17. 条件随机场(Conditional Random Field,CRF)
17.1. 背景
机器学习分类模型中,有硬分类 和软分类两种主流思想,其中硬分类模型有支持向量机SVM(最大化几何间隔)、感知机PLA(误差驱动优化)、线性判别分析LDA(类间大,类内小)等,通过严格的决策边界来区分多类样本;而软分类模型有逻辑回归(及Softmax回归等)和朴素贝叶斯模型等。
同时机器学习分类模型也有概率生成模型和概率判别模型两种思想:
- 软分类中的逻辑回归是概率判别模型 ,优化思想是最大熵(见另一篇笔记机器学习 白板推导(六)8.4.,给定均值和方差而无其他信息时,熵值最大的分布是高斯分布,同时最大熵思想是使模型贴近已有样本,而样本无法提供的信息使其尽量服从高斯分布)。
- 朴素贝叶斯是概率生成模型,并从中衍生出了隐马尔可夫模型(可以看做时序版本的朴素贝叶斯,同时认为每个观测变量每个时刻都有一个隐状态,为了求解这个隐状态,引入了齐次马尔可夫假设和观测独立假设)。
从软分类的概率生成模型和概率判别模型的研究成果中,结合了最大熵思想和隐马尔可夫模型的优点,诞生了最大熵马尔可夫模型(Maximum Entropy Markov Model,MEMM) ,这是一个概率判别模型,即求解的问题是 P ( Y ∣ X ) P(Y|X) P(Y∣X),同时是一种新的马尔可夫模型,其引入了一个全局变量,使得观测独立假设被打破,这在实际问题中更加合理,样本信息被更多地利用。
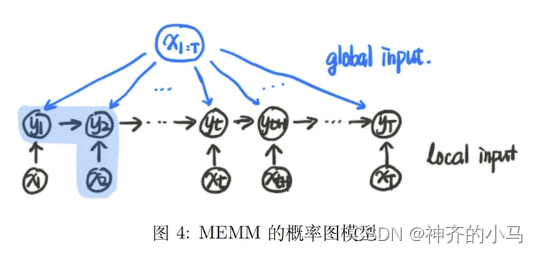
上述图中阴影部分为MEMM求解过程的的一个步骤,即 P ( y 2 ∣ x 2 , y 1 ) P(y_2|x_2,y_1) P(y2∣x2,y1),但这样的条件概率求出以后需要进行归一化才能使其符合概率分布特性(求和为1),这样的操作为局部归一化,但每次归一化时没有考虑全局信息,会导致标签偏差问题(Label Bias Problem),而将MEMM的概率图模型变为无向图即可解决这个问题,因此诞生了条件随机场CRF。
标签偏差问题是在Learning问题有效收敛的前提下,decoding任务中出现了明显偏差的现象,因为MEMM和CRF中的隐状态常常是标签(用 y t y_t yt 表示,例如词性标注中具体词语是观测变量,词性如名词、动词、形容词为隐变量),因此叫做标签偏差问题
举例来说:
