本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在智泊AI。
印象里大模型参数动辄千亿万亿,训练成本更是天文数字,感觉像是普通人遥不可及的"屠龙之术"。但今天想跟你们聊个有意思的反例,一个叫 MiniMind 的开源项目,它反其道而行之,主打一个"大道至简"。
这个项目的目标听起来有点不可思议:只花3块钱的服务器成本,用2个小时,就能从零开始训练一个属于你自己的语言模型。当然,这里的"2小时"是在NVIDIA 3090这种还算不错的个人显卡上测试的,"3块钱"也是指租用这块显卡的云服务费用。即便如此,这个门槛也低得让人心动。

这几年AI圈子实在太浮躁,各种框架和工具库把一切都封装得严严实实。比如用transformers库,十几行代码就能跑完一个模型的训练流程。这当然很方便,但给我的感觉就像是坐在飞船的头等舱里,速度是快,可你永远不知道这飞船的引擎是怎么造的。MiniMind的作者显然也有同感,他觉得"用乐高拼出一架飞机,远比坐在头等舱里飞行更让人兴奋"。
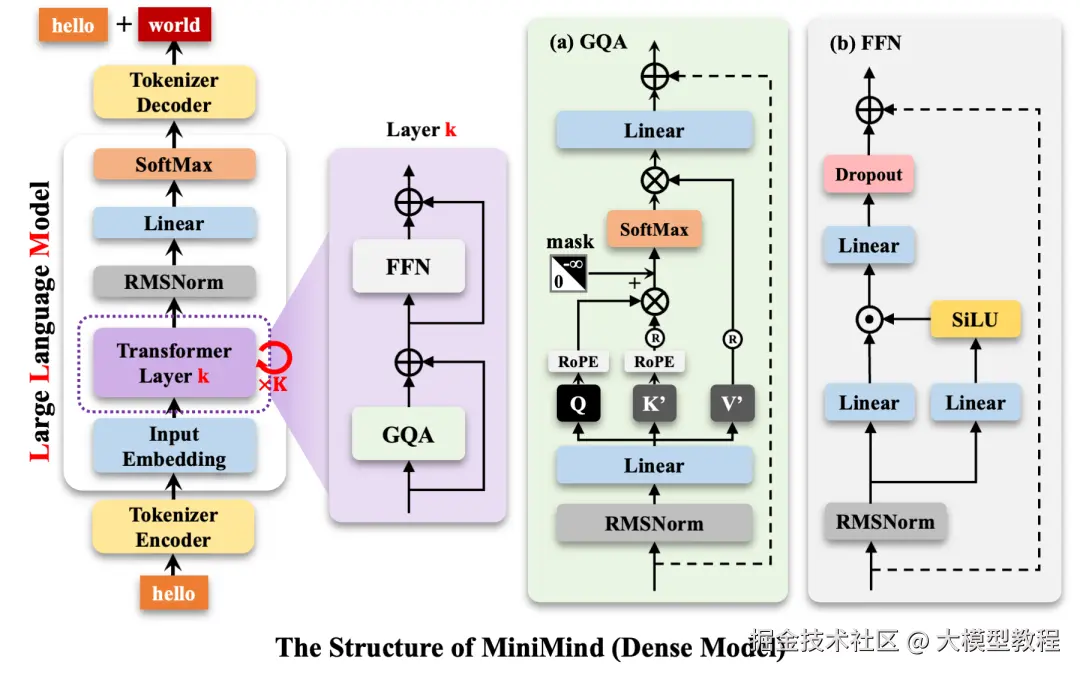
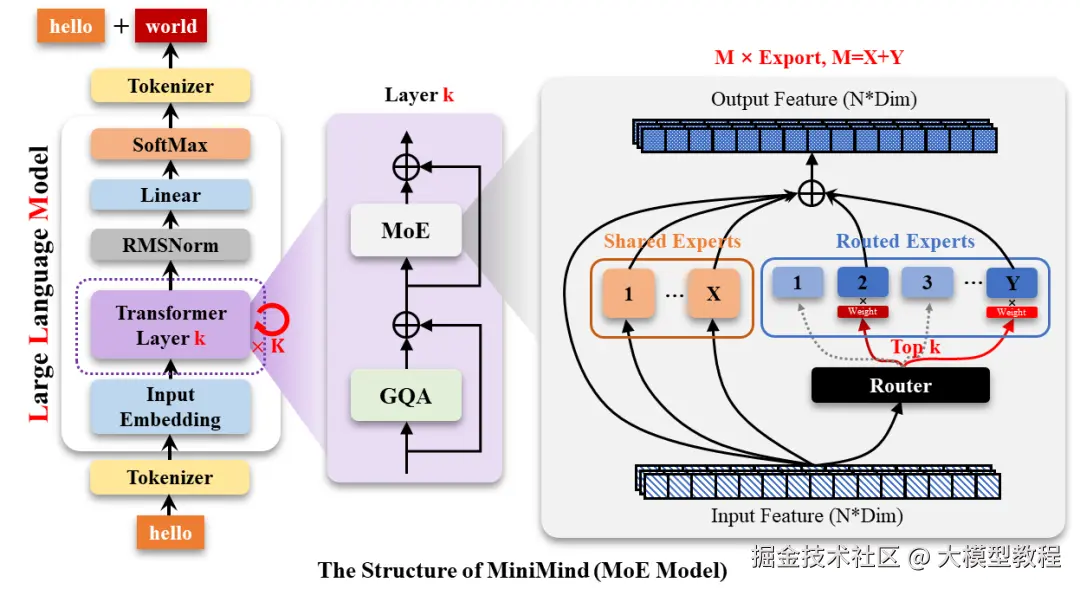
所以,这个项目最大的特点就是"透明"。它把大模型训练的全过程,包括数据清洗、预训练、监督微调、强化学习等等,全部用最基础的PyTorch代码从头实现了一遍,几乎不依赖那些高度抽象的第三方库。这相当于把大模型的"黑盒子"拆开,把里面的零件一个个摆在你面前,让你看清楚、摸明白。对于想真正入门LLM的人来说,这简直是一份宝藏级的教程。
MiniMind训练出来的模型有多大呢?最小的版本只有25.8M,作为对比,几年前的GPT-3模型体积是它的7000多倍。这意味着,你不仅能在自己的普通电脑上训练它,还能轻松地部署和运行它。
当然,这么小的模型,你不能指望它有GPT-4的智商。但它的意义不在于挑战巨头,而在于"祛魅"。它让你亲身体验一个语言模型是如何从一堆杂乱的文本数据中"学会"知识,再通过对话练习"学会"交流的。
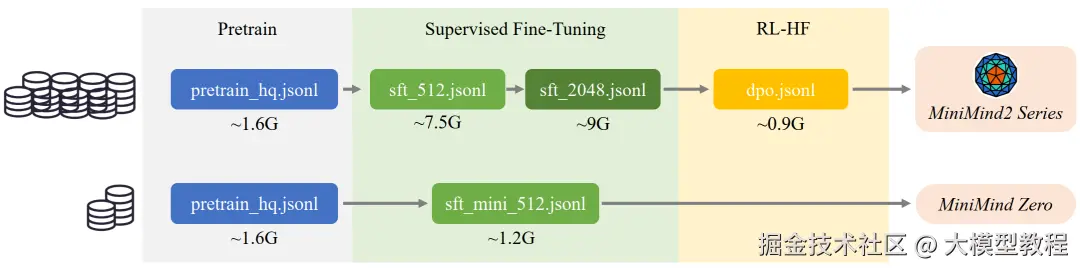
整个过程大概分几步。首先是预训练,就像让一个刚出生的婴儿去读海量的书籍报刊,虽然它还不懂怎么说话,但脑子里已经装满了各种知识。MiniMind用的是一份约1.6GB的高质量中文语料,让模型在这个阶段埋头"学习接龙",比如看到"秦始皇",它得学会接"是中国的第一位皇帝"。
