一、背景描述
早上某事业部同事联系到我,说他们 AI 程序应用 P 版日志放在了生产 XXX 空间下,希望能帮忙创建一个公共账户,拥有只读取 XXX 命名空间下 XXX_AI 索引模式的权限,暂时放开给 AI 部门相关同事使用。
二、操作过程
之前都是给某个账号设置查询某个空间下所有索引的访问权限,现在要指定索引索引,该如何实现呢。
查询了相关资料,操作如下:
2.1 创建角色
这里先解释一个概念,什么是 ES 的角色。
ES 中角色的概念您可以将其理解为 一个权限的集合 或 一个权限的蓝图。它本身并不与任何用户直接关联,而是定义了"什么操作可以在什么资源上执行"。
角色的核心目的是实现权限的抽象和复用。您不需要为每个用户单独配置一堆零散的权限,而是创建一个角色(例如 log_reader, db_writer),然后将这个角色分配给需要相同权限的所有用户。
一个 ES 角色主要由几大块权限定义构成:集群权限 (Cluster Privileges)、索引权限 (Index Privileges)、应用权限 (Application Privileges)、运行身份 (Run As)、元数据 (Metadata)等。
总结就是:角色(Role)是 Elasticsearch 安全体系的枢纽。 它就像是一个权限容器,将集群、索引、应用等不同维度的权限打包在一起。用户(User) 通过被分配一个或多个角色来获得实际的权限,从而能够与 ES 集群和 Kibana 进行交互。
如下是创建角色命令及详细注释
PUT /_security/role/xxx_ai_space_restricted_user
{
// 集群权限配置:定义角色在整个Elasticsearch集群级别的操作权限
// 空数组表示此角色没有任何集群级别的特殊权限
"cluster": [],
// 索引权限配置:定义角色对特定索引的操作权限
"indices": [
{
// 指定此权限规则适用的索引名称模式
// 可以使用通配符 * 来匹配多个索引
// 此例中,角色可以访问所有以 'xxx_ai' 开头的索引
"names": ["xxx_ai*"],
// 定义在此索引上允许的操作权限
"privileges": [
"read", // 复合权限:包含读取操作如get、search等
"view_index_metadata" // 允许查看索引的元数据(映射、设置等)
]
// 可选的更细粒度控制:
// "field_security": {...} 可限制只能访问特定字段
// "query": {...} 可限制只能查询符合特定条件的文档
}
// 可以添加更多索引权限规则,以应对不同的索引模式
],
// 应用程序权限配置:定义角色对集成应用程序(如Kibana)的访问权限
"applications": [
{
// 指定应用程序标识符
// 'kibana-.kibana' 是Kibana应用程序的标准标识符
"application": "kibana-.kibana",
// 定义在Kibana中允许的功能特性权限
"privileges": [
"feature-discover.read", // 允许使用Discover功能进行数据探索
"feature-dashboard.read", // 允许查看仪表板
"feature-visualize.read", // 允许查看可视化图表
"feature-savedObjectsManagement.read" // 允许查看和管理已保存对象
// 注意:这些是Kibana功能特性权限,不是Elasticsearch索引权限
// 更多功能特性可在Kibana权限设置中查看
],
// 指定这些应用程序权限适用的资源范围
// 这是实现Kibana多租户空间隔离的关键配置
// "space:xxx" 表示这些权限仅适用于名为'xxx'的Kibana空间
// 如果设置为"*"则表示适用于所有空间
"resources": ["space:xxx"]
}
// 可以添加更多应用程序权限规则,以授予其他应用程序的访问权
