一、概览
1.1 定义
大语言模型(LLM)是基于深度学习和神经网络的自然语言处理技术,目前主要通过Transformer架构和大规模数据训练来理解和生成语言。
GPT不同架构的训练参数:
- GPT-1(2018):1.17亿参数
- GPT-2(2018):15亿参数
- GPT-3(2020):1750亿参数
- GPT-4(2023):参数规模进一步增加
1.2 流程
主要步骤如下:
- 输入文本 → 2. Tokenize分词 → 3. 查表映射为词向量 → 4. Transformer网络编码/解码 → 5. 生成token分布 → 6. 采样/查表输出文本
1.3 主流大模型架构对比
经典Transformer架构由编码器(Encoder)和解码器(Decoder)2个组件构成,每个组件都含有自注意力机制和前馈网络2个核心机制。
当前主流大模型是此基础的变体
|-----------------------|-----------------|------------------|------------|
| 模型 | 架构类型 | 构成/特点 | 主要用途 |
| BERT | Encoder-only | 多层编码器,双向自注意力 | 理解(分类、问答等) |
| GPT系列/DeepSeek R1 | Decoder-only | 多层解码器,单向(因果)自注意力 | 文本生成、对话 |
| Gemini | 多模态/异构架构 | 可统一处理文本、视觉等 | 多模态AI任务 |
| Claude/文心/DeepSeek V3 | Decoder-only/增强 | 安全、知识注入等优化 | 更可靠的文本任务 |
二、大模型原理
输入层
1.用户输入文本
2.分词(Tokenization)
3.Token到Token ID(查词表得到整数编码)
便于计算机存储
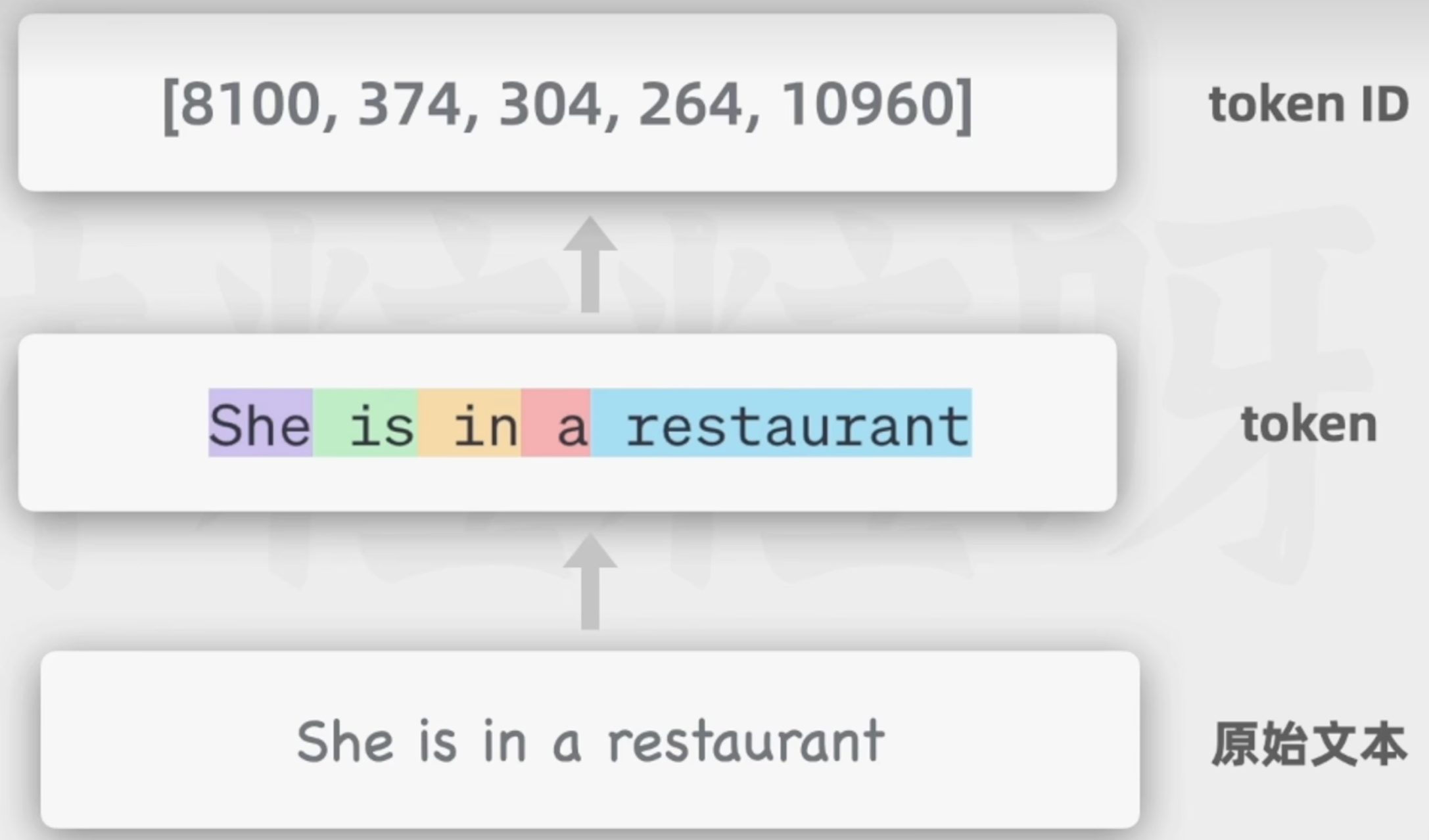
4.Token ID到词向量(查embedding矩阵)
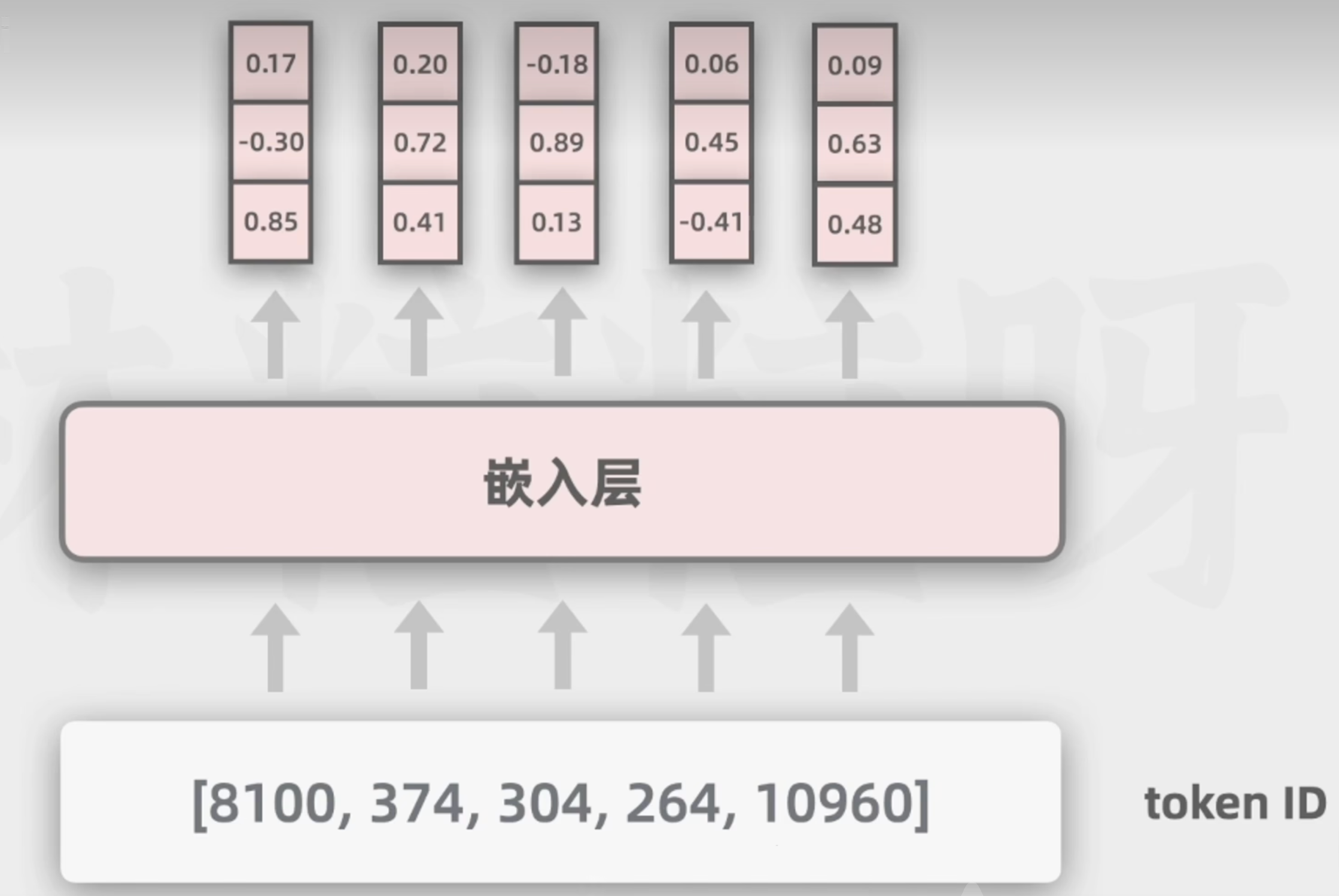