然后是监督微调(SFT) 。模型学富五车但不会聊天,怎么办?就给它看大量的对话范例,告诉它看到"问题"后面要跟"回答"。这个过程就像教一个书呆子社交礼仪,让他知道聊天的基本格式。
再往后,还有更高级的玩法,比如强化学习(RLHF/RLAIF) 。简单说,就是让模型知道什么样的回答是"好"的,什么样的回答是"坏"的。比如用DPO(直接偏好优化)方法,你给模型看一对答案,告诉它哪个更受人类喜欢,模型就会慢慢调整自己的说话风格,变得更讨人喜欢。MiniMind甚至还从零实现了PPO、GRPO这些更前沿的强化学习算法,用一个AI"裁判"来给模型的回答打分,引导它进化。
那么,花3块钱训练出来的模型效果到底怎么样?项目作者也坦诚地给出了测试结果。在一些客观的中文评测榜单上,比如C-Eval,MiniMind的得分基本在25%上下徘徊。要知道,四选一的选择题,瞎猜的正确率就是25%。所以,从"智商"上说,它确实只是个"宝宝"。
但在实际对话中,它已经能有模有样地回答一些基本问题了。比如你问它"介绍一下自己",它会说"我是一个人工智能,被设计用来帮助用户解答问题"。你让它推荐杭州美食,它也能说出几个像样的菜名。虽然偶尔会犯傻,比如问它美国历史,它可能会蹦出一段不知所云的中文。但考虑到它的体量和训练成本,能做到这样已经相当不错了。
我个人觉得,MiniMind这个项目最有价值的地方,不是它最终训练出的模型有多强,而是它提供了一个可动手、低成本的实验平台。它证明了理解和构建一个语言模型,并不一定需要庞大的算力和资金。它更像一个"厨房",备齐了所有食材和厨具,鼓励你自己下厨,而不是永远只当一个点外卖的食客。
现在,这个项目已经兼容了像llama.cpp、ollama这些流行的本地推理框架,你可以很方便地把自己训练的模型跑在个人电脑上,甚至把它打包成一个API服务,接入各种聊天界面。
总而言之,如果你也对AI的底层原理感到好奇,厌倦了那些云里雾里的概念,想亲手"拼"一个属于自己的语言模型,那MiniMind绝对值得你花上一个下午去研究一下。毕竟,能用一杯奶茶的钱,换来一次深入AI核心腹地的机会,这笔买卖怎么看都挺划算的。
学习资源推荐
如果你想更深入地学习大模型,以下是一些非常有价值的学习资源,这些资源将帮助你从不同角度学习大模型,提升你的实践能力。
本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在智泊AI。