一、引言
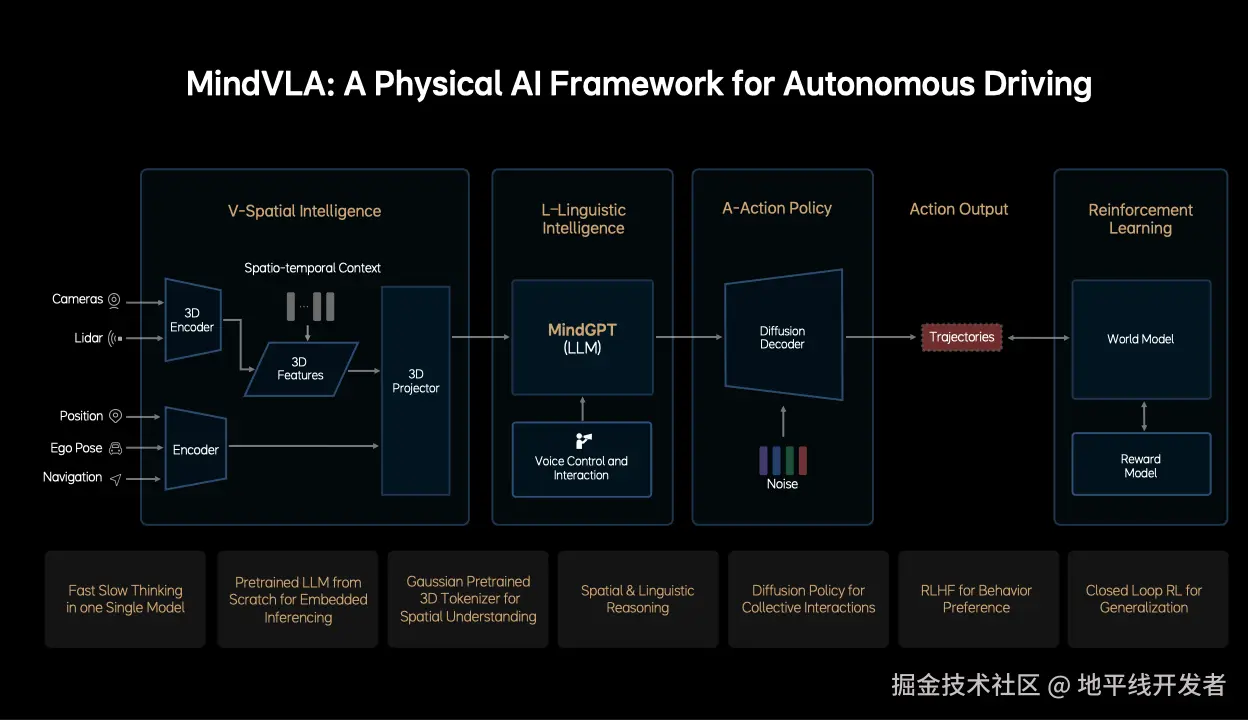
MindVLA 主要包括空间智能模块、语言智能模块、动作策略模块、强化学习模块,这些模块分别有以下功能:
- 空间智能模块:输入为多模态传感器数据,使用 3D 编码器提取时空特征,然后将所有传感器与语义信息融合成统一的表征。
- 语言智能模块:嵌入式部署的大语言模型 MindGP,用于空间 + 语言的联合推理,支持语音指令和反馈,可能实现人车交互。
- 动作策略模块:使用扩散模型生成车辆未来的行为轨迹,引入噪声来引导扩散过程以生成多样化的动作规划。
- 强化学习模块:使用 World Model 模拟外部环境响应,评估行为后果;使用奖励模型(Reward Model) :提供偏好或安全性评估,可能采用人类反馈(RLHF);使用闭环学习根据行为轨迹进行持续优化和泛化。
其亮点包括:
- 快慢思维融合于同一模型(Fast-Slow Thinking in One Model)
- 从零开始预训练的嵌入式大语言模型
- 高斯建模的 3D Tokenizer 增强空间理解
- 支持空间与语言的联合推理
- 扩散策略实现群体交互与行为生成
- 基于人类反馈的行为偏好学习(RLHF)
- 通过闭环强化学习实现泛化能力提升
- 下面将对以上提及的核心技术进行剖析。
二、V-Spatial Intelligence:自监督 3D 高斯编码器预训练
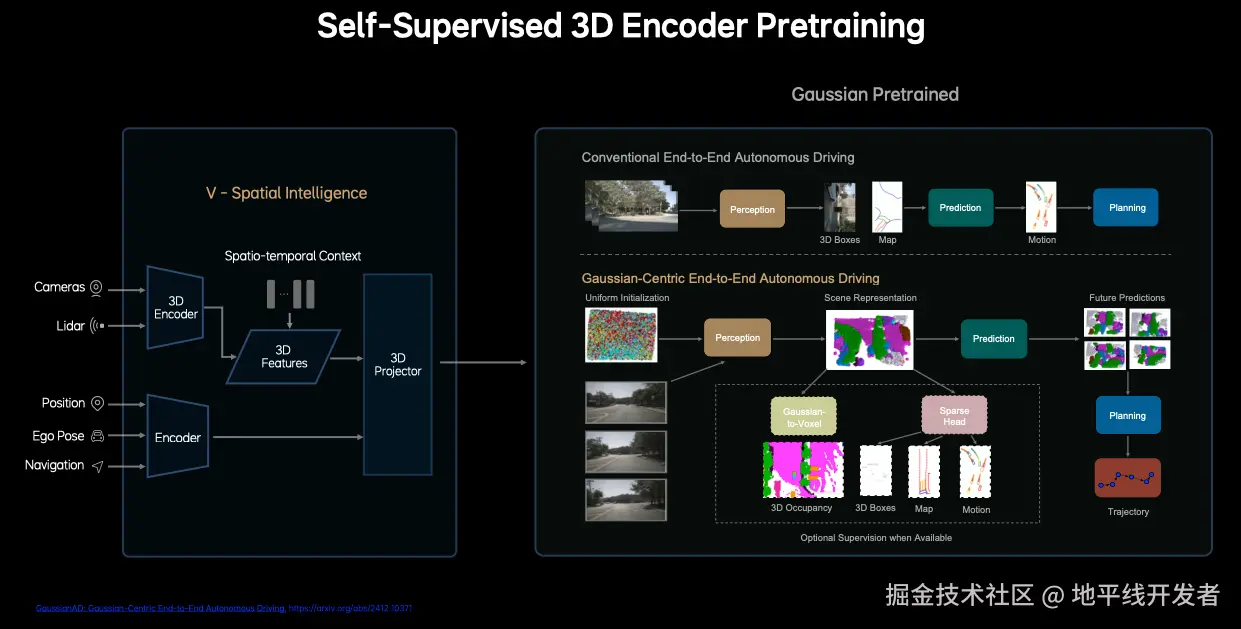
