
笔记整理:刘轶,天津大学硕士,研究方向为知识图谱和大模型
论文链接:https://doi.org/10.1162/coli_a_00548
发表会议:Computational Linguistics (2025) 51 (2): 467--504.
1. 动机
因果推理是人类思维的核心能力,但大型语言模型(LLMs)在处理复杂因果推理任务(如溯因推理和反事实推理)时仍面临挑战。其核心难点在于文本中复杂的因果结构(如多事件分支关系)通常隐含在时序描述中,难以被LLMs显式学习。而编程代码中的条件语句能更直接、频繁地表达因果关系,所以代码语言模型(Code-LLMs)可能具备更强的因果推理能力。因此亟需探索Code-LLMs是否比通用LLMs更擅长因果推理,以及代码提示是否能比文本提示更清晰地描述因果结构。
2. 贡献
本文的主要贡献有:
(1)设计了代码提示来处理因果推理任务,通过利用代码中的条件语句来表示因果结构。
(2)在零样本和单样本设置下,全面评估多种通用LLMs(如LLAMA-2、GPT-3)和Code-LLMs(如CODELLAMA、CODEX)在溯因推理和反事实推理任务上的表现,并验证了代码大语言模型比通用大语言模型更擅长因果推理,并且对于大多数模型来说,代码提示比文本提示更有效。
(3)通过干预实验,例如修改提示的信息、结构、格式和编程语言,揭示编程结构(尤其是条件语句)是代码提示有效的关键因素。
(4)证明了仅在条件语句的代码语料库上对大语言模型进行微调就可以提高它们的因果推理能力。
3. 方法
主要考虑两个具有挑战性的因果推理任务:溯因推理和反事实推理。溯因推理要求模型在与前提一致的情况下,为结果生成一个合理的原因。反事实推理询问在反事实分支中会发生什么。任务和研究问题概述如图1所示,其中任务中事件之间的因果关系如图1左图所示,而本工作中讨论的研究问题,包括如何激发和如何提升大语言模型的因果推理能力如图1右图所示。这些研究问题如下:
-
代码语言模型在因果推理方面是否比通用语言模型更好?
-
代码提示在描述因果结构方面是否比文本提示更好?
-
代码提示的哪些方面使其有效?
-
如何使用代码数据提高大语言模型的因果推理能力?
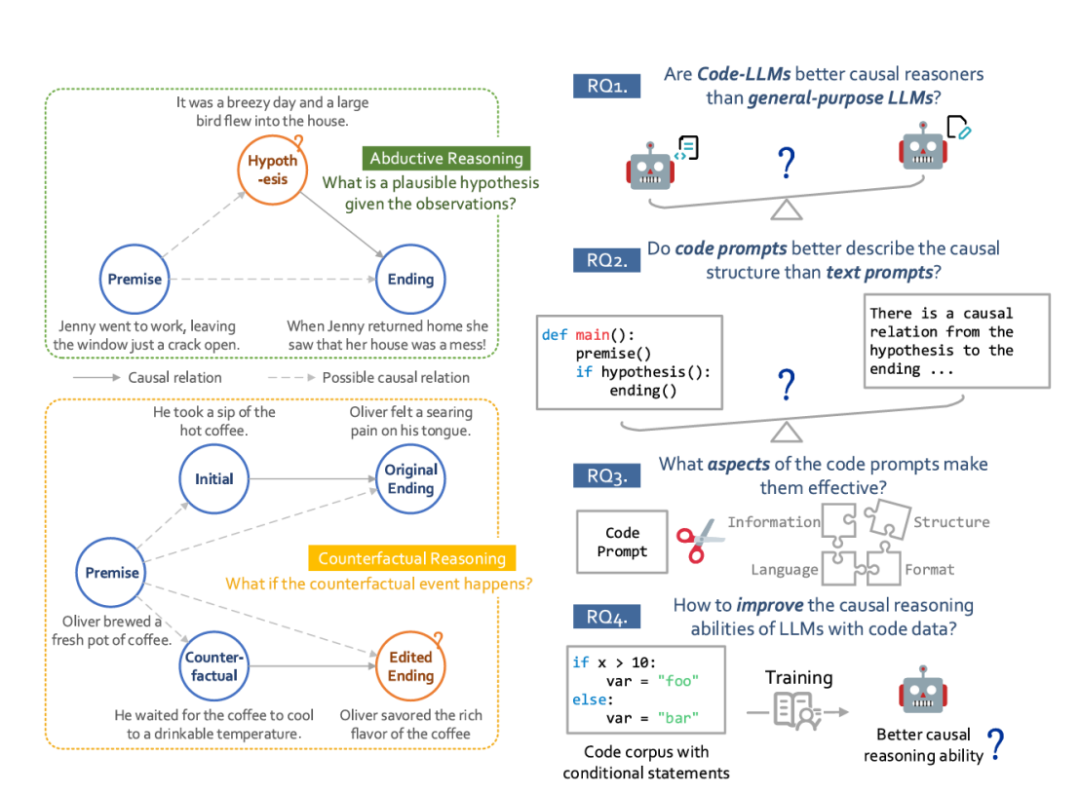
图1 任务和研究问题概述图
溯因推理的代码提示构建如图2所示,因果结构在主函数中通过执行流程来表示:执行前提,如果满足假设,则执行结局。事件内容以注释形式嵌入函数,目标函数置于末尾供模型生成

图2 溯因推理代码提示构建图
反事实推理的代码提示构建如图3所示,使用if-elif结构区分原始分支与反事实分支,确保因果逻辑清晰,并通过注释明确任务要求,例如最小化修改原始结局
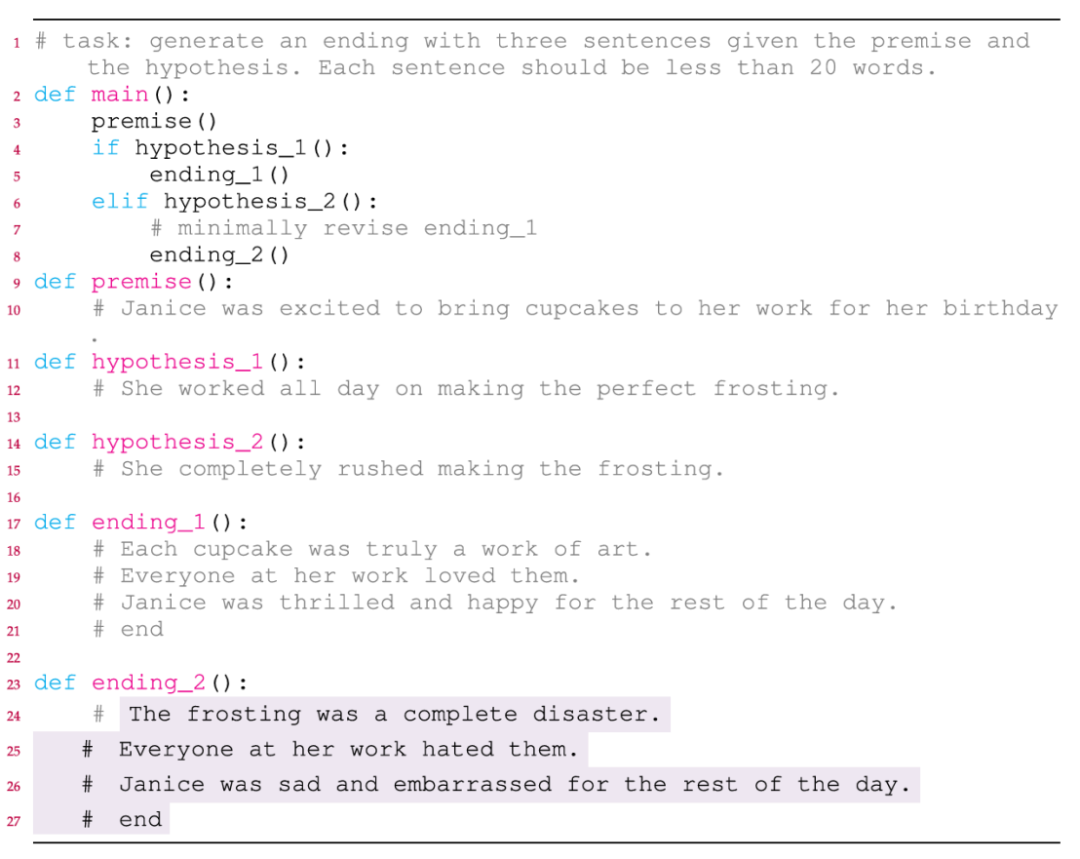
