还在当一线开发的时候,我最怕半夜接到电话,说:线上出问题了!!!。
那时候我们对线上环境几乎是两眼一抹黑。一个功能发布后,它在线上跑得快不快、有没有报错、用户到底喜不喜欢用,我们一概不知。出了问题,只能靠用户反馈和后端模糊的日志,排查效率极低,过程也极其痛苦。
当了组长后,我下定决心,必须改变这种被动救火的局面,能实时地看到线上应用的健康状况。
所以,我花了几个月的时间,搭建了一套前端监控体系。这篇文章,就是我们团队这套监控体系的实战总结。它主要分为三大块,回答三个核心问题:
- 性能监控:我们的网站快吗?
- 异常监控:我们的网站稳定吗?
- 行为监控:用户在我们网站上做了什么?
性能监控
监控什么?
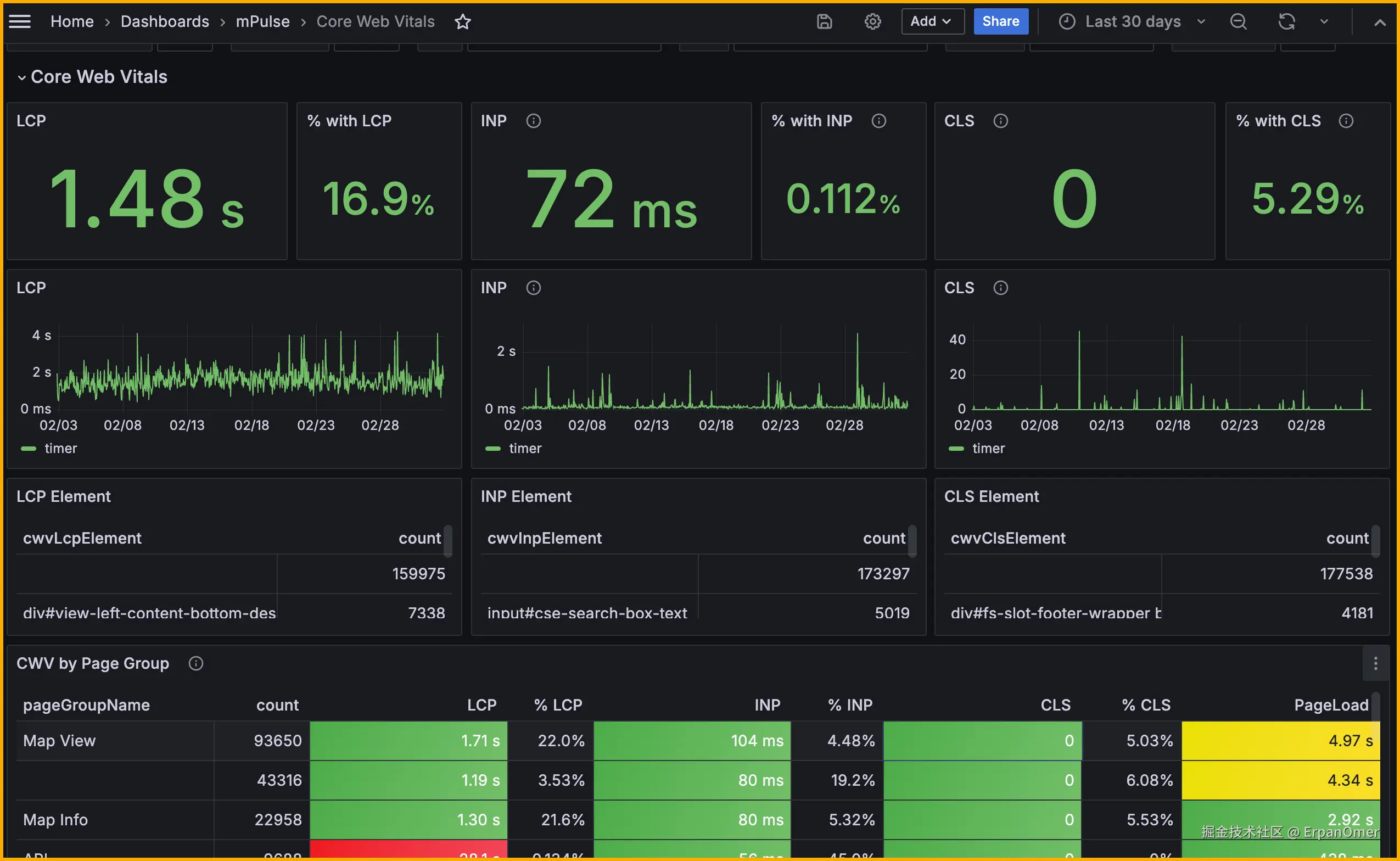
性能指标有很多,但我们初期应该聚焦在 核心Web指标(Core Web Vitals) 上,这是Google官方定义的、直接关系到用户体验的三个核心指标。
- LCP (Largest Contentful Paint) :最大内容绘制。衡量加载性能。简单说,就是用户看到页面主要内容花了多久。
- INP (Interaction to Next Paint) :下次绘制前交互。衡量交互性能。这是2024年取代FID的新指标,衡量用户点击、输入等操作后,页面给出视觉反馈的速度。
- CLS (Cumulative Layout Shift) :累积布局偏移。衡量视觉稳定性。比如页面加载时,图片突然出现导致下方按钮被挤下去,就是一次不好的CLS。
怎么实现?