2.1 传统端到端自动驾驶的不足
传统的端到端自动驾驶通过感知(Perception)生成 3D 目标框(3D Boxes);然后预测模块使用 3D 目标和地图预测运动轨迹;规划模块根据预测进行轨迹规划。这种传统方法采用 BEV(鸟瞰图)或稀疏实例框作为场景表示,存在信息全面性与效率的权衡。BEV 压缩高度信息导致细节丢失,而稀疏查询可能忽略关键环境细节(如不规则障碍物)。密集体素表示计算开销大,难以支持实时决策。所以理想汽车提出了 GaussianAD 框架。
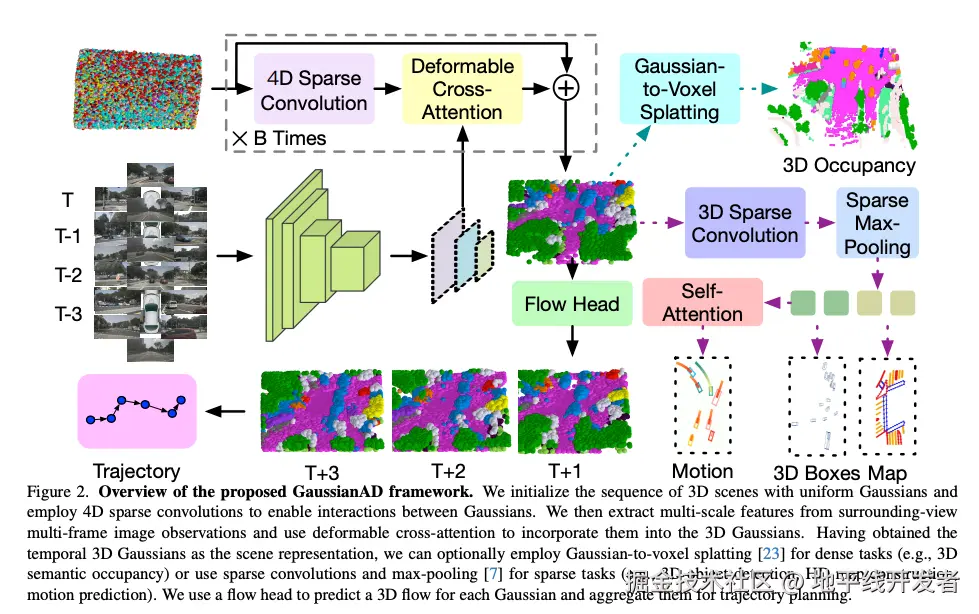
2.2 GaussianAD 框架的优点及核心方法
参考论文:GaussianAD: Gaussian-Centric End-to-End Autonomous Driving
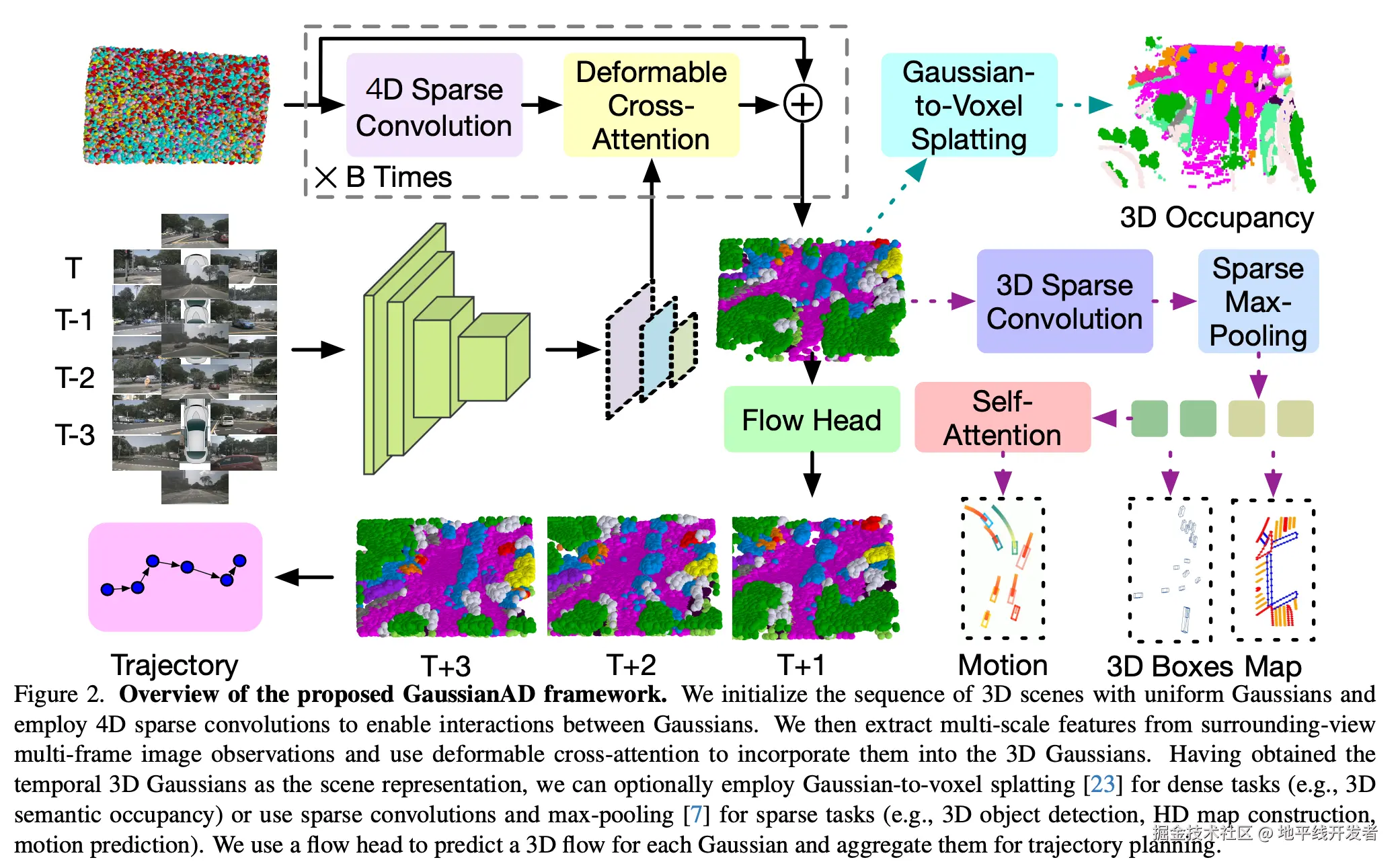
GaussianAD 用均匀的高斯序列初始化 3D 场景,并使用 4D 稀疏卷积来实现高斯之间的交互。然后从环视多帧图像提取多尺度特征,并使用可变形的交叉注意力将它们纳入 3D 高斯。在获得时间 3D 高斯作为场景表示后,可以选择使用对密集任务的高斯到体素 splatting(例如,3D 语义占用),或者使用稀疏卷积和最大池化进行稀疏任务(例如,3D 目标检测、高清地图构建、运动预测)。GaussianAD 使用 flow 头来预测每个高斯的 3D 流,并将其汇总用于轨迹规划。
2.2.1 3D 高斯场景表示
现有特征表示方法的不足