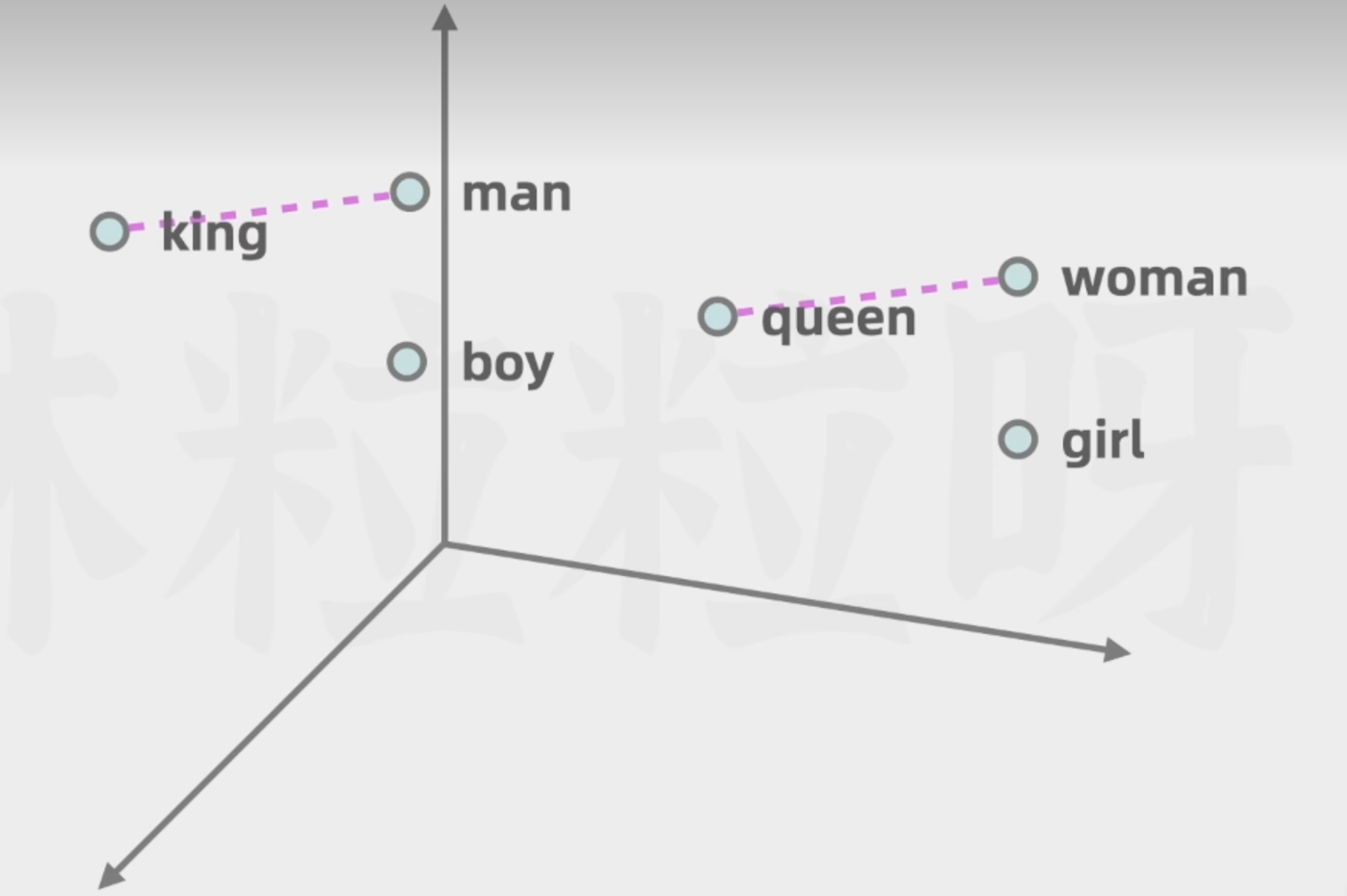
词向量可以表示更多的维度的含义,利于模型通过数学计算向量空间的距离,去捕捉不同词在语义和语法等方面的相似性
- 词的含义
- 词与词之间的复杂关系
如下图,男人与国王,女人与女王,两者之间的差异可以被看作是相似的
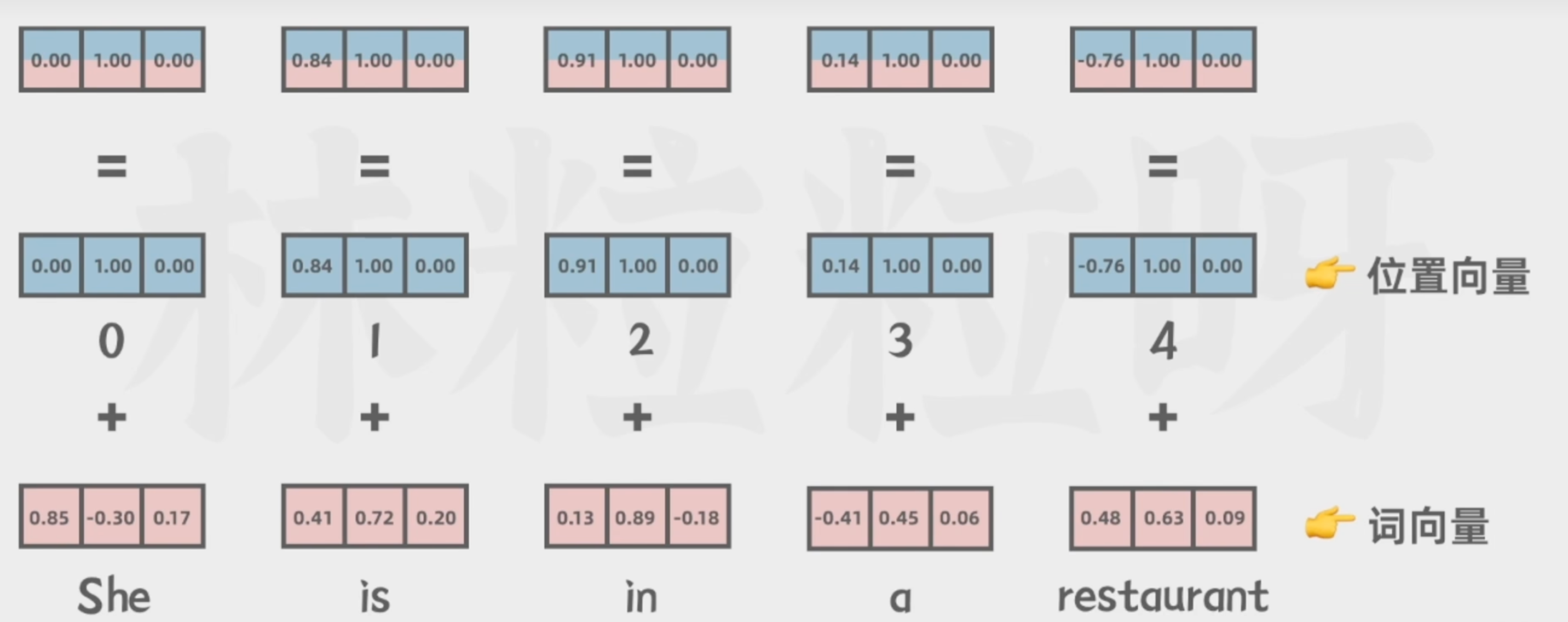
5.词向量与位置向量相加
让模型理解不同词之间的顺序关系
Transformer架构
编码器只做一次(输入全序列),解码器每生成一个词都要重新递归一次(扩展目标序列),但会用编码器已保存的输出。
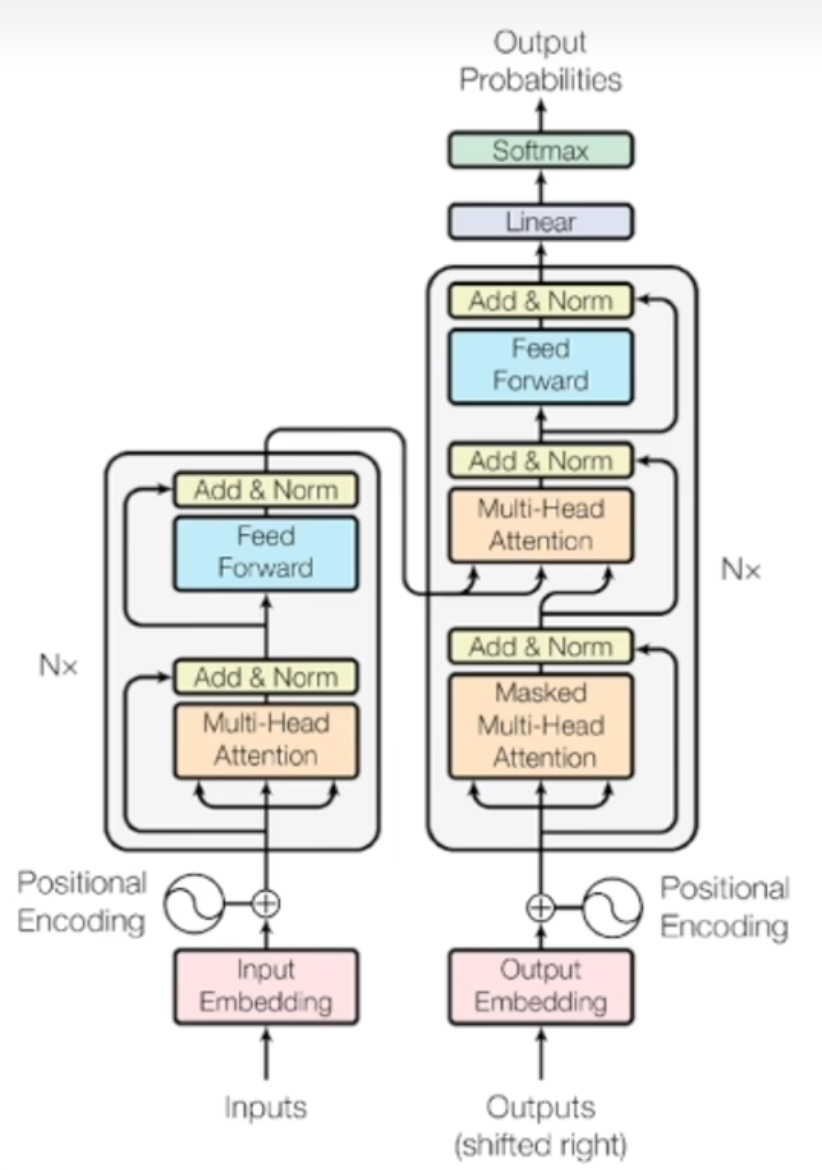