图3 反事实推理代码提示构建图
在文本提示的设计上,用自然语言描述相同的因果结构;在模型的对比上,选择了像<LLAMA - 2, CODELLAMA>和<GPT - 3, CODEX>这样的大语言模型对,它们具有相同的结构,只是在文本/代码训练语料库的比例上有所不同。
对于代码提示中构建因素的探讨,选择了信息、结构、格式和语言四个方面进行干预。
4. 实验
在结果评估实验中,溯因推理使用ART数据集,反事实推理使用TimeTravel数据集,评估指标包括BLEU-4、ROUGE-L、CIDEr、BERTScore。零样本情况下,溯因推理的自动评估结果如表1所示,反事实推理的自动评估结果表2所示;单样本情况下,评估结果如表3所示;人工评估结果如表4所示。
在干预提示实验中,在信息方面,研究两种类型的先验信息:任务指令和函数名,在"无指令"中,我们从提示中删除任务指令,在"函数名扰动"中,我们用匿名函数X替换原始函数名;在结构方面,一种是将条件结构转换为顺序结构,一种是随机打乱条件结构中函数的位置;在格式方面,除了原始格式外,还测试了两种格式:类和打印;在语言方面,将原始的Python程序转换为另外两种编程语言,Java和C,以评估编程语言的影响。实验结果如表5所示。
在微调实验中,使用现有的代码语料库CodeAlpaca - 20k(Chaudhary,2023)来构建微调数据,CodeAlpaca - 20k包含20,000个遵循指令的数据,用于将LLAMA - 2微调为Code Alpaca模型。对三个7B模型LLAMA - 2、QWEN1.5和DEEPSEEK - LLM进行微调,以128的批量大小训练它们一个轮次,使用AdamW优化器,学习率为2e-5,热身率为0.03。最大长度设置为512,这涵盖了大部分CodeAlpaca数据。