深度学习分类网络初篇:从感知机到AlexNet,深度学习的崛起之路
本文是深度学习分类网络系列的开篇之作,将带你回顾深度学习的发展历程,解析基础概念,并剖析一个完整的深度学习流程。无论你是初学者还是有一定经验的开发者,都能从这里找到新的启发。
文章目录
- 深度学习分类网络初篇:从感知机到AlexNet,深度学习的崛起之路
- 系列文章前言
- 一、深度学习简史:三起两落的技术革命
-
- [1.1 神经网络的早期探索(1940-1969)](#1.1 神经网络的早期探索(1940-1969))
- [1.2 反向传播与BP网络(1970-1990)](#1.2 反向传播与BP网络(1970-1990))
- [1.3 深度学习的崛起(2006年至今)](#1.3 深度学习的崛起(2006年至今))
- 二、深度学习基础概念解析
-
- [2.1 神经网络基本组成](#2.1 神经网络基本组成)
-
- [1. 输入层(Input Layer)](#1. 输入层(Input Layer))
- [2. 隐藏层(Hidden Layers)](#2. 隐藏层(Hidden Layers))
- [3.输出层(Output Layer)](#3.输出层(Output Layer))
- [2.3 核心组件](#2.3 核心组件)
-
- [1.激活函数(Activation Function)](#1.激活函数(Activation Function))
- [2. 损失函数(Loss Function)](#2. 损失函数(Loss Function))
- 3.优化器(Optimizer)
- [4. 正则化技术](#4. 正则化技术)
- 三、完整的深度学习流程详解
-
- [3.1 数据准备与预处理](#3.1 数据准备与预处理)
- [3.2 模型构建与配置](#3.2 模型构建与配置)
- [3.3 训练循环与验证](#3.3 训练循环与验证)
- [3.4 模型评估与超参数优化](#3.4 模型评估与超参数优化)
- 四、深度学习当前挑战与未来方向
-
- [4.1 当前面临的主要挑战](#4.1 当前面临的主要挑战)
- [4.2 未来发展方向与趋势](#4.2 未来发展方向与趋势)
- 总结
系列文章前言
近年来,深度学习技术在图像分类、目标检测、语义分割等领域取得了突破性进展。作为一名计算机视觉爱好者,我决定撰写这个系列文章,系统地介绍从LeNet到Vision Transformer等各种经典的深度学习分类网络。我们将一起探索这些网络的结构设计思想、实现原理以及实际应用,希望能为后来者提供一份清晰的学习路线和实践指南。
一、深度学习简史:三起两落的技术革命
