自动绘制框 + 标签
# ⑤ 显示视频
cv2.imshow("YOLOv11 CAM Detection", annotated_frame)
# 按 q 退出
if cv2.waitKey(1) & 0xFF == ord("q"):
break
cap.release()
cv2.destroyAllWindows()启动后会看到 YOLO 实时检测摄像头画面。