现有方法通常构建密集的 3D 特征来表示周围环境,并处理具有相等存储和计算资源的每个 3D 体素,这通常会因为资源分配不合理而导致难以解决的开销。与此同时,这种密集的 3D 体素表示无法区分不同比例的目标。
高斯表示的优势
高斯表示以均匀分布的 3D 高斯初始化场景,通过多视角图像逐步优化高斯参数(均值、协方差、语义),生成稀疏的 3D 语义高斯集合。每个高斯单元描述局部区域的几何和语义属性。高斯混合模型能近似复杂场景,稀疏性减少冗余计算,同时保留细粒度 3D 结构,极大地促进下游任务的性能提升。
感知任务
- 高斯特征提取
GaussianAD 首先将 3D 高斯及其高维查询表示为可学习的向量。然后,我们使用高斯编码器来迭代地回放这些表示。每个高斯编码器块由三个模块组成:一个促进高斯之间交互的自编码模块,一个用于聚合视觉信息的图像交叉关注模块,以及一个用于微调高斯属性的细化模块。与 GaussianFormer 不同,GaussianAD 使用由 4D 稀疏卷积组成的时间编码器,将上一帧的高斯特征与当前帧中的相应特征集成。
- 稀疏 3D 目标检测
提取到稀疏高斯特征后,采用 VoxelNeXt 根据稀疏体素特征预测 3D 目标。使用 3D 稀疏 CNN 网络来编码 3D 高斯表示,一组 Agent Tokens 来解码 3D 动态物体边界框。
- 稀疏语义地图构建
使用一组 Map Tokens 生成车道、边界等静态元素。
预测与规划
- 高斯流预测:基于当前高斯状态和规划轨迹,预测未来帧的高斯分布,通过仿射变换模拟自车运动后的观测场景。