- 在经典的John Lafferty论文中的例子是:
- 假如样本数据有15个 r → i → d r→i→d r→i→d,5个 r → o → d r→o→d r→o→d,忽视发射矩阵,仅考虑状态转移,那么在Learning阶段,理想的概率图模型应该如下图所示,此时在decoding阶段,给定观测变量 r → o → d r→o→d r→o→d,得到 i 2 → i 4 → i 5 i_2→i_4→i_5 i2→i4→i5 的隐变量序列。
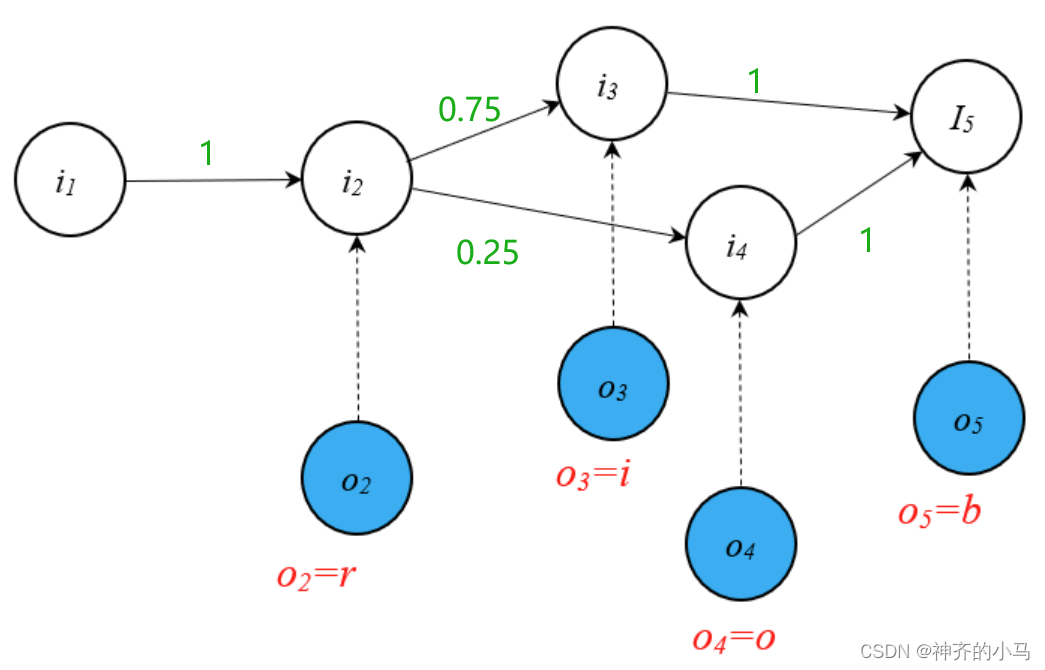
- 但如果在o2位置有更多的隐变量取值空间,则Learning阶段可能学习到下图所示的,则在decoding阶段给定观测变量 r → o → d r→o→d r→o→d 时,会在第一步走向 i 1 i_1 i1 的路径,从而得到 i 1 → i 3 → i 5 i_1→i_3→i_5 i1→i3→i5 的隐变量序列,这显然是不正确的。
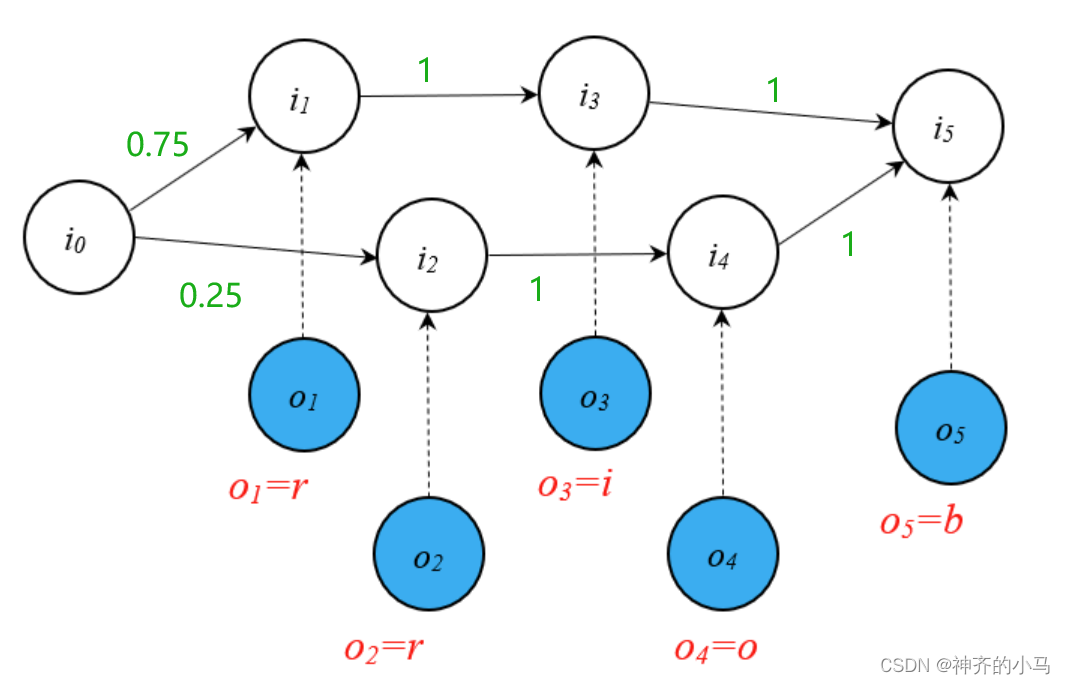
- 假如样本数据有15个 r → i → d r→i→d r→i→d,5个 r → o → d r→o→d r→o→d,忽视发射矩阵,仅考虑状态转移,那么在Learning阶段,理想的概率图模型应该如下图所示,此时在decoding阶段,给定观测变量 r → o → d r→o→d r→o→d,得到 i 2 → i 4 → i 5 i_2→i_4→i_5 i2→i4→i5 的隐变量序列。
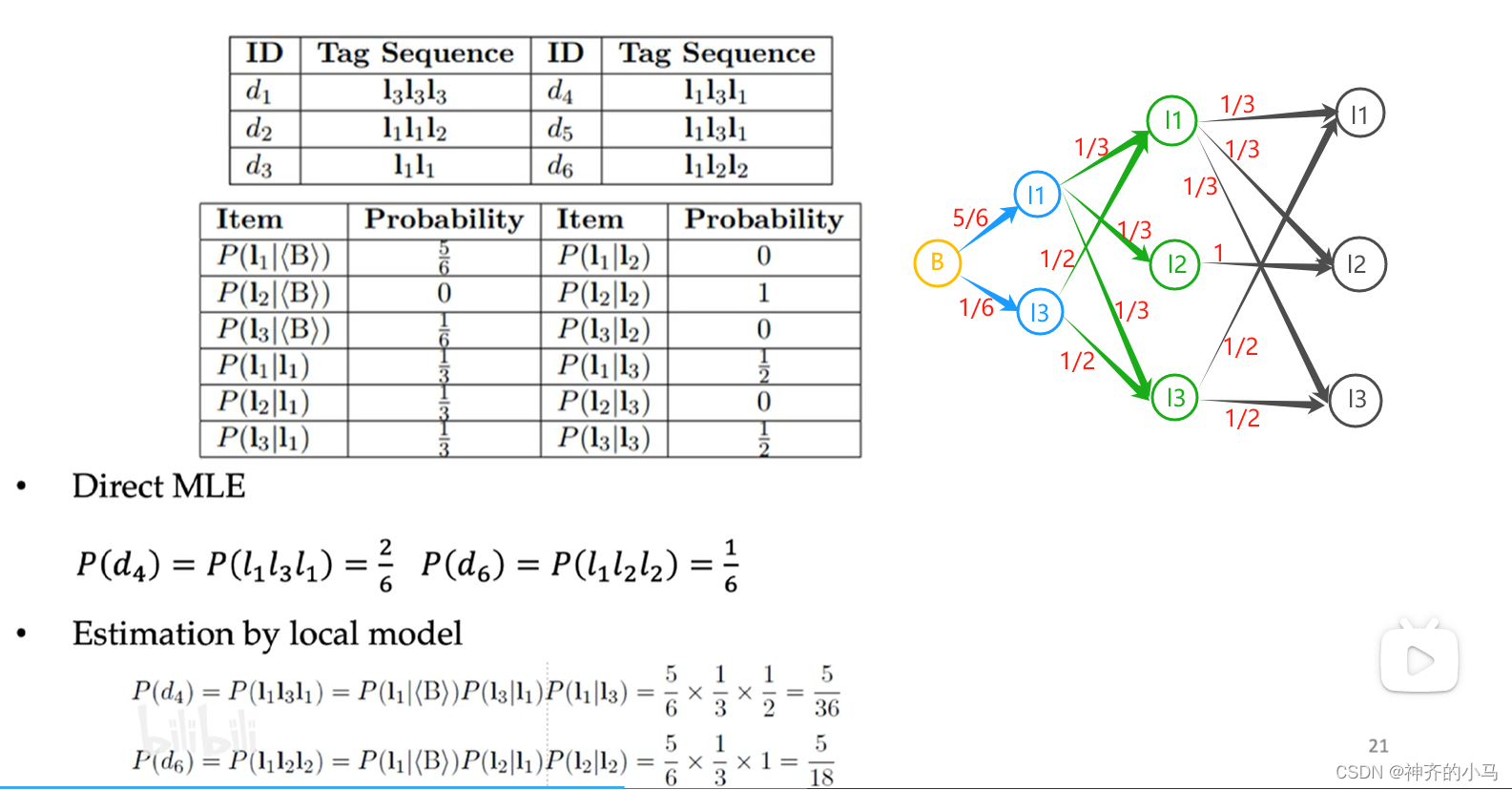
- 西湖大学NLP课程中给出例子为:如下图,根据频率统计,d4出现了2次,比d6频率更高,但根据维特比算法求出二者的概率,却是d6比d4概率高,因为l3有两种转移的可能,即便两种可能出现的频率更高(l2→l1有2次,l3→l3有2次),但经过归一化后都为0.5的概率值,而l2只有一种转移的可能,即便出现频率低(只有l2→l2有1次),但经过归一化后概率值依然为1,因此d6算得的概率更高,这种现象本质上是局部归一化导致的。
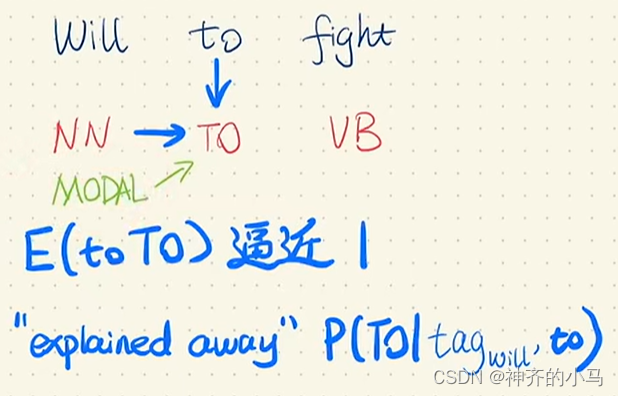
