目录
-
-
- [PBO 说明](#PBO 说明)
- [PBO 优点](#PBO 优点)
- [从 PBO 更新纹理](#从 PBO 更新纹理)
- [保存 FrameBuffer 到 PBO](#保存 FrameBuffer 到 PBO)
-
PBO 说明
Opengl-es 的 PBO(Pixel Buffer Obejct), 也就是像素缓冲区对象,主要用于异步像素的传输操作, PBO 仅仅用做像素的一个暂存区,不连接到纹理,并且和 FBO(FrameBuffer Object) 无关
Opengl-es PBO (像素缓冲区对象) 类似于 VAO, VBO,EBO 等其他 Opengl-es 中用于缓存数据的对象,本质是对应一段 Opengles 自己管理的 VRAM,但是只用于存储图像数据
PBO 绑定的方式有两种 GL_PIXEL_UNPACK_BUFFER 和 GL_PIXEL_PACK_BUFFER
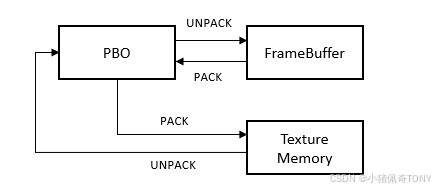
将 PBO 绑定为 GL_PIXEL_UNPACK_BUFFER 时, glTexImage2D 和 glTexSubImage2D 会从 PBO 对象中解包(unpack)像素数据并加载到纹理
将 PBO 绑定为 GL_PIXEL_PACK_BUFFER 时, glReadPixels 会从 帧缓冲区(或者 Pbuffer) 读取像素数据并传输到 PBO
PBO 优点
在处理高分辨率图像时,在内存和 GPU 的 VRAM (GPU管理的内存区域) 之间拷贝往往是比较耗时的,使用 PBO 相当于添加了一个 VRAM 暂存区域,结合异步的方式,一点程度上可以解决这个问题
使用 PBO 可以在 GPU 和 GPU_VRAM 之间快速传输数据,使用的是 DMA 传输的方式,不占用 CPU 时间,而且PBO 也支持异步传输
从 PBO 更新纹理
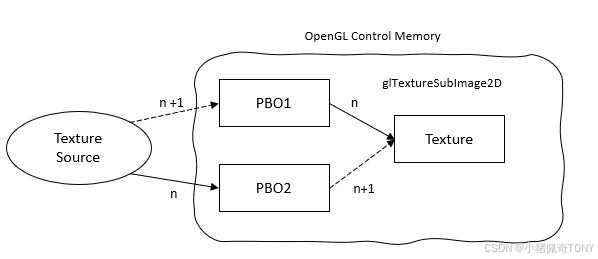
上图从文件中加载纹理,图像数据首先被加载到 CPU 内存中,然后通过 glTexImage2D 函数将图像数据从 CPU 内存复制到 OpenGL-ES 纹理对象中(GPU 内存),两次加载过程(拷贝和加载)完成由 CPU 控制和执行
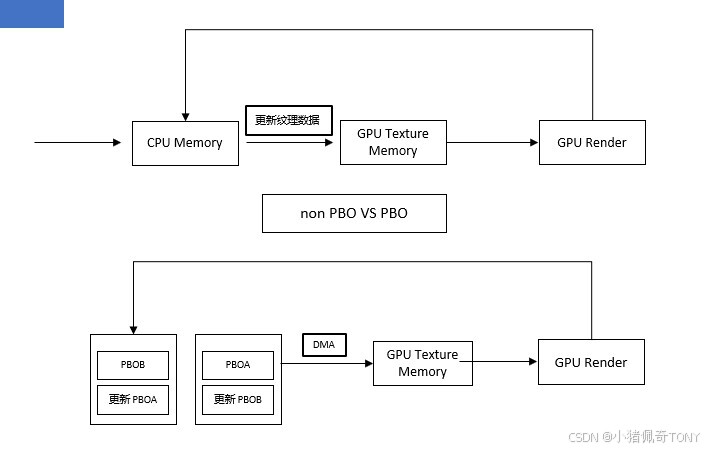
使用 PBO 加载纹理时,文件中图像数据可以直接加载到 PBO 中,这个操作由 CPU 进行控制,我们可以通过 glMapBufferRange 获取 PBO 对应的 GPU 的缓冲区的内存地址
将图像数据加载到 PBO 之后,再将图像数据从 PBO 传输到纹理对象中完全由 GPU 进行控制,不会占用 CPU 的时钟周期时间,所以绑定 PBO 之后,执行 glTexImage2D 操作,CPU 无需等待,可以立刻返回
参考代码:
c
static int Init(ESContext *esContext) {
UserData *userData = esContext->userData;
...