- 轨迹规划:结合预测的高斯流和未来场景的占用情况,优化轨迹以最小化碰撞风险与轨迹偏差。
端到端训练
- 灵活监督:支持多任务监督(3D 检测、语义地图、运动预测、占用预测),通过损失函数联合优化:
- 感知损失(检测、地图、占用)
- 预测损失(未来场景与真实观测的差异)
- 规划损失(轨迹误差与碰撞率)
- 未来场景自监督:利用未来帧的真实观测作为预测监督,增强长期一致性。
三、L(Lingustic Intelligence):定制化设计 LLM
L 模块的设计思想比较容易理解,LLM 模型是强大且通用的模型毋庸置疑,但是其使用的是互联网多模态数据资源进行训练的,数据场景和分布混乱,比如存在大量与自动驾驶无关的文史类数据,难以直接应用到自动驾驶场景中,尚不具备较强的 3D 空间理解能力、3D 空间推理能力和强大的语言能力,需要在模型的预训练阶段就要加入大量的相关数据。所以,理想汽车不计成本地从 0 开始设计和训练一个适合 VLA 的基座模型。在模型架构上还进行了稀疏化设计,减少模型容量,从而实现推理性能的提升。
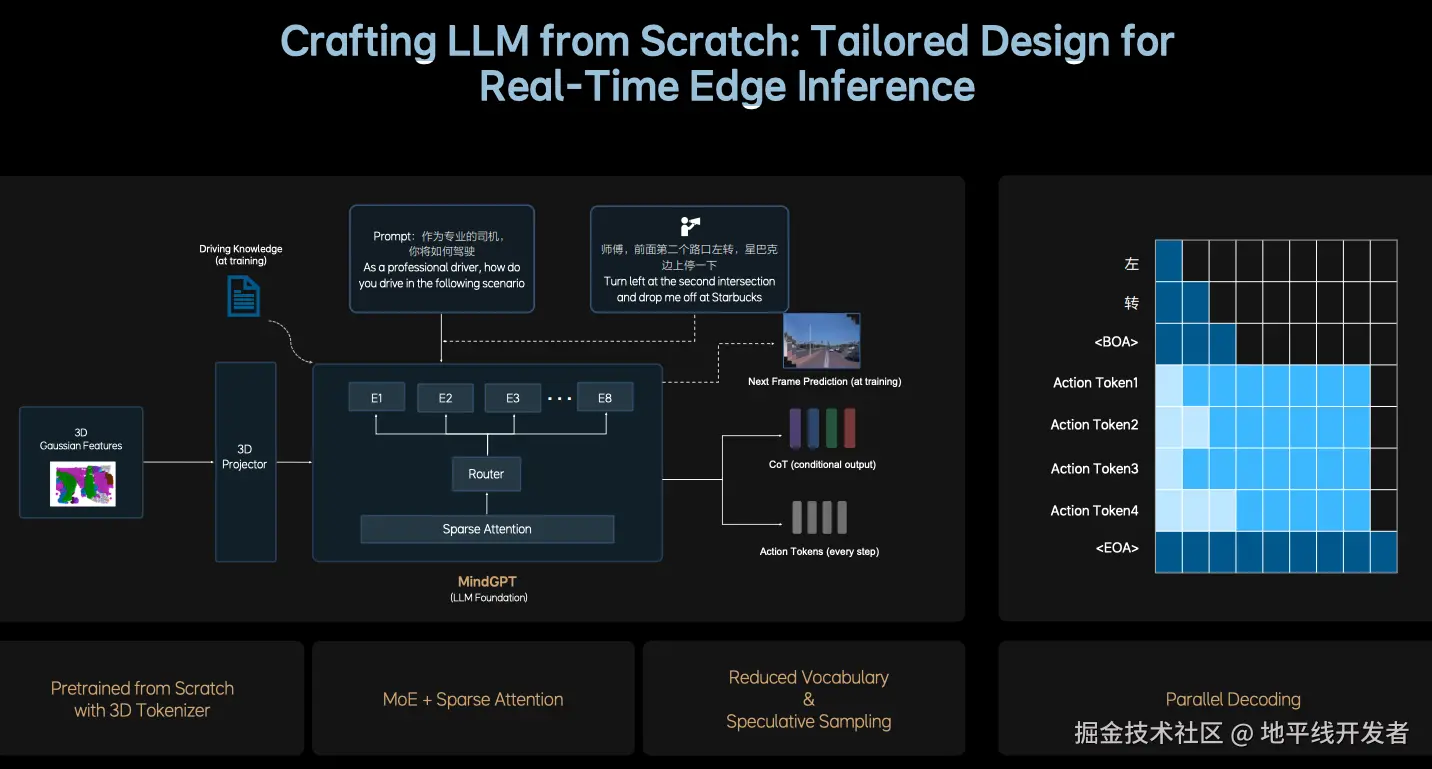
上图为 PPT 上对 L 模块的介绍,其核心设计思想可以总结为:
- 基于开源 LLM 结构,重新设计适用于智驾场景的 LLM input tokenizer;