- Toutanova在论文中也讨论了标签偏差现象的原因,提出有一种情况是发射概率过高,例如下图同样是词性标注问题,Will to fight是句子,是观测变量,NN MODAL TO VB是词性(NN指名词,MODAL指情态动词,TO指to专属词性,VB指动词),而MEMM在decoding任务中需要计算的是,而因为TO是to的专属词性,因此只要见到t时刻观测变量为to即可直接标注词性为TO,无需纳入前一时刻Will的词性作为考虑,这样的模型Learning阶段会无法学习到NN→TO和MODAL→TO之间的状态转移关系,而事实上情态动词后面是基本不搭配to的,因此对Will的词性出现了标签偏差问题,这样的问题本质上也是对to→TO的发射概率进行了局部归一化所导致。
因此CRF将MEMM改为无向图连接,使得局部归一化变为了全局归一化,解决了标签偏差问题,同时打破了齐次马尔可夫假设,使得模型更加有效地利用信息。
17.2. CRF的概率密度函数------Decoding
17.2.1. 无向图模型的概率密度函数
团:对于一个无向图,其中某个子图满足各个节点相互连通,则作为原无向图的一个团,而对于一个团,若其无法添加一个新节点使其变为一个更大的团(也不能等于原无向图),则称为最大团。
概率因子分解法:
- 对于一个无向图形式的概率图模型,要求解其概率密度函数时,常常用到概率因子分解法,具体来说是找到图模型的所有最大团,对每个最大团求解势函数,相乘并归一化得到概率密度函数。
- 公式:设概率图模型中所有变量集合为 X = { x 1 , x 2 , ⋯ , x m } X=\{ x_1,x_2,\cdots,x_m\} X={x1,x2,⋯,xm},每个 x i x_i xi 为一个节点,对图划分得到 K K K个最大团 C = { c 1 , ⋯ , c K } C=\{ c_1,\cdots,c_K \} C={c1,⋯,cK},每个团的势函数为 Ψ i ( x j ∈ c i ) \Psi i(x_j\in c_i) Ψi(xj∈ci),则联合概率密度为 P ( X ) = 1 Z ∏ i = 1 K Ψ i ( x j ∈ c i ) P(X)=\frac{1}{Z}\prod{i=1}^K\Psi_i(x_j\in c_i) P(X)=Z1∏i=1KΨi(xj∈ci),其中归一化因子 Z = ∫ X ∏ i = 1 K Ψ i ( x j ∈ c i ) d X Z=\int_X \prod_{i=1}^K\Psi_i(x_j\in c_i)\ dX Z=∫X∏i=1KΨi(xj∈ci) dX.