1.1 神经网络的早期探索(1940-1969)
深度学习的发展并非一帆风顺,而是经历了多次起伏:
1943年 :Warren McCulloch和Walter Pitts提出了第一个人工神经元模型(MP模型),开创了神经网络的研究先河
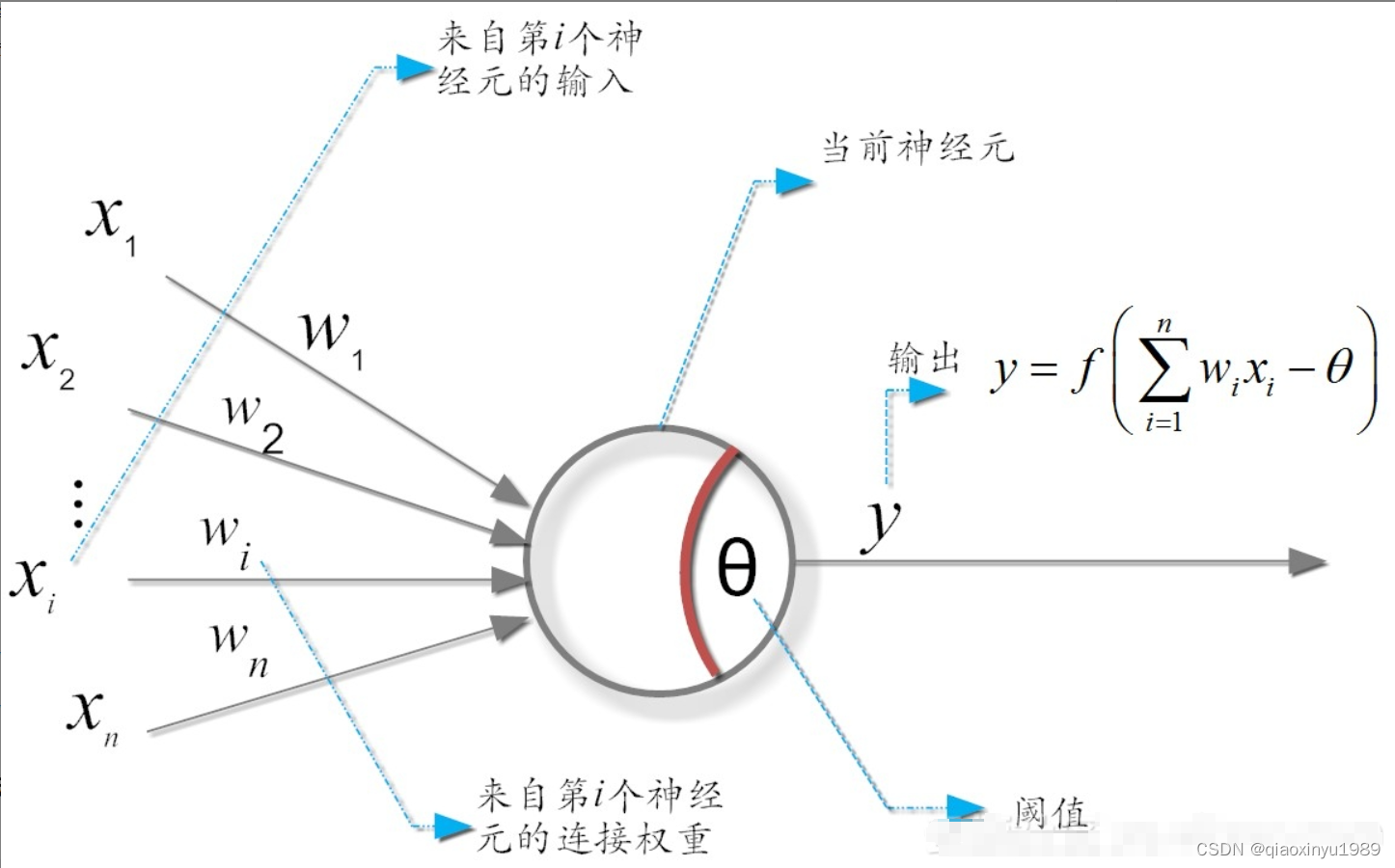
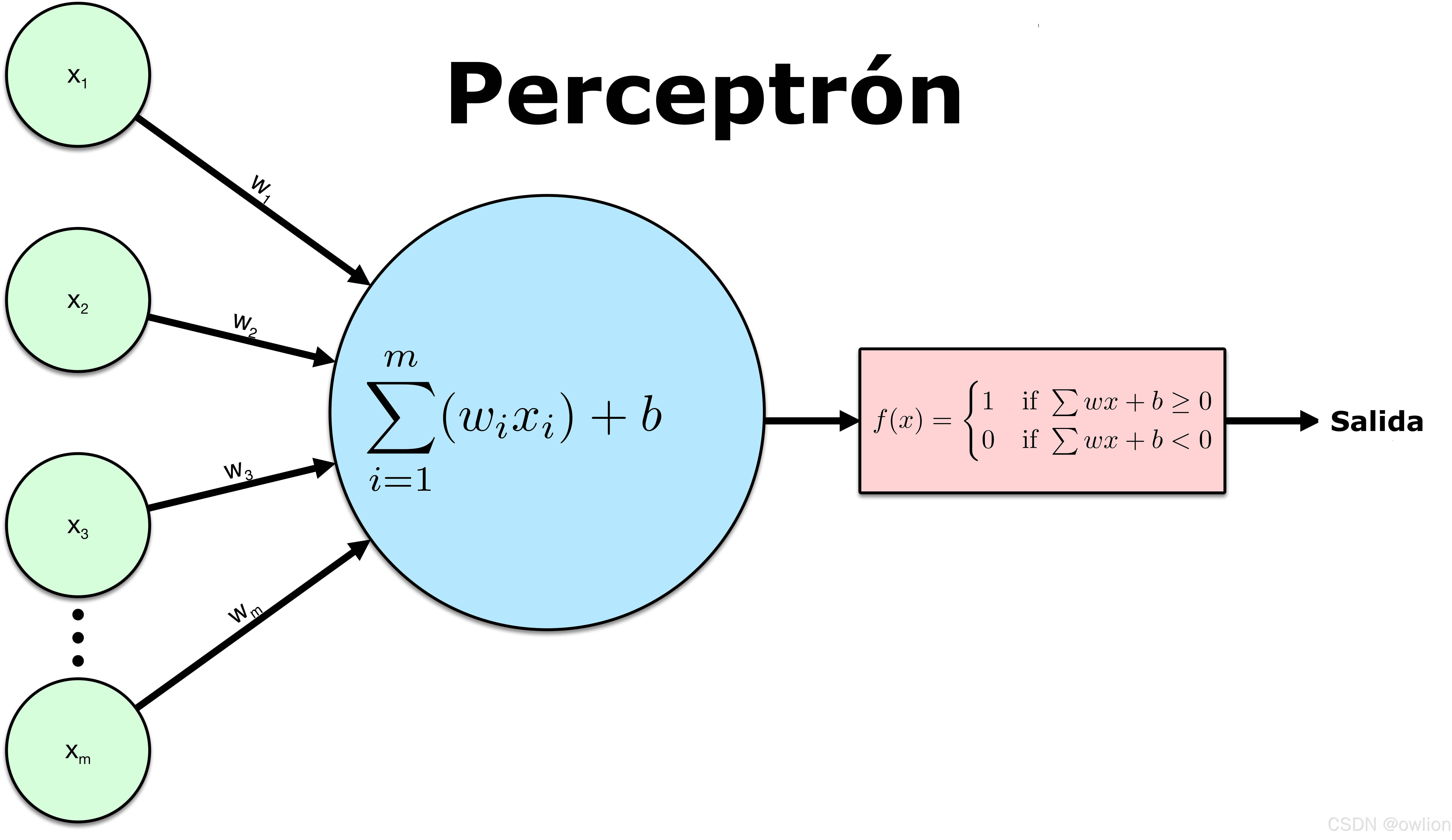
1958年 :Frank Rosenblatt提出了感知机(Perceptron)模型,这是第一个能够进行二分类学习的神经网络
python
# 感知机的现代实现
import torch
import torch.nn as nn
class Perceptron(nn.Module):
"""最简单的感知机实现"""
def __init__(self, input_dim):
super(Perceptron, self).__init__()
self.linear = nn.Linear(input_dim, 1)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
return self.sigmoid(self.linear(x))
# 感知机只能解决线性可分问题
perceptron = Perceptron(2)
print("感知机参数:", list(perceptron.parameters()))1969年:Minsky和Papert出版了《Perceptrons》一书,指出了单层感知机无法解决线性不可分问题(如异或问题),这直接导致了神经网络的第一次寒冬
1.2 反向传播与BP网络(1970-1990)
1974年 :Paul Werbos提出了反向传播算法(Backpropagation),但当时并未引起广泛关注
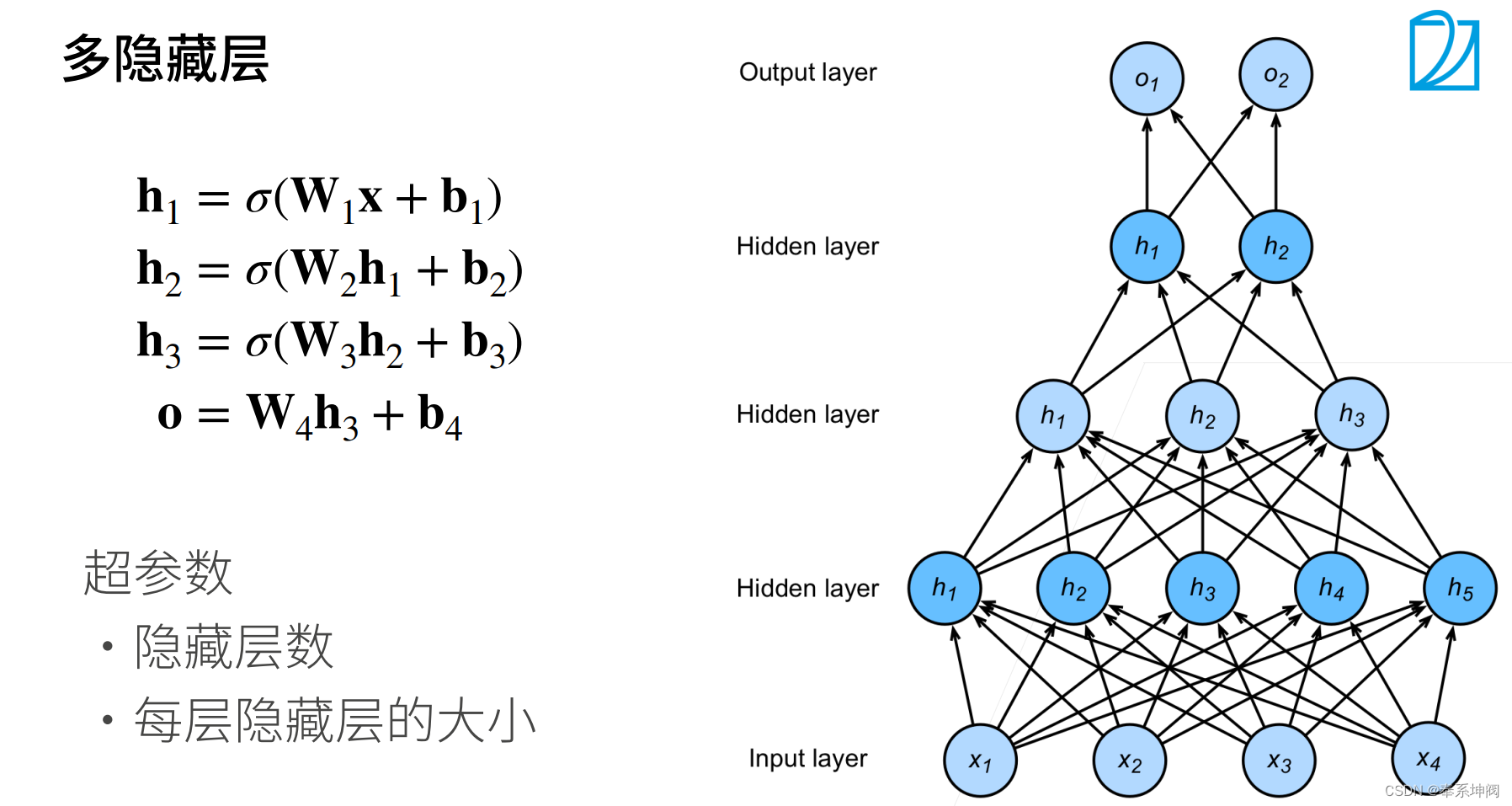
1986年 :Rumelhart、Hinton和Williams独立重新发现了反向传播算法,独立重新发现了反向传播算法,并成功应用于多层感知机(MLP)训练。这一突破为神经网络研究注入了新的活力
python
# 多层感知机(MLP)实现
class MLP(nn.Module):
"""多层感知机解决了线性不可分问题"""
def __init__(self, input_dim, hidden_dim, output_dim):
super(MLP, self).__init__()
self.layer1 = nn.Linear(input_dim, hidden_dim)
self.relu = nn.ReLU()