- **稀疏化:**为了在增加模型参数量的同时平衡端侧推理速率,采用 MoE+SparseAttention 的高效结构;使用多个专家实现模型扩容,还可以保证模型参数量不会大幅度增加;引入 SparseAttention 进一步提升稀疏化率。
- **训练数据配比重构:**融入大量的 3D 场景数据和自动驾驶相关图文数据,同时降低文史类数据的比例;
- **进一步强化 3D 空间理解和推理能力:**加入未来帧的预测生成 + 稠密深度的预测;
- **提升逻辑推理能力:**人类思维模式 + 自主切换快思考慢思考,慢思考输出精简的 CoT(采用的固定简短的 CoT 模板) + 输出 action token;快思考直接输出 action token;
- **实时推理性能(10HZ):**通过以下手段压榨 OrinX 和 ThorU 的性能,在同一个 Transformer 模型中加入了两种推理模式:
- CoT 生成加速:小词表 + 投机推理(推理模式 1: 因果注意力机制 token by token 的逐字输出);
- action token 生成加速:并行解码的方式(推理模式 2: 双向注意力机制并行一次性输出);
四、A(Action Policy): 生成精细化动作
4.1 总体介绍
LLM 基座模型构建完成后,利用扩散模型 Diffusion Model 将 action token 解码为最终的轨迹,包括自车轨迹、他车和行人的轨迹,这样可以提升 VLA 模型在复杂交通环境下的博弈能力。另外,Diffusion Model 还具有根据外部的条件改变生成结果,类似于图像生成领域的多风格生成。