编码器(模型理解的关键)
自注意力机制
作用:
融合上下文中的相关信息
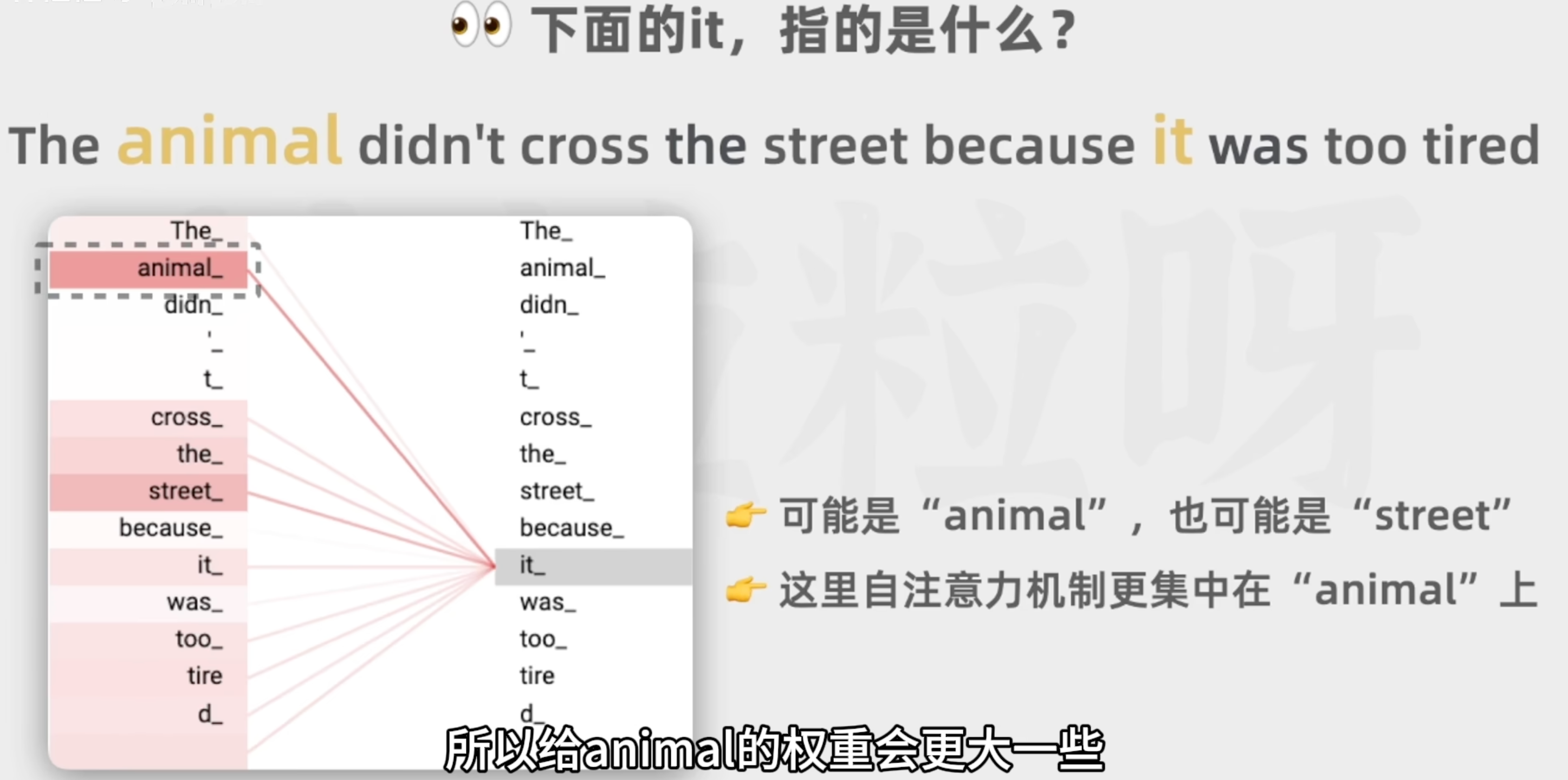
可以有多个自注意力头,关注情感的,关注命名实体的,可以并行运算
每个自注意力头的权重是模型在之前的训练过程中从大量文本里学习和调整的
原理:
用三个权重矩阵Wq、Wk、Wv与每个词的向量表示相乘后得到q、k、v向量
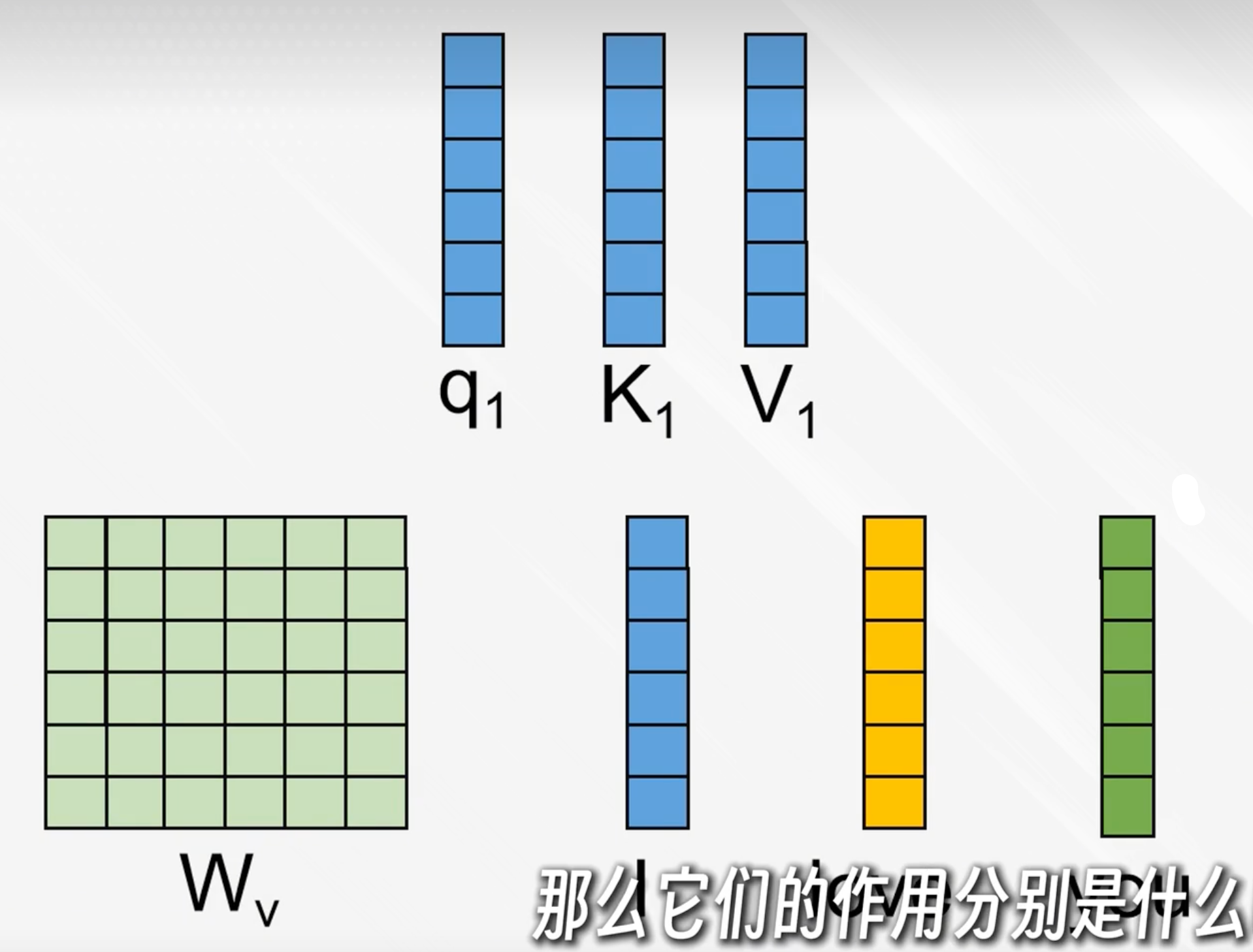
q:我想要找什么
k:你有没有我要找的东西(权重)
v:我要传递的内容
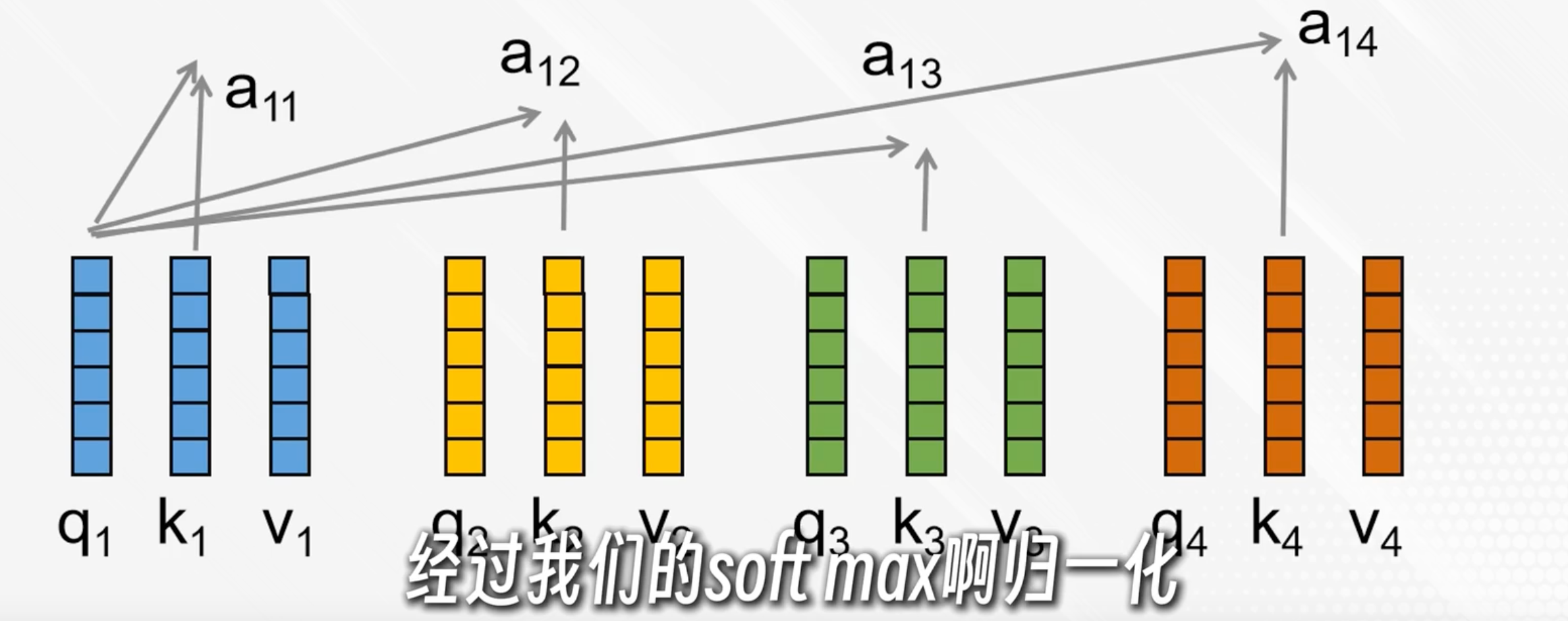