- 举例:
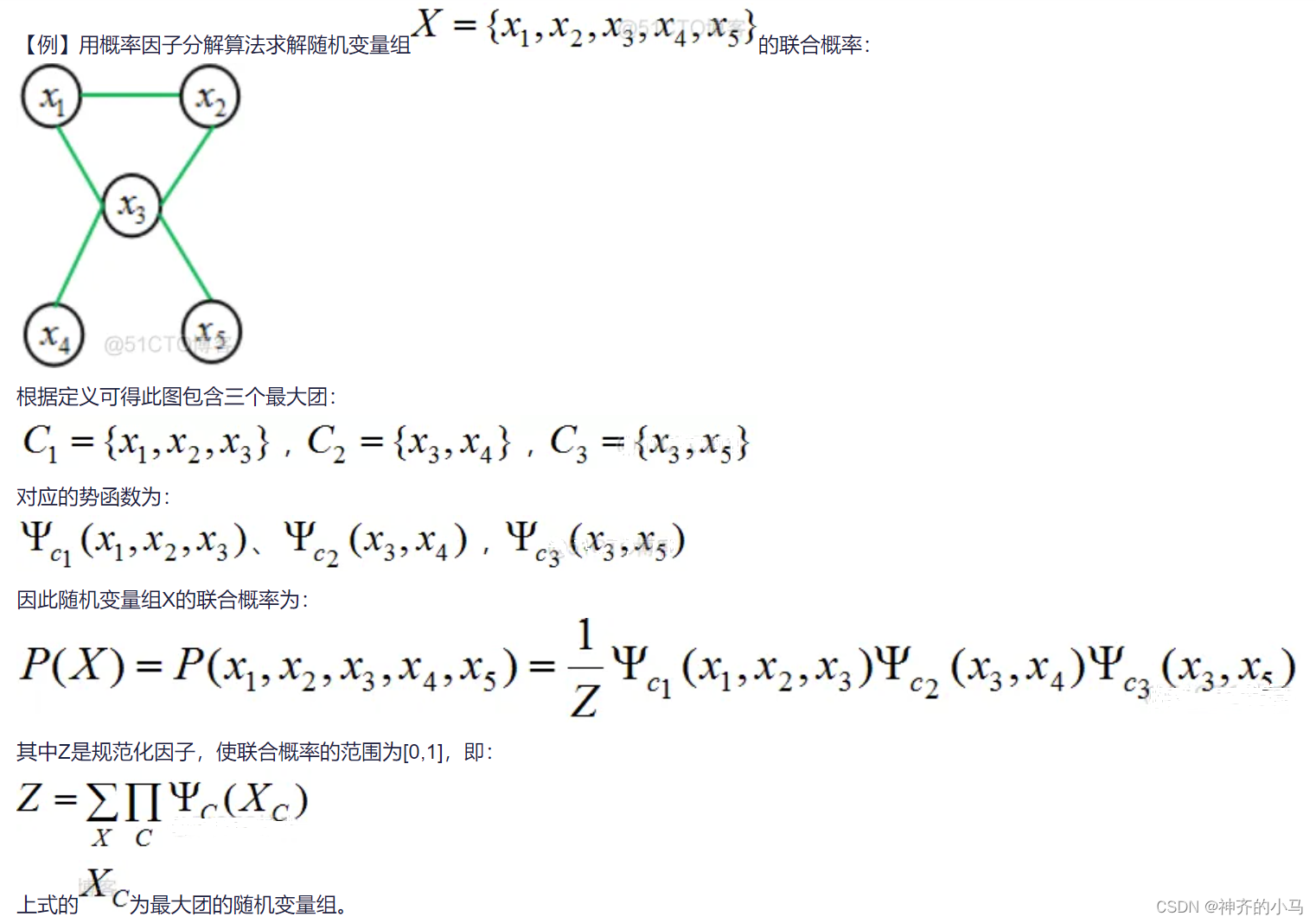
可以进一步简化概率因子分解的公式: P ( X ) = 1 Z ∏ i = 1 K Ψ i ( x j ∈ c i ) = 1 Z ∏ i = 1 K exp { − E i ( x j ∈ c i ) } P(X)=\frac{1}{Z}\prod_{i=1}^K\Psi_i(x_j\in c_i)=\frac{1}{Z}\prod_{i=1}^K\exp\{-E_i(x_j\in c_i)\} P(X)=Z1∏i=1KΨi(xj∈ci)=Z1∏i=1Kexp{−Ei(xj∈ci)},其中 E ( x ) E(x) E(x) 为能量函数,再设 F ( x ) = − E ( x ) F(x)=-E(x) F(x)=−E(x),则 P ( X ) = 1 Z ∏ i = 1 K exp { F i ( x j ∈ c i ) } = 1 Z exp ∑ i = 1 K { F i ( x j ∈ c i ) } P(X)=\frac{1}{Z}\prod_{i=1}^K\exp\{F_i(x_j\in c_i)\}=\frac{1}{Z}\exp\left \\sum_{i=1}\^K\\{F_i(x_j\\in c_i)\\} \\right P(X)=Z1∏i=1Kexp{Fi(xj∈ci)}=Z1exp∑i=1K{Fi(xj∈ci)}.