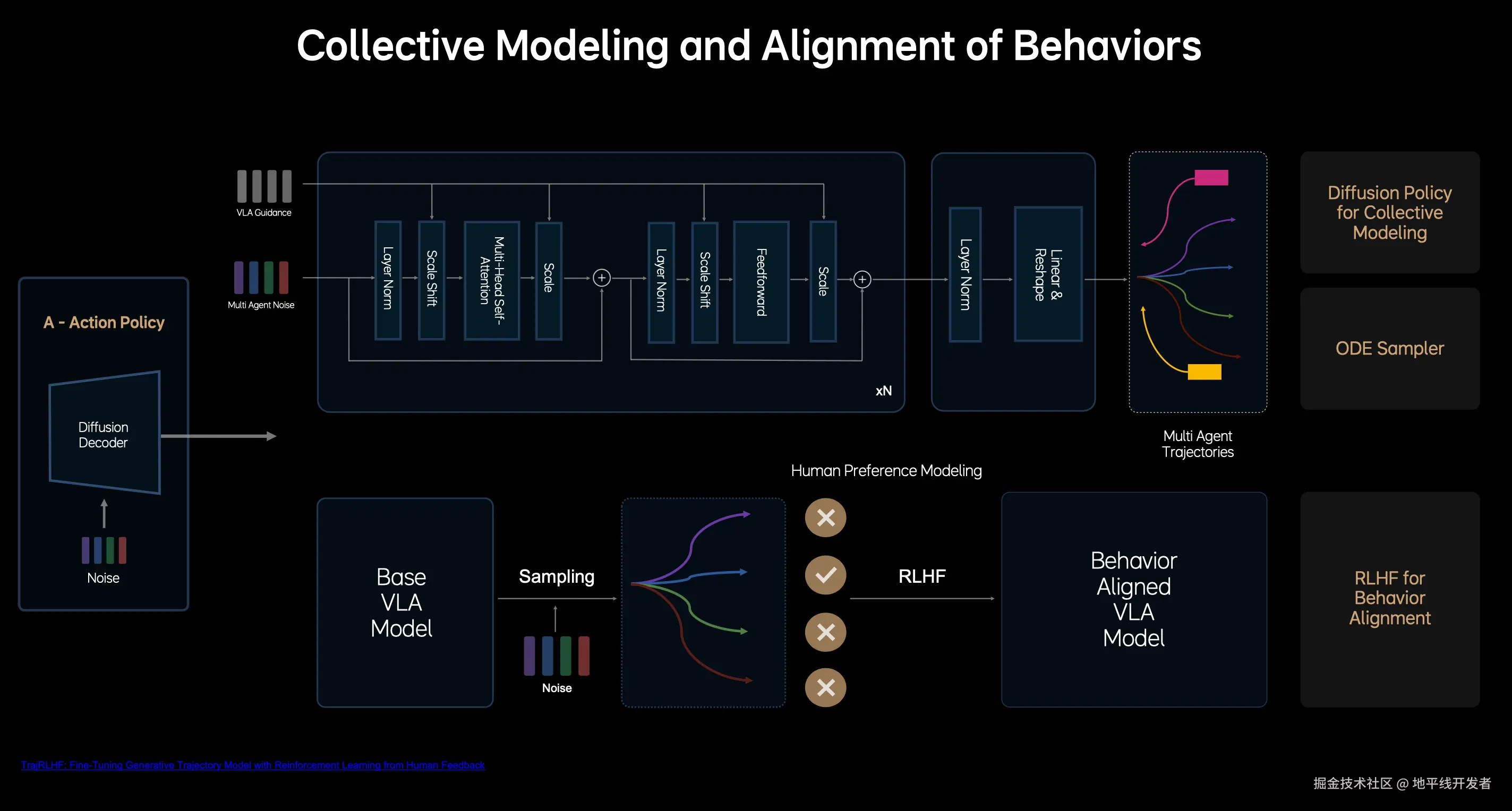
上图为 PPT 上对 V 模块的介绍,其核心设计思想可以总结为:
- 引入多层 DIT(Diffusion Transformer)结构;
- **提升生成效率:**基于常微分方程的 ode 采样器大幅的加速 diffusion 的生成过程,使其在 2~3 步内完成稳定轨迹的生成;
- **对齐人类驾驶员行为:**使用 RLHF 做后训练,通过人类偏好数据集微调模型的采样过程, 对齐专业驾驶员的行为,提高安全驾驶的下限。其中,人类偏好数据集搭建:人类驾驶数据 + NOA 的接管数据
4.2 TrajHF
TrajHF 通过 多条件去噪器生成多样化轨迹 + 人类反馈驱动的强化学习微调,解决了生成模型与人类驾驶偏好的对齐问题。其结构兼顾生成能力与个性化适配,在安全约束下实现了驾驶风格的灵活调节,为自动驾驶的"人车共驾"提供了新范式。
4.2.1 动机
- 数据集偏差:传统模仿学习(IL)仅学习数据集的平均行为,忽略人类驾驶的微妙偏好(如攻击性超车、保守跟车等)。
- 分布偏移:生成模型易受高频模式主导,难以生成低频但符合人类偏好的轨迹(如复杂交互中的适应性行为)。
- 高阶因素缺失:人类驾驶受风险容忍度、社会交互等隐性因素影响,现有模型难以编码。
4.2.2 核心思想
- 人类反馈作为监督信号:通过人类标注的轨迹排序或偏好标签,引导模型学习多样化驾驶风格。
- 强化学习微调(RLHF):将偏好转化为奖励函数,优化策略以最大化人类偏好奖励。