q与每个k点积后各自得到一个分数,经过softmax归一化变成加权系数aij
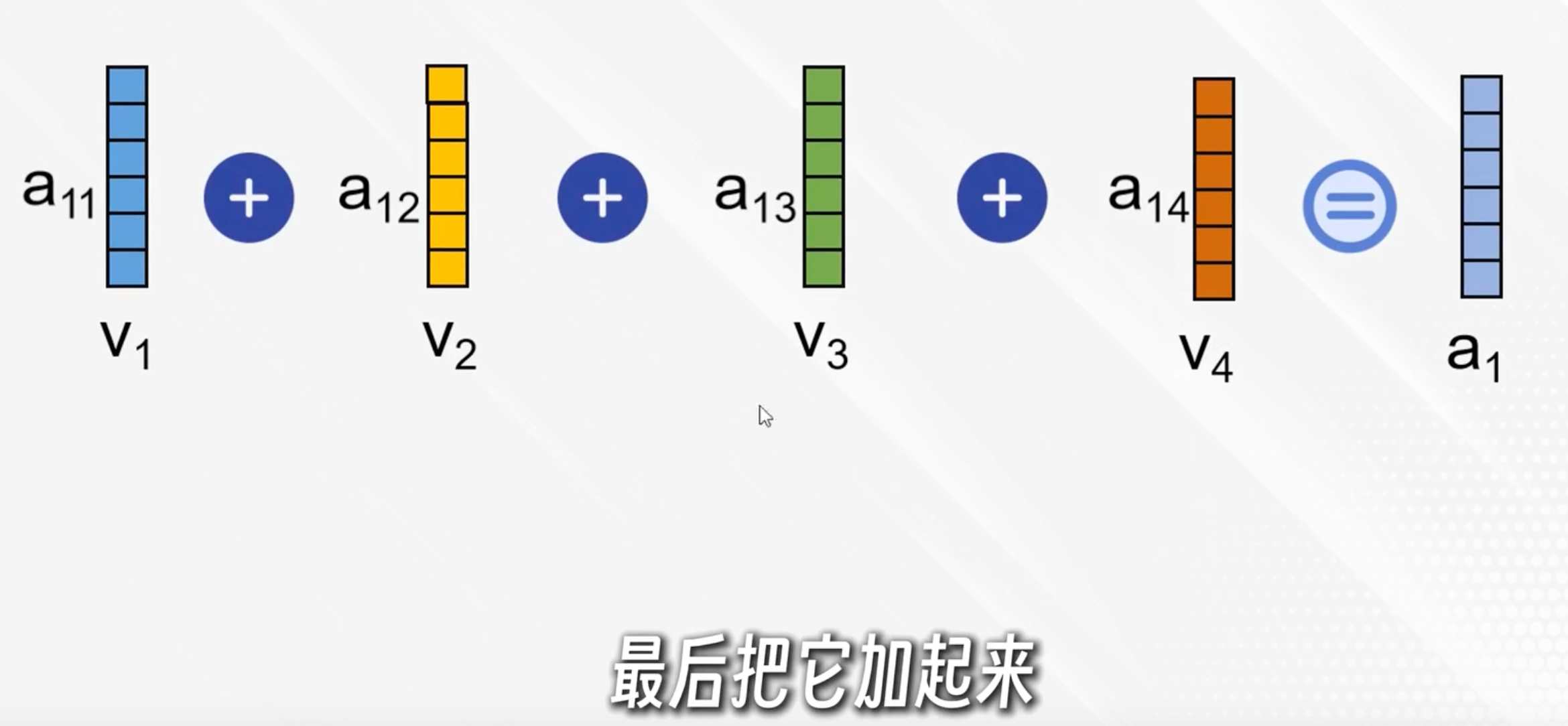
每个加权系数与对应的v点积,再相加,得到ai,表示在第i个词的视角下,按照权重与其他词的内容融合
简单说,ai就是以第i个词为中心理解了上下文

实际有多个自注意力头,把对应的拼接起来(如a11+a12)再乘上一个权重矩阵得到输出
前馈神经网络
为为每个位置的"单词"做复杂的、非线性加工
标准FFN结构:
- 一个线性层,升维,通常把d_model提升到更高的d_ff(通常是d_model的4倍)
- 非线性激活(如ReLU或GELU)