glGenBuffers(2, userData->pboIds);
int BufferSize = updateWidth * updateHeight * 3;
for (int i = 0; i < NUM_PBO; ++i) {
glBindBuffer(GL_PIXEL_UNPACK_BUFFER, userData->pboIds[i]);
glBufferData(GL_PIXEL_UNPACK_BUFFER, BufferSize, NULL, GL_STREAM_DRAW);
}
glClearColor(0.0f, 0.0f, 0.0f, 0.0f);
return TRUE;
}
// 使用 PBO 的方式更新纹理
static void updateTgaTexturesPBO(ESContext *esContext) {
UserData *userData = esContext->userData;
int index = userData->frameIndex % 2;
int nextIndex = (userData->frameIndex + 1) % 2;
glBindTexture(GL_TEXTURE_2D, userData->textureId);
glBindBuffer(GL_PIXEL_UNPACK_BUFFER, userData->pboIds[index]);
if (userData->frameIndex % 2) {
// 异步 DMA:GPU 从 PBO 中读取数据到纹理,注意最后一个参数是 NULL
glTexSubImage2D(GL_TEXTURE_2D, 0, 0, 0, updateWidth, updateHeight, GL_RGB, GL_UNSIGNED_BYTE, NULL);
// 绑定另一个 PBO 并映射到 CPU
glBindBuffer(GL_PIXEL_UNPACK_BUFFER, userData->pboIds[nextIndex]);
int BufferSize = updateWidth * updateHeight * 3;
GLubyte* ptr = (GLubyte*)glMapBufferRange(GL_PIXEL_UNPACK_BUFFER, 0, BufferSize, GL_MAP_WRITE_BIT | GL_MAP_INVALIDATE_BUFFER_BIT);
if (ptr) {
memcpy_s(ptr, BufferSize, userData->pixelsBlue, BufferSize);
glUnmapBuffer(GL_PIXEL_UNPACK_BUFFER);
}
} else {
// 异步 DMA:GPU 从 PBO 中读取数据到纹理 注意最后一个参数是 NULL
glTexSubImage2D(GL_TEXTURE_2D, 0, 200, 200, updateWidth, updateHeight, GL_RGB, GL_UNSIGNED_BYTE, NULL);
// 绑定另一个 PBO 并映射到 CPU
glBindBuffer(GL_PIXEL_UNPACK_BUFFER, userData->pboIds[nextIndex]);
int BufferSize = updateWidth * updateHeight * 3;
GLubyte* ptr = (GLubyte*)glMapBufferRange(GL_PIXEL_UNPACK_BUFFER, 0, BufferSize, GL_MAP_WRITE_BIT | GL_MAP_INVALIDATE_BUFFER_BIT);
if (ptr) {
memcpy_s(ptr, BufferSize, userData->pixelsRed, BufferSize);
glUnmapBuffer(GL_PIXEL_UNPACK_BUFFER);
}
}
glBindBuffer(GL_PIXEL_UNPACK_BUFFER, 0);
}
// 不使用 PBO 的方式直接更新纹理
static void updateTgaTextures(ESContext *esContext) {
UserData *userData = esContext->userData;
glBindTexture(GL_TEXTURE_2D, userData->textureId);
if (userData->frameIndex % 2) {
glTexSubImage2D(GL_TEXTURE_2D, 0, 0, 0, updateWidth, updateHeight, GL_RGB, GL_UNSIGNED_BYTE, userData->pixelsBlue);
}
else {
glTexSubImage2D(GL_TEXTURE_2D, 0, 0, 0, updateWidth, updateHeight, GL_RGB, GL_UNSIGNED_BYTE, userData->pixelsRed);
}
}保存 FrameBuffer 到 PBO
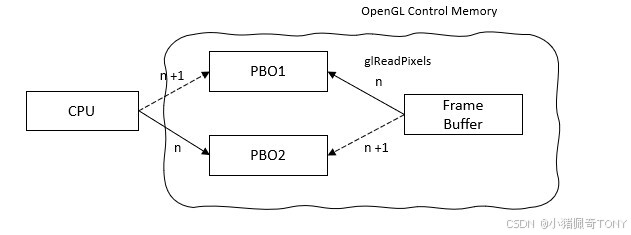
上图使用 glReadPixels从 帧缓冲区读取图像数据,需要 CPU 控制读取,涉及到 GPU 管理的内存区域向 CPU 内存区域拷贝,是需要阻塞等待完成的
使用 PBO 读取帧缓冲区数据时,帧缓冲数据可以直接传输到 PBO,这一步完全由 GPU 进行控制,不会占用 CPU 的时钟周期时间, glReadPixels可以立刻返回
传输完成后,通过 glMapBufferRange 获取 PBO 对应的 GPU 的缓冲区的内存地址,再将帧缓冲数据拷贝到 CPU 内存中
参考代码:
c
static int Init(ESContext *esContext) {
UserData *userData = esContext->userData;
......
// create multi pbo
glGenBuffers(NUM_PBO, userData->pbo);
printf("glGenBuffers PBO[0]:%d PBO[1]:%d\n", userData->pbo[0], userData->pbo[1]);
int dataSize = width * height * 3;
for (int i = 0; i < NUM_PBO; i++) {
glBindBuffer(GL_PIXEL_PACK_BUFFER, userData->pbo[i]);
glBufferData(GL_PIXEL_PACK_BUFFER, dataSize, NULL, GL_STREAM_READ);
}
glBindBuffer(GL_PIXEL_PACK_BUFFER, 0);
return GL_TRUE;
}
static void storeFrameBufferPBO() {
// async read (GPU render ==> current PBO)
GLuint index = userData->index;
glBindBuffer(GL_PIXEL_PACK_BUFFER, userData->pbo[index]);
glReadPixels(0, 0, width, height, GL_RGB, GL_UNSIGNED_BYTE, 0);
int dataSize = width * height * 3;
if (userData->cpuBuffer == NULL) {
userData->cpuBuffer = malloc(dataSize);
}
memset(userData->cpuBuffer, 0, dataSize);
// peek data from last pbo
int next_index = (index + 1) % NUM_PBO;
glBindBuffer(GL_PIXEL_PACK_BUFFER, userData->pbo[next_index]);
void *ptr = glMapBufferRange(GL_PIXEL_PACK_BUFFER, 0, dataSize, GL_MAP_READ_BIT);
if (ptr) {
memcpy(userData->cpuBuffer, ptr, dataSize);
glUnmapBuffer(GL_PIXEL_PACK_BUFFER);
char file_name[64];
sprintf(file_name, "pbuffer_output_%d.bmp", userData->frameindex);
saveBMP(file_name, userData->cpuBuffer, width, height);
}
// swap index
userData->index = next_index;
userData->frameindex++;
}