- 多模态生成与约束平衡:结合扩散模型生成多样化候选轨迹,通过强化学习微调对齐偏好,同时用行为克隆(BC)损失保留基础驾驶能力。
4.2.3 模型结构
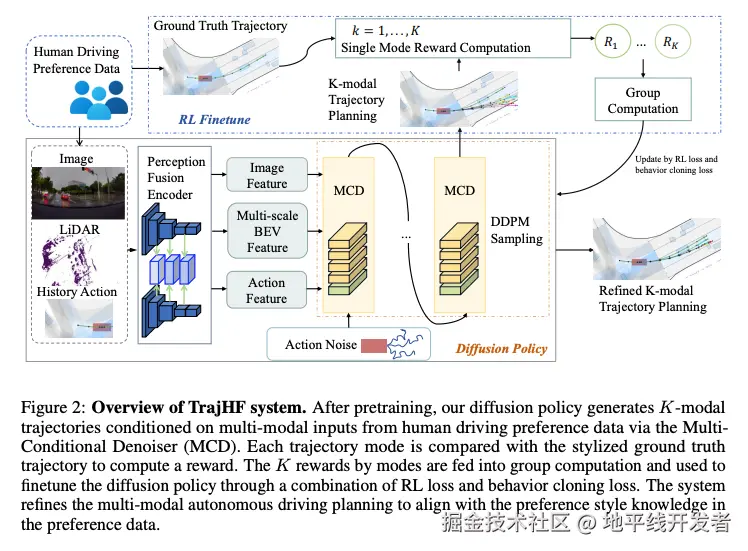
TrajHF 包括生成轨迹模型(Diffusion Policy)和 强化学习微调(RL Finetuning)这两个部分,其中 RL Finetuning 是最大化人类偏好奖励。
除了这两个部分,个人认为 TrajHF 中最重要的是偏好数据的自动构建,我们首先就来介绍这个部分。
偏好数据自动构建
偏好数据自动构建过程如下图所示,这个过程涉及用不同的驾驶风格标签标记大量驾驶数据。然而,出现了实际挑战,例如确定每个场景或框架是否需要驾驶风格标签。以下步骤概述了这些挑战和相应的解决方案。
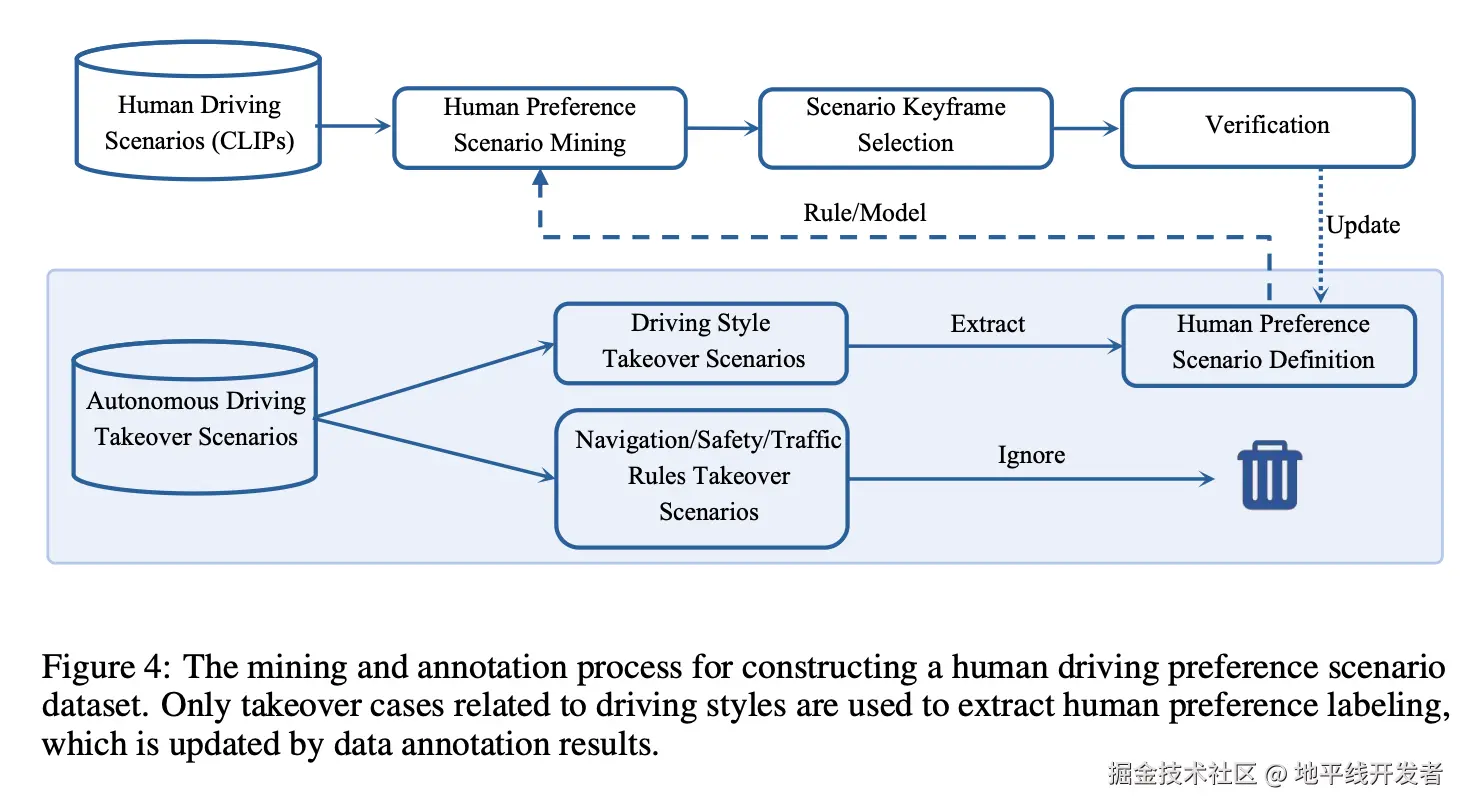
- **场景挖掘:**人类驾驶通常发生在普通环境中,这使得很难为每个决定定义特定的驾驶风格,而且手动手动注释效率低下。论文发现人类司机接管数据可以帮助识别偏好场景。这些数据分为六类(例如,"过于激进"或"过于保守"),每个类别对应不同的驾驶风格,可用于定义规则或训练模型,以识别偏好场景。
- **关键帧标注:**在确定偏好场景后,只需要标记与偏好相关的部分,专注于发生重要动作的关键帧,例如速度或方向的变化。如果帧标记过早,则定义操作尚未发生;如果标记过晚,则该操作已经开始。关键帧识别的明确规范允许基于规则的自动检测,从而实现潜在的大规模注释。