17.2.2. CRF的概率密度函数(参数形式)
下图是一个典型的CRF概率图,其中每个最大团是 c t = { y t − 1 , y t , x 1 : T } c_t=\{ y_{t-1},y_t,x_{1:T} \} ct={yt−1,yt,x1:T},三个节点组成。
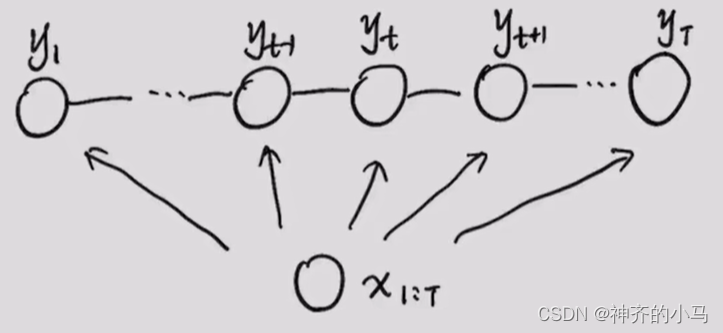
由概率因子分解可得, P ( Y ∣ X ) = 1 Z exp ∑ t = 1 T { F t ( y t − 1 , y t , x 1 : T } P(Y|X)=\frac{1}{Z}\exp\left \\sum_{t=1}\^T\\{F_t(y_{t-1},y_t,x_{1:T}\\} \\right P(Y∣X)=Z1exp∑t=1T{Ft(yt−1,yt,x1:T},因为decoding问题中观测变量 x 1 : T x_{1:T} x1:T 给定,则可以写作 F t ( y t − 1 , y t , x 1 : T ) = F ( y t − 1 , y t ) = F a ( y t − 1 ) + F b ( y t ) + F c ( y t − 1 , y t ) F_t(y_{t-1},y_t,x_{1:T})=F(y_{t-1},y_t)=F_a(y_{t-1})+F_b(y_{t})+F_c(y_{t-1},y_t) Ft(yt−1,yt,x1:T)=F(yt−1,yt)=Fa(yt−1)+Fb(yt)+Fc(yt−1,yt).
由于在计算 F t F_t Ft 时, y t − 1 y_{t-1} yt−1 已知,所以只关注 F b ( y t ) F_b(y_{t}) Fb(yt) 和 F c ( y t − 1 , y t ) F_c(y_{t-1},y_t) Fc(yt−1,yt);其中 F b ( y t ) F_b(y_{t}) Fb(yt) 所表达的信息比较类似HMM中的发射矩阵,而 F c ( y t − 1 , y t ) F_c(y_{t-1},y_t) Fc(yt−1,yt) 类似状态转移矩阵,可以通过这个思路来设计合理的函数使得模型更加合理和有效,例如设 F b ( y t ) = ∑ i = 1 K η i ⋅ g i ( y t ) F_b(y_t)=\sum_{i=1}^K\eta_i\cdot g_i(y_t) Fb(yt)=∑i=1Kηi⋅gi(yt), F a ( y t − 1 ) + F c ( y t − 1 , y t ) = ∑ i = 1 L λ i ⋅ f i ( y t − 1 , y t ) F_a(y_{t-1})+F_c(y_{t-1},y_t)=\sum_{i=1}^L\lambda_i\cdot f_i(y_{t-1},y_t) Fa(yt−1)+Fc(yt−1,yt)=∑i=1Lλi⋅fi(yt−1,yt),其中根据应用场景设计 f i ( ⋅ ) f_i(\cdot) fi(⋅) 和 g i ( ⋅ ) g_i(\cdot) gi(⋅),而将 λ i \lambda_i λi 和 η i \eta_i ηi 作为可学习参数,这就完成参数形式的概率密度函数。
整理参数形式的概率密度函数为:
P ( Y ∣ X ) = 1 Z exp { ∑ t = 1 T ∑ i = 1 K η i ⋅ g i ( y t ) + ∑ i = 1 L λ i ⋅ f i ( y t − 1 , y t ) } = 1 Z exp { ∑ t = 1 T η ⃗ T ⋅ g ⃗ ( y t ) + λ ⃗ T ⋅ f ⃗ ( y t − 1 , y t ) } , (17.1) \begin{aligned} P(Y|X)&=\frac{1}{Z}\exp\left \{\sum_{t=1}^T\left \\sum_{i=1}\^K\\eta_i\\cdot g_i(y_t)+\\sum_{i=1}\^L\\lambda_i\\cdot f_i(y_{t-1},y_t) \\right \right \}\\ &=\frac{1}{Z}\exp\left \{\sum_{t=1}^T\left \\vec{\\eta}\^T\\cdot \\vec{g}(y_t)+\\vec{\\lambda}\^T\\cdot \\vec{f}(y_{t-1},y_t) \\right \right \},\tag{17.1} \end{aligned} P(Y∣X)=Z1exp{t=1∑Ti=1∑Kηi⋅gi(yt)+i=1∑Lλi⋅fi(yt−1,yt)}=Z1exp{t=1∑Tη T⋅g (yt)+λ T⋅f (yt−1,yt)},(17.1)其中 η ⃗ = { η 1 , η 2 , ⋯ , η K } T \vec{\eta}=\{ \eta_1,\eta_2,\cdots,\eta_K \}^T η ={η1,η2,⋯,ηK}T, g ⃗ ( ⋅ ) = { g 1 ( ⋅ ) , g 2 ( ⋅ ) , ⋯ , g K ( ⋅ ) } T \vec{g}(\cdot)=\{g_1(\cdot),g_2(\cdot),\cdots,g_K(\cdot) \}^T g (⋅)={g1(⋅),g2(⋅),⋯,gK(⋅)}T, λ ⃗ \vec{\lambda} λ 和 f ⃗ ( ⋅ ) \vec{f}(\cdot) f (⋅) 同理.