]
// 可选字段:
// "run_as": [] - 允许此角色代表其他用户执行操作(高级功能)
// "metadata": {} - 用于存储角色的元数据信息(如描述、创建者等)
// "transient_metadata": { "enabled": true } - 临时元数据配置
}以上命令该如何操作呢,以上命令可以通过 curl 命令登录 ES 服务器执行,也可以在 Kibana 开发工具上执行,这里使用 Kibana 开发工具来执行,首先登录账号要有足够的权限可以执行上述命令。
登录 Kibana 管理界面,在开发工具下执行:
PUT /_security/role/xxx_ai_space_user
{
"cluster": [],
"indices": [
{
"names": ["xxx_ai*"],
"privileges": ["read", "view_index_metadata"]
}
],
"applications": [
{
"application": "kibana-.kibana",
"privileges": [
"feature-discover.read",
"feature-dashboard.read",
"feature-visualize.read",
"feature-savedObjectsManagement.read"
],
"resources": ["space:xxx"]
}
]
}执行命令返回 200-OK,表示执行成功。
2.2 创建用户
上面创建了角色后,接下来就要创建一个账号,让这个账号拥有上述创建的角色权限。
可以有如下几种方式来创建:
**方式一)**使用管理员账号登录 Kibana,然后依次打开 Stack Management --> User(用户),按照以下方式来创建,设置需要的相关信息,并选择之前创建的角色和 Kibana 角色。
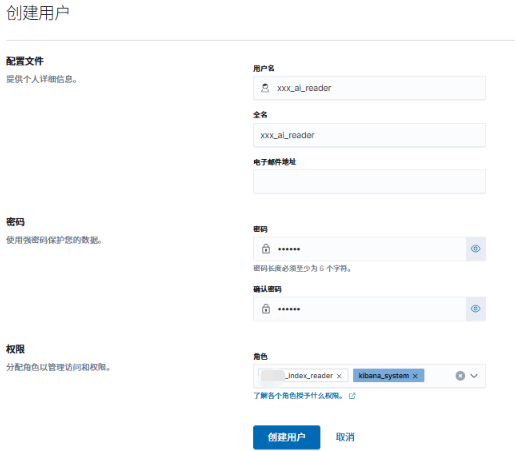
然后点击"创建用户"按钮,就创建了相应用户并设置了权限。
方式二)使用开发工具来创建,使用管理员账号,登录开发工具,执行如下命令:
PUT /_security/user/xxx_ai_reader
{
"password": "set_your_strong_password_here",
"roles": ["xxx_ai_space_user", "kibana_user", "system_kibana"],
"full_name": "xxx_ai_reader",
"email": ""
}方式三) 通过curl 命令来创建
登录 ES 服务器,早 esuser 用户下执行
curl -u elastic:elastic密码 -X PUT "http://<your-es-host>:9200/_security/user/xxx_ai_reader" \
-H 'Content-Type: application/json' \
-d '
{
"password": "set_your_strong_password_here", # 设置密码
"roles": ["xxx_ai_index_reader", "kibana_system", "system_kibana"], # 分配角色
"full_name": "xxx_ai_reader", # 用户全名
}
'三、验证测试
使用上述创建的 xxx_ai_reader 用户,登录 Kibana, 选择对应空间,然后查看 xxx_ai 前缀索引信息,如下所示:
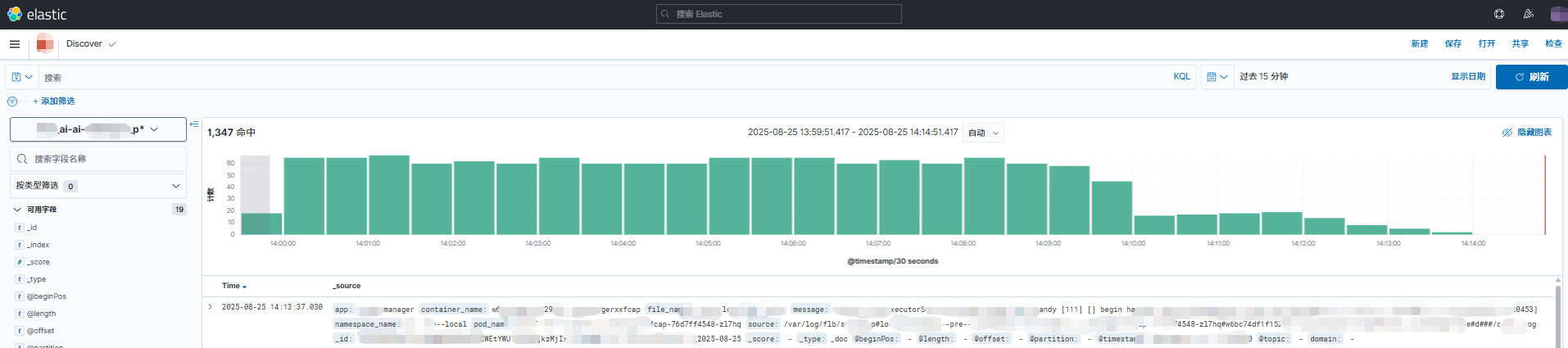
可以正常看到 XXX_ai 开头的前缀索引的相关日志信息。
再试试能否查看其它非 xxx_ai 前缀的索引日志信息

可以看到无法查看非 xxx_ai 前缀的索引日志信息。
四、附录
当前 ES 生产集群有很多空间,目前我还没找到如何设置让该用户登录后就直接打开其所在的空间,这块等我有时间再摸索下,到时补充下。