self.layer2 = nn.Linear(hidden_dim, output_dim)
def forward(self, x):
x = self.relu(self.layer1(x))
return self.layer2(x)
# MLP可以解决异或等非线性问题
mlp = MLP(2, 4, 1)
print("MLP参数量:", sum(p.numel() for p in mlp.parameters()))1989年:Yann LeCun等人将反向传播算法与卷积操作结合,开发了LeNet网络用于手写数字识别。这一工作奠定了卷积神经网络的基础,但在当时由于计算资源限制和数据稀缺,并未引起广泛关注
1.3 深度学习的崛起(2006年至今)
2006年 :Geoffrey Hinton等人提出了"深度学习"的概念,通过无监督预训练和逐层贪婪训练的方法解决了深层网络训练困难的问题,在MNIST数据集上取得了当时最好的结果
2012年 :成为了深度学习的转折点。Alex Krizhevsky等人提出的AlexNet在ImageNet竞赛中以压倒性优势获胜(top-5错误率从26%降至15%),标志着深度学习时代的正式到来
2015年 :ResNet首次解决了超深层网络(超过100层)的退化问题,使网络深度不再是性能瓶颈
2017年至今:Transformer架构的出现引领了新一轮技术革命,Vision Transformer等模型开始在计算机视觉领域展现强大能力
二、深度学习基础概念解析
2.1 神经网络基本组成
一个基本的神经网络包含以下组件:
1. 输入层(Input Layer)
输入层是神经网络与原始数据的接口,负责接收和预处理原始数据。在图像处理中,输入层通常接收三维张量(通道×高度×宽度),并进行标准化等预处理操作。
作用:数据接口、数据预处理、维度转换
2. 隐藏层(Hidden Layers)
隐藏层是神经网络的核心组成部分,负责从数据中提取和学习特征。每一层都会学习到不同抽象级别的特征表示。
python
# 隐藏层的作用演示
import torch.nn.functional as F
class FeatureExtractor(nn.Module):
"""展示隐藏层如何逐步提取特征"""
def __init__(self):
super(FeatureExtractor, self).__init__()
self.conv1 = nn.Conv2d(3, 32, 3) # 学习边缘等低级特征
self.conv2 = nn.Conv2d(32, 64, 3) # 学习纹理等中级特征