17.3. CRF的边缘概率密度------Smoothing
在Decoding中求出概率密度函数 P ( Y ∣ X ) P(Y|X) P(Y∣X),还需要求解边缘概率密度函数 P ( y t ∣ X ) P(y_t|X) P(yt∣X),先直接写出公式
P ( y t ∣ X ) = ∫ y 1 , ⋯ , y t − 1 , y t + 1 , ⋯ , y T P ( Y ∣ X ) = ∫ y 1 , ⋯ , y t − 1 , y t + 1 , ⋯ , y T 1 Z ∏ i = 1 T Ψ i ( y i − 1 , y i , X ) , (17.2) \begin{aligned} P(y_t|X)&=\int_{y_{1},\cdots,y_{t-1},y_{t+1},\cdots,y_T}P(Y|X)\\ &=\int_{y_{1},\cdots,y_{t-1},y_{t+1},\cdots,y_T}\frac{1}{Z}\prod_{i=1}^T\Psi_i(y_{i-1},y_i,X),\tag{17.2} \end{aligned} P(yt∣X)=∫y1,⋯,yt−1,yt+1,⋯,yTP(Y∣X)=∫y1,⋯,yt−1,yt+1,⋯,yTZ1i=1∏TΨi(yi−1,yi,X),(17.2)
这个连乘与积分的计算是非常复杂的(指数级时间复杂度),需要使用动态规划方法递推求解。
拆解 P ( y t ∣ X ) = ∫ y 1 , ⋯ , y t − 1 ∫ y t + 1 , ⋯ , y T 1 Z ∏ i = 1 T Ψ i ( y i − 1 , y i , X ) P(y_t|X)=\int_{y_{1},\cdots,y_{t-1}}\int_{y_{t+1},\cdots,y_T}\frac{1}{Z}\prod_{i=1}^T\Psi_i(y_{i-1},y_i,X) P(yt∣X)=∫y1,⋯,yt−1∫yt+1,⋯,yTZ1∏i=1TΨi(yi−1,yi,X),则可以令 α t ( y t ) = ∫ y 1 , ⋯ , y t − 1 ∏ i = 1 t Ψ i ( y i − 1 , y i , X ) \alpha_t(y_t)=\int_{y_{1},\cdots,y_{t-1}}\prod_{i=1}^t\Psi_i(y_{i-1},y_i,X) αt(yt)=∫y1,⋯,yt−1∏i=1tΨi(yi−1,yi,X), β t ( y t ) = ∫ y t + 1 , ⋯ , y T ∏ i = t + 1 T Ψ i ( y i − 1 , y i , X ) \beta_t(y_t)=\int_{y_{t+1},\cdots,y_{T}}\prod_{i=t+1}^T\Psi_i(y_{i-1},y_i,X) βt(yt)=∫yt+1,⋯,yT∏i=t+1TΨi(yi−1,yi,X),因此 P ( y t = i ∣ X ) = α t ( i ) ⋅ β t ( i ) P(y_t=i|X)=\alpha_t(i)\cdot \beta_t(i) P(yt=i∣X)=αt(i)⋅βt(i).
