
安装部署
官方参考:Documentation for Apache Ozone
准备环境
1->4-b
参考:Apache Ozone 介绍与部署使用(最新版2.0.0)-CSDN博客
c、创建workers
cpp
touch /usr/local/soft/ozone-2.0.0/etc/hadoop/workers里面添加
cpp
node11
node12
node135、集群拷贝
cpp
scp -r /usr/local/soft/ozone-2.0.0 root@node12:/usr/local/soft
scp -r /usr/local/soft/ozone-2.0.0 root@node13:/usr/local/soft
scp /etc/profile root@node12:/etc/profile
scp /etc/profile root@node13:/etc/profile进入node12、node13执行
cpp
source /etc/profile如果之前初始化过,需要删除node节点的数据
cpprm -fr /data/ozone/
6、初始化Ozone集群
在启动 Ozone 集群之前,需要依次初始化 SCM 和 OM。
以下在node11节点执行
a、初始化 SCM
cpp
ozone scm --init运行SCM
cpp
ozone --daemon start scmb、初始化OM(scm需要启动状态)
cpp
ozone om --init启动OM
cpp
ozone --daemon start om注意 : 如果 SCM 未启动,om --init 命令会失败,同样,如果磁盘上的元数据缺失,SCM 也无法启动,所以请确保 scm --init 和 om --init 两条命令都成功执行了。
c、初始化DataNode(或者直接执行第7步)