self.conv3 = nn.Conv2d(64, 128, 3) # 学习物体部件等高级特征
def forward(self, x):
x = F.relu(self.conv1(x)) # 低级特征
x = F.relu(self.conv2(x)) # 中级特征
x = F.relu(self.conv3(x)) # 高级特征
return x作用:特征提取、特征转换、表示学习
3.输出层(Output Layer)
输出层根据任务需求生成最终的预测结果。不同的任务需要不同类型的输出层设计和激活函数。
作用:结果生成、概率转换、任务适配
2.3 核心组件
1.激活函数(Activation Function)
作用:引入非线性变换,使神经网络能够学习复杂的模式和关系。没有激活函数,无论多少层的神经网络都等价于单层线性模型。
常见激活函数比较:
Sigmoid:将输入压缩到(0,1)区间,适合二分类问题
ReLU:计算简单,缓解梯度消失,但可能导致神经元死亡
Leaky ReLU:解决ReLU的神经元死亡问题
Softmax:将输出转换为概率分布,适合多分类问题
python
# 激活函数比较示例
def compare_activation_functions():
x = torch.linspace(-5, 5, 100)
activations = {
'Sigmoid': torch.sigmoid(x),
'ReLU': torch.relu(x),
'Leaky ReLU': F.leaky_relu(x, 0.1),
'Tanh': torch.tanh(x)
}
# 绘制对比图
plt.figure(figsize=(12, 8))
for i, (name, y) in enumerate(activations.items()):
plt.subplot(2, 2, i+1)
plt.plot(x.numpy(), y.numpy())
plt.title(name)
plt.grid(True)
plt.tight_layout()
plt.show()
# 通过可视化理解不同激活函数的特性
compare_activation_functions()2. 损失函数(Loss Function)
作用:衡量模型预测值与真实值之间的差异,为优化提供方向。损失函数的选择直接影响模型的学习目标和性能。
常见损失函数:
交叉熵损失:分类任务的首选,衡量概率分布差异
均方误差:回归任务常用,衡量数值差异
对比损失:度量学习中使用,学习数据间的相似性
python
# 损失函数的作用演示
def demonstrate_loss_functions():