建立递推关系(也是一种前向后向算法):
α t ( y t ) = ∫ y 1 , ⋯ , y t − 1 ∏ i = 1 t Ψ i ( y i − 1 , y i , X ) = ∫ y t − 1 Ψ t ( y t − 1 , y t , X ) ∫ y t − 2 Ψ t − 1 ( y t − 2 , y t − 1 , X ) \[ ⋯ \[ ∫ y 2 Ψ 2 ( y 1 , y 2 , X ) \[ ∫ y 1 Ψ 1 ( y 0 , y 1 , X ) ] ] ] = ∫ y t − 1 Ψ t ( y t − 1 , y t , X ) ⋅ α t − 1 ( y t − 1 ) . (17.3) \begin{aligned} \alpha_t(y_t)&=\int_{y_{1},\cdots,y_{t-1}}\prod_{i=1}^t\Psi_i(y_{i-1},y_i,X) \\ &=\int_{y_{t-1}}\Psi_t(y_{t-1},y_t,X)\left \\int_{y_{t-2}}\\Psi_{t-1}(y_{t-2},y_{t-1},X)\\left \[ \\cdots\\left \[ \\int_{y_{2}}\\Psi_2(y_{1},y_2,X)\\left \[ \\int_{y_{1}}\\Psi_1(y_{0},y_1,X) \\right \right ] \right ] \right ] \\ &=\int_{y_{t-1}}\Psi_t(y_{t-1},y_t,X)\cdot \alpha_{t-1}(y_{t-1}) .\tag{17.3} \end{aligned} αt(yt)=∫y1,⋯,yt−1i=1∏tΨi(yi−1,yi,X)=∫yt−1Ψt(yt−1,yt,X)∫yt−2Ψt−1(yt−2,yt−1,X)\[⋯\[∫y2Ψ2(y1,y2,X)\[∫y1Ψ1(y0,y1,X)]]]=∫yt−1Ψt(yt−1,yt,X)⋅αt−1(yt−1).(17.3)
β t ( y t ) = ∫ y t + 1 , ⋯ , y T ∏ i = t + 1 T Ψ i ( y i − 1 , y i , X ) = ∫ y t + 1 Ψ t + 1 ( y t , y t + 1 , X ) ∫ y t + 2 Ψ t + 2 ( y t + 1 , y t + 2 , X ) \[ ⋯ \[ ∫ y T − 1 Ψ T − 1 ( y T − 2 , y T − 1 , X ) \[ ∫ y T Ψ T ( y T − 1 , y T , X ) ] ] ] = ∫ y t + 1 Ψ t + 1 ( y t , y t + 1 , X ) ⋅ β t + 1 ( y t + 1 ) . (17.4) \begin{aligned} \beta_t(y_t)&=\int_{y_{t+1},\cdots,y_{T}}\prod_{i=t+1}^T\Psi_i(y_{i-1},y_i,X) \\ &=\int_{y_{t+1}}\Psi_{t+1}(y_{t},y_{t+1},X)\left \\int_{y_{t+2}}\\Psi_{t+2}(y_{t+1},y_{t+2},X)\\left \[ \\cdots\\left \[ \\int_{y_{T-1}}\\Psi_{T-1}(y_{T-2},y_{T-1},X)\\left \[ \\int_{y_{T}}\\Psi_T(y_{T-1},y_T,X) \\right \right ] \right ] \right ] \\ &=\int_{y_{t+1}}\Psi_{t+1}(y_{t},y_{t+1},X)\cdot \beta_{t+1}(y_{t+1}) .\tag{17.4}\end{aligned} βt(yt)=∫yt+1,⋯,yTi=t+1∏TΨi(yi−1,yi,X)=∫yt+1Ψt+1(yt,yt+1,X)∫yt+2Ψt+2(yt+1,yt+2,X)\[⋯\[∫yT−1ΨT−1(yT−2,yT−1,X)\[∫yTΨT(yT−1,yT,X)]]]=∫yt+1Ψt+1(yt,yt+1,X)⋅βt+1(yt+1).(17.4)
17.4. CRF的参数估计------Learning
CRF的Learning就是根据已有的样本数据来最大化似然函数,即 θ = < λ ⃗ , η ⃗ > = arg max λ ⃗ , η ⃗ ∏ i = 1 N P ( Y ( i ) ∣ X ( i ) ) \theta=<\vec{\lambda},\vec{\eta}>=\underset{\vec{\lambda},\vec{\eta}}{\arg\max}\ \prod_{i=1}^NP(Y^{(i)}|X^{(i)}) θ=<λ ,η >=λ ,η argmax ∏i=1NP(Y(i)∣X(i)),等价于求对数似然函数
< λ ⃗ , η ⃗ > = arg max λ ⃗ , η ⃗ log ∏ i = 1 N 1 Z ( i ) exp { ∑ t = 1 T η ⃗ T ⋅ g ⃗ ( y t ( i ) ) + λ ⃗ T ⋅ f ⃗ ( y t − 1 ( i ) , y t ( i ) ) } = arg max λ ⃗ , η ⃗ ∑ i = 1 N { − log Z ( i ) ( X ( i ) , λ ⃗ , η ⃗ ) + ∑ t = 1 T η ⃗ T ⋅ g ⃗ ( y t ( i ) ) + λ ⃗ T ⋅ f ⃗ ( y t − 1 ( i ) , y t ( i ) ) } . (17.5) \begin{aligned} <\vec{\lambda},\vec{\eta}>&=\underset{\vec{\lambda},\vec{\eta}}{\arg\max}\ \log\prod_{i=1}^N\frac{1}{Z^{(i)}}\exp\left \{\sum_{t=1}^T\left \\vec{\\eta}\^T\\cdot \\vec{g}(y_t\^{(i)})+\\vec{\\lambda}\^T\\cdot \\vec{f}(y_{t-1}\^{(i)},y_t\^{(i)}) \\right \right \}\\ &=\underset{\vec{\lambda},\vec{\eta}}{\arg\max}\ \sum_{i=1}^N\left \{-\log Z^{(i)}(X^{(i)},\vec{\lambda},\vec{\eta})+\sum_{t=1}^T\left \\vec{\\eta}\^T\\cdot \\vec{g}(y_t\^{(i)})+\\vec{\\lambda}\^T\\cdot \\vec{f}(y_{t-1}\^{(i)},y_t\^{(i)}) \\right \right \}.\tag{17.5} \end{aligned} <λ ,η >=λ ,η argmax logi=1∏NZ(i)1exp{t=1∑Tη T⋅g (yt(i))+λ T⋅f (yt−1(i),yt(i))}=λ ,η argmax i=1∑N{−logZ(i)(X(i),λ ,η )+t=1∑Tη T⋅g (yt(i))+λ T⋅f (yt−1(i),yt(i))}.(17.5)
