断断续续大约用了一个月的时间,完全重新训练了一下Cortex LLM,大部分还是在4张4090显卡上训练的。模型还是一个小型的MoE,总参数量大约0.6B,激活参数0.2B。比上一个版本更新了如下内容:
-
替换预训练数据集,使用序列猴子通用文本数据集进行预训练。
-
采用多阶段预训练和后训练方式。预训练采用两阶段方式,第一阶段上下文长度是512,第二阶段采用YaRN技术将上下文扩展至2048。后训练采用四阶段方式,先在cot数据集上进行SFT,让模型原生支持思考能力,然后使用GSPO增强其逻辑思维能力,再通过融合思考和非思考数据进行SFT,最后使用DPO进行对齐。
-
新增思考模式控制,可通过添加/think和/no think控制是否思考。在后训练的第三阶段通过融合cot和非cot数据进行SFT实现。
-
新增思考预算功能,可控制思考token长度。该功能通过两次调用生成实现。
最终模型效果
思考模式 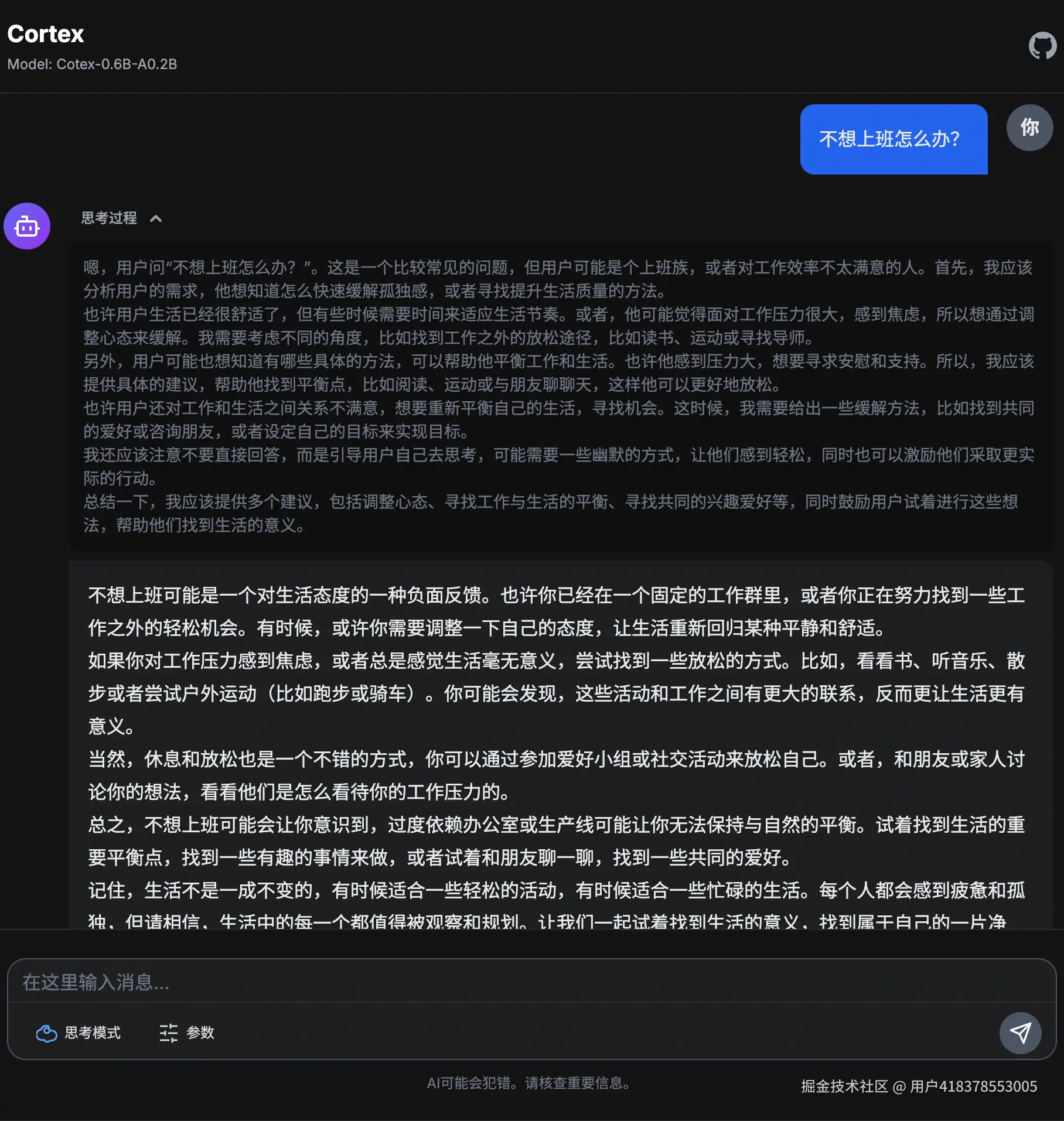