# 模拟预测值和真实值
predictions = torch.tensor([[2.0, 1.0, 0.1], [1.0, 2.0, 0.1]])
targets = torch.tensor([0, 1]) # 类别索引
# 交叉熵损失
ce_loss = F.cross_entropy(predictions, targets)
print(f"Cross Entropy Loss: {ce_loss.item():.4f}")
# 回归任务的均方误差损失
regression_pred = torch.tensor([1.5, 2.3, 3.1])
regression_true = torch.tensor([1.0, 2.0, 3.0])
mse_loss = F.mse_loss(regression_pred, regression_true)
print(f"MSE Loss: {mse_loss.item():.4f}")
demonstrate_loss_functions()3.优化器(Optimizer)
作用:通过反向传播算法更新网络参数,最小化损失函数。优化器的选择影响模型的收敛速度和最终性能。
优化器比较:
SGD:基础优化器,需要仔细调参
Adam:自适应学习率,通常效果较好
AdamW:改进的Adam,解决权重衰减问题
python
# 优化器比较示例
def compare_optimizers(model, train_loader):
# 不同优化器的训练效果比较
optimizers = {
'SGD': optim.SGD(model.parameters(), lr=0.01),
'Adam': optim.Adam(model.parameters(), lr=0.001),
'AdamW': optim.AdamW(model.parameters(), lr=0.001)
}
results = {}
for name, optimizer in optimizers.items():
model.reset_parameters() # 重置模型参数
train_loss = train_with_optimizer(model, train_loader, optimizer)
results[name] = train_loss
# 绘制训练曲线对比
plt.figure(figsize=(10, 6))
for name, loss in results.items():
plt.plot(loss, label=name)
plt.legend()