我们没有重复造轮子,直接选用了Google官方的小型库web-vitals来采集指标。
-
第一步:安装
bashpnpm add web-vitals -
第二步:在你的应用入口处(如
main.js)进行采集javascriptimport { onLCP, onINP, onCLS } from 'web-vitals'; // 封装一个上报函数 function sendToAnalytics(metric) { // 这里是你把数据发送到自己后端服务的逻辑 // 为了保证数据在页面关闭前也能成功发送,强烈建议使用 navigator.sendBeacon const body = JSON.stringify({ [metric.name]: metric.value }); const url = "/your/analytics/endpoint"; if (navigator.sendBeacon) { navigator.sendBeacon(url, body); } else { fetch(url, { body, method: 'POST', keepalive: true }); } } // 采集并上报 onLCP(sendToAnalytics); onINP(sendToAnalytics); onCLS(sendToAnalytics); -
第三步:后端接收与展示 你需要一个简单的后端服务来接收这些数据,并存入数据库。然后通过可视化工具(如Grafana)来展示性能大盘。
异常监控
监控什么?
- JS运行时错误 :代码里的逻辑错误,比如
cannot read property 'xxx' of undefined。 - Promise异步错误 :
Promise中未被catch的reject。 - 静态资源加载错误:JS、CSS、图片等资源加载失败。
- 白屏错误:这是一个比较难定义,但非常致命的错误。
怎么实现?
异常监控的体系非常复杂,涉及到错误捕获、堆栈解析、SourceMap还原、上报、聚合、告警等一整套流程。这块我们坚决不自己造轮子,直接选择了成熟的开源方案:Sentry。
-
第一步:接入Sentry SDK
bashpnpm add @sentry/browser @sentry/tracing -
第二步:在应用入口处初始化
javascriptimport * as Sentry from "@sentry/browser"; import { BrowserTracing } from "@sentry/tracing"; Sentry.init({ dsn: "你在Sentry官网上获取的DSN地址", integrations: [new BrowserTracing()], // 我们只关心生产环境的错误 environment: 'production', // 设置性能监控的采样率 tracesSampleRate: 0.1, // 10%的页面会采集性能数据 });只需要这几行代码,Sentry就会自动帮我们监听全局的JS错误、Promise异常和资源加载异常。
-
第三步(最重要的一步):上传Source Map
Source Map是异常监控的灵魂。 没有它,你Sentry上看到的错误堆栈,就是一堆经过压缩混淆的、毫无意义的天书。
我强制要求我们团队的CI/CD流程,必须在每次生产构建后,自动将Source Map上传到Sentry 。这可以通过Sentry官方的
sentry-cli或Webpack/Vite插件来完成。
具体怎么使用网上有不少教程,可以参考这位博主的👉 bug 追踪系统 Sentry (4) -- 关联 sourceMap
行为监控
性能和稳定性保证了我们的应用 能不能用 ,而行为监控,则是为了搞清楚应用 好不好用。
监控什么?
- 基础流量:PV(页面浏览量)、UV(独立访客数)、用户停留时长等。
- 用户转化漏斗:比如"访问商品页 -> 点击加入购物车 -> 进入结算页 -> 支付成功"这一整个流程中,每一步的用户流失率是多少。
- 功能使用率:某个按钮的点击次数、某个功能的渗透率等。
2. 怎么实现?
这块的选择很多,从免费的Google Analytics,到更专业的Mixpanel、Amplitude。
但无论用什么工具,作为组长,我要求团队在代码层面,必须遵守一个原则:封装一个统一的埋点(tracking)函数。
-
第一步:封装一个
tracker.jsjavascript// src/utils/tracker.js /** * 统一的埋点上报函数 * @param {string} eventName 事件名称 * @param {object} properties 事件属性 */ export function trackEvent(eventName, properties = {}) { // 可以在开发环境下打印,方便调试 if (process.env.NODE_ENV === 'development') { console.log(`[Track Event]: ${eventName}`, properties); } // 在这里,你可以接入任何第三方或自研的埋点SDK // 比如 Google Analytics // window.gtag?.('event', eventName, properties); // 比如 Mixpanel // window.mixpanel?.track(eventName, properties); } -
第二步:在业务组件中调用
jsximport { trackEvent } from '@/utils/tracker'; function AddToCartButton({ productId }) { const handleClick = () => { // 业务逻辑... // 调用统一的埋点函数 trackEvent('click_add_to_cart', { productId, from: 'product_detail_page' }); }; return <button onClick={handleClick}>加入购物车</button>; }
为什么要封装? 因为这样能让我们的业务代码,和具体的埋点SDK实现解耦 。未来如果我们想从Google Analytics切换到Mixpanel,我们只需要修改tracker.js这一个文件,而不需要去改动散落在项目里成百上千个业务组件。
搭建监控体系,终点不是收集数据和看报表,而是驱动行动。
搭建这套体系,让我们的团队工作模式,真正从靠感觉猜,升级到了靠数据 处理特定问题。虽然过程很麻烦,但每一分投入,都非常值得。
分享完毕 谢谢大家