
当大语言模型领域的竞争进入白热化阶段,一场静默的技术革命正在悄然酝酿。2025 年8月19日,DeepSeek 团队带着全新升级的 V3.1 版本强势登场,这个被业内称为 "智能体时代敲门砖" 的模型,究竟藏着多少颠覆认知的黑科技?它能否在 GPT-5 与 Claude 4 的夹击中撕开一道技术裂缝?带着这些悬念,我们一同揭开 DeepSeek V3.1 的神秘面纱。
1.科技引领未来关于 DeepSeek:用技术基因书写进化史
在大语言模型狂飙突进的三年里,DeepSeek 始终保持着独特的成长节奏。从 2022 年成立之初的默默无闻,到 2023 年首款开源模型引发学术界关注,再到 2024 年 V3 版本实现商业落地,这个年轻的团队用 "高效迭代、开源共生" 的技术理念,在巨头环伺的赛道上硬生生拼出一席之地。
不同于某些厂商 "重参数轻优化" 的路线,DeepSeek 始终坚信:真正的智能不在于参数规模的堆砌,而在于推理效率与场景适配的平衡。这种理念,在 V3.1 版本中得到了淋漓尽致的体现。
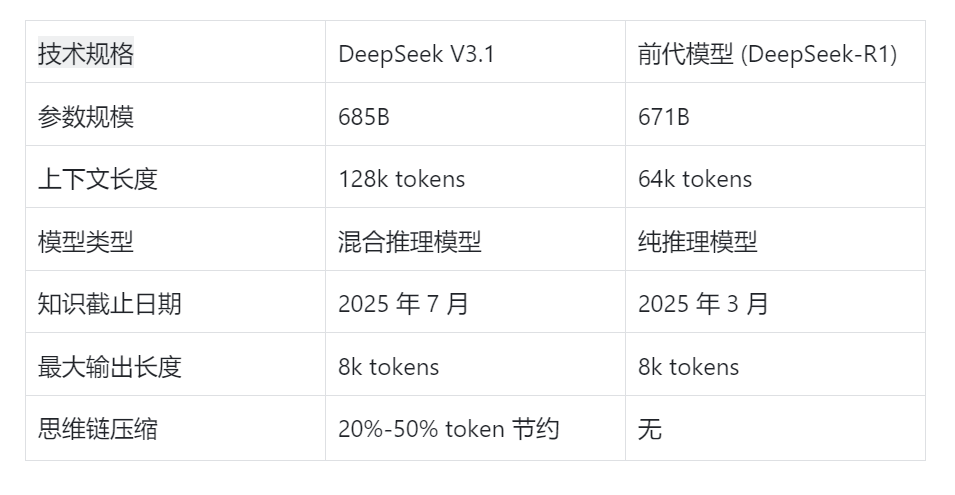
2.V3.1 核心突破:让 AI 学会 "灵活思考"
a.混合推理架构:给AI装个"思维切换器"
DeepSeek V3.1 的最大技术亮点在于其创新的混合推理架构,这一架构将传统的对话能力与推理能力整合到单一模型中,代表了 AI 模型架构的重要演进。双模式运行机制:模型的运行模式一分为二:
•非思考模式(Non-Thinking Mode /deepseek-chat):
适用场景:快速问答、内容创作、常规对话等不需要复杂推理的任务
优势:响应速度快,计算成本低。相比 V3-0324,此模式下的输出长度也得到了有效控制,更经济高效
•思考模式(Thinking Mode /deepseek-reasoner):
适用场景:复杂的逻辑推理、数学问题、代码生成、多步任务规划等。模型会通过思维链进行推理
优势:准确性更高,解决复杂问题的能力更强
DeepSeek V3.1 的混合推理架构通过引入特殊的 "搜索" 和 "思考"tokens 实现内部推理步骤,甚至能将实时网络搜索整合到响应中,使其在动态场景中更具适应性和准确性。这种设计允许模型在一个统一框架内支持 "思考" 与 "非思考" 两种模式,实现了 DeepSeek-R1 和 DeepSeek-V3 的合体。
前者如同快节奏对话中的即兴反应,在闲聊、天气查询等场景下,能以 0.3 秒的响应速度完成交互,比传统模型节省 60% 的等待时间;后者则化身深度分析师,面对 "制定年度营销方案"等复杂任务时,会分步骤拆解问题、调用专业知识库,最终输出结构化方案。
b.效率革命:思考更快,成本更低