对上述最大化似然函数,可以使用梯度上升法逼近数值解,即
▽ λ ⃗ = ∑ i = 1 N − 1 Z ( i ) ∂ Z ( i ) ∂ λ ⃗ + ∑ i = 1 N ∑ t = 1 T f ⃗ ( y t − 1 ( i ) , y t ( i ) ) \bigtriangledown {\vec{\lambda}}=\sum{i=1}^N- \frac{1}{Z^{(i)}}\frac{\partial Z^{(i)}}{\partial \vec{\lambda}}+\sum_{i=1}^N\sum_{t=1}^T\vec{f}(y_{t-1}^{(i)},y_t^{(i)}) ▽λ =i=1∑N−Z(i)1∂λ ∂Z(i)+i=1∑Nt=1∑Tf (yt−1(i),yt(i))其中 Z ( i ) = ∫ Y exp { ∑ t = 1 T η ⃗ T ⋅ g ⃗ ( y t ( i ) ) + λ ⃗ T ⋅ f ⃗ ( y t − 1 ( i ) , y t ( i ) ) } d Y Z^{(i)}=\int_Y\exp\left\{\sum_{t=1}^T\left \\vec{\\eta}\^T\\cdot \\vec{g}(y_t\^{(i)})+\\vec{\\lambda}\^T\\cdot \\vec{f}(y_{t-1}\^{(i)},y_t\^{(i)}) \\right \right \} dY Z(i)=∫Yexp{∑t=1Tη T⋅g (yt(i))+λ T⋅f (yt−1(i),yt(i))}dY,则
∑ i = 1 N − 1 Z ( i ) ∂ Z ( i ) ∂ λ ⃗ = ∑ i = 1 N − ∫ Y exp { ∑ t = 1 T η ⃗ T ⋅ g ⃗ ( y t ( i ) ) + λ ⃗ T ⋅ f ⃗ ( y t − 1 ( i ) , y t ( i ) ) } Z ( i ) ⏟ P ( Y ( i ) ∣ X ( i ) ) ⋅ f ⃗ ( y t − 1 ( i ) , y t ( i ) ) d Y = ∑ i = 1 N − E f ⃗ ( y t − 1 ( i ) , y t ( i ) ) . (17.6) \begin{aligned} \sum_{i=1}^N- \frac{1}{Z^{(i)}}\frac{\partial Z^{(i)}}{\partial \vec{\lambda}} &=\sum_{i=1}^N- \int_Y\underset{P(Y^{(i)}|X^{(i)})}{\underbrace{\frac{ \exp\left\{\sum_{t=1}^T\left \\vec{\\eta}\^T\\cdot \\vec{g}(y_t\^{(i)})+\\vec{\\lambda}\^T\\cdot \\vec{f}(y_{t-1}\^{(i)},y_t\^{(i)}) \\right \right \}}{Z^{(i)}}}}\cdot \vec{f}(y_{t-1}^{(i)},y_t^{(i)}) dY\\ &=\sum_{i=1}^N- E\left \\vec{f}(y_{t-1}\^{(i)},y_t\^{(i)}) \\right .\tag{17.6} \end{aligned} i=1∑N−Z(i)1∂λ ∂Z(i)=i=1∑N−∫YP(Y(i)∣X(i)) Z(i)exp{∑t=1Tη T⋅g (yt(i))+λ T⋅f (yt−1(i),yt(i))}⋅f (yt−1(i),yt(i))dY=i=1∑N−Ef (yt−1(i),yt(i)).(17.6)
因为
∫ Y P ( Y ∣ X ) ⋅ f ⃗ ( y t − 1 , y t ) d Y = ∫ y 1 ⋯ ∫ y T P ( y 1 , ⋯ , y T ∣ X ) ⋅ f ⃗ ( y t − 1 , y t ) d y 1 ⋯ d y T = ∫ y t − 1 ∫ y t P ( y t − 1 , y t ∣ X ) ⋅ f ⃗ ( y t − 1 , y t ) d y t − 1 d y t , (17.7) \begin{aligned} \int_YP(Y|X)\cdot\vec{f}(y_{t-1},y_t)dY&=\int_{y_1}\cdots\int_{y_T}\left P(y_1,\\cdots,y_T\|X)\\cdot\\vec{f}(y_{t-1},y_t) \\right \ dy_1\cdots dy_T \\ &=\int_{y_{t-1}}\int_{y_t}\left P(y_{t-1},y_t\|X)\\cdot\\vec{f}(y_{t-1},y_t) \\right \ dy_{t-1}dy_t,\tag{17.7}\end{aligned} ∫YP(Y∣X)⋅f (yt−1,yt)dY=∫y1⋯∫yTP(y1,⋯,yT∣X)⋅f (yt−1,yt) dy1⋯dyT=∫yt−1∫ytP(yt−1,yt∣X)⋅f (yt−1,yt) dyt−1dyt,(17.7)其中 P ( y t − 1 , y t ∣ X ) P(y_{t-1},y_t|X) P(yt−1,yt∣X) 可以用前向后向算法求得(见上文17.3 ),将该式带入上一步,可以求得 ▽ λ ⃗ \bigtriangledown _{\vec{\lambda}} ▽λ ,则 ▽ η ⃗ \bigtriangledown _{\vec{\eta}} ▽η 也可以同理计算。