批量大小、轮次数量和学习率这些超参数是通过在ART和TimeTravel的验证集上进行网格搜索选择的。在条件语句上微调的模型的自动评估结果如表6所示,而为了研究性能提升随训练数据量的变化趋势,将训练数据的比例从0%控制到100%,并评估微调后模型的性能,结果如图4所示。
表1 溯因推理的自动评估结果表
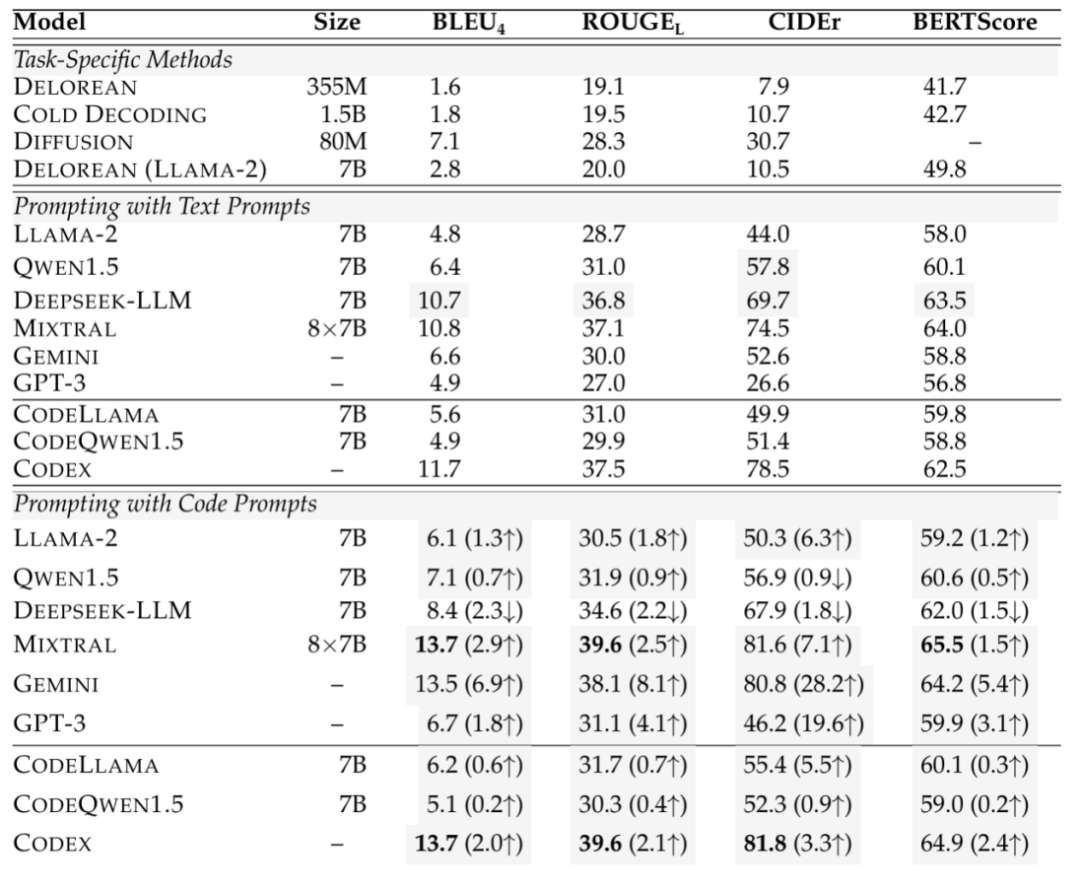
表2 反事实推理的自动评估结果表
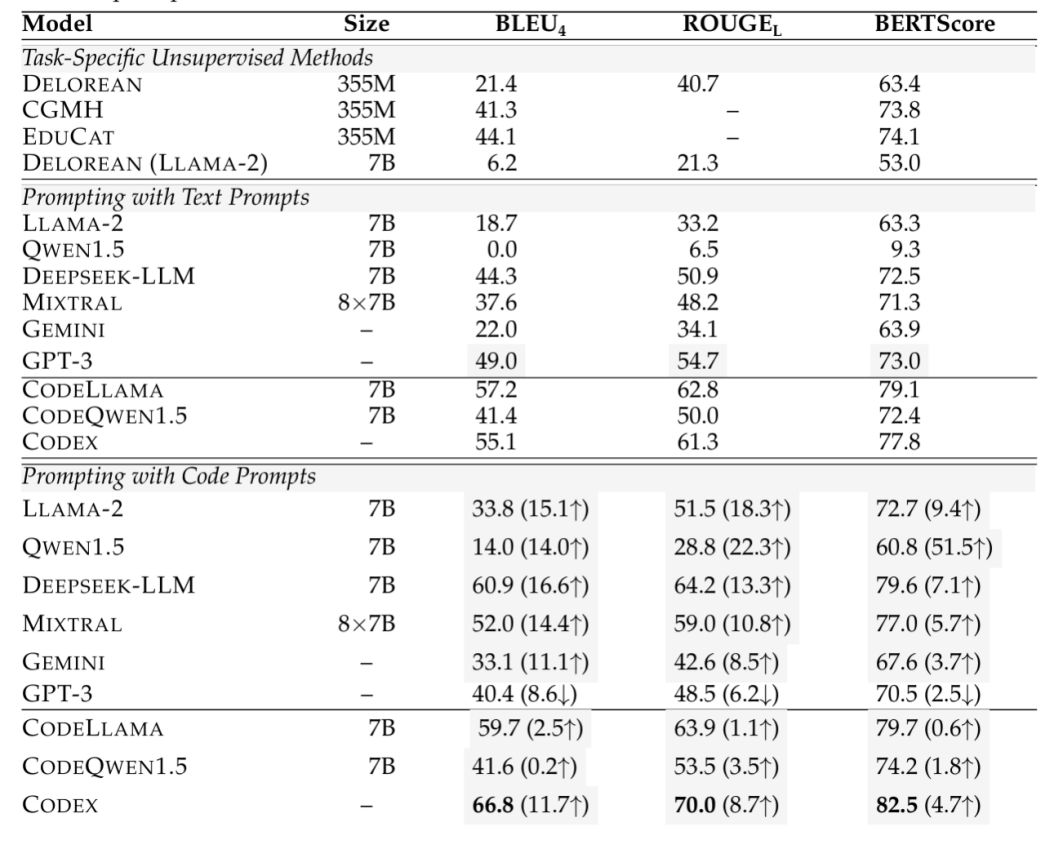
表3 单样本设置下评估结果表
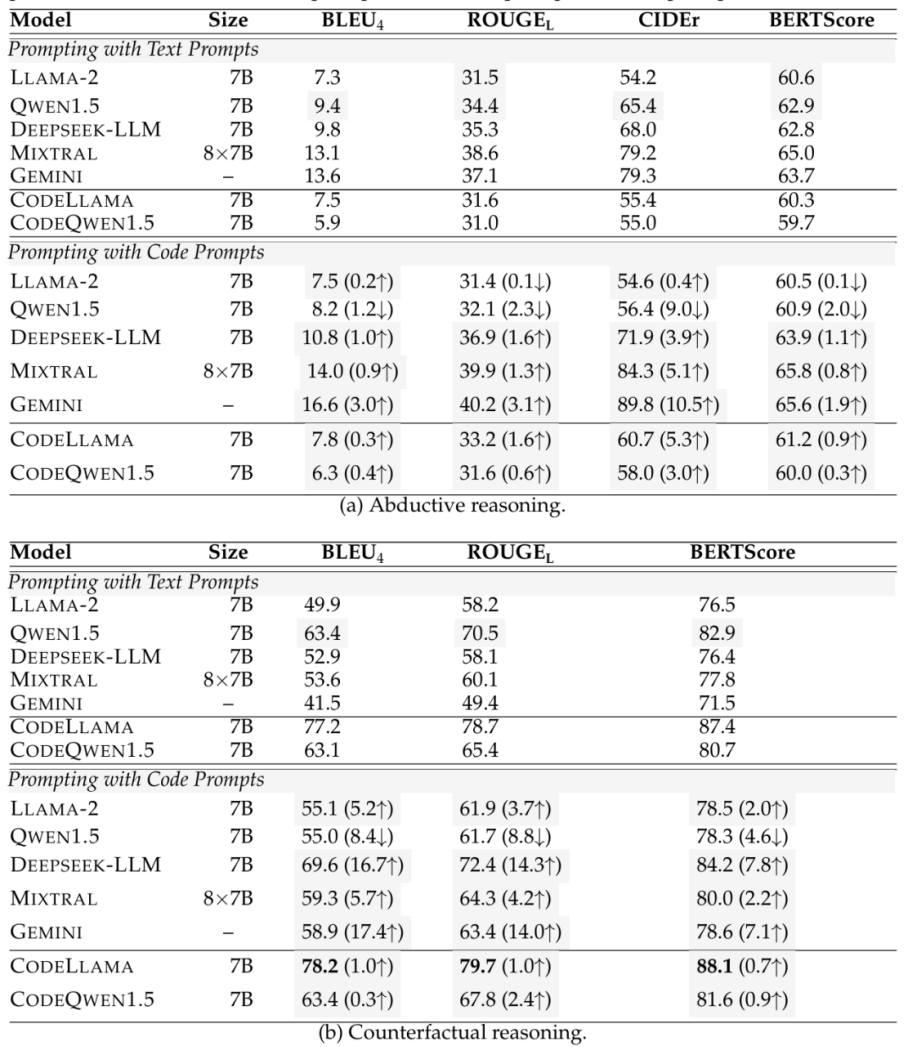
表4 人工评估结果表
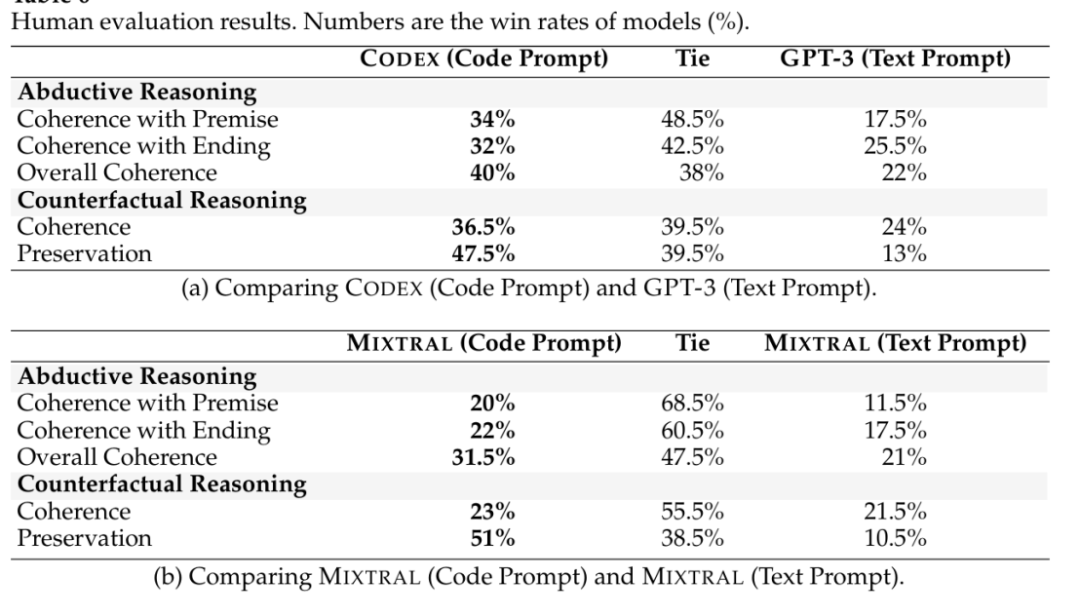
表5 干预提示实验结果表
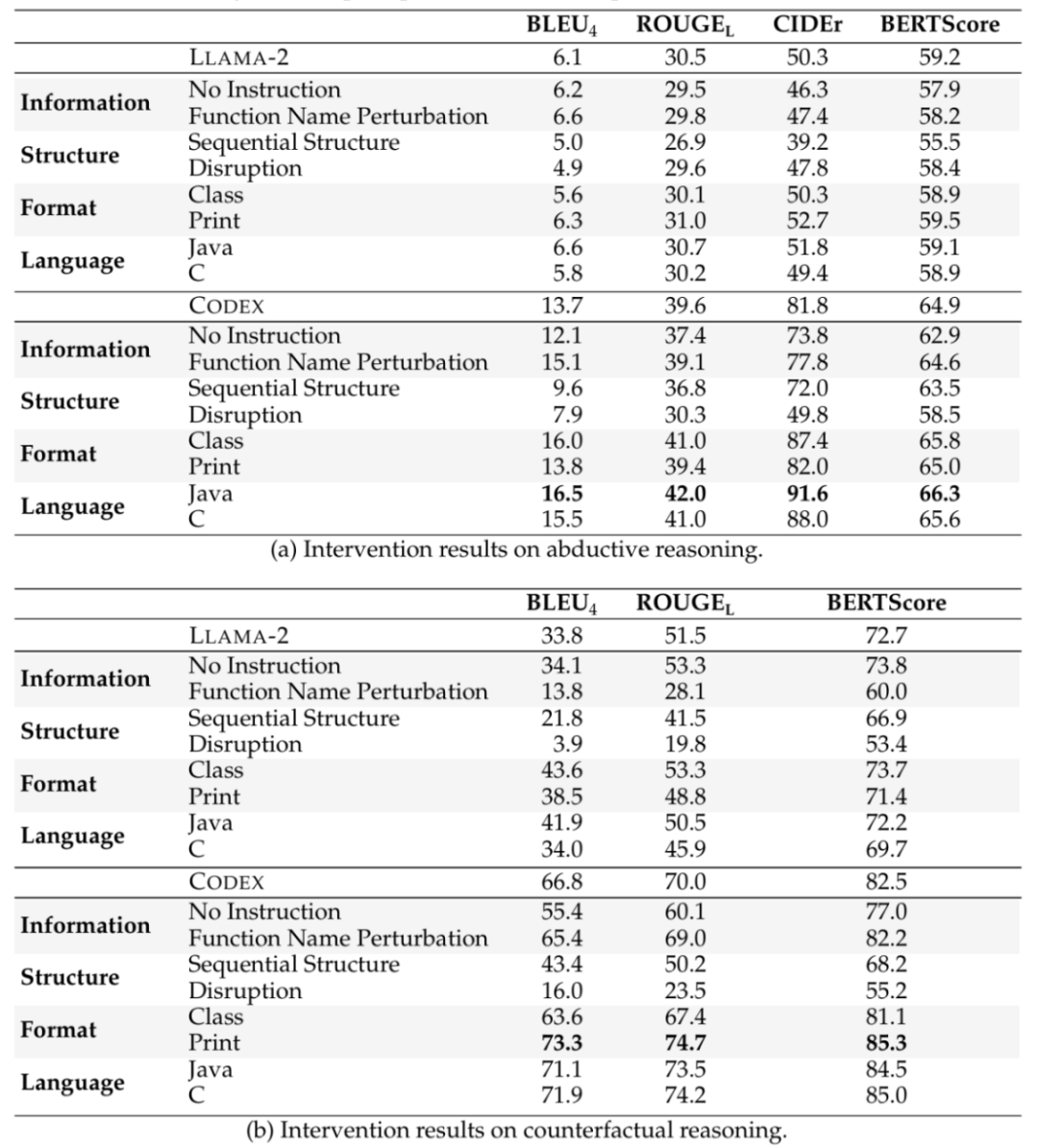