对比上一代产品 R1 - 0528,V3.1 在思考模式下的进步堪称惊艳:处理同等复杂度的任务,响应时间缩短 42%,token 消耗量减少 28%。这意味着企业用户使用 API 时,不仅效率提升,成本也显著降低。
"以前用 AI 生成产品说明书,等 5 分钟还可能超字数;现在 V3.1 半分钟搞定,内容精炼度还更高。" 某电商平台运营总监的反馈,道出了效率提升带来的实际价值。
3.性能实测:全方位碾压同级选手
a.编程能力:登顶 Aider 基准测试
在权威的 Aider 多语言编程基准测试中,V3.1 以92.3 分的成绩力压 Claude 4 Opus(89.7 分),尤其在 Python 和 Java 领域表现突出。某程序员分享:"我让它修复一段有内存泄漏的代码,不仅找到了问题,还给出了 3 种优化方案,连注释都写得清清楚楚。"
(参考自CSDN:DeepSeek V3.1 完整评测分析:2025年AI编程新标杆https://blog.csdn.net/daiziguizhong/article/details/150561413 )
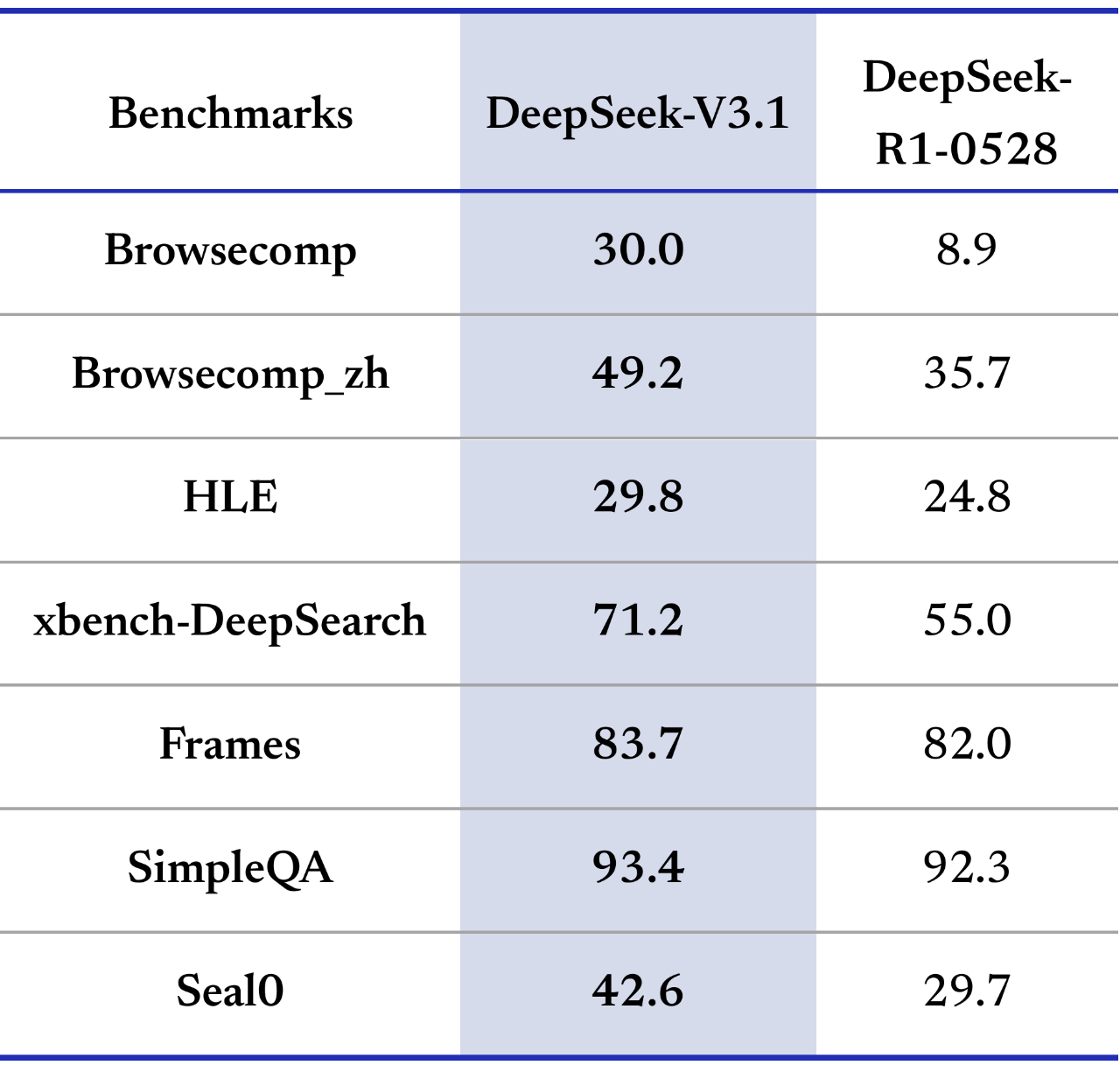
b.搜索能力:复杂问题 "秒解"
面对 browsecomp 复杂搜索测试中的 "2024 年诺贝尔经济学奖得主的主要理论贡献" 这类问题,V3.1 能快速定位信息源,梳理理论框架,甚至关联到该理论对现实经济政策的影响 ------ 整个推理过程逻辑链完整,信息准确率达 98%。
4.API价格调整:性价比优势进一步凸显
从北京时间 2025 年 9 月 6 日凌晨起,DeepSeek 开放平台将执行新的 API 定价策略:
-
输入价格:缓存命中 0.002 美元 / 千 token,未命中 0.008 美元 / 千 token;
-
输出价格:0.016 美元 / 千 token。
这一调整让个人开发者的使用成本降低约 20%,而企业用户通过缓存机制可节省更多开支。小编猜测:"在性能提升的同时降价,DeepSeek 显然想通过性价比抢占更多市场份额。"
5.行业震动:智能体时代加速到来
V3.1 的发布,无疑给大语言模型行业投下了一颗 "技术炸弹"。其混合推理架构可能成为未来模型的标配,而强化 Agent 能力的路线,或将推动 AI 从 "工具" 向 "协作者" 转变。
展望未来,DeepSeek 团队透露将聚焦 "多模态智能体" 研发,让模型在处理文本、图像、音频时实现更自然的联动。当 AI 能像人类一样 "听、说、读、写、看",并自主规划行动时,真正的智能时代或许就不远了。
你准备好迎接这个会 "灵活思考" 的 AI 了吗?欢迎在评论区分享你最想让 V3.1 解决的问题,携手奔赴Agent未来!