plt.title('Optimizer Comparison')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.show()4. 正则化技术
作用:防止过拟合,提高模型泛化能力。深度学习模型参数众多,容易过拟合训练数据。
常用正则化方法:
Dropout:随机丢弃神经元,强制网络学习冗余表示
权重衰减:L2正则化,限制参数大小
批量归一化:稳定训练过程,允许使用更高学习率
python
# 正则化技术示例
class RegularizedModel(nn.Module):
"""展示各种正则化技术的应用"""
def __init__(self, input_dim, hidden_dim, output_dim, dropout_rate=0.5):
super(RegularizedModel, self).__init__()
self.layer1 = nn.Linear(input_dim, hidden_dim)
self.bn1 = nn.BatchNorm1d(hidden_dim) # 批量归一化
self.dropout = nn.Dropout(dropout_rate) # Dropout
self.layer2 = nn.Linear(hidden_dim, output_dim)
def forward(self, x):
x = F.relu(self.bn1(self.layer1(x)))
x = self.dropout(x)
return self.layer2(x)
# 权重衰减在优化器中设置
optimizer = optim.AdamW(
model.parameters(),
lr=0.001,
weight_decay=0.01 # 权重衰减
)三、完整的深度学习流程详解
3.1 数据准备与预处理
数据是深度学习的基石,合理的数据预处理可以显著提升模型性能。深度学习模型对数据质量非常敏感,因此数据预处理环节至关重要。
数据预处理的主要步骤:
数据加载与清洗:读取原始数据,处理缺失值和异常值
数据增强:通过对训练数据进行变换,增加数据多样性
数据标准化:将数据缩放到合适范围,加速训练收敛
数据集划分:划分为训练集、验证集和测试集
3.2 模型构建与配置
模型构建是深度学习的核心环节,需要根据任务需求选择合适的网络架构。现代深度学习框架提供了丰富的预训练模型和灵活的构建方式。
模型构建的关键考虑因素:
任务类型:分类、检测、分割等不同任务需要不同的网络结构
数据特性:输入数据的尺寸、通道数等影响网络设计
计算资源:模型大小和计算复杂度需要与可用资源匹配
性能要求:准确率、速度、内存占用等性能指标的权衡
3.3 训练循环与验证