表6 在条件语句上微调的模型的自动评估结果表
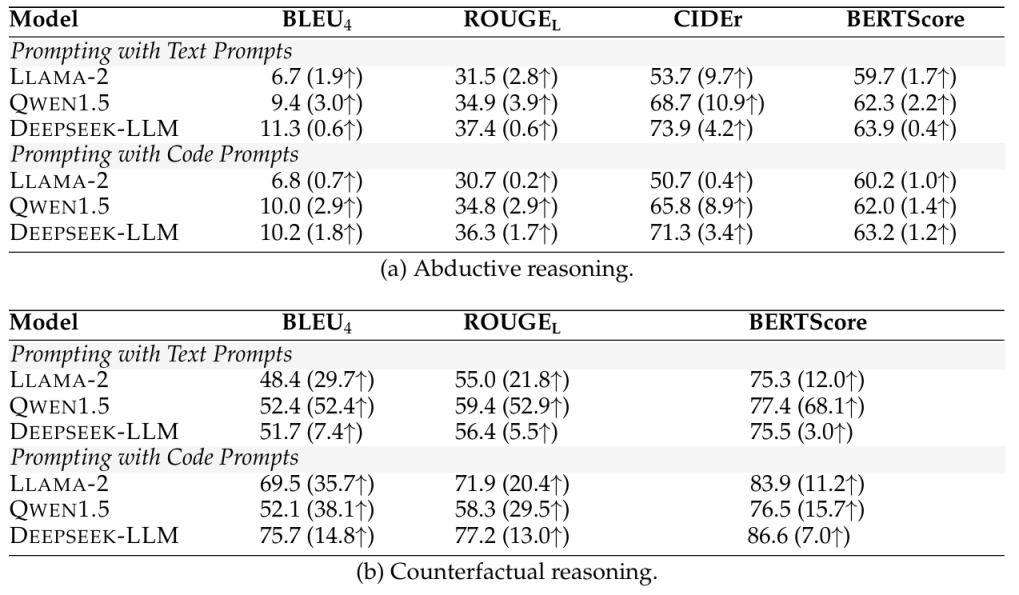
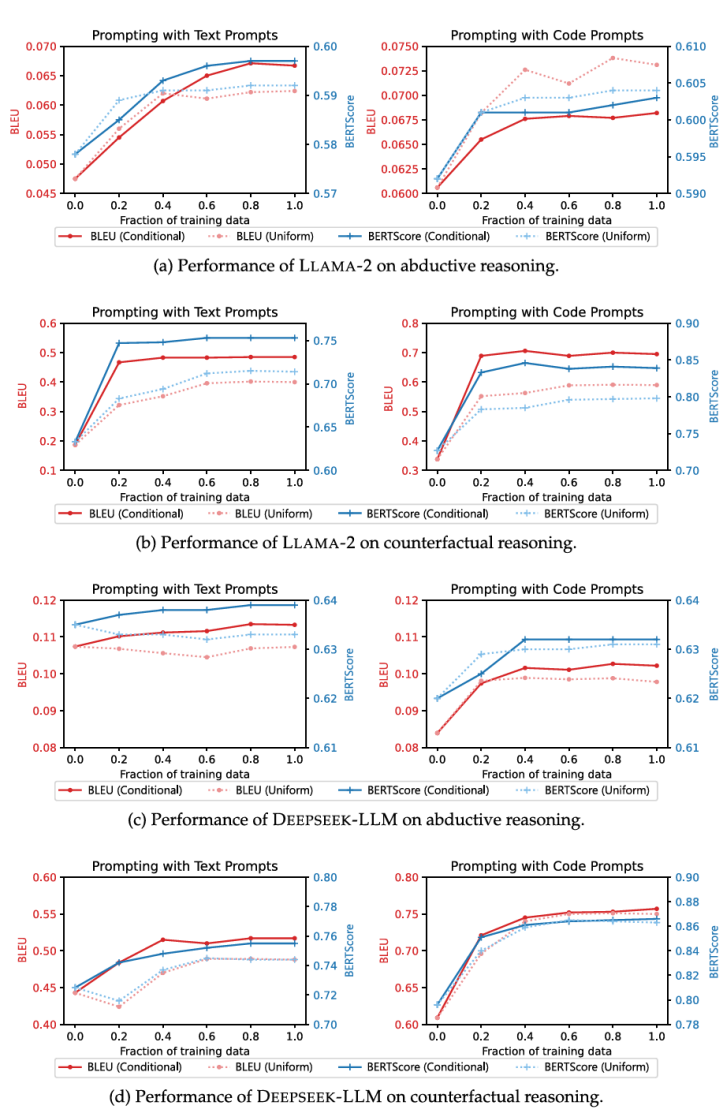
图4 使用不同比例训练数据微调后的模型性能图
实验表明用代码描述复杂的因果结构对大多数模型来说更清晰、更容易理解,并且所有模型在单样本设置下的表现都优于零样本设置,代码语言模型在大多数设置下仍然优于相应的通用语言模型,并且对于大多数模型来说,代码提示优于文本提示,代码语言模型和代码提示的优势在不同设置下都是稳健的;合理描述事件之间关系的条件结构在模型进行推理时至关重要,而模型对格式和语言干预更具鲁棒性,这表明通过精细的提示工程可以进一步提高性能;同时在大多数情况下,从0%到20%的训练数据观察到最大的性能提升,这表明仅用少量(少于一千条)条件语句代码,模型的因果推理能力就能大幅提高,条件语句是能增强因果推理能力的。
5. 总结
本文研究了代码语言模型(Code-LLMs)的因果推理能力以及在因果推理任务中使用代码提示的有效性。经过证明,在执行复杂因果推理任务时,代码语言模型优于相同结构的通用语言模型。与文本提示相比,代码提示在描述因果结构方面更有效,提高了广泛语言模型的性能。本文还进一步分析了代码提示不同方面的重要性,发现在代码中提供合理的因果结构有助于生成合理的输出。基于这些观察结果,本文假设在条件语句的代码语料库上微调模型可以提高因果推理能力,并通过实验验证了这一假设。这些发现表明,代码,特别是代码中的条件语句,通过提示和微调在引发和提高语言模型的因果推理能力方面可以发挥重要作用。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文 ,进入 OpenKG 网站。