非思考模式 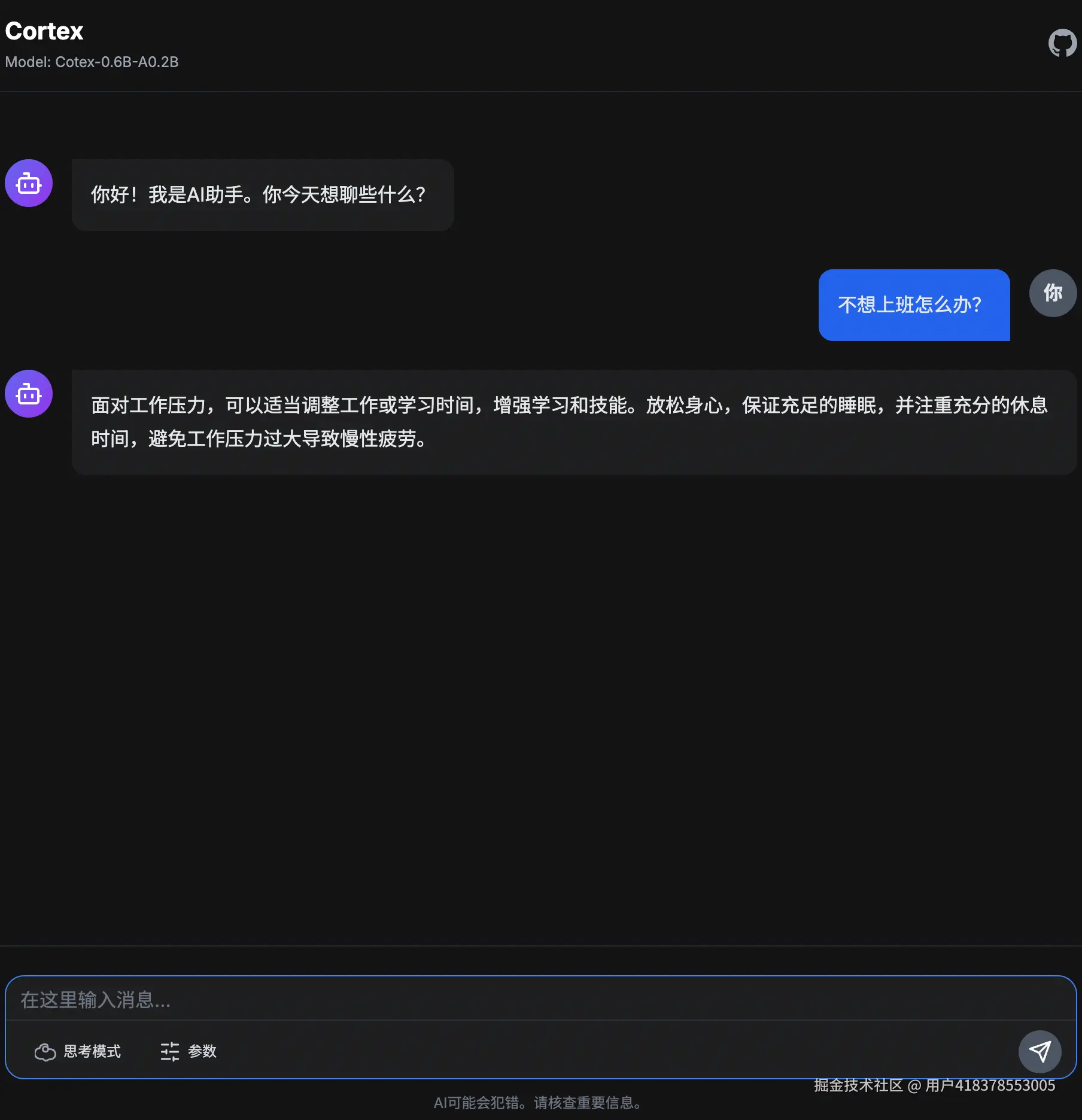
思考预算 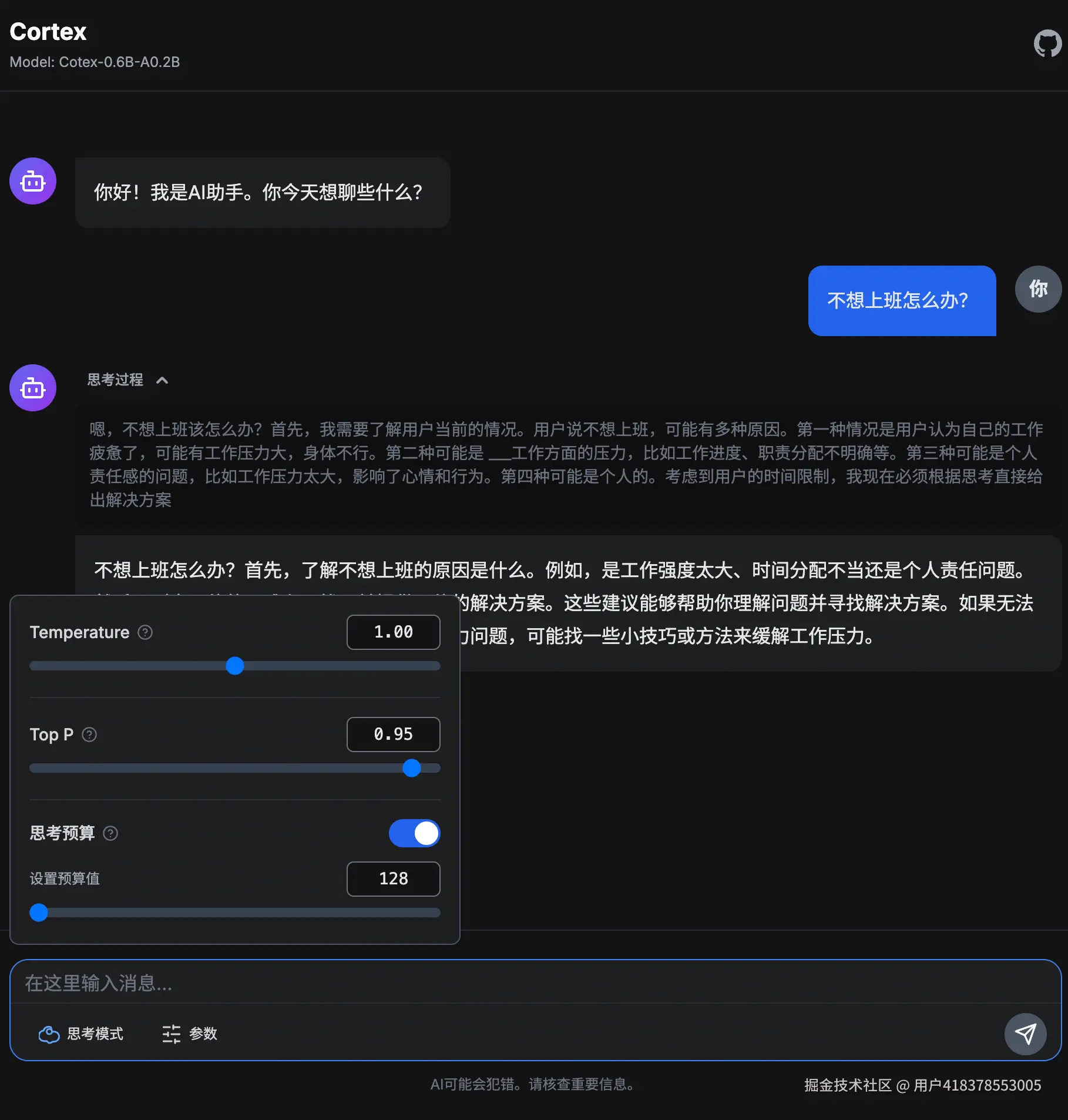
模型和训练代码完全开放在github上了。
另外本项目依赖的模型代码和训练代码也已开源,模型支持LLM和VLM。训练代码支持Pretrain、SFT、GRPO、GSPO、DPO,支持ddp和deepspeed zero0-3训练。