- **手动检查:**注释的关键帧经过随机手动检查,以确保数据质量。人工检查员可以在特殊情况下更新场景定义或引入新的偏好场景。
Diffusion Policy
Diffusion Policy 的核心组件是多条件去噪器(Multi-Conditional Denoiser, MCD),它的工作过程如下:
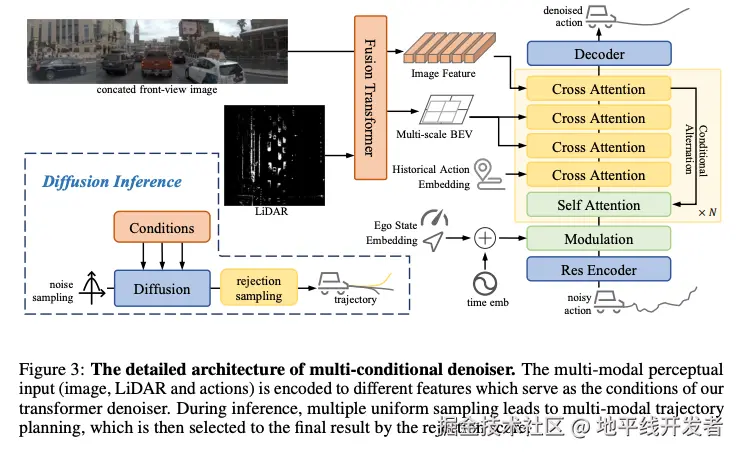
- 输入:多模态感知数据;
- 轨迹表示:将轨迹 转换为动作空间,减少时间异方差性。
- 去噪过程:
- 噪声动作经 MLP 编码,与状态/时间嵌入融合。
- 图像与激光雷达特征通过骨干网络(ViT + ResNet34)提取,经融合 Transformer 交互生成 BEV 特征。
- 条件与噪声动作通过交叉注意力模块迭代去噪。
- 输出:生成 K 条多模态候选轨迹(8 个航迹点,覆盖 4 秒)。
RL Finetuning
RL Finetuning 的目标是最大化人类偏好奖励,主要包括奖励计算和策略优化两个步骤,其中涉及较多数学计算,感兴趣的同学可以自行研读论文。

参考资料
zhuanlan.zhihu.com/p/188598833...
GaussianAD: Gaussian-Centric End-to-End Autonomous Driving
Finetuning Generative Trajectory Model with Reinforcement Learning from Human Feedback