接下来启动 Datanode,在每个 Datanode 上运行下面的命令:
cpp
ozone --daemon start datanode
7、启动与关闭
如果首次执行第6步,代表已经启动,这里不用启动了
启动
cpp
start-ozone.sh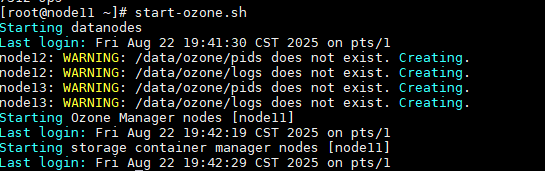
关闭
cpp
stop-ozone.sh8、浏览器验证
a、访问om web
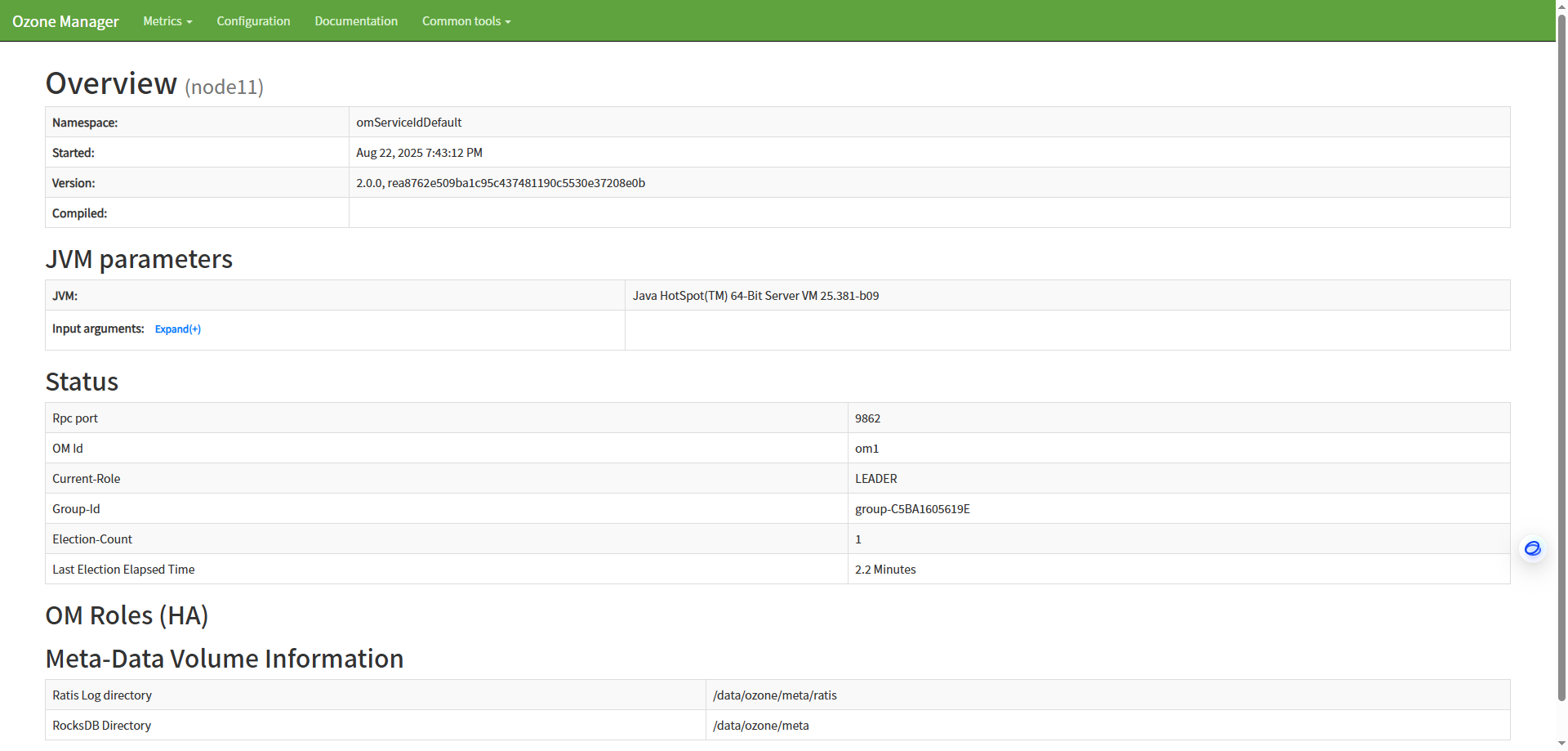
b、访问scm web
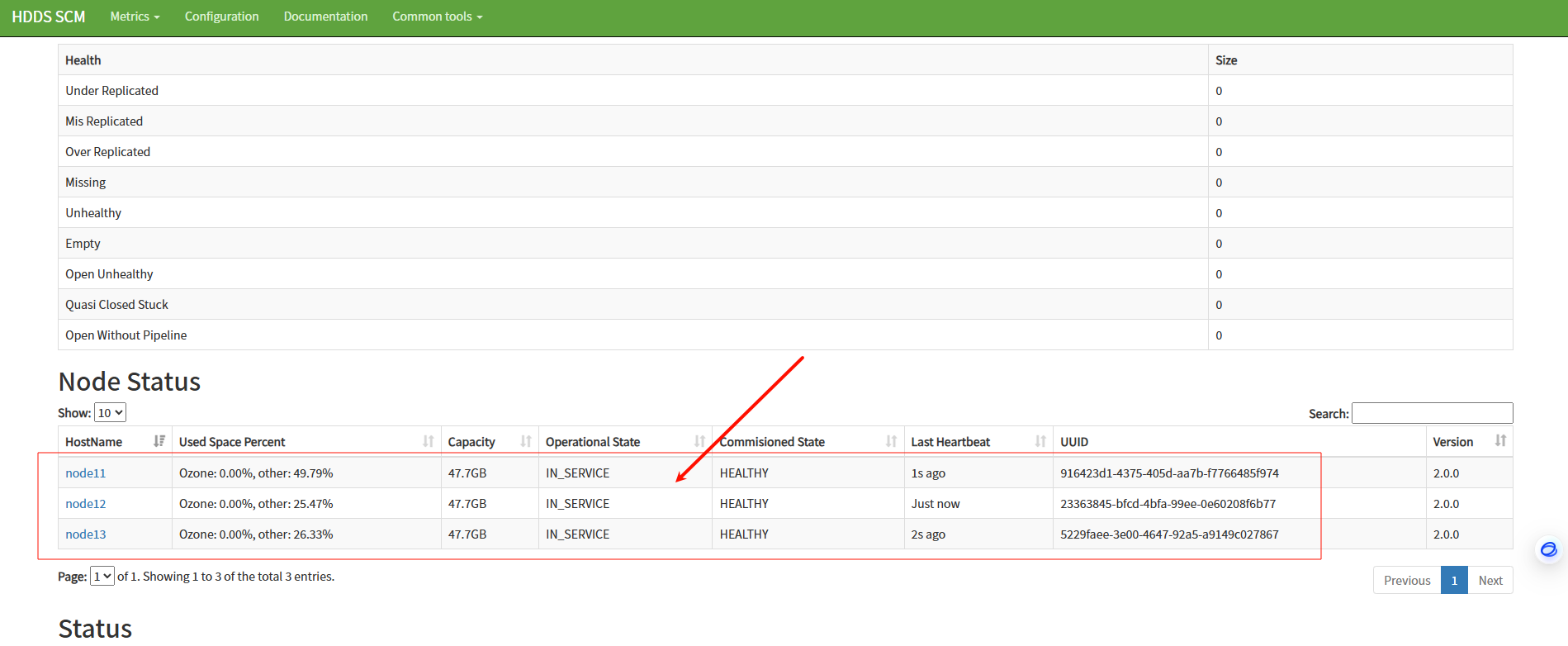
c、访问datanode
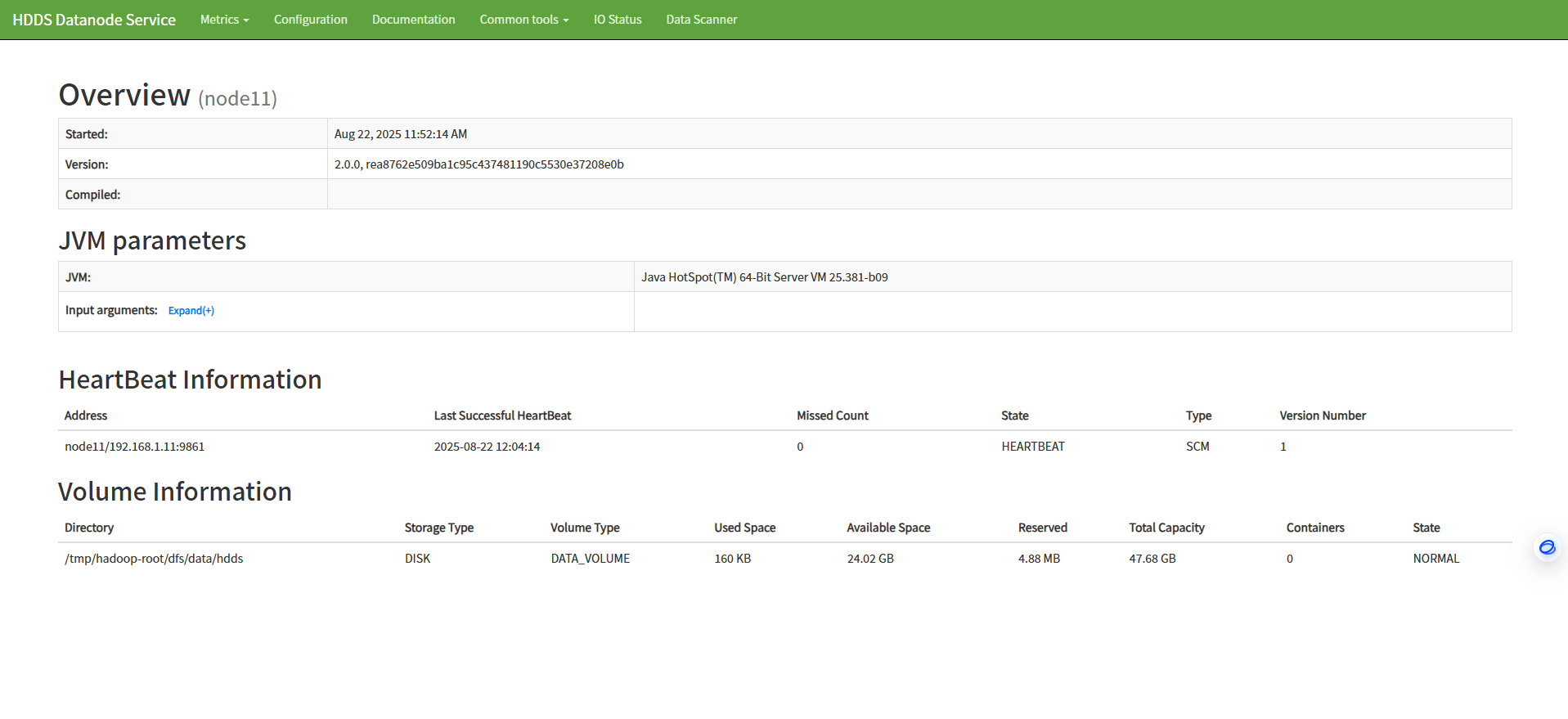
9、cli命令
参考官网: 参考官方文档:Documentation for Apache Ozone