- 一个线性层,降维,回到d_model
- 残差+LayerNorm
假如模型在生成句子时,自注意力层捕捉到了"猫"和"坐在垫子上"的关联;前馈神经网络可以进一步细化每个词的语义,比如让"坐"这个词的隐藏向量更好地表达了动作信息,让"垫子上"这个词的向量更好地表达了空间关系。最后,经过多层叠加,模型能生成更自然有上下文语义的话。
解码器(模型生成的关键)
解码器把编码器的输出和已经生成的文本作为每次的输入,保持输出的连贯性和上下文的相关性
每个解码器有2个多头自注意力和一个前馈神经网络
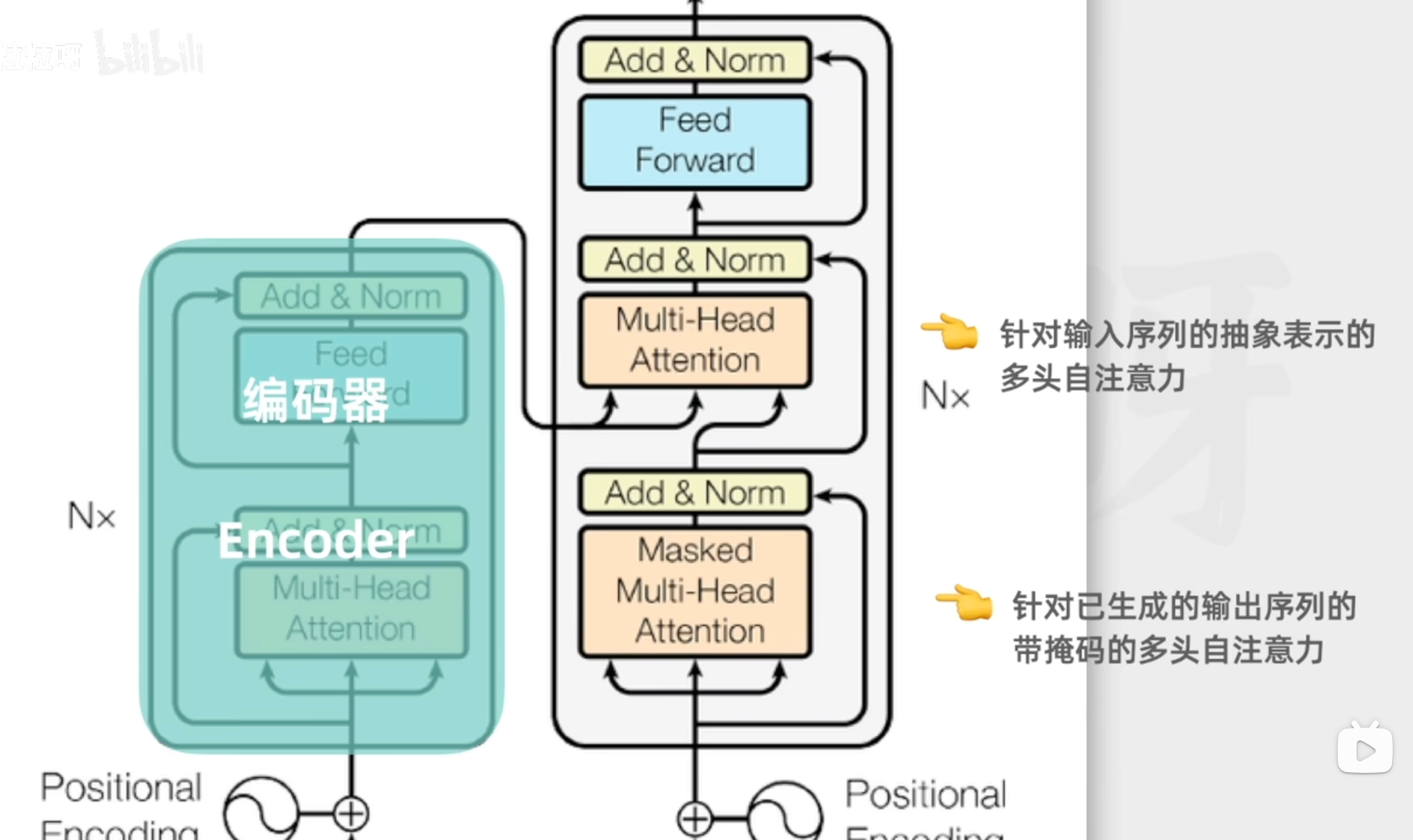
带掩码的自注意力机制
针对已生成的输出序列,只使用前面的词作为上下文

第二个自注意力机制
捕捉编码器的输出的和解码器即将生成的输出之间的对应关系,从而将原始输入序列融合到输出序列的生成过程中
前馈神经网络
与编码器的类似,通过额外计算增强模型的表达能力
输出层
logits = [3.2, 0.9, -2.0, ...] # 词表每个词的分数
softmax = [0.54, 0.13, 0.001, ...] # 转成概率,每个词的出现概率线性层
将解码器输出的隐藏表示投影到词表大小(Vocab size),得到每个词的logits(词表每个词的分数)
Softmax层
将logits变为概率分布,用于采样/选择下一个词