训练循环是深度学习的核心执行过程,需要仔细设计以确保模型有效学习。一个完整的训练流程包括前向传播、损失计算、反向传播和参数更新。
训练过程的关键组件:
训练循环:迭代处理训练数据
验证循环:定期评估模型性能
日志记录:记录训练过程中的关键指标
模型保存:保存最佳模型和训练检查点
3.4 模型评估与超参数优化
模型评估是验证模型性能的关键步骤,而超参数优化则是提升模型性能的重要手段。
模型评估的多个维度:
准确率:整体分类准确率
混淆矩阵:详细分析各类别的分类情况
PR曲线和ROC曲线:评估二分类模型性能
推理速度:模型的实际运行效率
四、深度学习当前挑战与未来方向
4.1 当前面临的主要挑战
深度学习虽然取得了巨大成功,但仍然面临着诸多挑战:
1.数据依赖与标注成本
- 深度学习模型需要大量标注数据进行训练
- 数据标注成本高昂且耗时耗力
- 在某些特定领域(如医疗影像)获取高质量标注数据尤为困难
2.模型可解释性
- 深度神经网络决策过程不透明,被称为"黑箱"
- 难以理解和解释模型的预测结果和决策依据
- 在关键应用领域(如自动驾驶、医疗诊断)的可信度问题
3.计算资源需求
- 训练大型模型需要大量的计算资源和时间
- 能源消耗大,存在碳足迹问题
- 部署到边缘设备时的资源限制和效率问题
4.泛化能力与鲁棒性
- 模型在分布外数据上表现往往不佳
- 容易受到对抗样本攻击,安全性令人担忧
- 对输入数据的微小变化过于敏感
4.2 未来发展方向与趋势
面对这些挑战,研究者们正在多个方向进行探索:
1.自监督与无监督学习
- 减少对标注数据的依赖,利用大量无标注数据
- 对比学习、生成式自监督学习等新方法
- 提高数据利用效率和模型泛化能力
2.模型效率与压缩技术
- 模型剪枝、量化、知识蒸馏等技术
- 设计高效的神经网络架构
- 适用于边缘设备的轻量级模型开发
3.可解释性与可信AI
- 开发模型解释工具和方法
- 增强模型的透明度和可信度
- 建立AI系统的问责机制和伦理标准
4.多模态与跨模态学习
- 融合视觉、语言、音频等多种模态信息
- 跨模态的理解与生成能力
- 实现更通用的人工智能系统
5.神经架构搜索与AutoML
- 自动寻找最优网络架构
- 减少人工设计网络的工作量
- 提高模型开发的自动化程度
总结
本文作为深度学习分类网络系列的开篇,全面回顾了深度学习的发展历程,详细介绍了核心概念和完整流程。我们从感知机的诞生谈起,一直展望到当前最前沿的研究方向,希望能够为读者提供一个系统的知识框架。
深度学习虽然取得了令人瞩目的成就,但仍然面临许多挑战。正是这些挑战推动着研究者们不断探索和创新。在接下来的文章中,我们将深入探讨各种经典的分类网络,从LeNet开始,一步步了解这些网络的设计思想、实现原理和应用场景。